 亚马逊AI芯片优化AI性能与成本案例
亚马逊AI芯片优化AI性能与成本案例




客户案例:使用亚马逊AI芯片优化AI性能和成本
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Trinium, Japanese Language Adaptation, Curriculum Training, Model Distillation, Small Language Models, Multimodal Model Deployment]
导读
随着您在业务规模上增加生成式人工智能的使用,模型开发和部署基础设施的成本上升可能会对您创新和提供令人愉悦的客户体验的能力产生不利影响。亚马逊云科技 Trainium和Amazon Inferentia在提供高性能人工智能训练和推理的同时,可将您的成本降低多达50%。参加本次会议,听取亚马逊云科技客户字节跳动、Ricoh和Arcee的分享,了解他们如何实现这些优势来发展业务并为最终用户提供创新体验。
演讲精华
以下是小编为您整理的本次演讲的精华。
2024年亚马逊云科技 re:Invent大会上举办了一场题为“客户案例研究:利用Amazon AI芯片优化AI性能和成本”的精彩会议。该会议深入探讨了生成式AI(genAI)的变革性影响,以及各公司如何利用亚马逊云科技 AI芯片(如Trinium和Inferentia)来训练和部署他们的genAI模型,实现无与伦比的成本效益和高性能。
亚马逊云科技的首席genAI专家Dewa Cribbenzo首先阐述了2024年塑造genAI格局的主导趋势,包括更大语言模型的出现、小型语言模型的兴起、多模态模型的激增以及AI代理和专家的到来。Cribbenzo强调亚马逊云科技在AI芯片方面的大量投资,尤其是最近推出的Trinium 2芯片,其计算性能高达1.3 PetaFLOPS。这款尖端芯片使得训练参数高达数万亿的大型AI模型成为可能。Cribbenzo表示,Trinium 2提供1.3 PetaFLOPS的计算能力,比亚马逊云科技上任何其他EC2实例都高出30%。Trinium 2提供4倍的计算能力、4倍的内存和4倍的高带宽内存带宽。Trinium 2实例在FP8下提供20.8 PetaFLOPS的计算能力、46TB/s的HBM带宽和1TB/s的NeuronLink速度,使其成为亚马逊云科技用于genAI训练和推理的最强大实例。
来自理光公司的Takashi Suzuki分享了他们利用Trinium基础设施开发日语大型语言模型(LLM)的经验。Suzuki阐述了理光的课程训练方法,该方法包括将英语LLM适应日语,同时保留其英语能力。这一过程分为三个阶段:快速阶段旨在通过纳入大量英语语料来最小化灾难性遗忘;慢速阶段专注于通过优先使用高质量日语语料并最小化英语语料来提高日语句子质量;中间阶段致力于通过使用大量语料进行循环训练来增强语言表示的稳健性。通过精心确定Trinium上的最佳节点配置,理光取得了显著成果,包括训练成本降低50%,训练时间缩短25%。Suzuki提到,在Trinium上采用最佳256节点设置后,理光的训练成本比GPU集群低50%,训练时间缩短25%,较上一年的45%成本降低和12%训练时间缩短有所改善。理光利用Neuron SDK 2.19进行开发工作,强调与亚马逊云科技开发人员团队密切沟通以了解此类软件开发工具包的可用性和调度情况的重要性。
RCIAGT的首席执行官兼联合创始人Mark McQuaid分享了他们利用Trinium训练以及Inferentia进行推理的小型专用语言模型(SLM)的专业知识。RCIAGT的旗舰模型,如Supernova(700亿参数)和Medias(140亿参数),在Hugging Face排行榜上名列前茅,展现了其卓越的性能。McQuaid强调在Inferentia实例上部署这些SLM的成本效益,他们的80亿参数模型比在g5.2xlarge GPU实例上运行的成本性能高32%,而他们的700亿参数模型与p4d和p5实例相比则极具成本效益。此外,RCIAGT的模型可在亚马逊云科技市场和SageMaker JumpStart上获得,支持一键部署到Trinium和Inferentia实例进行推理。RCIAGT最近推出了名为RC Orchestra的新产品,这是一个端到端的代理系统,提供了专门构建的AI代理及其SLM,使企业能够自动化任务并实现投资回报。
