



数学,特别是算术,本质上是由一系列简单的函数构成,这些函数可以看作是特定的模式。而Transformer模型则是一个强大的模式识别系统,它通过对输入和输出的关系进行建模,试图学习并复现这些模式。因此,训练Transformer模型来执行基本的数学运算是一个非常有趣的尝试。
概念验证
算术运算通常非常简洁,每个算式的长度通常不会超过17个字符,而Transformer的嵌入层具备足够的表达能力来处理这些简短的算式。在初步的实验中,使用了一个包含200万参数的Transformer模型,目标是让模型学习最基础的“加1”运算。
实验结果非常出色。在训练的前10步,损失值就从初始的高值下降到0.0425,经过100步后,损失值稳定在0.03左右,几乎达到了理想状态。这表明Transformer能够迅速掌握简单的算术规律。
以下是模型在训练过程中生成的一些加1示例:
4719+1=4720
4720+1=4721
4721+1=4722
4722+1=4723
4723+1=4724
4448+1=4449
4449+1=4450
4450+1=4451
4451+1=4452
4452+1=4453
4453+1=4454
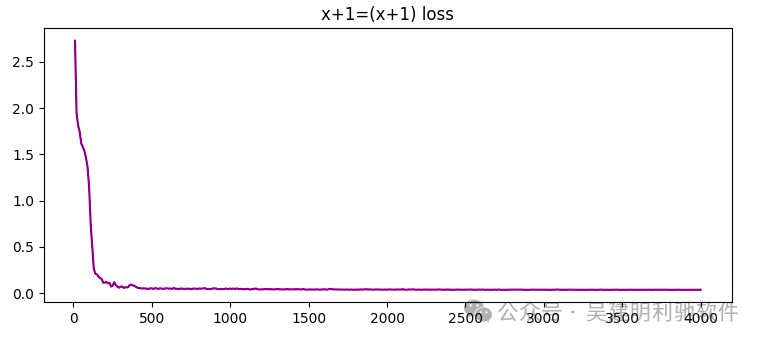
损失曲线
算术运算的进一步探索
在完成简单的“加1”运算并取得令人满意的结果后,实验进一步扩展至更复杂的算术操作,包括加法、减法、乘法和除法。每种算术操作均使用了规模庞大的数据集(1亿个示例)进行训练,以下是对不同算术运算任务的训练结果及分析:
加法
加法任务的训练过程相比“加1”稍显复杂,损失值下降速度较慢,但在约5000步后趋于平稳,最终达到1.1。以下是模型在加法任务中的部分示例输出:
6719+6207=12926
9472+8559=18031
8079+3103=11182
9483+9138=18621
8133+6652=14785
5478+4446=9924
4076+3936=7012
1599+7550=9049
4721+7543=12264
8487+4040=12527
6258+8013=14271
4860+8373=13233
1286+8721=10007
298+9025=9323
观察:
- • 大多数情况下,模型能够生成准确的加法结果,尤其是在小数值范围内表现优异。
- • 随着数值变大或样本间存在复杂关系时,偶尔出现错误,但总体表现稳定且接近实际值。
减法
减法任务的训练表现略逊于加法,损失值收敛至约1.3,整体表现尚可。以下是一些示例输出:
4529 -2147=2382
8376-4298=4078
1208-987=221
6792-7456=-664
观察:
- • 减法结果大多正确,但偶尔会出现误差或符号问题。
- • 适当调整数据分布或模型结构,可能进一步提升对负值与边界情况的处理能力。
乘法
在乘法任务中,模型的训练收敛较快,损失值在2000步时下降至约1.6,5000步后稳定在1.48。以下为部分训练结果示例:
680*258=173440 (真实答案是175440,差1位)
7412*2528=18716036
12*1307=9162084
观察:
- • 模型在乘法任务上的表现令人惊喜,对大数计算的精度较高。
- • 少量误差通常集中在个位或进位问题上,优化模型参数可能进一步改善精度。
除法
除法任务是所有算术运算中最具挑战性的,模型损失值在初期较高(约2.8),收敛速度显著慢于其他运算。以下是部分示例:
9137 ÷7041=1.2998
9636÷494=19.5
2498÷8702=0.287
观察:
- • 除法结果中,整数部分的表现尚可,但处理小数点后位数和精度时,模型显得不足。
- • 浮点数学习难度较高,模型在除法任务中常生成噪声,尤其是在复杂分母场景下。
RASP vs Transformer
RASP (Random Access Sequence Processing) 是一种为 Transformer 提供解释性基础的简化编程模型,可以被视为适用于 Transformer 的图灵机。它强调对序列操作的灵活性,适用于构建和解释复杂的操作逻辑,如加法、减法等基本算术运算。
Transformer 是一种基于注意力机制的深度学习架构,广泛应用于自然语言处理和序列建模任务。尽管其强大的学习能力适用于许多复杂任务,但在某些数学运算(如精确的加减乘除)上,仍面临挑战,尤其是涉及精确条件分支(如借位、进位)时。
加法
加法的逻辑较为直观,主要通过以下步骤完成:
- \1. 序列反转:将数字序列从右至左排列,便于逐位计算。
- \2. 逐位求和:处理当前位的数值,并加上进位。
- \3. 处理进位:确保每位数字都在 0-9 范围内,额外的进位传递到更高位。
- \4. 反转结果:将结果反转回标准形式。
伪代码:
num1 = [1, 2, 3] # 表示数字123
num2 = [4, 5, 6] # 表示数字456
rev1 = reverse(num1) # [3, 2, 1]
rev2 = reverse(num2) # [6, 5, 4]
pairs = zip(rev1, rev2) # [(3, 6), (2, 5), (1, 4)]
sum_digits = map(add, pairs) # [9, 7, 5]
carry = 0
final_sum = []
for digit in sum_digits:
digit += carry
carry = digit // 10 # 获取进位
final_sum.append(digit % 10) # 获取当前位
result = reverse(final_sum) # [5, 7, 9]
观察:
- • RASP 实现难度:操作清晰,层次简单,易于通过直接逻辑完成。
- • Transformer 表现:学习进位规则时表现较好,模型能够迅速收敛。
减法
