




Ollama
1.安装Ollama
访问Ollama官网下载Ollama安装包,或者可以访问百度网盘地址:https://pan.baidu.com/s/1kOcyzb3QGMnJOoIVXka4NA?pwd=ziyu ,提取码是ziyu,双击安装包OllamaSetup.exe

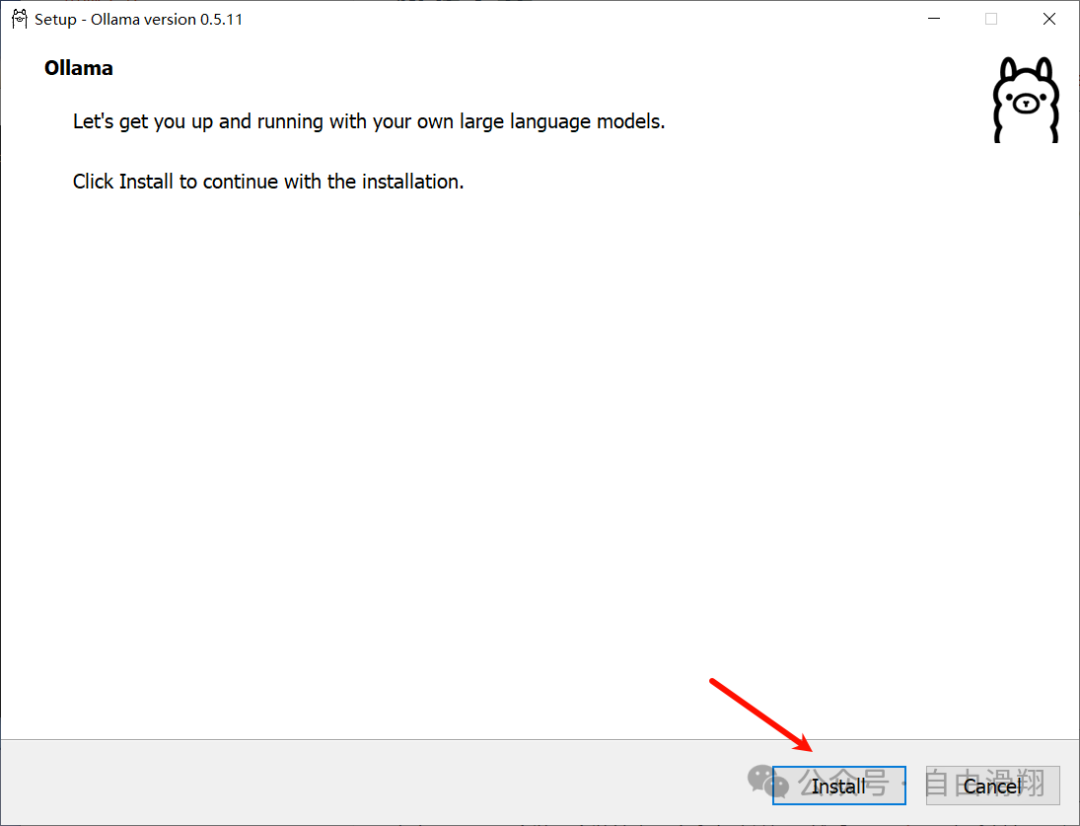
点击Install即可一键安装。
2.验证Ollama
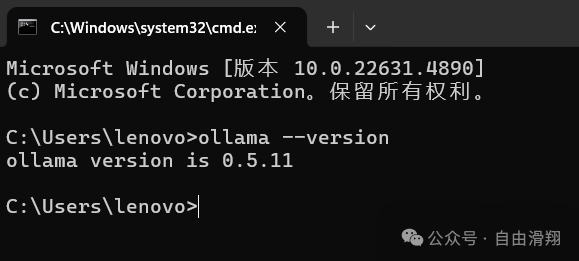
打开命令行界面。
命令
ollama --version
DeepSeek
1.安装DeepSeek
