



神经网络作为深度学习的基础,广泛应用于图像识别、自然语言处理、语音识别等任务中。
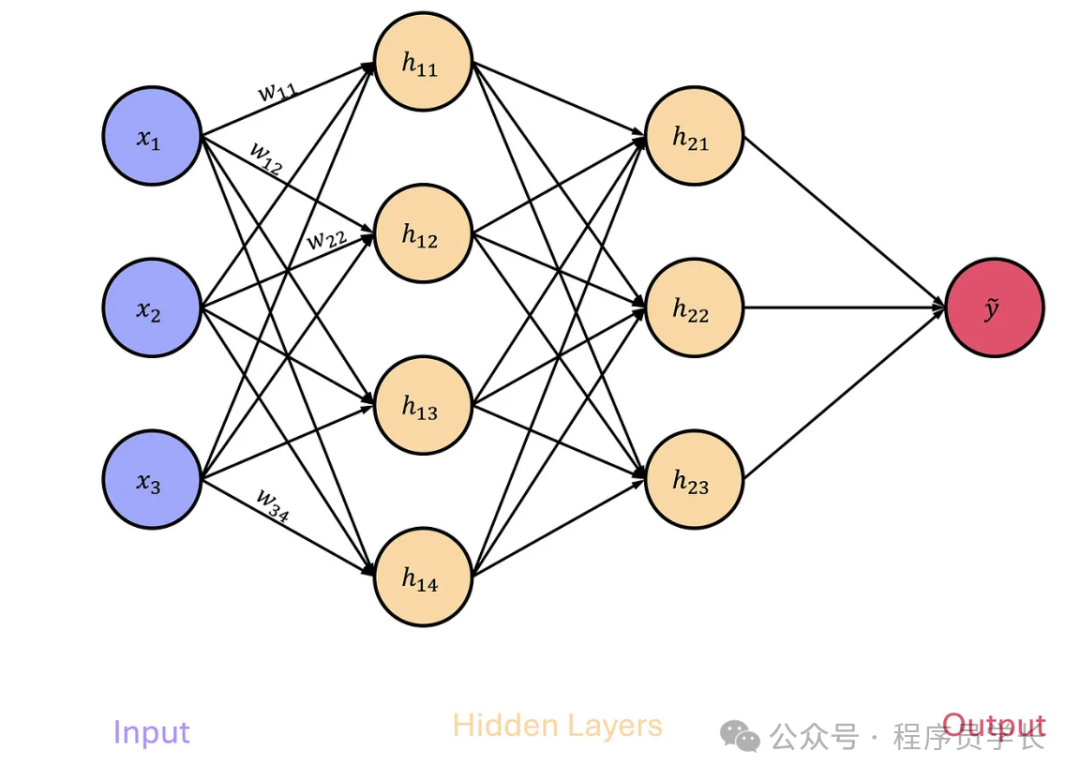
神经网络的结构
神经网络主要由输入层、隐藏层和输出层组成。
输入层
输入层用于接收输入数据(例如图像、文本),每个输入节点代表一个特征值,输入层的节点数目与输入数据的特征数目一致。
隐藏层
隐藏层位于输入层和输出层之间,通过对输入数据进行非线性变换来提取特征。
神经网络可以有多个隐藏层,每个隐藏层由若干神经元构成。
隐藏层的层数和神经元数量是神经网络设计中的重要超参数。
输出层
输出最终的预测结果或分类标签。
输出层的神经元数量与任务相关,例如分类任务的输出节点数等于类别数,回归任务通常只有一个输出节点。
神经元的结构
一个神经元的基本功能是将输入数据加权求和并通过激活函数进行处理。
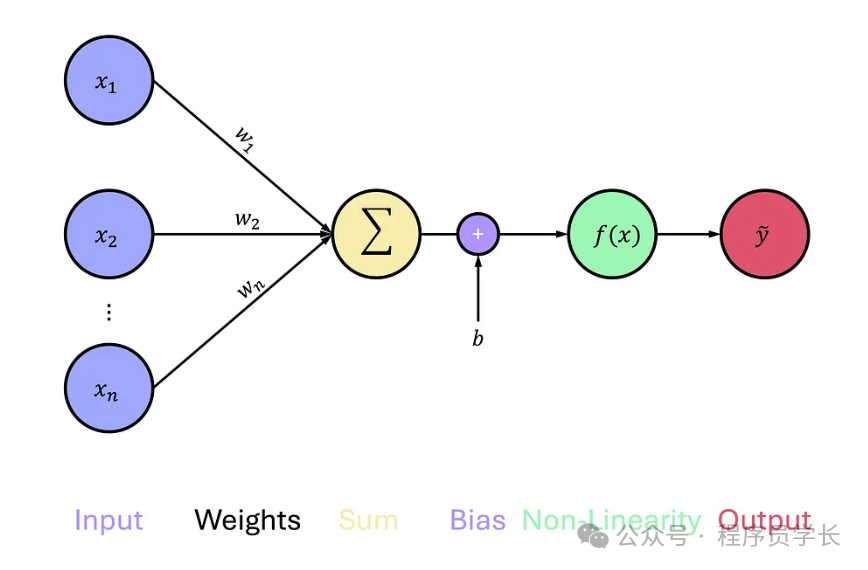
具体计算过程为:
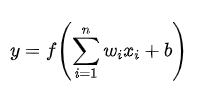
其中:

