



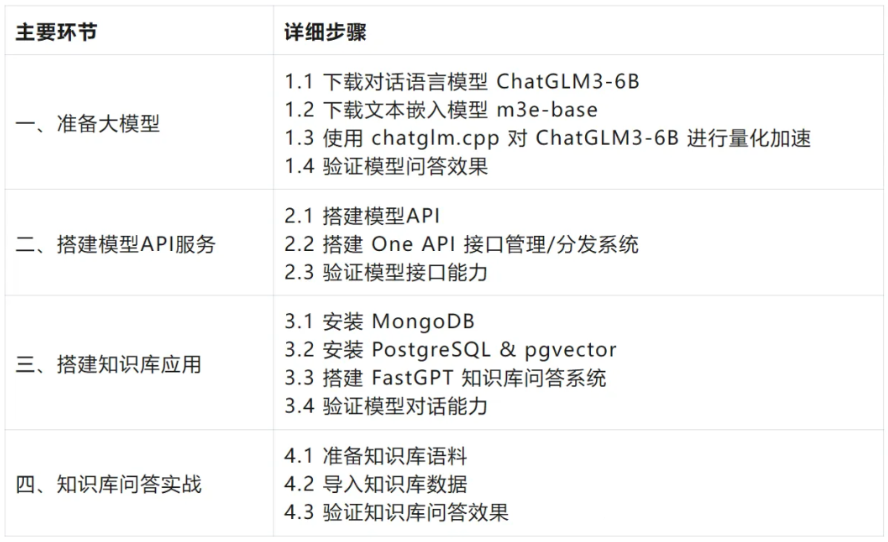
主要环节
核心架构
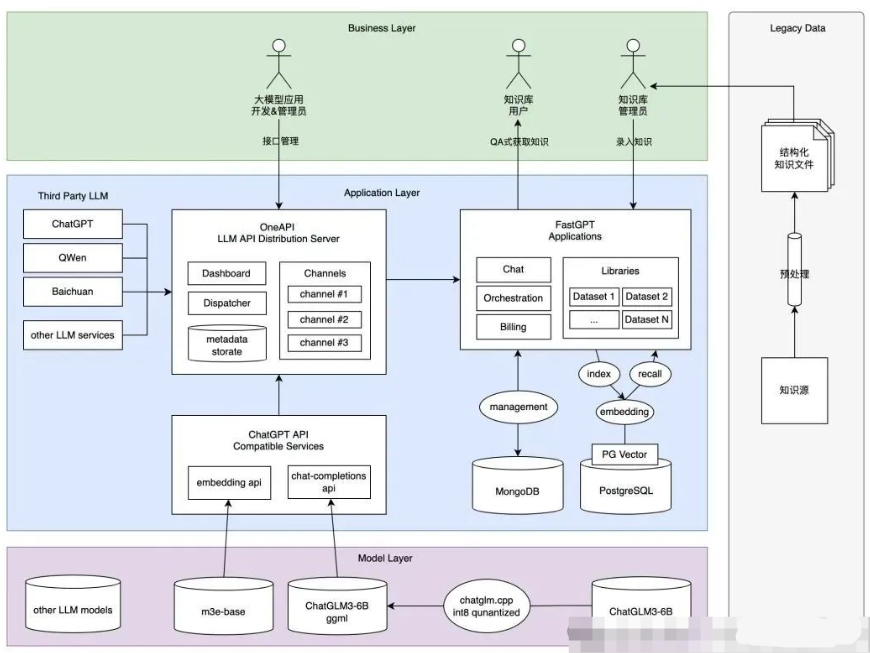
本文技术路线为:利用ChatGLM3-6b作为基座大模型,M3E作为向量模型,基于FastGPT建立用户知识库,One-API做统一API接口管理。其中ChatGLM3和M3E模型都是在windows下部署的,FastGPT和One-API是在Linux下部署。
在私有化和客制化大模型庞大需求推动下,除了从大模型的全量训练和微调这两个模型改动层面上,在大模型外添加一个知识库也是一种解决思路。因为,一方面重新训练模型需要相当多的资源和专业知识,另一方面大模型本身具有知识延迟问题和幻想问题。
-
知识延迟问题是训练大模型需要一定的时间,从而训练数据就不可能具有实时性,而且相当耗费资源。
-
幻想问题问题则由于LLM采用的概率模型,即预测生成下一个字符概率是多少,所有或多或少的它在生成结果的时候都有定的可能出现错误。
目前比较好的方式就是利用大模型极强的语义理解能力,给大模型外挂一个知识库或者搜索引擎去解决这两个问题。基于知识库的定制化服务是独立于大模型的,知识库可以理解为一个用于提示引导大模型,和提供客户特有知识的工具。
一、ChatGLM3大模型本地部署
1.1 从Git拉取项目到本地
-
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。
-
Git地址连接
由于模型的权重文件很大,故需从HuggingFace上拉取到models目录下。
-
ChatGLM3-6B-base地址连接(不支持微调)
-
ChatGLM3-6B地址连接
1.2 配置环境
在conda创建一个虚拟环境,其中需要python版本建议3.11以上,随后配置cuda和torch,可以先使用nvidia-smi命令查看cuda支持的最高版本,随后按照pytorch官网的命令进行安装。

切换到配置chatglm的conda环境后,使用pip install -r requirements.txt命令安装所需的包,若是单机单卡运行,可在相应文件中把模型地址进行更换,随后在cd到basic_demo后运行python cli_demo.py 或者 streamlit run web_demo_streamlit .py 进行本地运行。
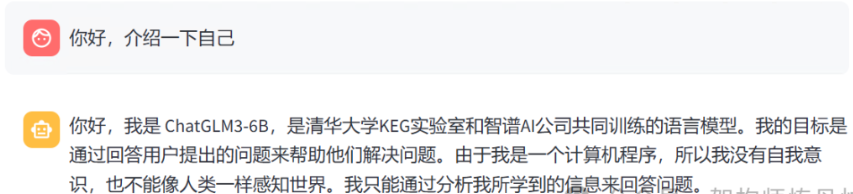
1.3 本地运行ChatGLM3-6b
1.4 使用Lora微调ChatGLM3-6b
首先安装微调需要的包,pip install在finetune_demo中的requirements.txt;其中若是单机单卡的环境可以不安装deepseed。Git的官方微调引导页面
安装完之后可以使用官方开源的服饰广告语推荐的数据集进行微调尝试。先对该数据集进行格式转换,转换为 ChatGLM3 对话格式约定,例如多轮对话格式为:
[
{
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]
import json
from typing import Union
from pathlib import Path
def _resolve_path(path: Union[str, Path]) -> Path:
return Path(path).expanduser().resolve()