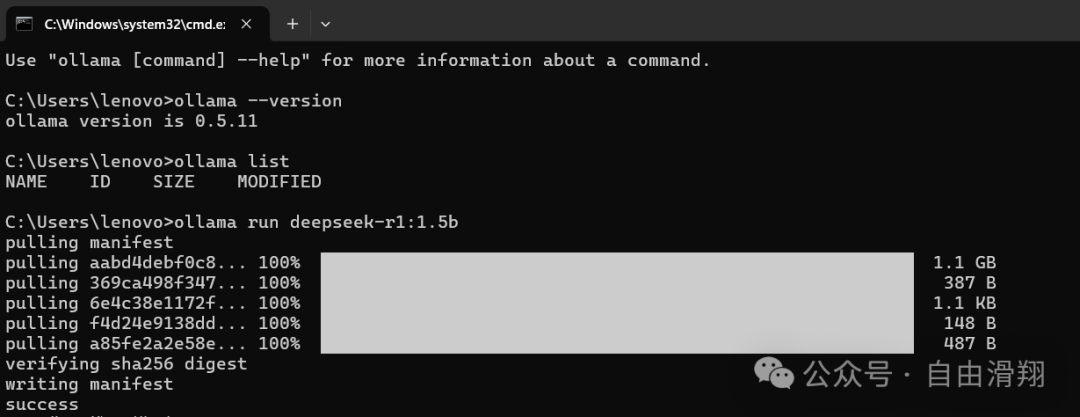
在命令行界面输入
ollama run deepseek-r1:1.5b
可以快速安装deepseek-r1:1.5b模型,结果如下图所示。
2.验证DeepSeek
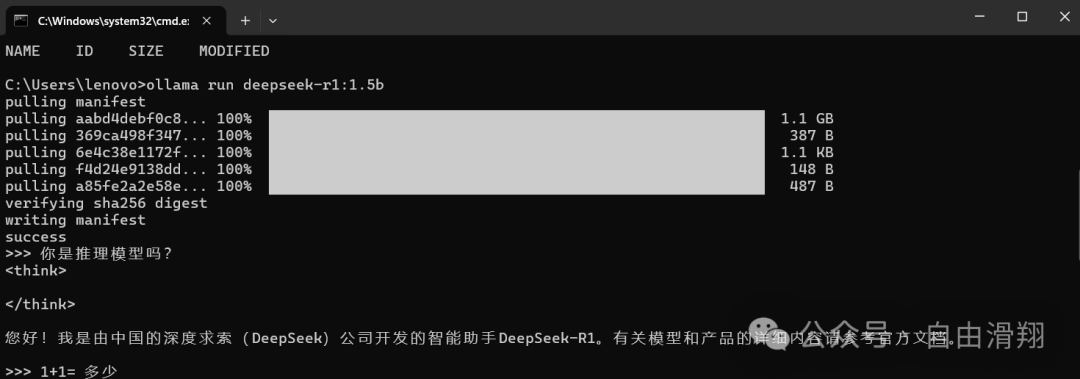
输入“你是推理模型吗”来验证,成功结果如下所示。
AnythingLLM
1.安装AnythingLLM
访问AnythingLLM官网下载AnythingLLM安装包,或者可以访问百度网盘地址:https://pan.baidu.com/s/1kOcyzb3QGMnJOoIVXka4NA?pwd=ziyu ,提取码是ziyu,双击AnythingLLMDesktop.exe开始安装