来自IBM的Armani分享了IBM通过Watson X平台专注于生成式AI的见解。他解释说,Watson X由三个核心组件组成:AI Studio提供工具、模型和能力来创建genAI解决方案;Watson Next Data是一个智能数据湖房,集成了数据和metadata;以及一个用于监控、观察和确保合规性的治理组件。Armani强调IBM与亚马逊云科技的合作关系,旨在使Watson X能够在亚马逊云科技 AI芯片上本地运行,并通过亚马逊云科技服务提供IBM的Granite基础模型。IBM的Granite模型专为企业用例而设计,重点是披露用于预训练和训练的整个数据集,确保法律合规性和版权遵从性,并提供完整的模型可识别性。Armani对AI代理的发展表示兴奋,这些代理结合了多个LLM和SLM,并强调IBM致力于优化这些代理系统的成本效益和可扩展性。IBM正与亚马逊云科技密切合作,将Watson X与Neuron SDK集成,并在Trinium和Inferentia实例上运行他们的模型。
来自ByteDance的Wong Peng讨论了他们利用多模态模型(如MAP(Modality as a Soft Prompt))的情况,该模型结合了文本、图像和音频输入来生成内容。ByteDance采用Inferentia全球部署MAP,吞吐量提高20%,成本降低13%。Peng预见,将代理纳入多模态模型用于自动化注释将成为下一个突破,能够生成高质量数据并进一步提升AI能力。他表示,ByteDance每天至少要处理数十亿次针对多媒体和视频数据的推理。ByteDance与亚马逊云科技工程团队密切合作,克服了将Hugging Face模型转换为Neuron框架的初始挑战,利用诸如Neuron Kernel Interface (NKI)等工具开发自定义内核和算子。
会议最后举行了小组讨论,演讲者就语言模型适应、模型蒸馏、小型模型的作用、AI代理以及AI芯片在可扩展和高成本效益genAI部署中的关键作用等话题进行了思考性的探讨。
Takashi Suzuki深入探讨了语言模型适应的领域,强调即使开源和专有模型扩大了语言覆盖范围,公司仍然需要将模型调整为特定语言。他强调了标记器的挑战,它们通常缺乏必要的词汇或效率来满足特定语言的需求,因此需要采用适应技术。Suzuki还谈到了前景广阔的模型蒸馏领域,并以最近的LLaMA 3.2模型为例,这是一种从较大模型中蒸馏出的较小模型。
Mark McQuaid分享了他对小型语言模型(SLM)未来的见解,他认为目标是不断缩小模型尺寸,同时保持或提高其准确性和功能适用性。他设想在未来,小型0.2-0.9亿参数的SLM可以在智能手机等设备上运行,并有望达到与700亿参数等大型模型相当的性能。McQuaid还讨论了SLM在代理系统中的作用,其中一系列较小的专用模型可以协作驱动复杂的工作流程,填补空白并补充一个更大的通用模型。
来自IBM的Armani就生成式AI的演进提供了他的观点,将其比作从固定流向可变流的过渡。他描述了初始阶段,开发人员专注于提示工程;接着是第二阶段,固定流可以通过数据进行支撑,正如经典的检索增强生成(RAG)用例所示,在Armani从事预售期间,这占据了90%的项目。Armani强调目前向完全自动化的genAI系统的转变,其中LLM负责规划、推理和反馈循环更新。他还强调了推理能力的重要性,以及出现了不仅测量准确性,还测量推理能力的基准。
来自ByteDance的Wong Peng分享了他对多模态模型未来的见解,承认视频数据带来的挑战,因为它包含空间和时间信息。他设想,对视频数据的深入理解将为机器人技术带来突破,使AI系统能够与现实世界互动并解决复杂问题。
演讲者一致认可AI芯片在实现可扩展和高成本效益的genAI部署中的关键作用。来自IBM的Armani强调与亚马逊云科技合作利用其基础设施和AI芯片的重要性,因为许多IBM客户的工作负载和数据都托管在亚马逊云科技上。他对AI芯片降低成本、提供高性能并实现与托管在亚马逊云科技上的数据无缝集成的潜力表示兴奋。
来自ByteDance的Wong Peng强调了AI芯片的必要性,并暗示目前对AI计算能力的需求仅仅是个开始,未来的需求可能是目前水平的100到200倍。
Mark McQuaid赞同了其他小组成员的观点,强调了在NVIDIA GPU之外的硬件上运行AI工作负载的好处。他提到了有时缺乏NVIDIA GPU的可用性,以及探索诸如Inferentia和Trinium等替代芯片选项可能带来更好的成本性能,这是令人信服的理由。RCIAGT正与亚马逊云科技团队密切合作,验证他们的架构,并确保他们的SLM可以在Trinium上高效训练并部署在Inferentia实例上。RCIAGT还是Trinium 2的设计合作伙伴,旨在进一步提高性能和成本效益。
下面是一些演讲现场的精彩瞬间:
演讲者承认,2024年生成式人工智能(genAI)在各个行业产生了变革性的影响,观众举手表示赞同。