def _mkdir(dir_name: Union[str, Path]):
dir_name = _resolve_path(dir_name)
if not dir_name.is_dir():
dir_name.mkdir(parents=True, exist_ok=False)
def convert_adgen(data_dir: Union[str, Path], save_dir: Union[str, Path]):
def _convert(in_file: Path, out_file: Path):
_mkdir(out_file.parent)
with open(in_file, encoding='utf-8') as fin:
with open(out_file, 'wt', encoding='utf-8') as fout:
for line in fin:
dct = json.loads(line)
sample = {'conversations': [{'role': 'user', 'content': dct['content']},
{'role': 'assistant', 'content': dct['summary']}]}
fout.write(json.dumps(sample, ensure_ascii=False) + '\n')
data_dir = _resolve_path(data_dir)
save_dir = _resolve_path(save_dir)
train_file = data_dir / 'train.json'
if train_file.is_file():
out_file = save_dir / train_file.relative_to(data_dir)
_convert(train_file, out_file)
dev_file = data_dir / 'dev.json'
if dev_file.is_file():
out_file = save_dir / dev_file.relative_to(data_dir)
_convert(dev_file, out_file)
convert_adgen('D:/workplaces/github_workplace/ChatGLM3/finetune_demo/data/AdvertiseGen', 'D:/workplaces/github_workplace/ChatGLM3/finetune_demo/data/AdvertiseGen_fix')
1.5 配置微调参数
参数在finetune-demo/configs/lora.yaml 文件中进行配置,具体参数有:

在openai_api_demo/api_server.py 中修改本地大模型权重和向量模型地址,(向量模型可先不设置,本文使用的是M3E模型)。
# set LLM path
MODEL_PATH = os.environ.get('MODEL_PATH', 'D:/workplaces/github_workplace/ChatGLM3/models/chatglm3-6b/')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