常见的激活函数
激活函数的作用是为神经网络引入非线性,使得神经网络能够学习和拟合复杂的函数。
常用的激活函数包括:
-
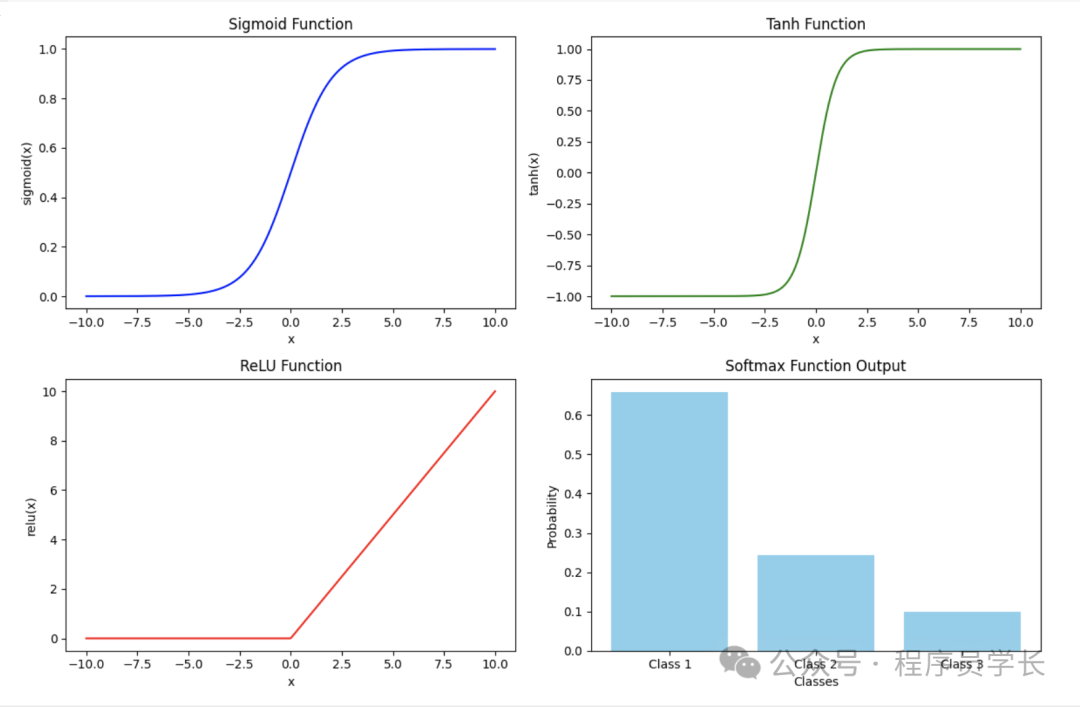
Sigmoid
输出值在(0, 1)之间,常用于二分类任务的输出层。
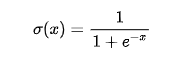
-
Tanh
输出值在-1到1之间,适合中心对称的数据。
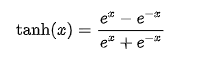
-
ReLU
ReLU 将所有负值截断为 0,广泛应用于隐藏层。
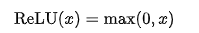
-
Softmax
用于多分类任务的输出层,输出概率分布。
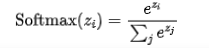
import numpy as np
import matplotlib.pyplot as plt
# 激活函数定义
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return np.tanh(x)
def relu(x):
return np.maximum(0, x)
def softmax(x):
e_x = np.exp(x - np.max(x)) # 防止溢出
return e_x / e_x.sum(axis=0, keepdims=True)
# 数据范围
x = np.linspace(-10, 10, 400)
y_sigmoid = sigmoid(x)
y_tanh = tanh(x)
y_relu = relu(x)
# 绘制图像
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(x, y_sigmoid, label="Sigmoid", color="blue")
plt.title("Sigmoid Function")
plt.xlabel("x")
plt.ylabel("sigmoid(x)")
plt.subplot(2, 2, 2)