减法需要额外考虑正负号和借位问题:
- \1. 比较大小:判断被减数与减数的大小,决定结果的正负号。
- \2. 逐位减法:从最低位开始,逐位减去,并处理借位。
- \3. 借位逻辑:如果当前位结果小于 0,则从更高位借 1,并调整当前位的值。
伪代码:
num1 = [1, 2, 3]
num2 = [4, 5, 6]
if num1 >= num2:
sign = 1
larger, smaller = num1, num2
else:
sign = -1
larger, smaller = num2, num1
rev_larger = reverse(larger)
rev_smaller = reverse(smaller)
diffs = map(sub, rev_larger, rev_smaller) # [7, 7, 3]
borrow = 0
final_diff = []
for digit in diffs:
digit -= borrow
if digit < 0:
digit += 10
borrow = 1
else:
borrow = 0
final_diff.append(digit)
if sign == -1:
final_diff.append('-')
result = reverse(final_diff)
观察:
- • RASP 难度:借位的逻辑复杂性较高,需通过显式状态跟踪完成。
- • Transformer 表现:模型在捕获借位规则时可能遇到困难,损失收敛速度较慢。
乘法
乘法可以视为多次加法的扩展:
- \1. 逐位相乘:将被乘数的每一位与乘数的每一位相乘。
- \2. 处理进位:处理每次相乘后的结果进位。
- \3. 结果累加:将每次相乘的结果按照权重(位数)累加。
伪代码:
num1 = [1, 2, 3]
num2 = [4, 5, 6]
rev1 = reverse(num1)
rev2 = reverse(num2)
result = [0] * (len(rev1) + len(rev2))
for i, digit1 in enumerate(rev1):
carry = 0
for j, digit2 in enumerate(rev2):
product = digit1 * digit2 + result[i + j] + carry
result[i + j] = product % 10
carry = product // 10
result[i + len(rev2)] += carry
final_result = reverse(result)
观察:
- • RASP 难度:需要嵌套的迭代操作,复杂度较高,但能通过明确逻辑实现。
- • Transformer 表现:模型较易捕获重复加法的模式,因此乘法效果优于减法。
除法
除法是最复杂的运算,涉及多次减法、判断和商的累积:
- \1. 模拟长除法:通过多次减法模拟商的生成。
- \2. 判断条件:比较当前余数是否大于或等于除数。
- \3. 计算小数部分:在余数存在时,通过多次乘 10 的操作生成小数。
伪代码:
num1 = [1, 2, 3, 4]
num2 = [5, 6]
rev1 = reverse(num1)
rev2 = reverse(num2)
result = []
remainder = rev1
while remainder >= rev2:
shift = len(remainder) - len(rev2)
multiple = rev2 + [0] * shift
remainder = map(sub, remainder, multiple)
result.append(shift)
remainder = reverse(remainder)
if remainder:
result.append('.') # 处理小数
whilelen(remainder) > 0:
remainder *= 10
result.append(remainder // num2)
remainder %= num2
final_result = reverse(result)
观察:
- • RASP 难度:多层循环嵌套且需处理条件分支,逻辑极其复杂。
- • Transformer 表现:模型对条件判断(如借位)和多分支路径学习效果较差,精度显著下降。
总体来看,RASP 的实现难度与 Transformer 的学习难度在某种程度上存在相似性。尽管 Transformer 对复杂运算(如除法)的学习能力有限,但相比于 RASP 的层数和操作步骤,Transformer 的局限性显得更为有趣。尤其是对于长除法和余数操作,Transformer 可能由于数据中缺乏充分的显式逻辑提示,而难以正确学习这类任务。某些涉及会计逻辑的复杂任务,也加剧了这种挑战。
具体而言,在代码实现中,任务的复杂性大致呈现为:加法 > 减法 > 乘法 > 除法;
而对于 Transformer 的学习表现,则更倾向于:加法 > 乘法 > 减法 > 除法。
这表明,Transformer 在处理反向逻辑时(如减法中的借位机制,相当于反向的进位)会遇到明显障碍。此外,长除法中包含的大量条件分支(如 if/else 判断)和复杂的操作步骤,使得低层 Transformer 更难以准确推导出计算规律。
结论
通过对Transformer模型的训练和实验,可以看出,在处理加法、减法和乘法等基本算术任务时,Transformer能够取得令人满意的结果。
然而,除法操作仍然是一个挑战,模型在这类运算上表现较差,主要原因在于浮点数运算和除法中产生的复杂性。
参考:https://vatsadev.github.io/articles/transformerMath.html
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