# set Embedding Model path
EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', 'D:/workplaces/github_workplace/M3E/m3e-base/')
----------------
if __name__ == "__main__":
# Load LLM
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="cuda").eval()
# load Embedding
embedding_model = SentenceTransformer(EMBEDDING_PATH, device="cuda")
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
使用python api_server.py启动后使用postman工具进行测试。

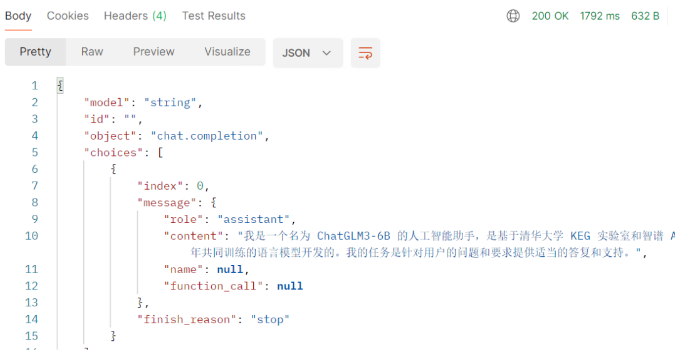
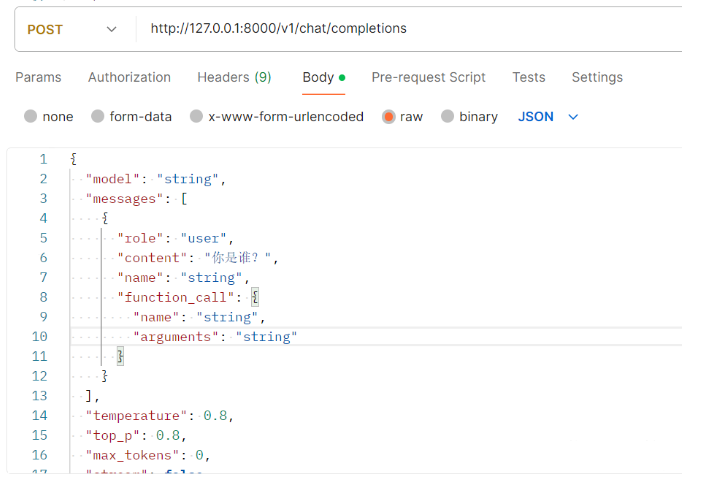
测试请求体:

二、部署M3E模型
M3E 是 Moka Massive Mixed Embedding 的缩写,其中:
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
- Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
- Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
M3E模型使用场景主要是中文,少量英文的情况,多语言使用场景,并且不介意数据隐私的话,建议使用 openai text-embedding-ada-002。
项目地址:moka-ai/m3e-base · Hugging Face,把项目拉下来即可使用。把项目地址在ChatGLM中openai_api_demo/api_server.py相应修改。
三、部署One-API
One-API使用Docker进行快速部署,One-API和FastGPT建议使用Linux系统进行部署,本文采用虚拟机安装了CentOS进行部署。
先安装Docker,Docker部署命令:
# 安装 Docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
# 安装 docker-compose
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
# 验证安装
docker -v
docker-compose -v
One-API部署命令:
由于FastGPT也是使用3000端口,这里One-API改用3080端口。
docker run --name one-api -d --restart always -p 3080:3000 -e TZ=Asia/Shanghai -v /home/data/one-api:/data justsong/one-api
利用docker ps查看One-API是否启动

启动后在本地浏览器打开One-API,地址为本地IP地址+3080端口,登录页初始账号为root,密码123456。
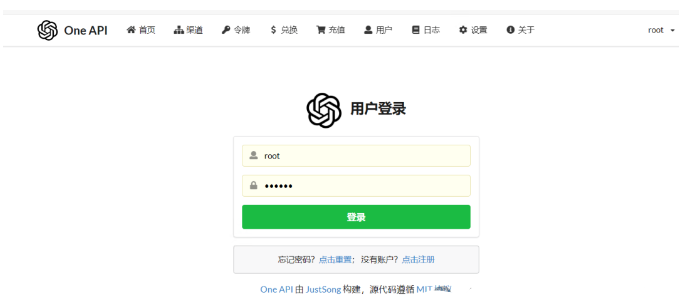
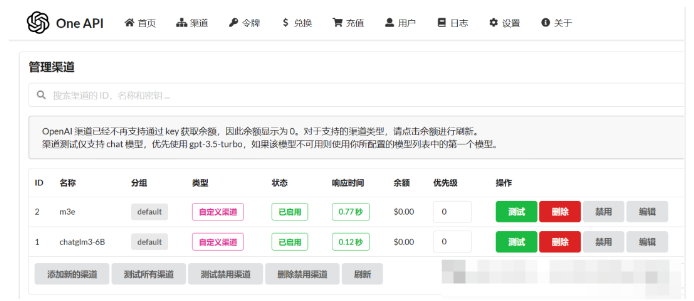
