



1、基本介绍
GraphRAG通过利用大模型从原始文本数据中提取知识图谱来满足跨上下文检索的需求。该知识图将信息表示为互连实体和关系的网络,与简单的文本片段相比,提供了更丰富的数据表示。这种结构化表示使 GraphRAG 能够擅长回答需要推理和连接不同信息的复杂问题。
具体来看,GraphRAG 定义了一个标准化数据模型,整体框架由几个关键组件组成,分别用于表示文档、TextUnit、实体、关系和社区报告等实体。像传统RAG一样,GraphRAG 过程也涉及两个主要阶段:索引和查询。我们依次展开来进行讨论。
在索引(Indexing)过程中,输入的文本被分为可管理的块,称为TextUnits 。然后大模型从这些文本单元中提取实体、关系和声明,形成知识图。完整的Indexing流程如下图所示:
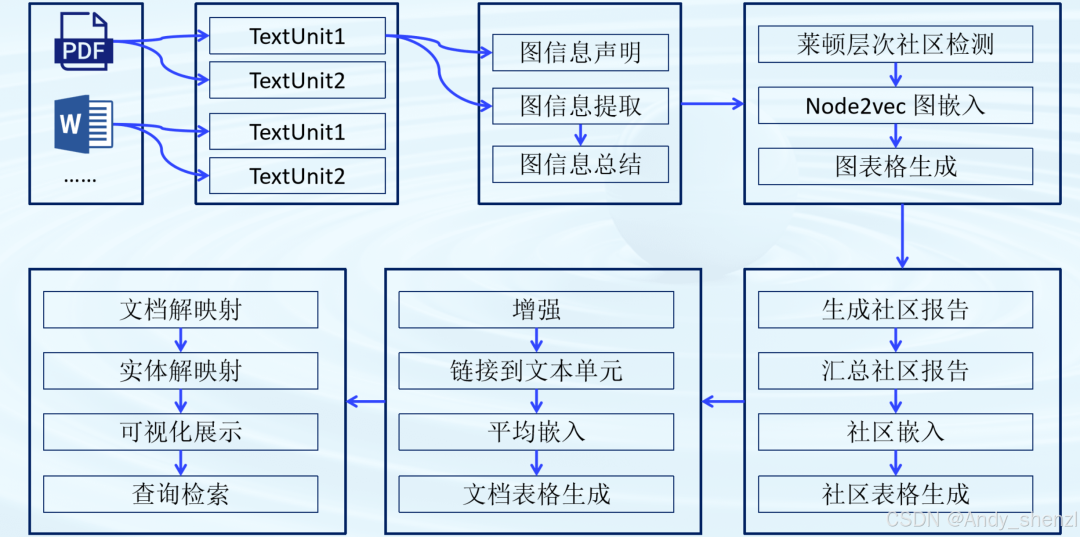
在这里插入图片描述
2、流程及原理解析
Step 1. 文本切分(Text Unit Splitting)
- GraphRAG 需要处理的是一大篇文档或语料库。首先,它会将这些文档切分为 Text Units(文本单元),这些 Text Units 是对输入文档的细分,通常是按照段落、句子或固定长度的文本块来进行切分。
- 这样做的目的是为了便于对文本内容进行分析,尤其是当需要进行 实体识别 和 关系抽取 时,能够精准地关联到文档中的具体上下文。
Step 2. 实体识别(Entity Extraction)
- 在文本切分之后,GraphRAG 会使用 大模型(如 OpenAI GPT 或其他 LLM) 对每个 Text Unit 进行处理,提取其中的 实体。这些实体通常是指文档中出现的人物、地点、组织、概念等信息。
- 实体识别的目的是构建 实体图谱(Entity Graph),将所有实体提取出来并为后续的关系挖掘和查询做准备。
Step 3. 关系挖掘(Relationship Extraction)
- 关系挖掘是从文本中识别出实体之间的 关系,例如:谁与谁有关联、某个实体与另一个实体之间的关系是“属于”、“合作”、“对立”等。
- 通过这种关系提取,GraphRAG 可以构建 关系图谱(Relationship Graph),这些关系将有助于后续的 查询引擎 理解和推理。
Step 4. 文本嵌入(Text Embedding)
- 在识别了文本中的实体和关系之后,GraphRAG 会利用 嵌入模型(如 OpenAI 的 Embedding 模型)将文本和实体表示为向量(vectors)。这些向量不仅包括了文本的语义信息,还能为后续的检索和查询提供高效的表示。
- 这些嵌入向量将存储在 向量数据库(如 LanceDB)中,为查询时提供快速的相似度搜索。
Step 5. 构建社区和层级结构(Community and Hierarchical Clustering)
- 通过使用 图谱聚类算法(如 Leiden 算法),GraphRAG 会将不同的实体和关系分组,形成多个 社区(Community)。这些社区是根据实体之间的相似度或关系的密切程度进行划分的。
- 这种分组帮助 GraphRAG 更好地理解不同知识领域的结构,为查询时提供更具层次性的上下文信息。
Step 6. 生成索引文件(Indexing)
- 完成上述步骤后,所有的 实体、关系、社区报告、文本单元等信息都会存储在磁盘上的 Parquet 文件中。
- 这些索引文件实际上就是构建好的 知识图谱,包括了文本内容、文本中涉及的实体和关系的结构化表示,并且这些文件是为后续的查询引擎和推理过程提供基础。
