



无需编码,开源、免费、可商用
项目概述

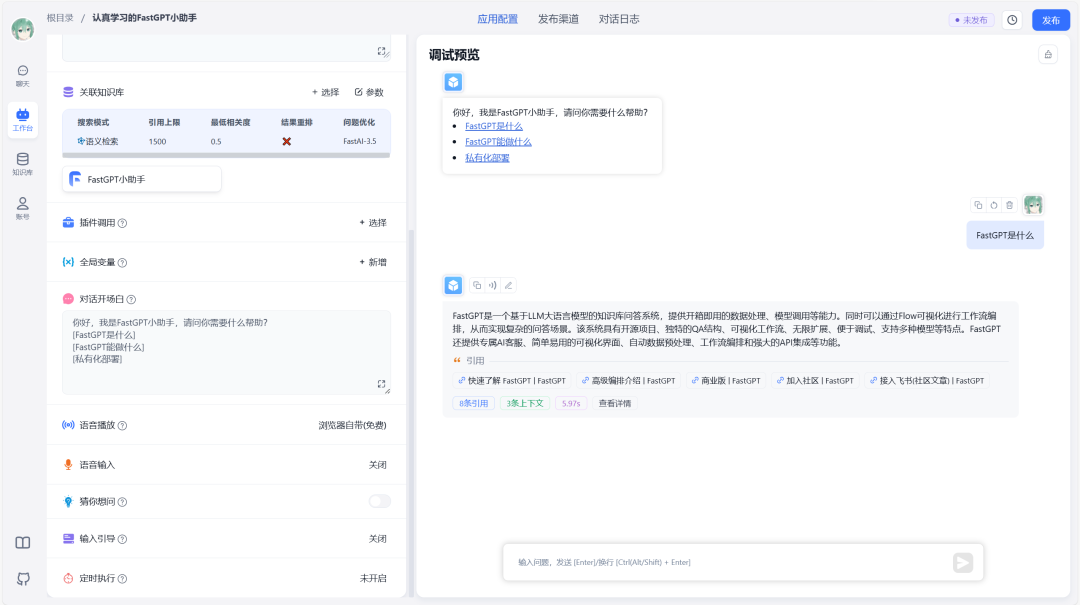
FastGPT 是一个基于大语言模型的开源知识库平台,40 万+ 开发者与企业正用它快速构建 RAG问答系统。它把「数据处理 → 向量化 → 检索 → 回答」整条链路做成了可视化拖拽流程,真正做到「开箱即用」,让你把精力花在业务场景而非底层实现上。
问题背景
企业内部知识散落各处:客服话术、产品文档、规章制度、技术 Wiki……
传统做法需要:
-
- 人工整理 → 耗时耗力
-
- 训练专属模型 → 成本高、周期长
-
- 写代码串流程 → 门槛高、维护难
FastGPT 的出现,让非工程师也能在半小时内完成从原始文档到可商用问答 API 的闭环。
功能亮点
| 能力 | 一句话亮点 | 典型场景 |
|---|---|---|
| 多格式数据导入 | 支持 Word / PDF / Excel / Markdown / 网页一键同步 | 把整站帮助文档变成知识库 |
| 可视化 Flow | 拖拽节点即可编排复杂 LLM 工作流 | 先做意图识别→再路由到不同知识库→最后调用函数 |
| 多模型兼容 | 任何兼容 OpenAI API 的模型都能接 | 国内 Moonshot、国外 GPT-4o、私有化 Llama3 |
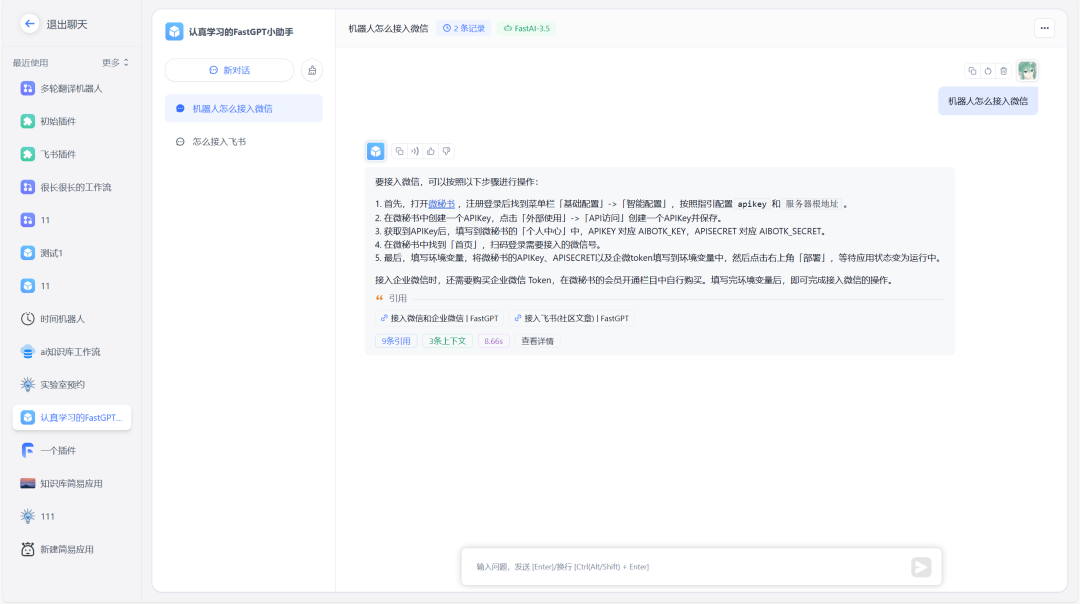
| API & Webhook | 一行代码嵌入现有系统 | 企业微信机器人、飞书群助手、客服工单 |
| 调试 & 日志 | 可追溯每一次检索与回答 | 精准定位幻觉来源 |
| 商用友好 | Apache-2.0 协议,可闭源二次开发 | SaaS 化、私有化部署均支持 |
技术细节(30 秒速览)
- • 检索层:混合检索(向量 + 全文 + 问答分段)
- • 向量化:内置 text-embedding-ada-002 / bge-large 等模型,也可自定义
- • 安全沙箱:文件解析与代码执行隔离,防止 Prompt 注入
- • 扩展点:支持自定义插件节点(Python/JavaScript),无缝对接内部系统
安装与使用
最快体验(Docker 一条命令)
docker run -d --name fastgpt -p 3000:3000 ghcr.io/labring/fastgpt:latest
浏览器打开 http://localhost:3000 即可开始创建知识库。
生产部署
官方提供 Sealos 一键模板与 Kubernetes Helm Chart,支持 GPU 自动扩缩、对象存储挂载、HTTPS 证书自动申请。
应用案例
| 公司/团队 | 场景 | 效果 |
|---|---|---|
| 某跨境电商 | 客服 FAQ 机器人 | 回答准确率 92%,人力节省 60% |
| 高校 AI 协会 | 内部课程问答 | 3 小时上线,覆盖 2000+ 课件 |
| 医疗 SaaS 厂商 | 药品知识检索 | 私有化部署,满足合规要求 |
项目地址
GitHub: https://github.com/labring/FastGPT
在线 Demo: https://fastgpt.io
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









