



1、模型结构:
Qwen2.5-14B-Chat和Qwen2.5-14B-Base模型结构一样,与Qwen1.5-14B-Chat代码也一样,不同点在于Qwen2.5-14B-Chat是48层transformer,比Qwen1.5-14B多8层,比之前的更深,模型结构如下:
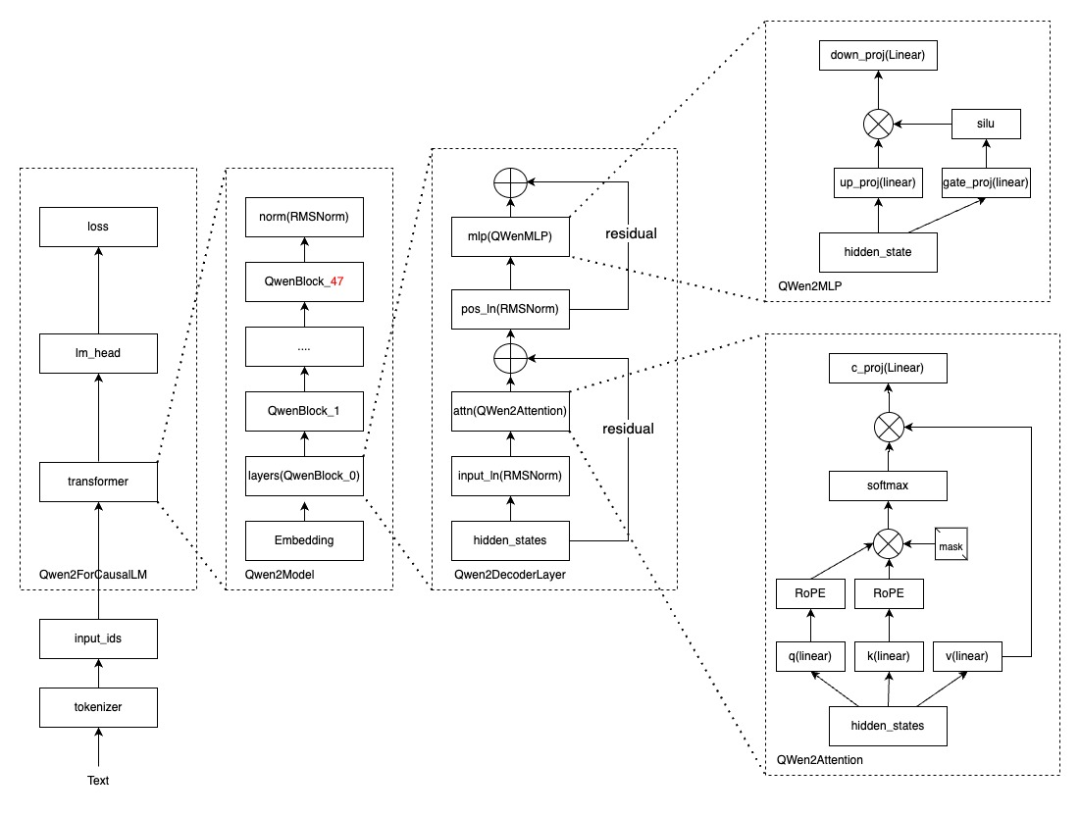
模型代码链接:
https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen2/modeling_qwen2.py
2、主干模块Qwen2ForCausalLM,模型入口
模型结构中,每个虚线框的名字对应代码的类名,最外层的Qwen2ForCausalLM,继承于Qwen2PreTrainedModel类,而Qwen2PreTrainedModel主要是在transformer的类(PreTrainedModel)上进行了一个简单的封装,无重要逻辑代码,Qwen2ForCausalLM主要实现如下:
class Qwen2ForCausalLM(Qwen2PreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.model = Qwen2Model(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
模型初始化__init__方法中,主要初始化Qwen2Model和输出层lm_head线性层,lm_head层的输入是size是hidden_size,输出是词表大小,主要作用就是将模型的输出,映射到token,输出的token会经过tokenizer的decode得到文本(英文就是单词,中文就是汉字)。
class Qwen2ForCausalLM(Qwen2PreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
num_logits_to_keep: int = 0,
)
-> Union[Tuple, CausalLMOutputWithPast]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
cache_position=cache_position,
)
hidden_states = outputs[0]
if labels is None and not is_torchdynamo_compiling():
logger.warning_once(
"Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)"
)
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
# TODO: remove the float() operation in v4.46
logits = self.lm_head(hidden_states[:, -num_logits_to_keep:, :]).float()
loss = None
if labels is not None:
# Upcast to float if we need to compute the loss to avoid potential precision issues
logits = logits.float()
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
shift_logits = shift_logits.view(-1, self.config.vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
loss = loss_fct(shift_logits, shift_labels)
if not return_dict:
output = (logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
forword中,有几个稍微有点绕的参数,稍微解释下,一个是num_logits_to_keep
解释:
lm_head: 语言模型的头部是模型的最后一层,负责将模型内部的表示转换为词汇表上的概率分布。简单来说,它将模型学到的信息转化为对下一个词的预测。
num_logits_to_keep: 这个参数决定在采样下一个词的时候,保留多少个最高概率的词作为候选。
原理:
语言模型处理输入序列后,lm_head 会输出一个logits向量,表示词汇表中每个词的得分。
通常,我们会将 logits 向量通过 softmax 函数转换为概率分布。
在生成文本时,我们并不总是选择概率最高的词。为了增加文本的多样性,可以使用采样策略。
num_logits_to_keep 参数就限制了采样范围。如果设置为5,那么只会从概率最高的5个词中进行采样。
作用:
控制输出多样性: num_logits_to_keep 越小,采样范围越窄,生成的文本可能更稳定、更接近高概率的词,但多样性会降低。
平衡创造力与准确性: 较大的 num_logits_to_keep 允许模型探索更多低概率词,增加文本的创造性和意外性,但也可能导致语法错误或不连贯的句子。
例子:
假设词汇表是 ["我", "爱", "学习", "机器学习", "人工智能"],lm_head 输出的 logits 向量是 [0.1, 0.2, 0.3, 0.8, 0.6]。
如果 num_logits_to_keep 设置为 2,那么只会考虑 "机器学习" 和 "人工智能" 两个词进行采样。
如果 num_logits_to_keep 设置为 5,那么所有词都会被考虑。
希望这个解释能够帮助你理解 lm_head 和 num_logits_to_keep 的含义。
另一个是loss计算:logits中的shift_logits,
shift_logits[..., :-1, :]:
shift_logits 是一个多维张量,这里使用了省略号 ... 来表示所有前面的维度。
:-1 表示取最后一个维度(通常是序列长度)的所有元素,除了最后一个元素。
: 表示取其他所有维度的所有元素。
这行代码的效果是将 shift_logits 在最后一个维度上向左移动一位,丢弃最后一个元素。
shift_logits[..., 1:]:
与 shift_logits 类似,labels 也是一个多维张量。
1: 表示取最后一个维度从第二个元素开始的所有元素。
这行代码的效果是将 labels 在最后一个维度上向右移动一位,丢弃第一个元素。
