







 介绍了南理工一篇论文,其思路类似SENet和空间注意力机制,将通道分为组并对每组进行空间注意力操作。具体步骤包括按通道维度分组、对每组单独做注意力、全局平均池化、元素点乘、归一化、激活,最后再与原组特征点乘。
介绍了南理工一篇论文,其思路类似SENet和空间注意力机制,将通道分为组并对每组进行空间注意力操作。具体步骤包括按通道维度分组、对每组单独做注意力、全局平均池化、元素点乘、归一化、激活,最后再与原组特征点乘。
论文地址:Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Network
一篇来自南理工的文章
文章的思路很简单,类似于SENet(对channel做attention)、spacial attention
就是将channel分为group,然后对每个group进行spatial的attention
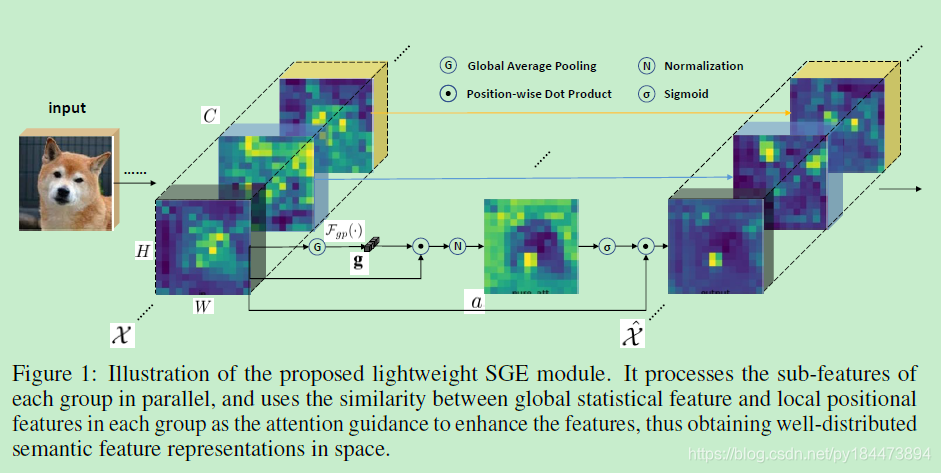
模块如上图所示,
1、将feature map按channel维度分为G个group
2、对每个group单独进行attention
3、对group进行global average pooling得到g
4、进行pooling之后的g与原group feature进行element-wise dot
5、在进行norm
6、再使用sigmoid进行激活
7、再与原group feature进行element-wise dot

















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