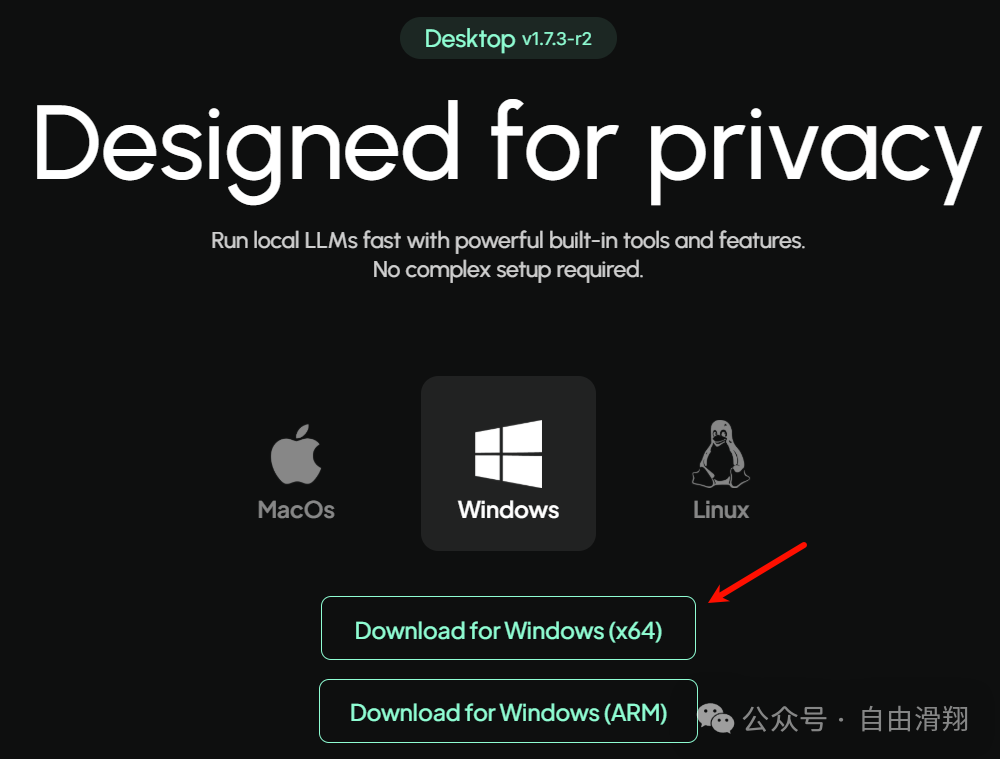
点击下一步。
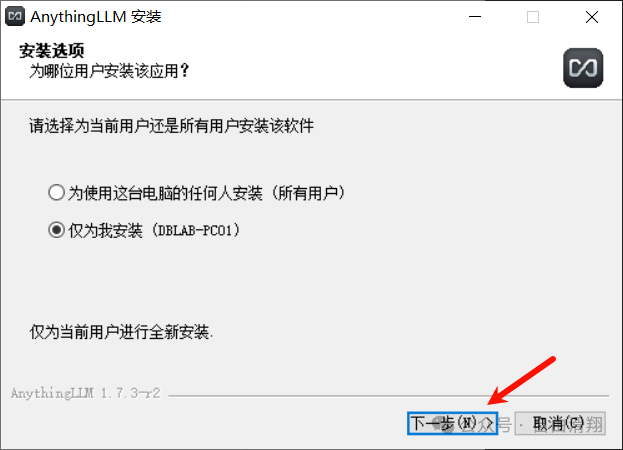
然后选择安装位置然后点击安装。
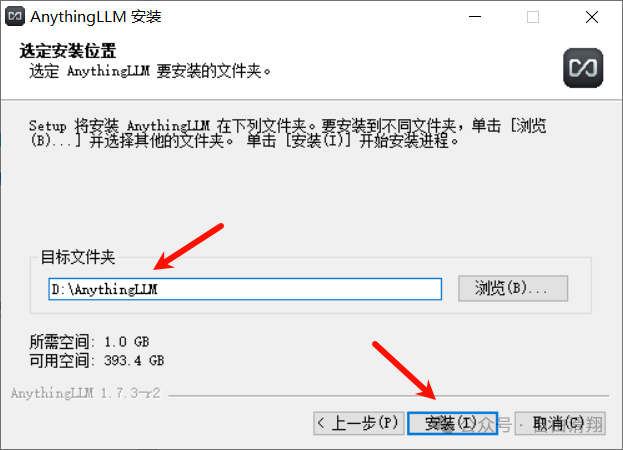
等待一段时间后出现如下界面说明安装完成。
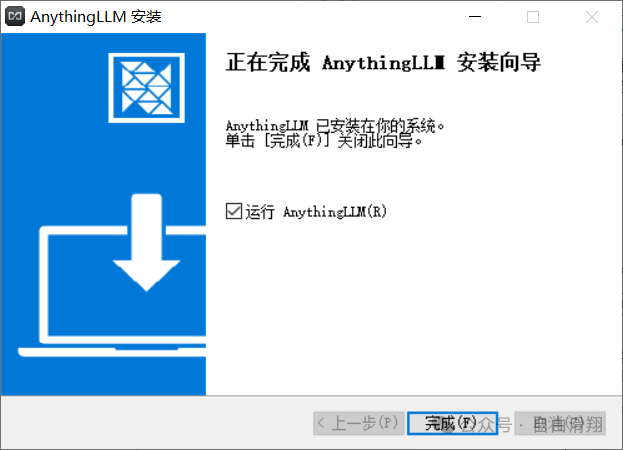
2.配置AnythingLLM
双击桌面AnythingLLM图标打开,首次启动会出现Get started,点击即可。