.contiguous():
contiguous() 方法用于确保张量在内存中是连续存储的。
在进行切片操作后,新生成的张量可能引用原始张量中不连续的内存块,使用 .contiguous() 方法可以将这些内存块重新排列,使张量元素在内存中连续存储。
代码目的:
import torch
logits = torch.tensor([[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[10, 11, 12]]])
labels = torch.tensor([[1, 2],
[3, 4]])
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
print(f"shift_logits: \n{shift_logits}")
print(f"shift_labels: \n{shift_labels}")
输出:
shift_logits:
tensor([[[1, 2],
[4, 5]],
[[7, 8],
[10, 11]]])
shift_labels:
tensor([[2],
[4]])
可以看到,shift_logits 相对于 logits 缺少了最后一个元素,而 shift_labels 相对于 labels 缺少了第一个元素,并且两者都保持了在内存中的连续存储。
3、Qwen2Model模块
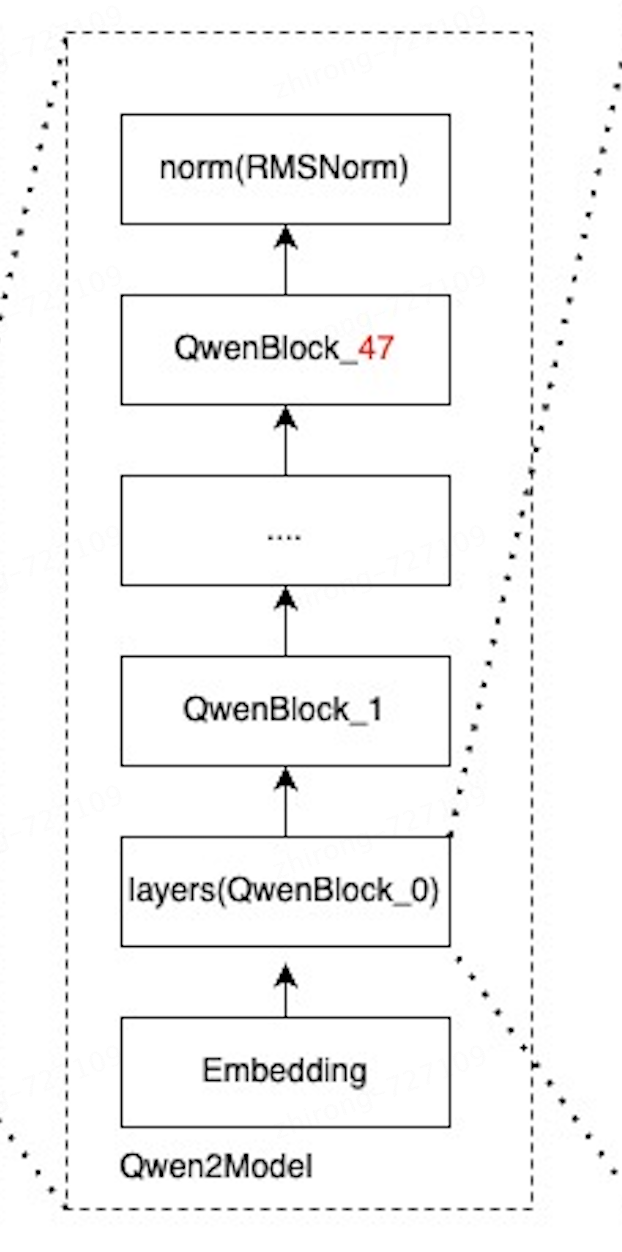
Qwen2Model与Qwen1.5的主要区别也在这儿,这是48层
class Qwen2Model(Qwen2PreTrainedModel):
"""
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Qwen2DecoderLayer`]
Args:
config: Qwen2Config
"""
def __init__(self, config: Qwen2Config):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self._attn_implementation = config._attn_implementation
self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.rotary_emb = Qwen2RotaryEmbedding(config=config)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
初始化方法中,主要就是初始化token词表的embedding、transformer的layers和归一化层norm的Qwen2RMSNorm,forward中的核心代码:
class Qwen2Model(Qwen2PreTrainedModel):
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
) -> Union[Tuple, BaseModelOutputWithPast]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
