




在构建基于大模型的智能系统时,如何让不同组件高效协同,是每个开发者都绕不开的问题。本文将结合Anthropic发布的《快速入门指南》第一、二部分[1][2],重点介绍如何通过模型上下文协议(Model Context Protocol,MCP)与Amazon Bedrock中的底层模型协同工作,让模型调用更灵活、更智能。我们还将演示一个实用的业务案例:通过扩展工具箱,打造一个能够自动总结博客内容并检测所有链接是否有效的智能Agent系统。

MCP介绍
根据官方文档的描述:“MCP是由Anthropic发布的一项开源协议,它规范了应用程序如何向大语言模型(LLM)提供上下文信息。可以将MCP想象成AI应用的‘USB-C接口’。就像USB-C提供了连接设备和各类配件的统一方式一样,MCP为AI模型接入不同数据源和工具提供了标准化路径”[3]。
从整体架构上看,MCP采用的是客户端/服务端的双向通信模式。该通信协议支持两种传输机制:
Stdio传输模式
使用标准输入/输出进行通信
适用于本地进程之间的数据交互
HTTP+SSE(服务器发送事件)传输模式
通过Server-Sent Events实现从服务器到客户端的信息推送
客户端到服务器的消息使用HTTP POST请求
无论是哪种传输方式,消息交换都遵循JSON-RPC 2.0协议。关于MCP消息格式的详细定义,可参考协议规范文档[4]。本文将以Stdio传输模式进行演示,这意味着MCP的客户端和服务端都在同一台机器上运行。
MCP的优势
MCP最显著的优势之一,就是它能够让不同团队更高效地协作,开发基于AI的应用系统。它就像微服务架构一样,划定了清晰的职责边界,使团队可以各自独立开发。
比如,工具开发团队可以自由地构建或更新工具能力,而不会对核心AI系统造成干扰;同时,AI团队也能专注于对话质量的优化,而不需要过多关注工具的底层实现。这种清晰的接口划分,让每个团队都能按照自己的节奏进行迭代,形成各自独立的开发周期。
更重要的是,这种模块化架构允许组织逐步添加新功能,无需对整个系统进行大规模调整,从而让AI系统能够持续演进。这种设计理念正是现代软件架构中“松耦合、高可维护性、可扩展性”的最佳实践。
以SaaS提供商为例,借助MCP,客户可以专注于自有产品功能的构建,而无需为接口对接和底层集成耗费大量时间。有了标准协议,他们可以轻松接入已有能力,实现快速上线。
从技术角度来看,MCP还带来了分布式架构的广泛优势。客户可以按需扩展各个组件、独立管理其生命周期,还能进行工具和模型的A/B测试,优化性能和成本,并通过云原生的弹性架构快速响应需求变化,实现精细化的资源配置与高效运维。
架构与流程
接下来我们将拆解一下整个系统的架构设计和对话流程。
我们会围绕一个简单的用户请求get me a summary of the blog post at this $URL来展开说明,并结合下面的两张图,逐步演示整个交互过程,确保每一步的逻辑清晰易懂。
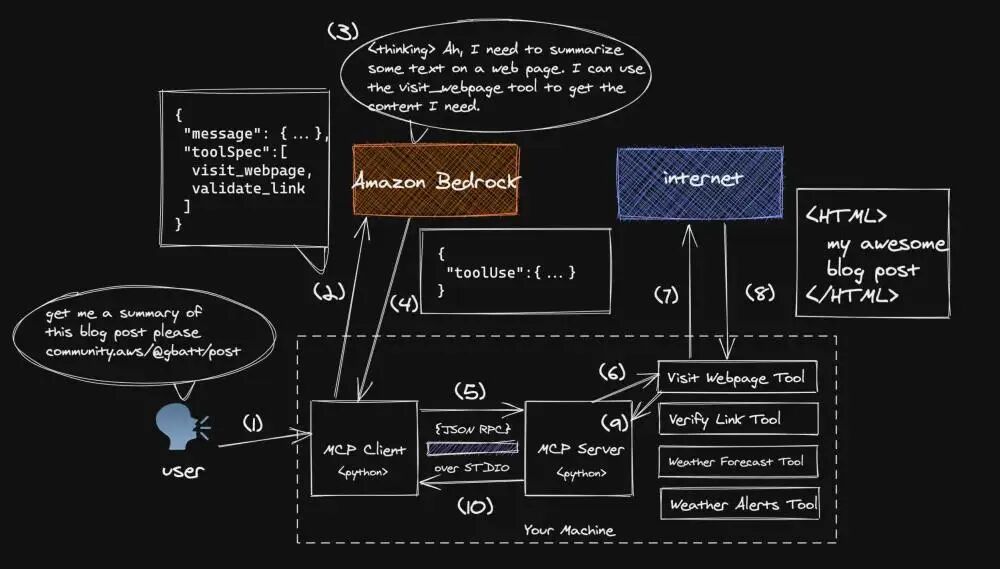
1.阅读网页并进行内容总结对人类而言,是一项很简单的任务,但大语言模型(LLM)通常无法像人类一样主动访问网页,也无法获取其参数记忆之外的信息。因此需要借助工具来实现这一功能。
2.我们将提示语(prompt)以及MCP服务端代理的一系列可用工具,通过Converse API一并发送给Amazon Bedrock。Amazon Bedrock扮演的是将模型统一接入的角色,负责调用多个底层模型。
3.模型会根据用户的请求和可用的工具列表,制定一个合理的响应计划。
4.在本案例中,模型判断应使用visit_webpage工具来访问用户提供的网页链接并获取内容。Amazon Bedrock随后会向客户端返回一条toolUse消息,其中包括:所选工具的名称、传递给工具的输入参数,以及一个唯一的toolUseId,这个ID将用于后续的消息交互。如果你想了解更多关于toolUse消息格式和用法的细节,可以参考Amazon Bedrock Converse API的官方文档[5]。
5.客户端被设定为自动将接收到的toolUse消息转发给MCP服务端。
6.在实操过程中,客户端与服务端通过本地机器上的标准输入输出(stdio)进行JSON-RPC通信。MCP服务端会将toolUse请求分发给对应的工具模块。
7.visit_webpage工具被调用,并对提供的URL发起一次HTTP请求。
8.该工具会下载指定链接的网页内容,并将其转换为Markdown格式后返回。
9.转换完成的网页内容会被传回给MCP服务端。
10.流程控制随后返回给MCP客户端。
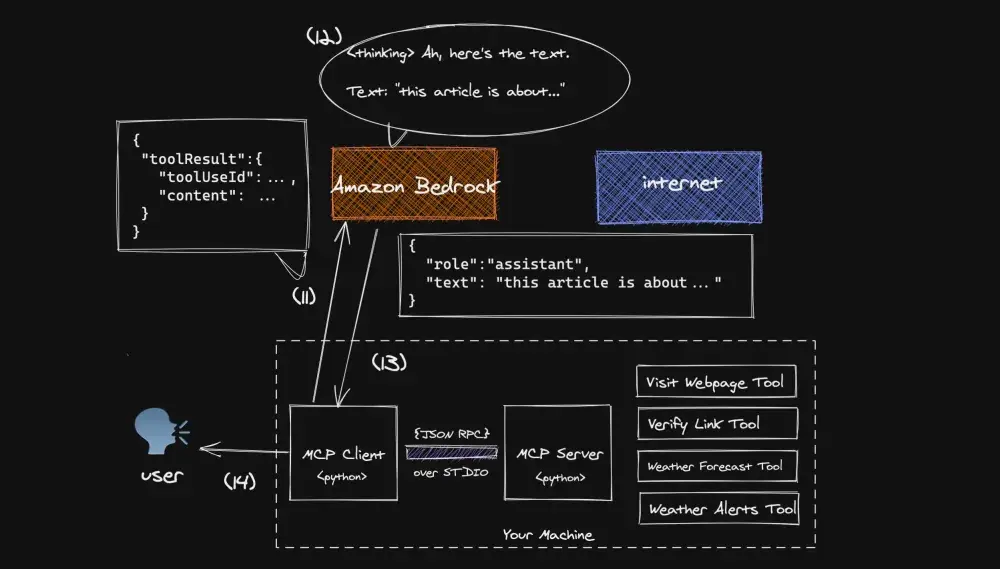
11.MCP客户端会将工具返回的结果封装成一条toolResult消息,并添加到当前对话历史中。这条消息会包含在第4步中生成的toolUseId,然后将该消息转发给Amazon Bedrock。如果你想了解toolResult的消息格式和用法,可以参考相关官方文档[6]。