接着直接点击右箭头,配置稍后再做。
继续点击右箭头。
继续点击右箭头。
起一个工作区名称然后点击右箭头进入工作界面。
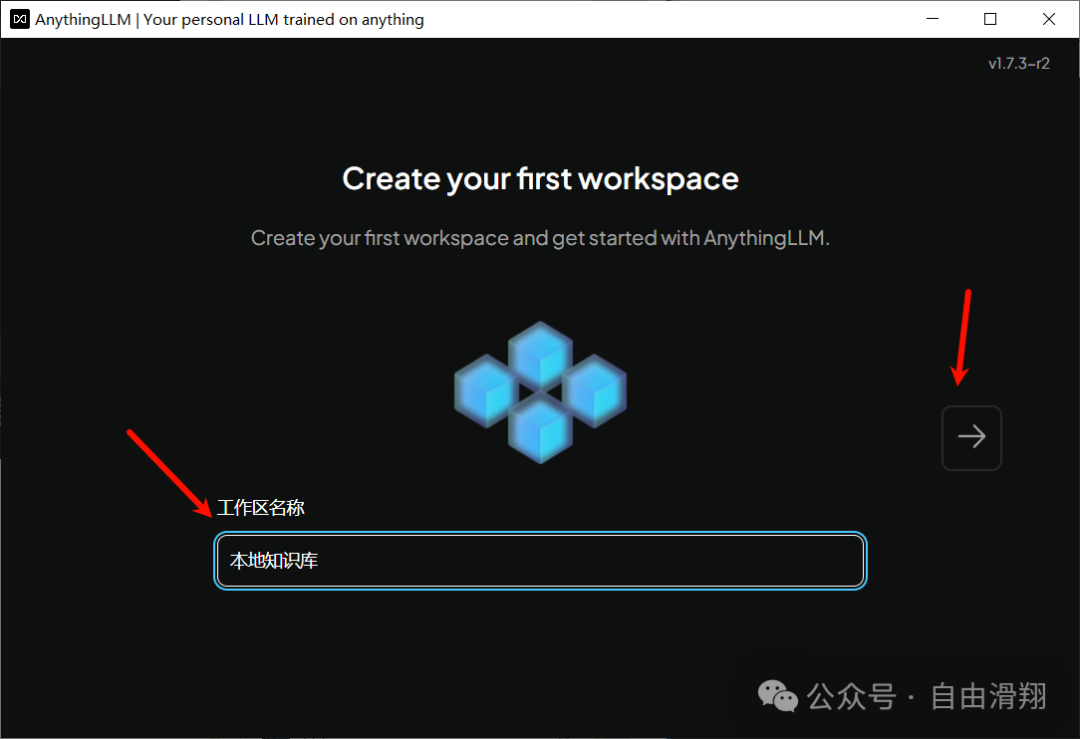
在工作界面左侧点击扳手按钮进入设置界面。
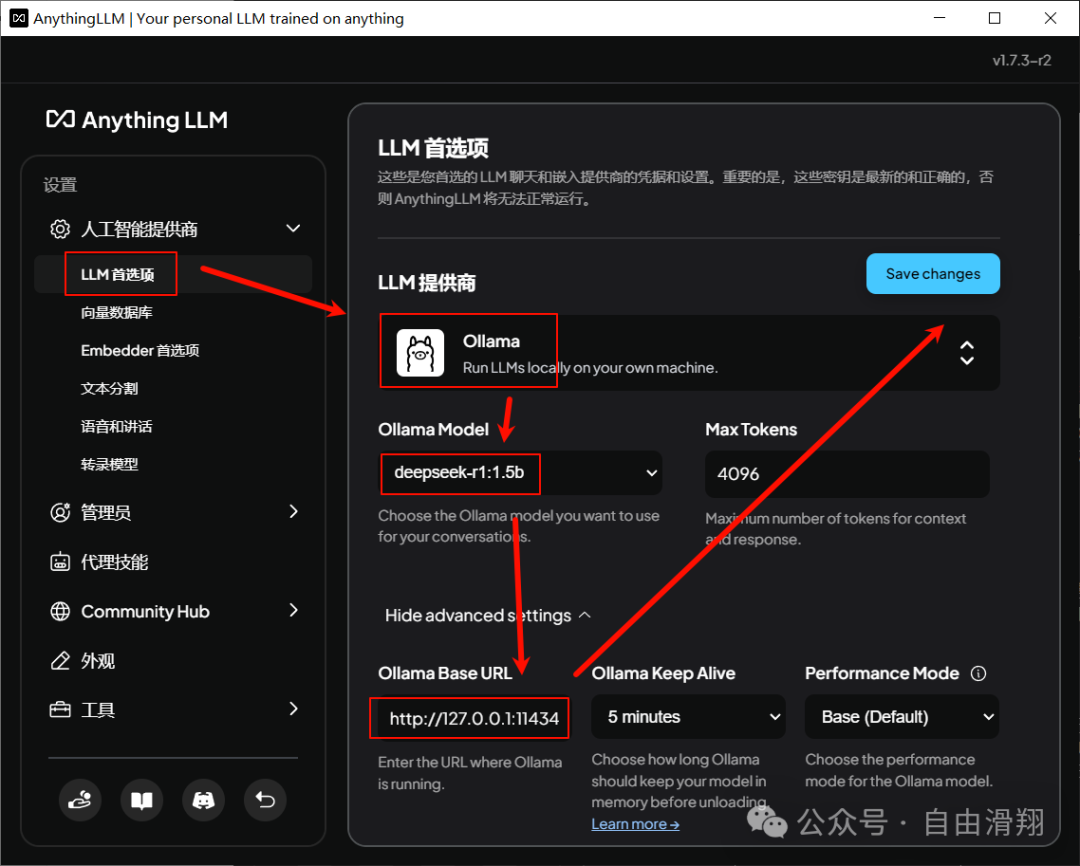
在设置界面左侧人工智能提供商下的LLM首选项中进行相关配置,如果已经正确安装了Ollama并下载了deepseek-r1:1.5b,那么只需要在右侧LLM提供商下拉列表中选中Ollama,相关信息会被自动填充到相应位置,然后点击Save changes即可。
3.使用AnythingLLM