# ....
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
if cache_position is None:
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
cache_position = torch.arange(
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
)
if position_ids is None:
position_ids = cache_position.unsqueeze(0)
causal_mask = self._update_causal_mask(
attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
)
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
decoder_layer.__call__,
hidden_states,
causal_mask,
position_ids,
past_key_values,
output_attentions,
use_cache,
cache_position,
position_embeddings,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=causal_mask,
position_ids=position_ids,
past_key_value=past_key_values,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
if output_attentions:
all_self_attns += (layer_outputs[1],)
hidden_states = self.norm(hidden_states)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
主要从input_ids变为inputs_embeds,position_ids位置编码的构建(之前序列长度开始past_seen_tokens到past_seen_tokens + inputs_embeds.shape[1]当前序列长度结束),最后一个就是causal_mask(主要采用torch.triu(causal_mask, diagonal=1)创建一个上三角矩阵,同时把padding部分的逻辑加上)构建
4、Qwen2DecoderLayer部分
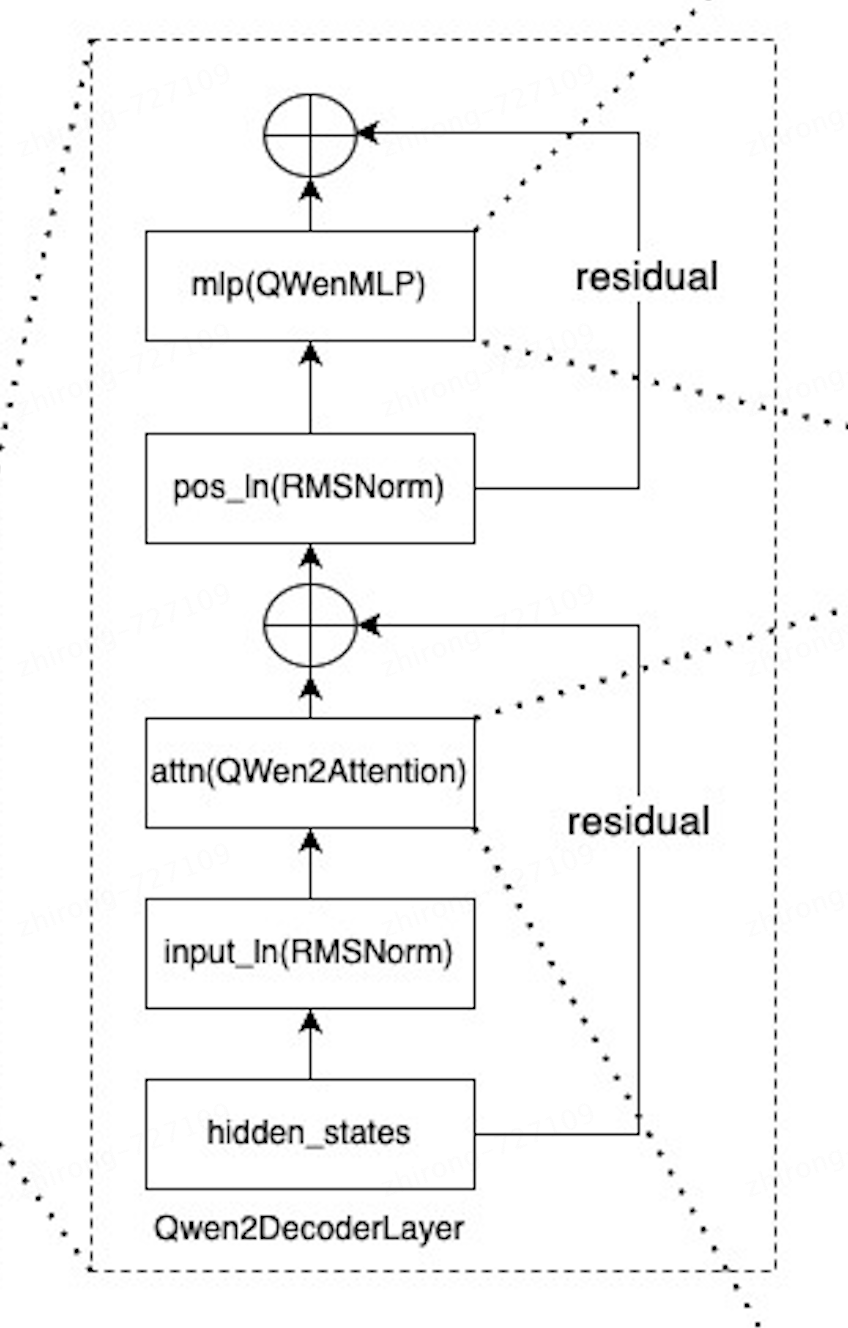
初始化如下:
class Qwen2DecoderLayer(nn.Module):
def __init__(self, config: Qwen2Config, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
if config.sliding_window and config._attn_implementation != "flash_attention_2":
logger.warning_once(
f"Sliding Window Attention is enabled but not implemented for `{config._attn_implementation}`; "
"unexpected results may be encountered."