12.此时,Amazon Bedrock会基于工具返回的结果,生成最终的自然语言响应。
13.生成的响应会被发送回客户端,客户端则会将对话控制权交还给用户。
14.用户接收到MCP客户端返回的回复内容后,可以自由发起下一轮对话或新的请求流程。
前期准备工作
在正式开始之前,请确保已完成以下准备工作:
学习如何使用Python创建一个MCP服务端[7]。完成教程后,你应该能够成功运行一个MCP服务端,并具备两个工具:get_alerts和get_weather。本教程还包括安装uv,这是一款快速、安全的Python运行时和包管理工具[8]。
确保已在环境变量中导出你的亚马逊云科技凭证,以便boto3可以正常使用。如需了解如何配置亚马逊云科技凭证,请参考“亚马逊云科技Boto3开发者指南”凭证配置[9]。
为Amazon Bedrock创建MCP客户端
在构建新的MCP客户端前,需要确保已完成“前期准备工作”中提到的创建MCP服务端教程。
设置项目
项目目录结构大致如下,目前还未包含即将创建的mcp-client文件夹:

初始项目树
如果当前的工作目录是在weather/文件夹内,请先返回上一级目录,然后创建一个新的Python项目。
cd ..uv init mcp-client
你可以通过以下命令删除默认生成的main.py文件,并新建一个名为client.py的文件:
cd mcp-clientrm main.pytouch client.py
你需要使用uv安装以下依赖包,以便后续开发MCP客户端:
uv add mcp boto3
导入包
使用mcp包来管理对MCP服务端会话的访问,并用boto3添加Amazon Bedrock的功能。
# client.pyimport asyncioimport sysfrom typing import Optional, List, Dict, Anyfrom contextlib import AsyncExitStackfrom dataclasses import dataclass
# to interact with MCPfrom mcp import ClientSession, StdioServerParametersfrom mcp.client.stdio import stdio_client
# to interact with Amazon Bedrockimport boto3
左右滑动查看完整示意
映射Amazon Bedrock消息
通过这个辅助类,可以将来自Amazon Bedrock Converse API的消息映射为可以在业务逻辑中使用的对象。我们还定义了一个工具方法,用于将MCP服务端中工具的定义映射为Amazon Bedrock Converse API的语法。
# client.py@dataclassclassMessage: role: str content: List[Dict[str, Any]]
@classmethod def user(cls, text: str) -> 'Message': returncls(role="user", content=[{"text": text}])
@classmethod def assistant(cls, text: str) -> 'Message': returncls(role="assistant", content=[{"text": text}])
@classmethod def tool_result(cls, tool_use_id: str, content: dict) -> 'Message': returncls( role="user", content=[{ "toolResult": { "toolUseId": tool_use_id, "content": [{"json": {"text": content[0].text}}] } }] )
@classmethod def tool_request(cls, tool_use_id: str, name: str, input_data: dict) -> 'Message': returncls( role="assistant", content=[{ "toolUse": { "toolUseId": tool_use_id, "name": name, "input": input_data } }] )
@staticmethod def to_bedrock_format(tools_list: List[Dict]) -> List[Dict]: return [{ "toolSpec": { "name": tool["name"], "description": tool["description"], "inputSchema": { "json": { "type": "object", "properties": tool["input_schema"]["properties"], "required": tool["input_schema"]["required"] } } } } for tool in tools_list]左右滑动查看完整示意