点击刚刚创建的工作区,然后点击upload a document进入文件上传界面。
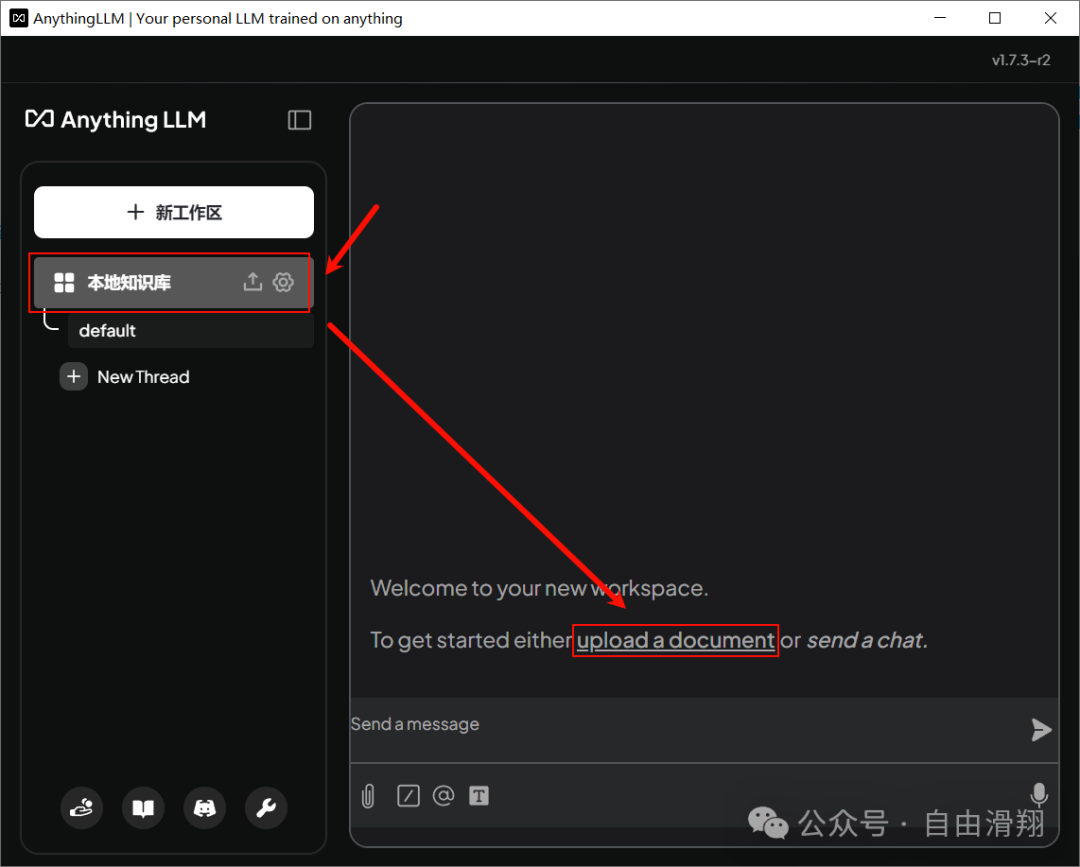
点击上传或拖拽一个文件。
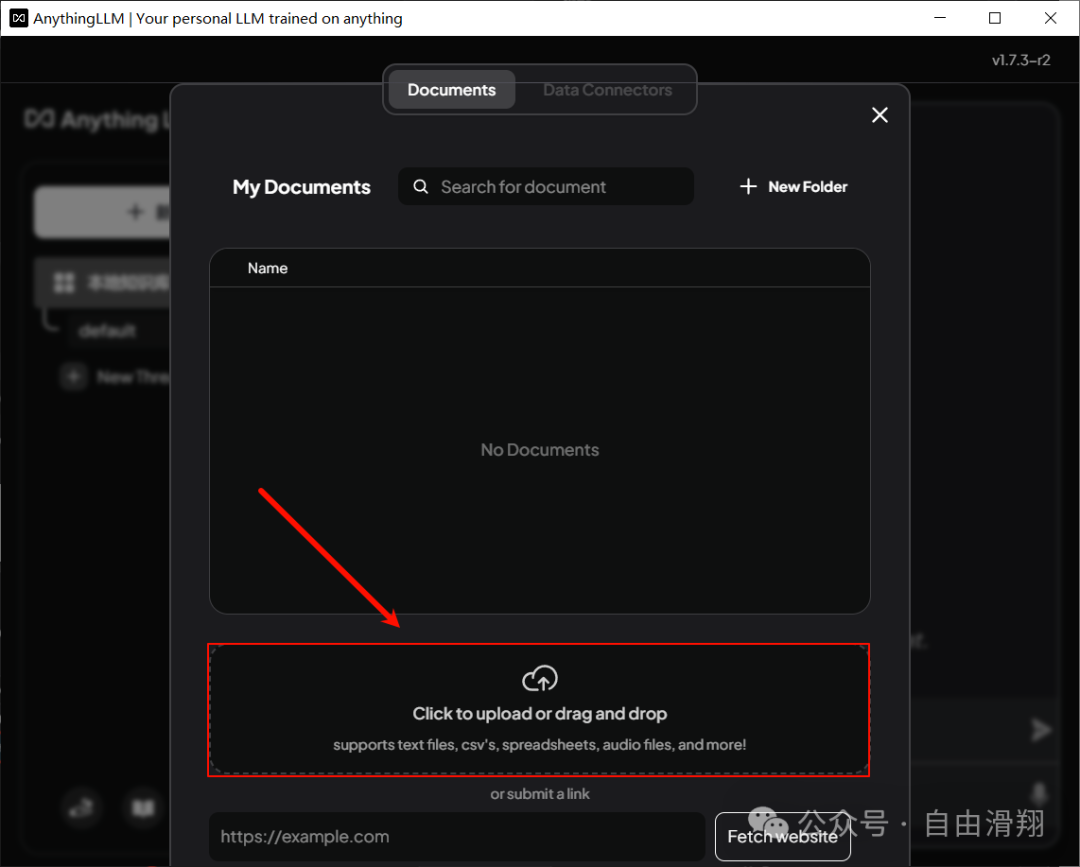
然后选中刚刚上传的文件并点击Move to Workspace将文件加载到AnythingLLM的本地知识库中。
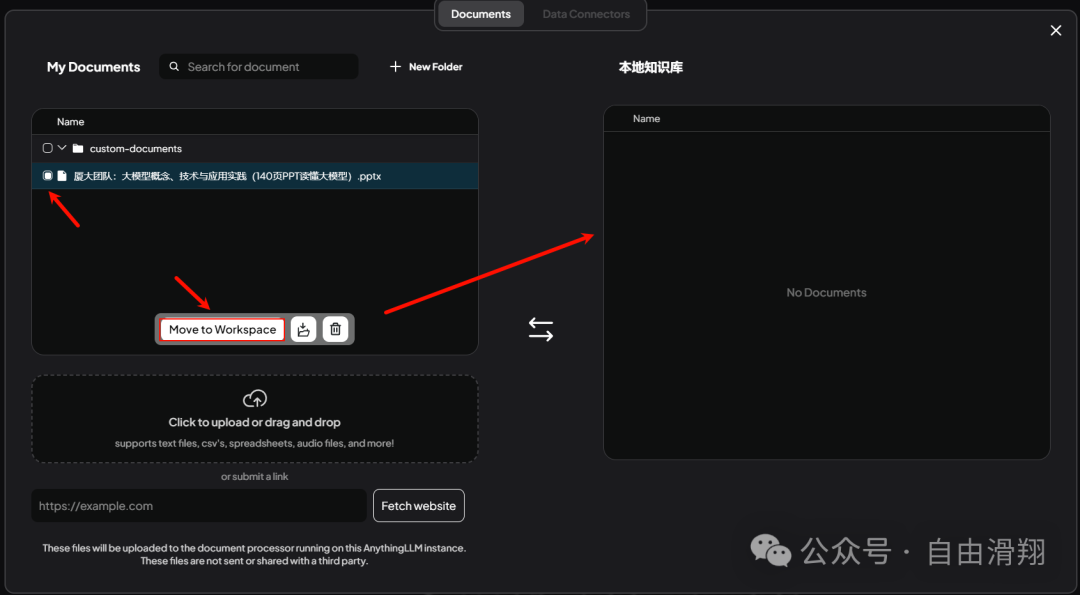
然后点击Save and Embed。
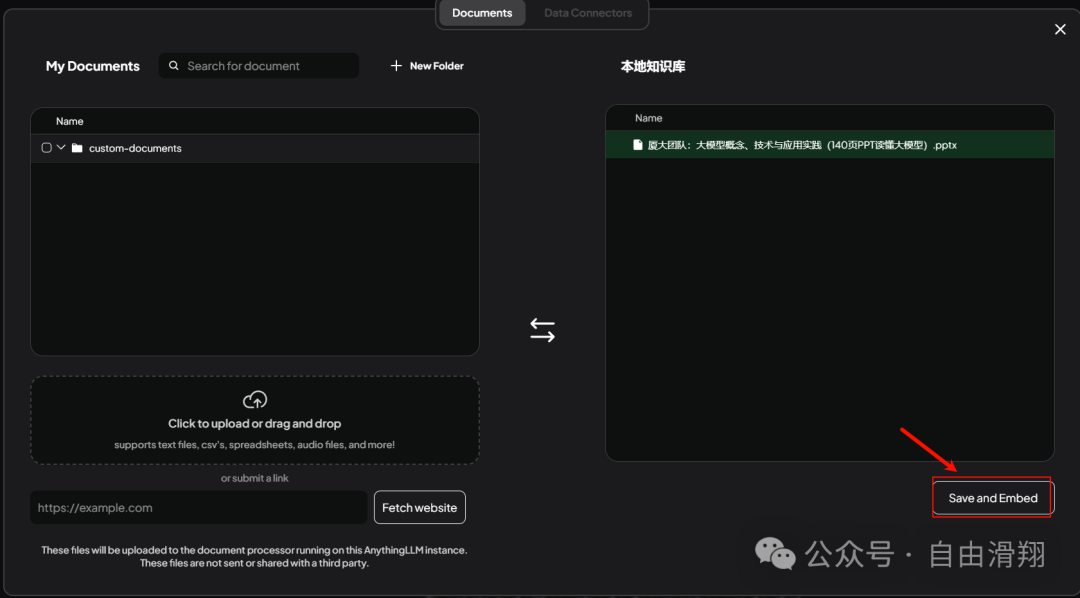