总的来说GraphRAG 的 索引阶段 是一个 多步骤 的过程,基本流程是:
- 文本切分(Text Units)
- 实体识别(Entity Extraction)
- 关系挖掘(Relationship Extraction)
- 文本嵌入(Text Embedding)
- 社区划分和层级结构(Clustering)
- 生成索引文件(Indexing)
整个过程的目的是将文档中的原始文本转化为可以进行检索和推理的结构化知识图谱。而 实体识别 和 关系挖掘 通常是在文本切分之后进行的,因为需要先确保文本已经切分成足够小的单元才能进行更精细的分析和抽取。
3、本地实现
3.1 使用pip安装graphrag
ounter(line
pip install graphrag
测试的graphrag版本为1.1.0
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
(graphrag) [root@local- graphrag]# pip show graphrag
Name: graphrag
Version: 1.1.0
Summary: GraphRAG: A graph-based retrieval-augmented generation (RAG) system.
Home-page:
Author: Alonso Guevara Fernández
Author-email: alonsog@microsoft.com
License: MIT
Location: /root/anaconda3/envs/graphrag/lib/python3.11/site-packages
Requires: aiofiles, azure-cosmos, azure-identity, azure-search-documents, azure-storage-blob, devtools, environs, fnllm, future, graspologic, httpx, json-repair, lancedb, matplotlib, networkx, nltk, numpy, openai, pandas, pyaml-env, pyarrow, pydantic, python-dotenv, pyyaml, rich, tenacity, tiktoken, tqdm, typer, typing-extensions, umap-learn
Required-by:
3.2 创建检索项目文件夹
ounter(line
mkdir -p ./sushi/input
在input文件夹中上传一个txt文件,该文件为需要创建知识图谱问答的文本文件。 这里以苏轼的百度百科的介绍内容为例,创建图谱问答。
3.3 初始化项目文件
ounter(lineounter(line
(graphrag) [root@local-7 graphrag]# graphrag init --root ./sushi
Initializing project at /root/szl/project/graphrag/sushi
初始化后,会在创建的检索项目文件夹下出现两个文件,一个是.env文件,和一个settings.yaml文件,是环境变量的设置文件:
- 打开.env文件,填写openai API-KEY

- 打开setting.yaml文件,填写模型名称和反向代理地址
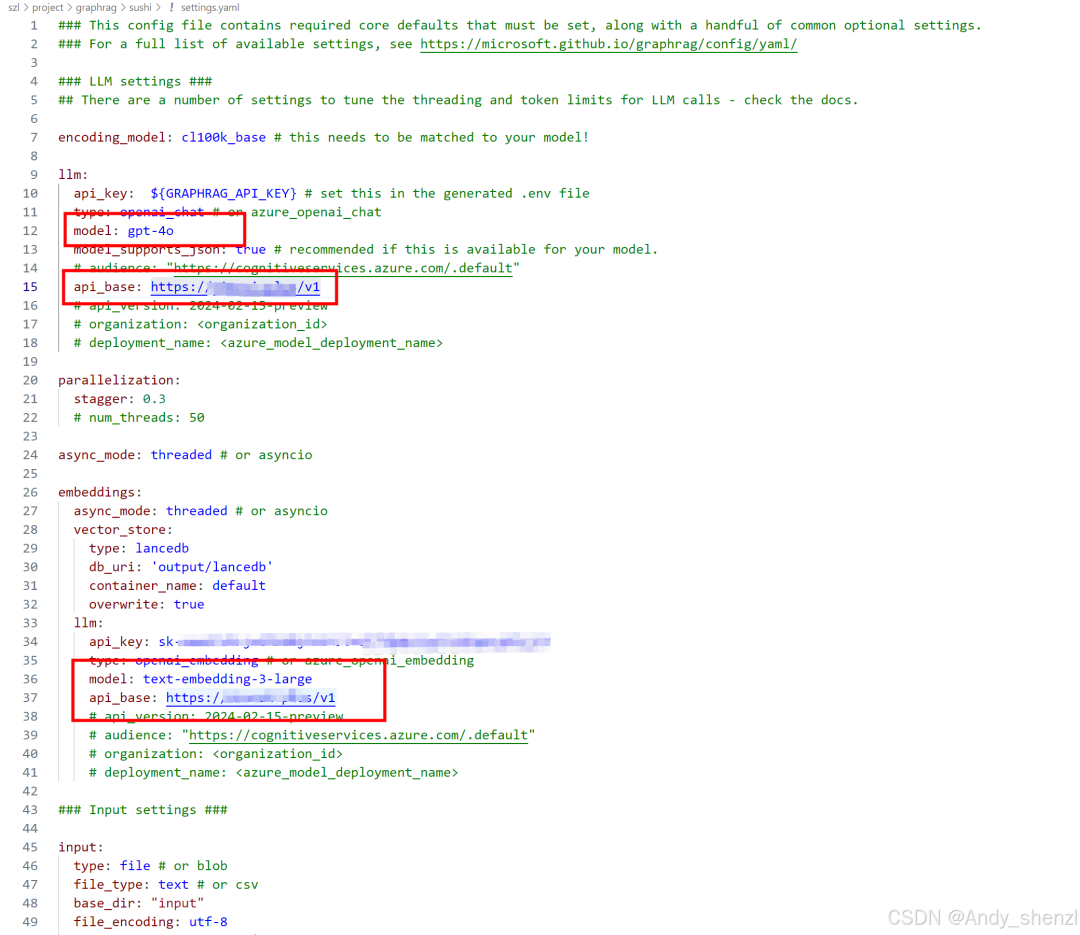
3.4 GraphRAG索引Indexing过程执行