定义客户端
为了简化起见,将客户端的所有业务逻辑封装在MCPClient这一个类别中。
# client.pyclassMCPClient: MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0" def __init__(self): self.session: Optional[ClientSession] = None self.exit_stack = AsyncExitStack() self.bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
async def connect_to_server(self, server_script_path: str): ifnot server_script_path.endswith(('.py', '.js')): raise ValueError("Server script must be a .py or .js file")
command = "python"if server_script_path.endswith('.py') else"node" server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params)) self.stdio, self.write = stdio_transport self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write)) await self.session.initialize()
response = await self.session.list_tools() print("\nConnected to server with tools:", [tool.name for tool in response.tools])
async def cleanup(self): await self.exit_stack.aclose()左右滑动查看完整示意
self.session是映射到我们正在建立的MCP会话的对象。在这种情况下,我们将使用stdio,因为我们会使用托管在同一台机器上的工具。
self.bedrock创建了一个Amazon SDK客户端,提供与Amazon Bedrock运行时API交互的方法,允许你调用像converse这样的API来与基础模型进行通信。
self.exit_stack = AsyncExitStack()创建了一个上下文管理器,帮助管理多个异步资源(例如网络连接和文件句柄),通过在程序退出时自动以相反的顺序清理它们,类似于嵌套的async with语句堆栈,但更加灵活和程序化。我们在公共的清理方法中使用self.exit_stack来处理资源的释放。
connect_to_server方法通过标准输入输出(stdio)与实现MCP工具的Python或Node.js脚本建立双向通信通道,并初始化一个会话,允许客户端发现并调用服务器脚本暴露的工具。
处理查询
这是业务逻辑的核心部分之一。
# client.py def _make_bedrock_request(self, messages: List[Dict], tools: List[Dict]) -> Dict: return self.bedrock.converse( modelId=self.MODEL_ID, messages=messages, inferenceConfig={"maxTokens": 1000, "temperature": 0}, toolConfig={"tools": tools} )
async def process_query(self, query: str) -> str: # (1) messages = [Message.user(query).__dict__] # (2) response = await self.session.list_tools()
# (3) available_tools = [{ "name": tool.name, "description": tool.description, "input_schema": tool.inputSchema } for tool in response.tools]
bedrock_tools = Message.to_bedrock_format(available_tools)
# (4) response = self._make_bedrock_request(messages, bedrock_tools)
# (6) return await self._process_response( # (5) response, messages, bedrock_tools )左右滑动查看完整示意
_make_bedrock_request方法是一个私有辅助函数,用于向Amazon Bedrock的Converse API发送请求,传递对话历史、可用工具和模型配置参数,以获取来自基础模型的响应,处理下一轮对话。我们将在多个方法中使用这个函数。