出现Workspace updated successfully就表示知识库配置已经完成。
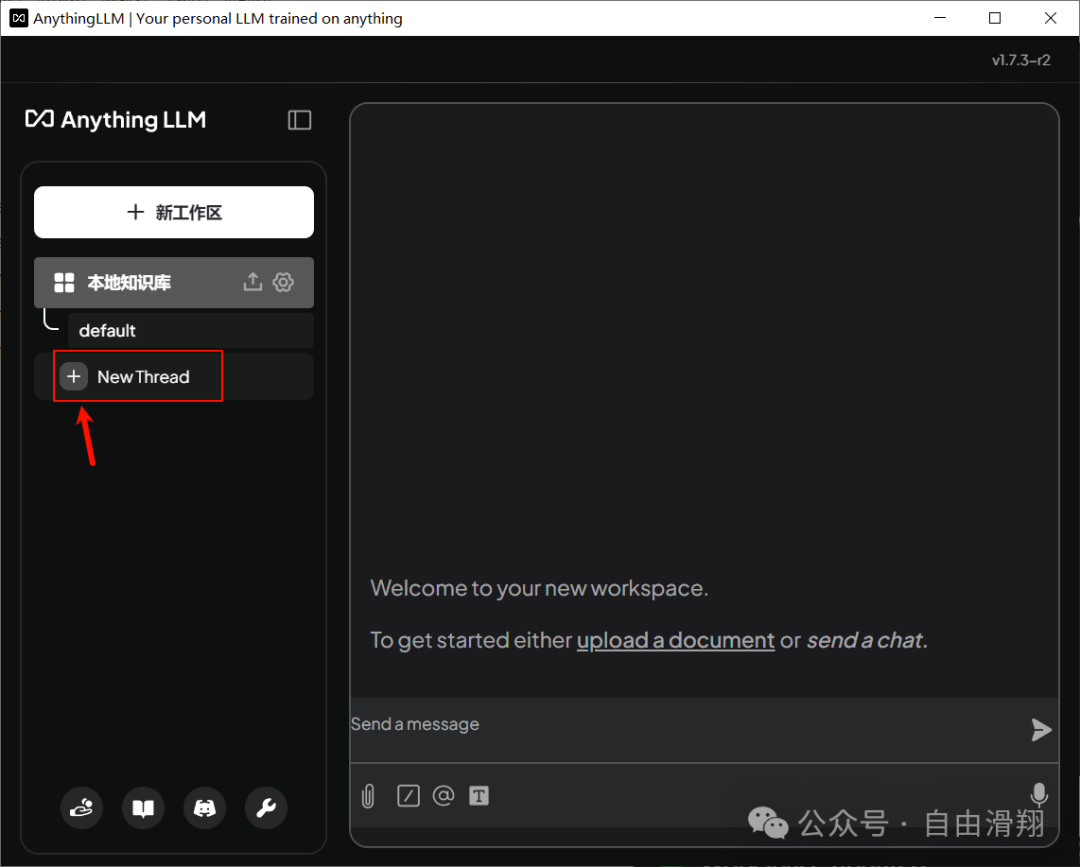
然后点击New Thread就可以开始一个新的对话了。
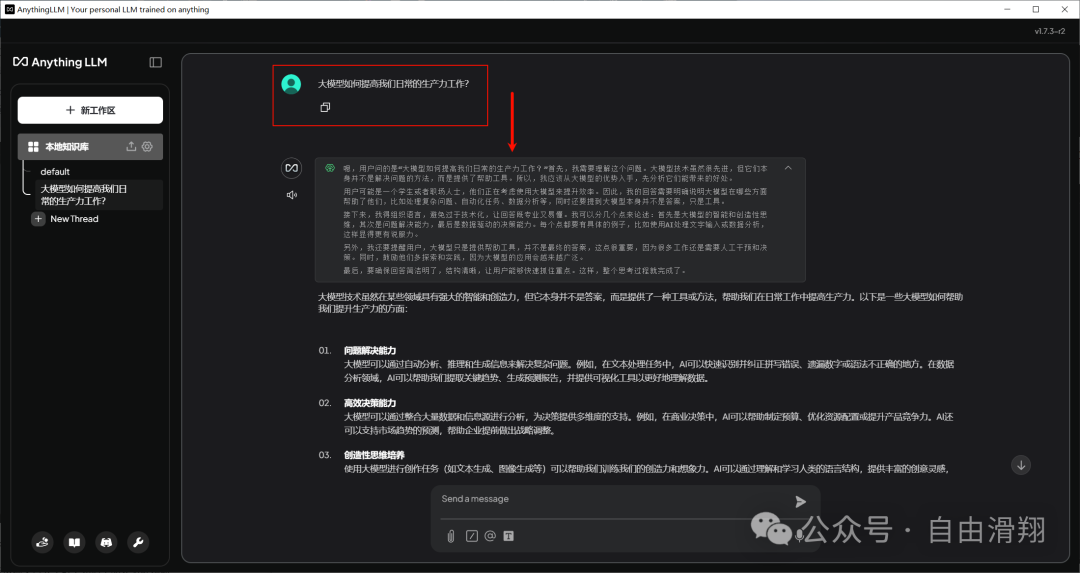
所有与AnythingLLM Desktop有关的数据将位于以下位置:
C:\Users\\AppData\Roaming\anythingllm-desktop\storage
目录下各个文件夹的含义:
- lancedb:这是存储您的本地矢量数据库及其表的地方。
- documents:这是任何上传文件的解析文档内容。