亚马逊云科技专注于提高效率、节省成本,并优化大规模训练和部署大型语言模型的成本性能比,利用Tranium和Inferentia芯片作为更经济高效、可获取性更强的NVIDIA GPU替代方案。

Anthropic展示了他们基于Llama的最先进语言模型,包括Supernova、Virtuoso和Medias,这些模型在Amazon Trainium上进行训练,并针对Amazon Inferentia进行了优化,现已在Amazon Marketplace和SageMaker JumpStart上提供。

演讲者分享了对人工智能演进的兴奋之情,从提示工程师到利用可变流程和全自动生成式人工智能系统,这些系统能够规划、推理并提供反馈。
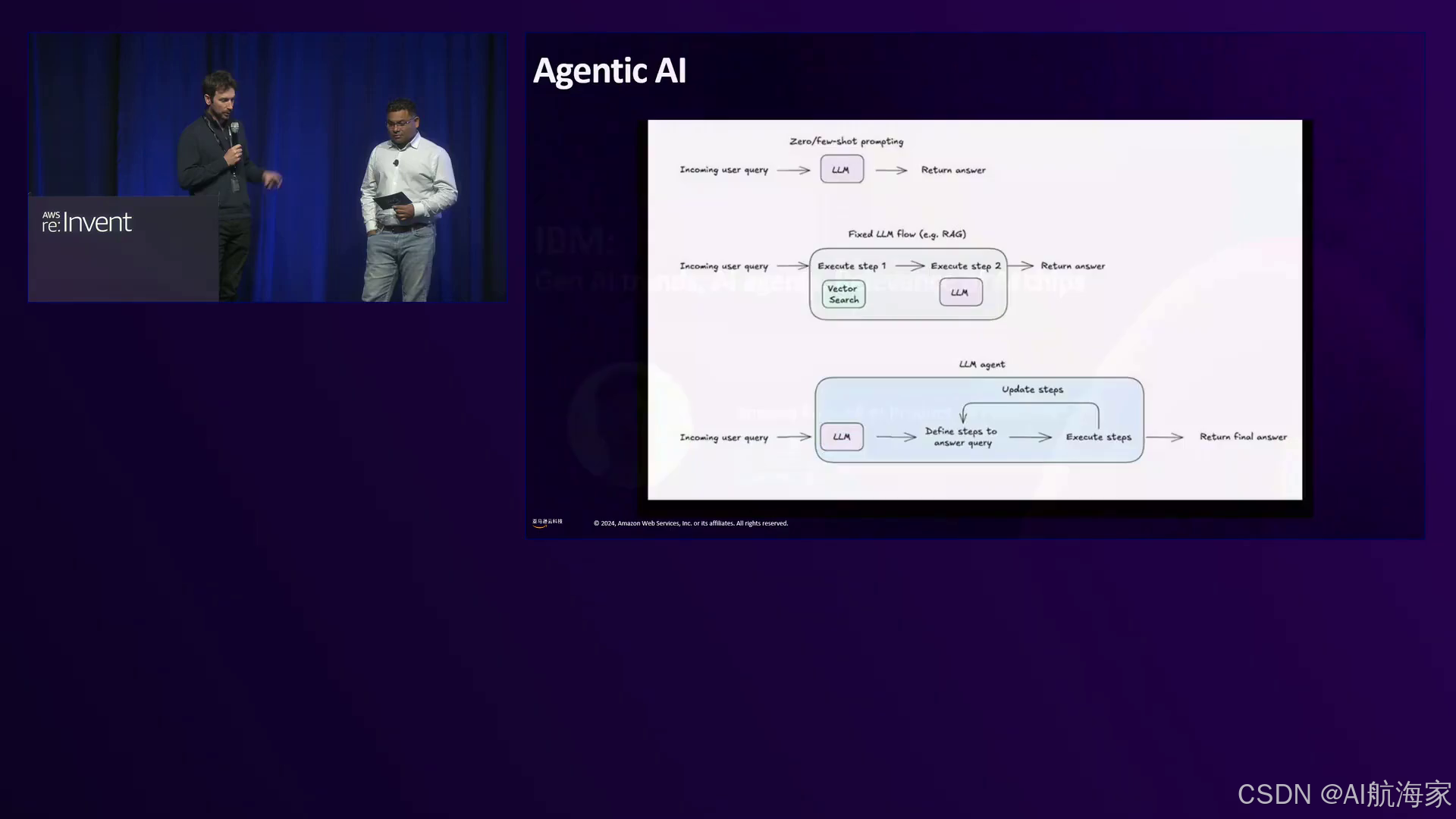
IBM高管强调了人工智能推理的重要性,以及与亚马逊云科技的合作伙伴关系,为客户提供高性能、低延迟和经济高效的人工智能解决方案。