plt.plot(x, y_tanh, label="Tanh", color="green")
plt.title("Tanh Function")
plt.xlabel("x")
plt.ylabel("tanh(x)")
plt.subplot(2, 2, 3)
plt.plot(x, y_relu, label="ReLU", color="red")
plt.title("ReLU Function")
plt.xlabel("x")
plt.ylabel("relu(x)")
x = np.array([2.0, 1.0, 0.1])
softmax_output = softmax(x)
labels = ['Class 1', 'Class 2', 'Class 3']
plt.subplot(2, 2, 4)
plt.bar(labels, softmax_output, color='skyblue')
plt.title('Softmax Function Output')
plt.xlabel('Classes')
plt.ylabel('Probability')
plt.tight_layout()
plt.show()
神经网络的训练过程
神经网络的训练过程是一个迭代优化的过程,主要目标是调整网络中的参数(权重和偏置),使得神经网络能够在给定任务上表现良好。
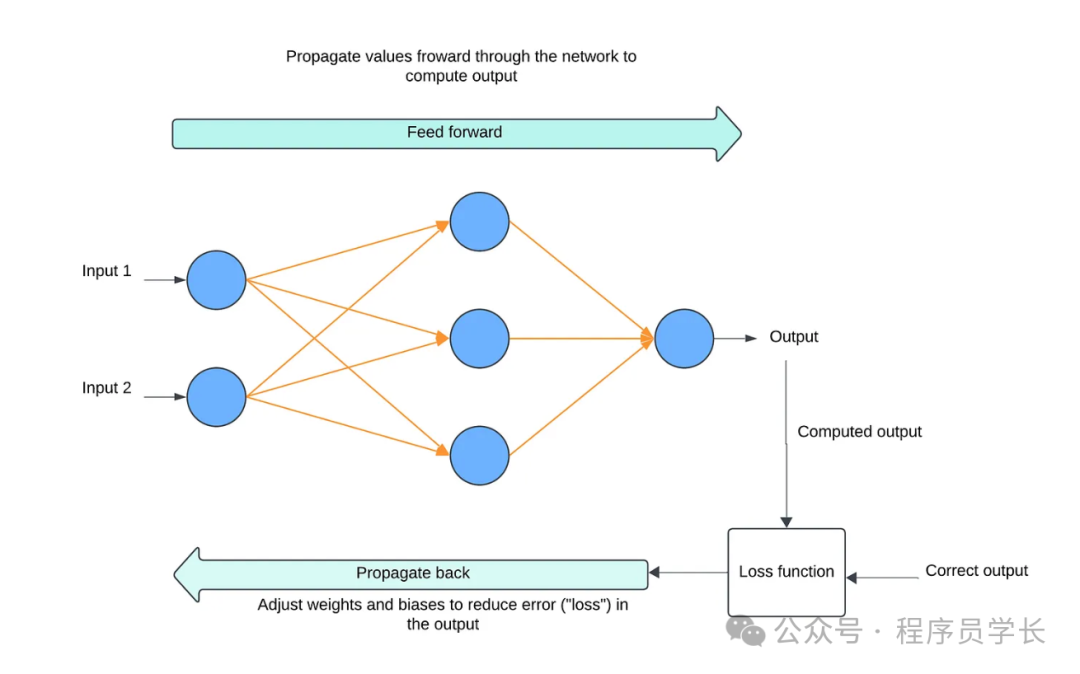
1. 初始化网络结构
神经网络的结构通常由输入层、隐藏层和输出层组成。
每一层都包含若干个神经元或“节点”,每个节点与上一层和下一层的节点通过“权重”相连。
在网络初始化时,权重通常随机初始化,偏置一般初始化为零或小的常数值。
2. 前向传播 (Forward Propagation)
前向传播是计算网络输出的过程
步骤如下:
-
输入数据
从输入层开始,网络接收一个输入样本(例如图像的像素值或文本的特征向量)。
-
加权求和
每一层的每个神经元会对来自前一层的输入进行加权求和。
计算公式如下:
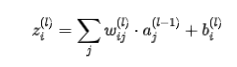