由于是本地部署的模型,需要在“渠道”里配置ChatGLM大模型和M3E向量模型的地址。其中Base URL是能访问大模型的地址,密钥是自定义的,可以随意填写。
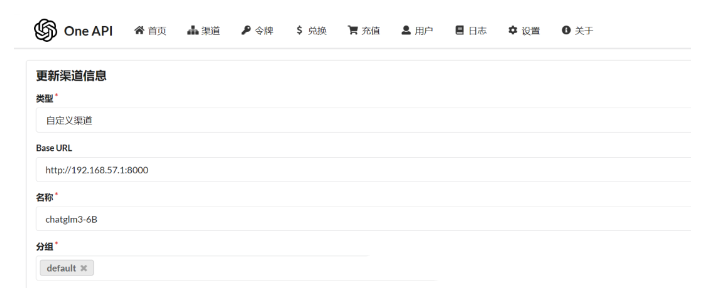
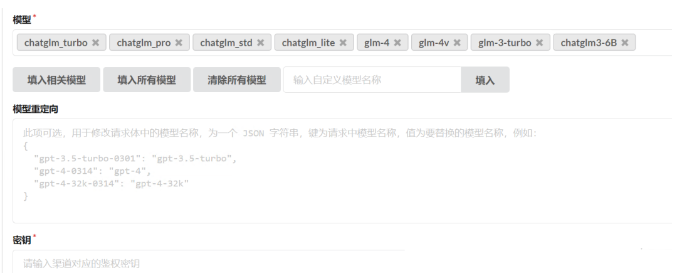
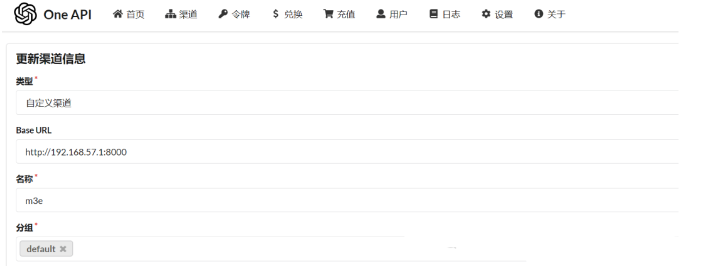
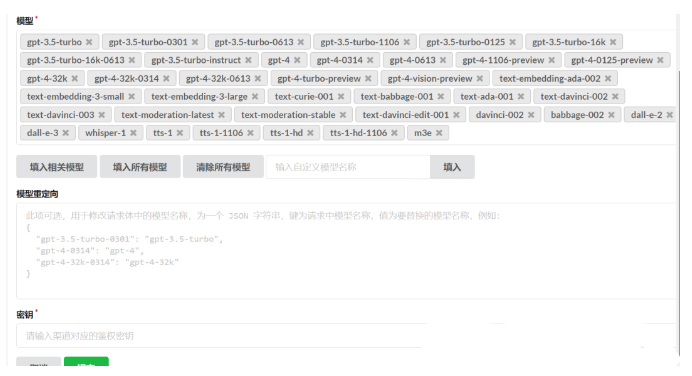
配置好后测试两个模型是否可以调用,点击测试按钮即可。
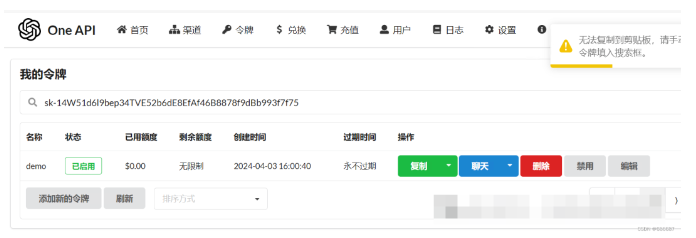
设置令牌,后面在配置FastGPT时会用到。
四、部署FastGPT
astGPT 是一个基于大语言模型的知识库问答系统,它为大模型的私有知识库提供便捷的数据处理、和不同模型调用等功能。
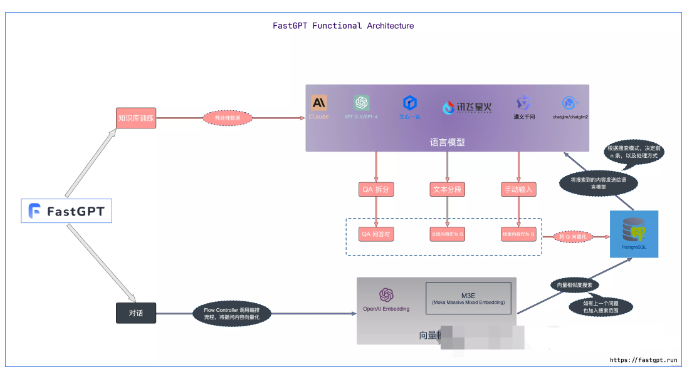
先来了解下 FastGPT 是如何进行知识库检索的。首先了解几个基本概念:
- 向量:将人类直观的语言(文字、图片、视频等)转成计算机可识别的语言(数组)。
- 向量相似度:两个向量之间可以进行计算,得到一个相似度,即代表:两个语言相似的程度。
- 语言大模型的一些特点:上下文理解、总结和推理。
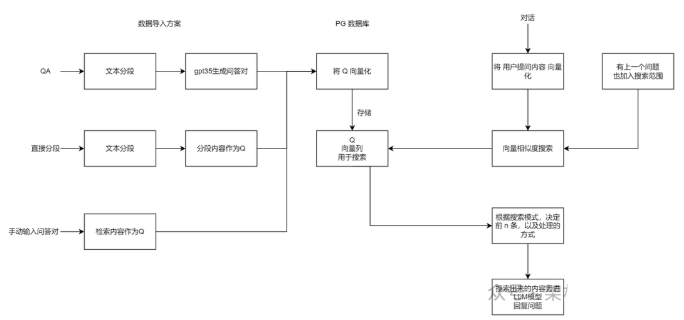
结合上述 3 个概念,便有了 “向量搜索 + 大模型 = 知识库问答” 的公式。下图是 FastGPT V3 中知识库问答功能的完整逻辑:
FastGPT本文在Linux系统下使用Docker进行部署,目前这也是官方推荐的部署方式,官网介绍链接
依次执行下面命令,创建 FastGPT 文件并拉取docker-compose.yml和config.json,执行完后目录下会有 2 个文件。
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
接下来修改docker-compose.yml文件:
主要修改fastgpt/environment下的OPENAI_BASE_URL和CHAT_API_KEY
前者填入One-API的地址和端口号,后者填写设置好的令牌口令。数据库的账号密码可以后面再重新设定。
fastgpt:
container_name: fastgpt
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.7 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.7 # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
restart: always
environment:
# root 密码,用户名为: root。如果需要修改 root 密码,直接修改这个环境变量,并重启即可。
- DEFAULT_ROOT_PSW=1234
# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://192.168.57.129:3080/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-14W51d6l9bep34TVE52b6dE8EfAf46B8878f9dBb993f7f75