process_query方法协调了整个查询处理流程:
a.从用户的查询创建一条消息;
b.从连接的服务器获取可用工具;
c.将工具格式化为Amazon Bedrock预期的结构;
d.使用查询和工具向Amazon Bedrock发送请求;
e.通过可能的多轮对话处理响应(如果需要使用工具);
f.返回最终的响应。
这是处理用户查询并管理用户、工具和基础模型之间对话流程的主要入口点。接下来,让我们深入了解如何处理对话。
循环对话处理
这是一个循环对话流程,我们将在此处理来自用户和Amazon Bedrock的各种请求。
# client.py async def _process_response(self, response: Dict, messages: List[Dict], bedrock_tools: List[Dict]) -> str: # (1) final_text = [] MAX_TURNS=10 turn_count = 0
while True: # (2) if response['stopReason'] == 'tool_use': final_text.append("received toolUse request") for item in response['output']['message']['content']: if'text' in item: final_text.append(f"[Thinking: {item['text']}]") messages.append(Message.assistant(item['text']).__dict__) elif 'toolUse' in item: # (3) tool_info = item['toolUse'] result = await self._handle_tool_call(tool_info, messages) final_text.extend(result) response = self._make_bedrock_request(messages, bedrock_tools) # (4) elif response['stopReason'] == 'max_tokens': final_text.append("[Max tokens reached, ending conversation.]") break elif response['stopReason'] == 'stop_sequence': final_text.append("[Stop sequence reached, ending conversation.]") break elif response['stopReason'] == 'content_filtered': final_text.append("[Content filtered, ending conversation.]") break elif response['stopReason'] == 'end_turn': final_text.append(response['output']['message']['content'][0]['text']) break
turn_count += 1
if turn_count >= MAX_TURNS: final_text.append("\n[Max turns reached, ending conversation.]") break # (5) return"\n\n".join(final_text)
左右滑动查看完整示意
_process_response方法初始化了一个对话循环,最多可进行10轮(MAX_TURNS),并将响应保存在final_text中。
当模型请求使用工具时,它通过处理思考步骤(文本)和工具执行步骤(toolUse)来处理该请求。
对于工具的使用,它调用工具处理程序,并使用工具的结果向Amazon Bedrock发起新的请求。这些工具已经在MCP服务器上被本地托管。
通过附加适当的消息并打破循环来处理各种停止条件(最大令牌数、内容过滤、停止序列、结束回合)。
最后,它将所有积累的文本用换行符连接起来,并返回完整的对话历史。
处理工具请求
# client.py
async def _handle_tool_call(self, tool_info: Dict, messages: List[Dict]) -> List[str]: # (1) tool_name = tool_info['name'] tool_args = tool_info['input'] tool_use_id = tool_info['toolUseId']