-
激活函数
加权求和后,通过激活函数计算神经元的输出。
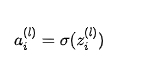

-
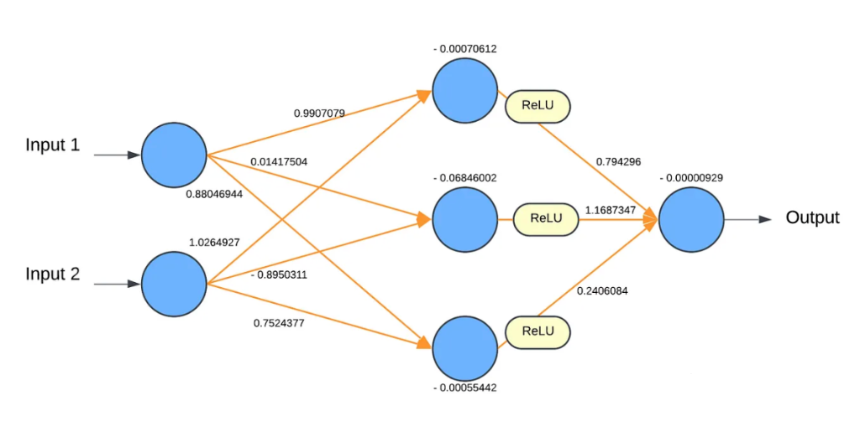
输出层
最终,经过一系列层的前向传播后,网络会输出预测结果。
3.计算损失
在每次前向传播后,我们需要计算神经网络的预测值与真实值之间的误差。
损失函数用于量化这种误差,不同的任务需要选择不同的损失函数。
- 回归任务

其中, 是真实值, 是预测值, 是样本数。
- 分类任务

4. 反向传播
反向传播是训练神经网络的核心,它用于计算损失函数关于每个权重的梯度,并通过梯度下降算法来更新权重。
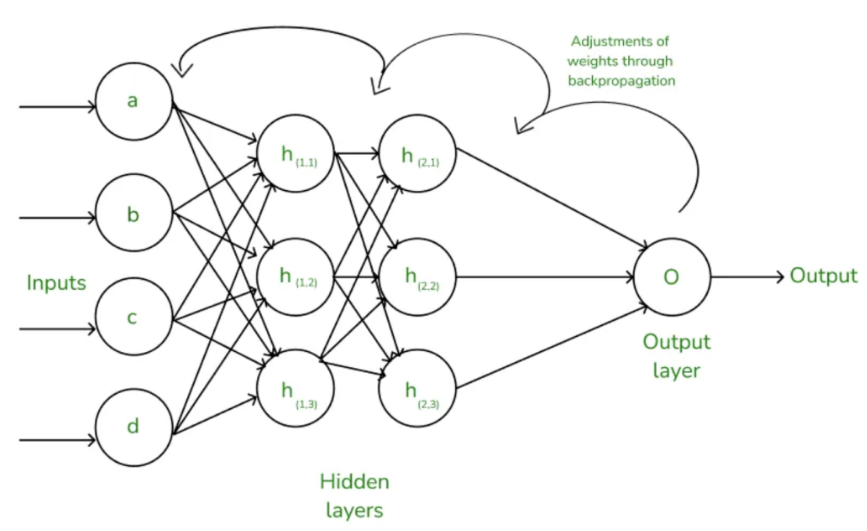
反向传播的步骤如下
-
计算损失函数对输出的梯度
首先,计算损失函数对输出层的梯度(即误差):

-
计算每一层的误差
然后,通过链式法则逐层将误差向后传播,计算每一层的误差

-
计算权重和偏置的梯度
然后,计算每一层的权重和偏置的梯度
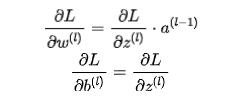
5. 参数更新
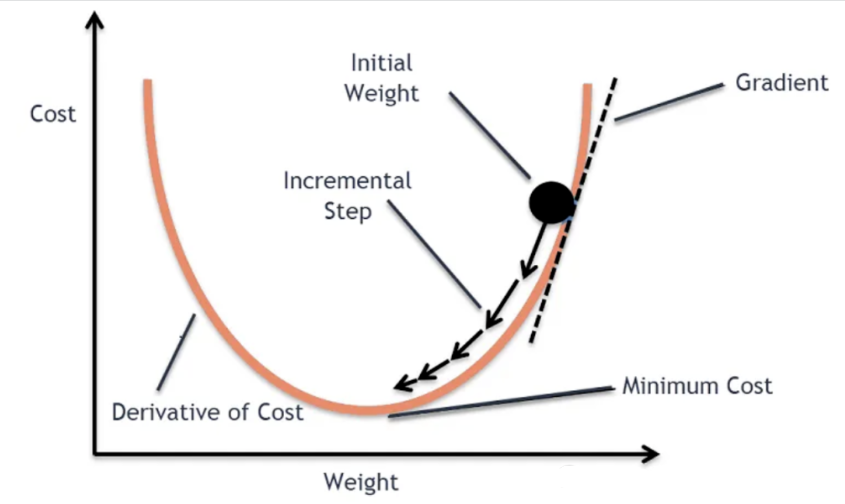
反向传播计算出每个权重和偏置的梯度后,接下来就是更新权重和偏置。
通常使用梯度下降算法来更新网络的权重和偏置。
更新公式如下