)
self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
self.mlp = Qwen2MLP(config)
self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
QWEN2_ATTENTION_CLASSES中包含了Qwen2Attention、Qwen2FlashAttention2和Qwen2SdpaAttention注意力机制算法,
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
**kwargs,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, sequence_length)` where padding elements are indicated by 0.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
(see `past_key_values`).
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
Indices depicting the position of the input sequence tokens in the sequence.
position_embeddings (`Tuple[torch.FloatTensor, torch.FloatTensor]`, *optional*):
Tuple containing the cosine and sine positional embeddings of shape `(batch_size, seq_len, head_dim)`,
with `head_dim` being the embedding dimension of each attention head.
kwargs (`dict`, *optional*):
Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
into the model
"""
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
)
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights,)
if use_cache:
outputs += (present_key_value,)
return outputs
hidden_states会进过第一个block,过rmslayernorm、attention,之后加残差hidden_states = residual + hidden_states,再经过layernorm,进入mlp,最后再残差hidden_states = residual + hidden_states
5、Attention模块:

最核心的模块,
class Qwen2Attention(nn.Module):
"""
Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
and "Generating Long Sequences with Sparse Transformers".
"""
def __init__(self, config: Qwen2Config, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
if layer_idx is None:
logger.warning_once(
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
"when creating this class."
)
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.rope_theta = config.rope_theta
self.is_causal = True
self.attention_dropout = config.attention_dropout
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
self.rotary_emb = Qwen2RotaryEmbedding(config=self.config)
主要初始化q、k、v及输出的映射线性Linear层,另外就是RoPE的位置位置编码Embedding层
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Cache] = None,
output_attentions: bool = False,
use_cache: bool = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
if position_embeddings is None:
logger.warning_once(
"The attention layers in this model are transitioning from computing the RoPE embeddings internally "
"through `position_ids` (2D tensor with the indexes of the tokens), to using externally computed "
"`position_embeddings` (Tuple of tensors, containing cos and sin). In v4.46 `position_ids` will be "
"removed and `position_embeddings` will be mandatory."
)
cos, sin = self.rotary_emb(value_states, position_ids)
else:
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position} # Specific to RoPE models
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
# repeat k/v heads if n_kv_heads < n_heads
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attention_mask is not None: # no matter the length, we just slice it
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
q、k、v经过线性层映射后,k和v分别加上position embeding,算attn_weights,这里有一个技巧attn_weights = attn_weights + causal_mask,不是采用乘法的方式(减少计算量),而是采用加法,causal_mask是一个上三角矩阵,里面存储一个非常小的数,加上这个数后attn_weights中上三角矩阵中的值也会非常小,再经过softmax后,attn_weights也很小,对于的物理意义在同一句话中,保证模型了偷看看不到未来的信息,都是用之前的信息预估下一个token,这里最后再经过线性层o_proj输出,保持维度一致。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 3334
3334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