- vector-cache:此文件夹是之前上传并嵌入的文件的缓存和嵌入表示。其文件名经过哈希处理。
- models:系统使用的任何本地存储的LLM或Embedder模型都存储在此处。通常是GGUF文件。
- anythingllm.db:这是AnythingLLM SQLite数据库。
- plugins:这是存储您的自定义代理技能的文件夹。
一些问题
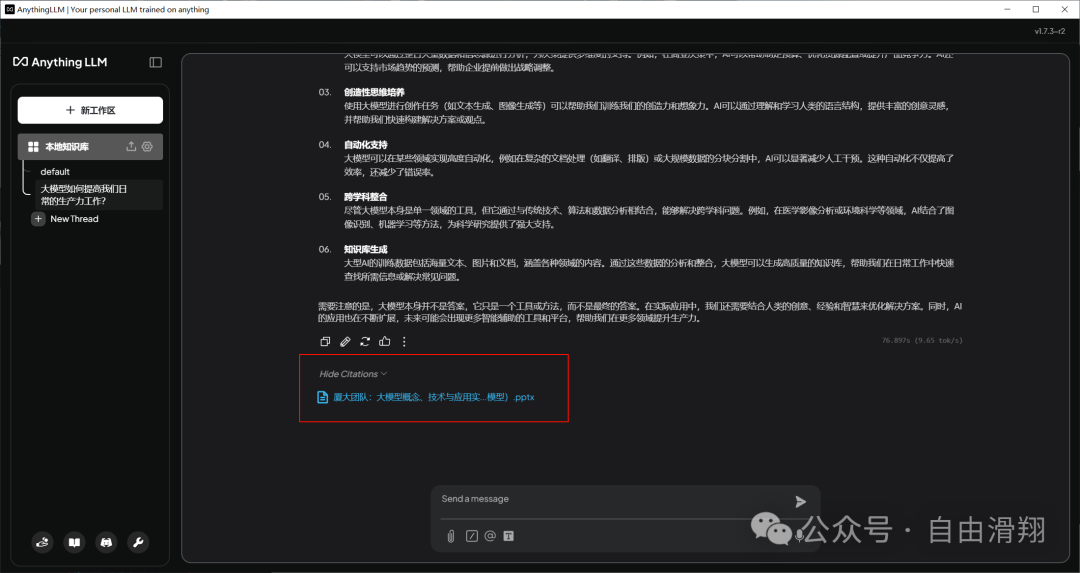
1.Show Citations太少
当您使用了多篇文档构建本地知识库时,AnythingLLM的回答仅使用了一篇或少部分文档,即Show Citations展示的文档数量较少,这可能是由于以下三个原因造成的:
- 提出的问题不需要那么多文档就可以回答。
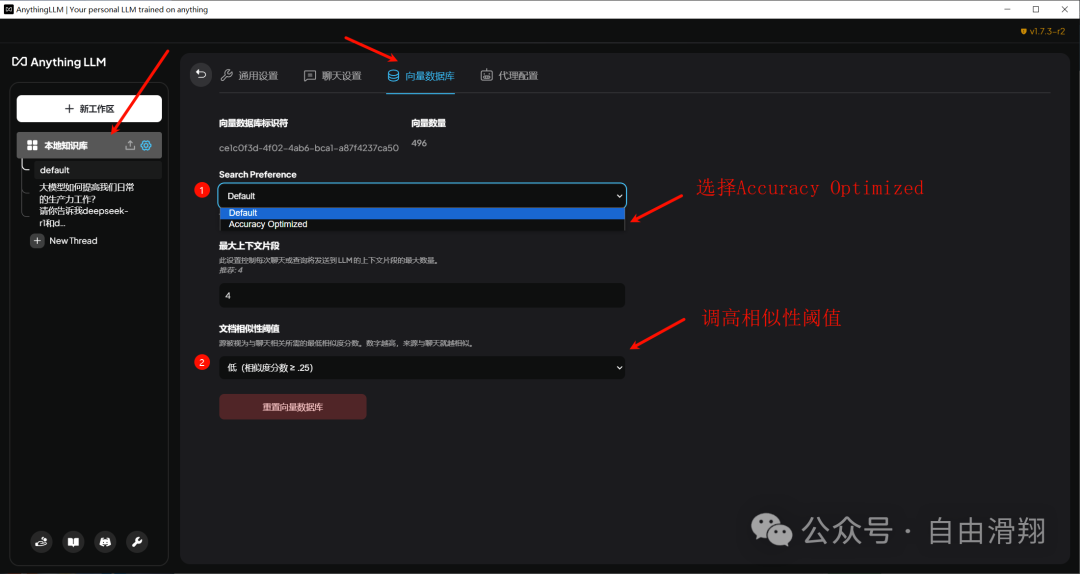
- 应当修改向量数据库的搜索偏好为
Accuracy Optimized,这将搜索更多文本块。 - 应当提高文档相似性阈值,这会减少筛选掉可能与查询无关的低分矢量块的概率。
可能不需要同时使用以上三种方法。
向量数据库搜索偏好和文档相似性阈值修改位置:
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2395
2395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