# 数据库最大连接数- DB_MAX_LINK=30 # 登录凭证密钥
- TOKEN_KEY=any
# root的密钥,常用于升级时候的初始化请求
- ROOT_KEY=root_key
# 文件阅读加密
- FILE_TOKEN_KEY=filetoken
# MongoDB 连接参数. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg 连接参数
- PG_URL=postgresql://username:password@pg:5432/postgres
volumes:
- ./config.json:/app/data/config.json
- ./fastgpt/tmp:/app/tmp
networks:
fastgpt:
同时修改config.json文件:
主要修改“llmModels”键值对中“model”和“name”的名字和其它需要的配置,如果不用其它的模型,保留这样一个字典就行,同时也要修改一下向量模型 "vectorModels"的“model”和“name”。
{
"systemEnv": {
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"model": "chatglm3-6B", // 模型名
"name": "chatglm3-6B", // 别名
"maxContext": 16000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 13000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0,
"censor": false,
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig":{} // LLM默认配置,可以针对不同模型设置特殊值(比如 GLM4 的 top_p
},
],
"vectorModels": [
{
"model": "m3e",
"name": "m3e",
"charsPointsPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100,
"defaultConfig":{} // 默认配置。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}
修改后启动容器:
在 docker-compose.yml 同级目录下执行。同时确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
# 启动容器
docker-compose pull
docker-compose up -d
用docker ps查看是否正常启动

若oneapi没正常启动
# 等待10s,OneAPI第一次总是要重启几次才能连上
Mysqlsleep 10
# 重启一次oneapi(由于OneAPI的默认Key有点问题,不重启的话会提示找不到渠道,临时手动重启一次解决,等待作者修复)
docker restart oneapi
正常启动后在浏览器上访问fastgpt,本地ip:3000端口。
账号root,初始密码1234。创建应用后即可测试是否正常使用本地部署的大模型。

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