Erman赞同地点头,因为演讲者强调了小型、面向任务的语言模型(SLMs)和健壮的人工智能应用评估框架的重要性。

演讲者将当前的人工智能状态比作黄金等有价商品的早期阶段,暗示人工智能的潜力远远大于我们目前所见。

总结
这段视频记录了在reInvent2024活动上的一场小组讨论,重点是利用亚马逊云科技的AI芯片Trinium和Inferentia来优化AI性能和成本效益。小组成员分享了他们各自公司在大规模部署生成式AI(genAI)模型时所面临的挑战和解决方案。
亚马逊云科技的首席genAI专家Dewa Cribbenzo介绍了这场会议,概述了genAI的主导趋势,包括更大的语言模型、更小的模型、多模态模型和AI代理。他强调亚马逊云科技在AI芯片如Trinium 2上的投资,可为genAI工作负载提供卓越的性能和成本效益。
来自理光公司的Takashi Suzuki分享了他们在Trinium基础设施上开发日语语言模型的经验。他讨论了为特定语言调整标记器和微调模型的挑战,以及课程训练和模型蒸馏技术的好处。Suzuki强调了与亚马逊云科技合作所带来的成本降低和训练时间缩短。
RCI GT RCI的首席执行官Mark McQuaid讨论了他们专注于小型专用语言模型(SLM)以及在Trinium和Inferentia实例上部署它们的节省成本潜力。他介绍了他们的RC Orchestra平台,该平台提供由SLM驱动的定制AI代理,使企业能够自动化任务并实现投资回报。
IBM人工智能平台产品管理副总裁Erman Andros分享了关于IBM的Watson X平台及其与亚马逊云科技的合作伙伴关系的见解。他强调了AI代理、推理和编排多个模型以适应可变工作流的重要性。Andros强调了AWSAI芯片在实现企业级AI解决方案的高性能和经济高效推理方面的作用。
字节跳动的Wong Peng讨论了他们在多模态模型方面的经验,将文本、图像和音频结合用于TikTok等应用。他分享了使用Inferentia实例的性能和成本优势,以及为特定语言和领域调整模型的挑战。
小组成员一致认为,Trinium和Inferentia等AI芯片对于实现经济高效和可扩展的genAI部署至关重要。他们强调需要在硬件、软件和模型架构方面持续创新,以充分释放genAI在各个行业和应用场景中的潜力。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