6. 迭代训练
训练过程通常会进行多次迭代(称为 epochs),每个 epoch 包括了对训练数据的一次完整的前向传播和反向传播。
案例分享
下面是一个使用神经网络对鸢尾花数据集进行分类的示例代码。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
#加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
y_one_hot = to_categorical(y, 3)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_one_hot, test_size=0.2, random_state=42)
#构建神经网络模型
model = Sequential()
#输入层和第一个隐藏层
model.add(Dense(64, activation='relu', input_dim=X_train.shape[1]))
#第二个隐藏层
model.add(Dense(32, activation='relu'))
#输出层
model.add(Dense(3, activation='softmax')) # 3类输出
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
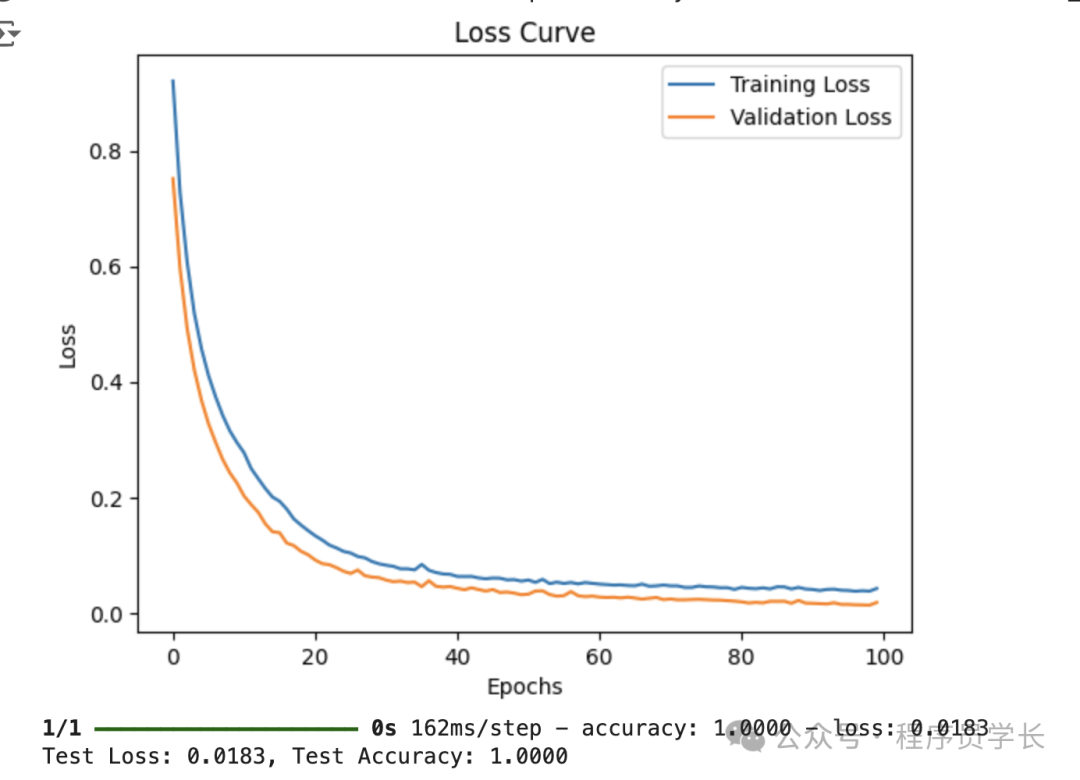
history = model.fit(X_train, y_train, epochs=100, batch_size=10, validation_data=(X_test, y_test))
#绘制损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Loss Curve')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
#评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Loss: {loss:.4f}, Test Accuracy: {accuracy:.4f}")
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 3377
3377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