# (2) result = await self.session.call_tool(tool_name, tool_args)
# (3) messages.append(Message.tool_request(tool_use_id, tool_name, tool_args).__dict__) messages.append(Message.tool_result(tool_use_id, result.content).__dict__)
# (4) return [f"[Calling tool {tool_name} with args {tool_args}]"]左右滑动查看完整示意
_handle_tool_call方法通过提取提供的信息中的工具名称、参数和ID来执行工具请求。
它通过会话接口调用工具,并等待其结果。
该方法将工具请求及其结果记录在对话历史中。这是为了让Amazon Bedrock知道我们与其他地方的某个人(即运行在你机器上的工具)进行了对话。
最后,它返回一个格式化的消息,指示调用了哪个工具以及使用了哪些参数。
这个方法实际上充当了模型的工具使用请求(来自Amazon Bedrock)和实际工具执行系统(运行在你的机器上)之间的桥梁。
开始聊天
chat_loop方法实现了一个简单的交互式命令行界面,它持续接受用户输入,通过系统处理查询,并显示响应,直到用户输入‘quit’或发生错误为止。
# client.py
async def chat_loop(self): print("\nMCP Client Started!\nType your queries or 'quit' to exit.") while True: try: query = input("\nQuery: ").strip() if query.lower() == 'quit': break response = await self.process_query(query) print("\n" + response) except Exception as e: print(f"\nError: {str(e)}")左右滑动查看完整示意
这是程序的核心入口,处理整个流程的启动,管理用户输入并触发相关操作。
# client.pyasync def main(): iflen(sys.argv) < 2: print("Usage: python client.py <path_to_server_script>") sys.exit(1)
client = MCPClient() try: await client.connect_to_server(sys.argv[1]) await client.chat_loop() finally: await client.cleanup()
if __name__ == "__main__": asyncio.run(main())
左右滑动查看完整示意
在这里,我们验证命令行参数并初始化一个MCP客户端,连接到指定的服务器脚本。然后,我们在异步上下文中运行聊天循环,使用Python的asyncio来管理异步执行流,并进行适当的清理处理。
我们将单独演示两个工具:
天气警报工具:将帮助我们获取美国某州的天气警报。
提示词:“获取加利福尼亚的天气警报摘要”
天气预报工具:将帮助我们获取美国某个城市的天气预报
提示词:“获取纽约布法罗的天气预报摘要”
使用uv运行client.py,需要将保存工具的位置路径一同输入。
uv run client.py ../weather/weather.py
左右滑动查看完整示意
使用MCP实现
博客文章自动化审阅
现在我们已经配置好了客户端和服务器,准备开始解决一些实际应用场景。在这个示例中,我们将构建几个自定义工具,为LLM赋予网页浏览的能力。扩展MCP服务器的方式非常简单——你只需在现有的服务器文件中添加新功能,或者创建一个新的服务器文件即可。
为了演示这个过程,我们会在当前的服务器文件中加入几个非常实用的功能,并展示Claude如何智能地将它们组合使用,同时准确地区分各个工具的作用。
在开始编写新代码之前,记得先切换到MCP服务器所在的文件夹,并安装一些额外的依赖项。
cd ../weatheruv add requests markdownify
左右滑动查看完整示意
访问网页
我们为LLM提供了一个HTTP客户端,用于访问网页并从中提取markdown格式的内容。
# wheather.py (I know, I know...)
import reimport requestsfrom markdownify import markdownifyfrom requests.exceptions import RequestException
@mcp.tool()def visit_webpage(url: str) -> str: """Visits a webpage at the given URL and returns its content as a markdown string.