ounter(line
(graphrag) [root@local-7 graphrag]# graphrag index --root ./sushi
运行过程如下 整个过程会比较长,与input里面的文件大小有关 输出:
整个过程会比较长,与input里面的文件大小有关 输出:
ounter(line
All workflows completed successfully.
表示创建完成
3.5 输出结果信息
GraphRAG在索引阶段构建的知识图谱的确是以 Parquet 格式保存的!索引阶段的输出文件中,Parquet 文件存储了知识图谱的各个核心组成部分,例如实体、关系、社区信息以及文本单元等。这些文件共同组成了一个完整的知识图谱。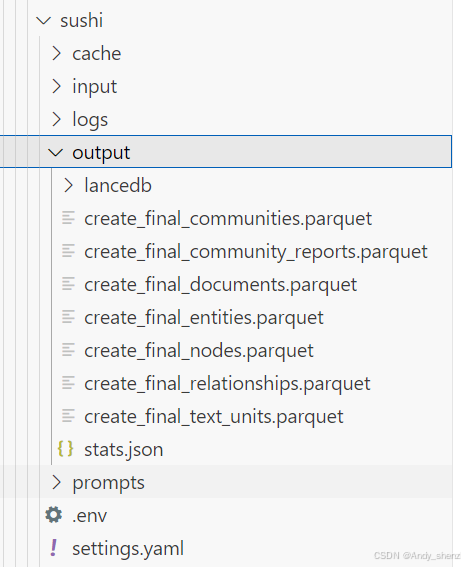 索引阶段的主要输出内容如下:
索引阶段的主要输出内容如下:
- 实体表(Nodes Table)
- 文件名:create_final_nodes.parquet
- 内容:知识图谱中的实体节点(例如:人、地点、组织)。
- 包含信息:
- 实体的名称(如 “John Doe”)。
- 实体的类别(如 “PERSON”, “ORGANIZATION”, “LOCATION”)。
- 与社区相关的信息(如实体所属的社区)。
- 实体的度数(degree),表示该实体在图谱中的连接数。
- 关系表(Relationships Table)
- 文件名:create_final_relationships.parquet
- 内容:知识图谱中实体之间的关系(即图谱的边)。
- 包含信息:
- 两个实体之间的关系描述(例如 “works for”, “lives in”)。
- 关系的强度(数值化,用于衡量关系的显著性或重要性)。
- 嵌入向量表(Entity Embedding Table)
- 文件名:create_final_entities.parquet
- 内容:实体的语义嵌入,用于表示实体的语义信息。
- 用途:支持语义搜索(通过嵌入计算实体之间的相似性)。
- 社区报告表(Community Reports Table)
- 文件名:create_final_community_reports.parquet
- 内容:社区的摘要信息。
- 用途:支持全局搜索(通过社区信息回答关于数据集整体的问题)。
- 文本单元表(Text Units Table)
- 文件名:create_final_text_units.parquet
- 内容:被切分的原始文本单元(TextUnits)。
- 用途:将知识图谱和原始文本结合,为 LLM 提供上下文支持。
- 社区表(Community Table)
- 文件名:create_final_Communities.parquet
- 内容:每个社区基本情况。
- 文件表(Documents Table)
- 文件名:create_final_documents.parquet
- 内容:用于记录所有参与知识图谱构建的文件情况。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















基本原理介绍(上)&spm=1001.2101.3001.5002&articleId=155304757&d=1&t=3&u=7402555329f542a18c48584052c57af9)
 1521
1521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









