




LlamaFactory 前言
LLaMA Factory 是一个用于微调大型语言模型的强大工具,特别是针对 LLaMA 系列模型。
可以适应不同的模型架构和大小。
支持多种微调技术,如全参数微调、LoRA( Low-Rank Adaptation )、QLoRA( Quantized LoRA )等。
还给我们提供了简单实用的命令行接口。
支持多 cpu 训练,多任务微调,还有各种内存优化技术,如梯度检查点、梯度累积等。
支持混合精度训练,提高训练效率。
本文不再赘述 LlamaFactory 的安装过程
LlamaFactory参数基本设置
打开我们 LlamaFactory 的 web 运行界面,进入根目录执行下列命令:
llamafactory-cli webui
看到下列界面

在浏览器打开我们开启的 webui 界面 http://127.0.0.1:7860:
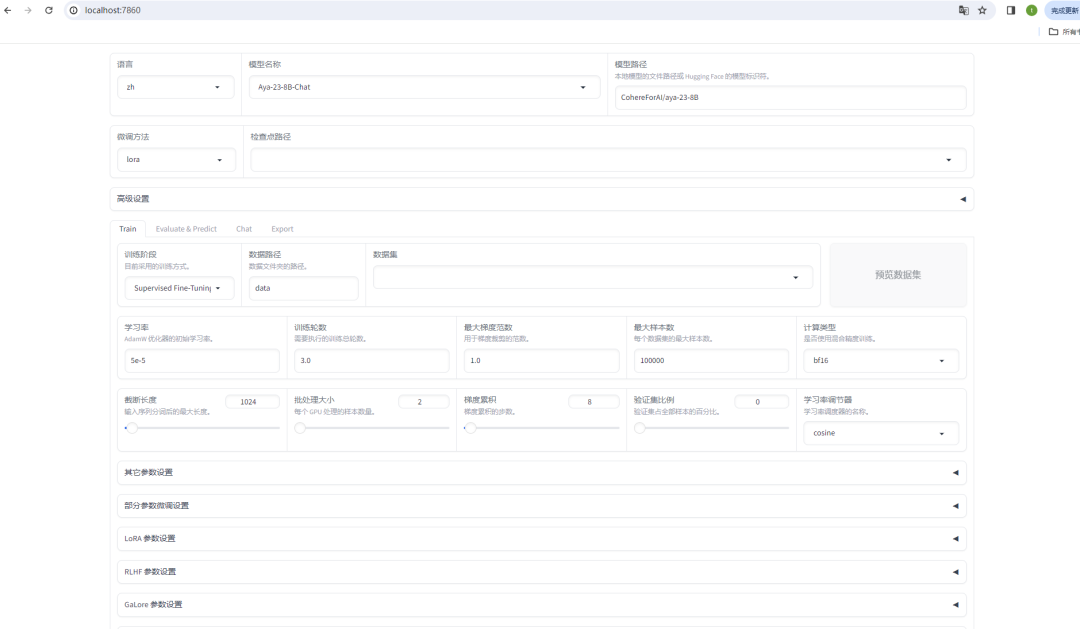
我们依次来解释每个参数的选择:
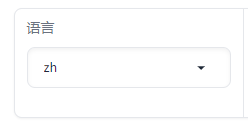
这里是语言选择
选择 zh 即可。
模型选择选择适合自己的模型,这里都会从 Hugging Face 里面下载,

这一步是自定义路径一般就用选择好的默认路径即可。

微调方法:
这里有三种,full全参数微调, Freeze(冻结部分参数) LoRA(Low-Rank Adaptation),还有 QLoRA 等。
全参数微调可以最大的模型适应性,可以全面调整模型以适应新任务。通常能达到最佳性能。
Freeze 训练速度比全参数微调快,会降低计算资源需求。
LoRA :显著减少了可训练参数数量,降低内存需求,训练速度快,计算效率高。还可以为不同任务保存多个小型适配器,减少了过拟合风险。
QLoRA训练速度跟 LoRA 差不多,基本保持了 LoRa 的优势,会进一步减少内存使用。
综合速度,灵活性考虑 选择 LoRA 或者 QLorRA 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