Args: url: The URL of the webpage to visit.
Returns: The content of the webpage converted to Markdown, or an error message if the request fails. """ try: # Send a GET request to the URL response = requests.get(url, timeout=30) response.raise_for_status() # Raise an exception for bad status codes
# Convert the HTML content to Markdown markdown_content = markdownify(response.text).strip()
# Remove multiple line breaks markdown_content = re.sub(r"\n{3,}", "\n\n", markdown_content)
return markdown_content
except RequestException as e: return f"Error fetching the webpage: {str(e)}" except Exception as e: return f"An unexpected error occurred: {str(e)}"
左右滑动查看完整示意
visit_webpage函数是一个用于通过HTTP GET请求从给定的URL获取内容的工具。它将获取的HTML内容转换为更简洁的Markdown格式,去除多余的换行符并处理边缘情况。该函数包含全面的错误处理,能够处理网络相关问题和意外错误,并在出现问题时返回适当的错误信息。
验证链接
# weather.py@mcp.tool()def validate_links(urls: list[str]) -> list[str, bool]: """Validates that the links are valid webpages.
Args: urls: The URLs of the webpages to visit.
Returns: A list of the url and boolean of whether ornot the link is valid. """ output = [] for url in urls: try: # Send a GET request to the URL response = requests.get(url, timeout=30) response.raise_for_status() # Raise an exception for bad status codes print('validateResponse',response) # Check if the response content is not empty if response.text.strip(): output.append([url, True]) else: output.append([url, False]) except RequestException as e: output.append([url, False]) print(f"Error fetching the webpage: {str(e)}") except Exception as e: output.append([url, False]) print(f"An unexpected error occurred: {str(e)}") return output左右滑动查看完整示意
validate_links函数接受一个URL列表,并检查每个URL是否有效、可访问。它尝试对每个URL发出HTTP GET请求,如果请求成功且返回非空内容,则认为该链接有效。该函数返回一个包含URL和布尔值(表示链接是否有效)的配对列表,并处理网络和一般异常的错误。
本篇作者
Giuseppe Battista
亚马逊云科技的高级解决方案架构师,负责英国和爱尔兰的早期阶段初创公司解决方案架构。
Kevin Shaffer-Morrison
亚马逊云科技的高级解决方案架构师,帮助数百家初创公司迅速启动并进入云端。
Jamila Jamilova
亚马逊云科技初创公司UKIR的解决方案架构师和Anthropic推广专家。
参考链接:
[1]https://modelcontextprotocol.io/quickstart/server
[2]https://modelcontextprotocol.io/quickstart/client
[3]https://modelcontextprotocol.io/introduction
[4]https://modelcontextprotocol.io/specification/2025-03-26
[5]https://docs.aws.amazon.com/bedrock/latest/userguide/conversation-inference-call.html
[6]https://docs.aws.amazon.com/bedrock/latest/userguide/tool-use-inference-call.html#tool-calllng-make-tool-request
[7]https://modelcontextprotocol.io/quickstart/server[8]https://docs.astral.sh/uv/getting-started/installation/
[9]https://boto3.amazonaws.com/v1/documentation/api/latest/guide/credentials.html
我们正处在Agentic AI爆发前夜。企业要从"成本优化"转向"创新驱动",通过完善的数据战略和AI云服务,把握全球化机遇。亚马逊将投入1000亿美元在AI算力、云基础设施等领域,通过领先的技术实力和帮助“中国企业出海“和”服务中国客户创新“的丰富经验,助力企业在AI时代突破。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









