



简化企业采用生成式 AI 的过程(由 NVIDIA 赞助)
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, NeMo, Generative Ai Adoption, Enterprise Ai Adoption, Nvidia Ai Frameworks, Large Language Models, Model Inference Optimization]
导读
通过提升客户体验、简化运营流程和提高生产力,生成式 AI 正在为各行各业的创新和业务增长带来革命性的变化。参加本次讲座,了解大型语言模型(LLMs)这一生成式 AI 的基本支柱,并了解如何利用 NVIDIA 解决方案来构建、定制、部署和保护 LLMs,从而为各种企业应用提供动力。NVIDIA AI 是世界上先进的生成式 AI 全栈平台,它包括加速基础设施、AI 框架、企业服务和工具,能够让您更轻松地构建自定义 LLMs,并将您的生成式 AI 解决方案更快地推向市场。本讲座由亚马逊云科技合作伙伴 NVIDIA 为您带来。
演讲精华
以下是小编为您整理的本次演讲的精华。
在尖端科技的领域,NVIDIA不仅仅是一家硬件公司,而是一股超越界限的强大力量。Peter Dykis是NVIDIA的一位解决方案架构师,他与推理专家Jehan一起,在Amazon Web Services re:Invent 2024活动上,带领观众探索了企业如何简化采用生成式AI的复杂过程。
NVIDIA不仅擅长硬件,更是一家全栈AI公司,提供针对各种用例(包括新兴的生成式AI领域)优化的容器、软件和框架。他们与亚马逊云科技的合作形成了共生关系,让企业能够利用NVIDIA的GPU实例,应用于广泛的领域。高性能的P5实例由强大的H100 GPU驱动,在大规模训练方面表现出色;而经济实惠的G5实例则由A10G GPU驱动,专注于高效推理。此外,T4G实例是一款针对视觉密集型工作负载的图形处理器。NVIDIA的Triton推理服务器与Amazon SageMaker无缝集成,简化了模型部署,实现了硬件和软件的完美融合。
Peter分享了一些成功案例,展示了NVIDIA与Amazon团队的协同效应。例如,Amazon Catalog团队利用TensorRT和Triton推理服务器,实现了延迟降低和吞吐量提升,从而更高效地为卖家自动生成产品列表。同样,Amazon Music团队也见证了延迟降低、与CPU相比显著降低,以及拼写纠正模型延迟的改善。此外,NVIDIA团队还帮助他们利用张量核心和H100的能力,将训练时间缩短,并显著提高了GPU利用率。
负责实时产品搜索拼写检查的Amazon Search团队面临着严格的吞吐量和延迟要求。通过利用Triton和TensorRT,他们实现了低延迟和吞吐量提升。值得一提的是,Model Analyzer工具简化了配置过程,将原本需要数周的工作缩减到几个小时内。
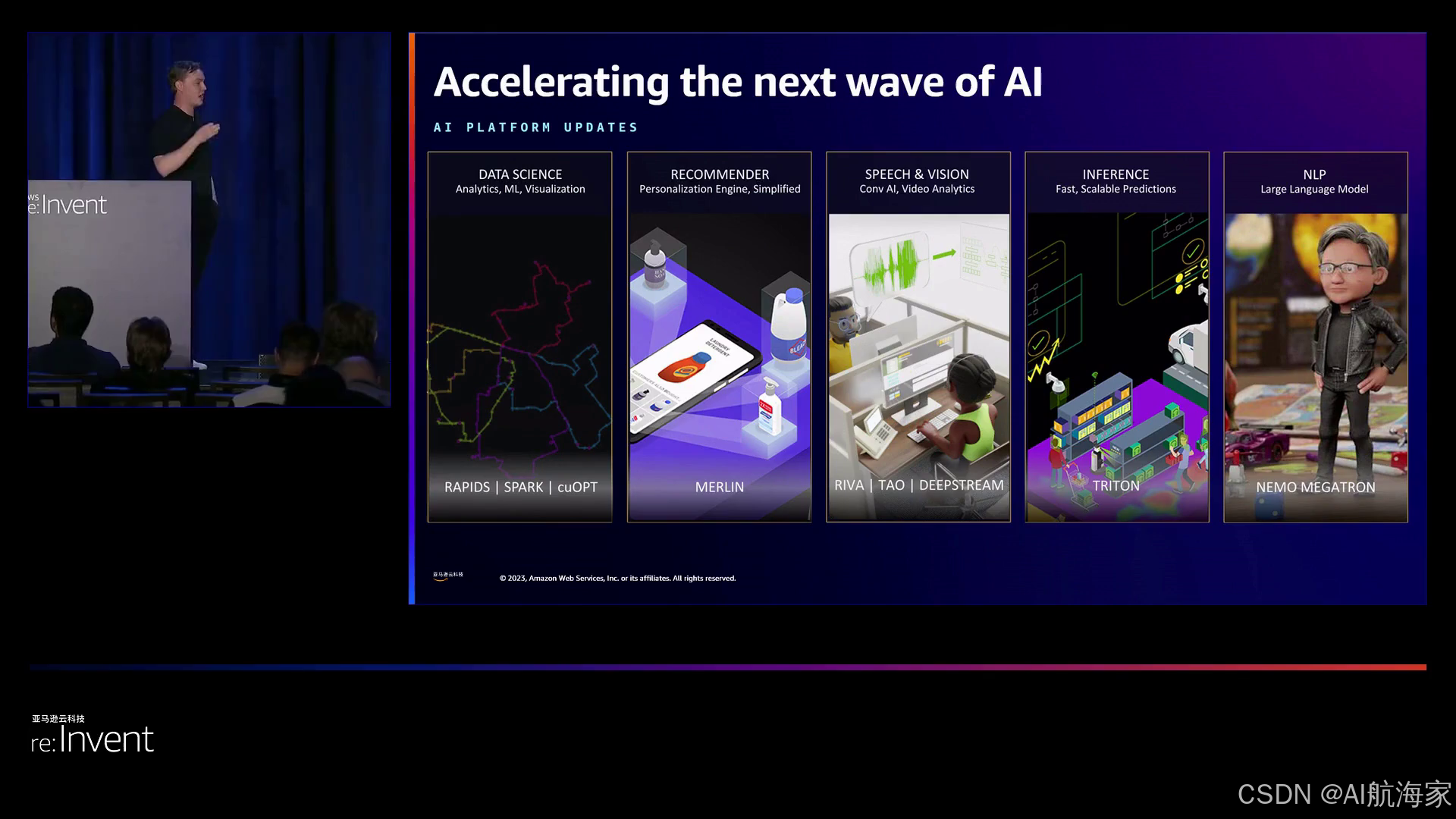
Peter还介绍了NVIDIA的NGC (NVIDIA GPU Cloud)平台,这是一个集合了NVIDIA软件、容器和预训练模型的资源库。该平台为NVIDIA的各种框架提供了入口,每个框架都针对特定任务进行了优化。例如,RAPIDS专注于数据科学领域,而Merlin则专门用于推荐系统。TAO和DeepStream分别擅长计算机视觉和语音应用。然而,这个阵容中的重点是NeMo,一个专门为复杂的生成式AI而设计的框架。
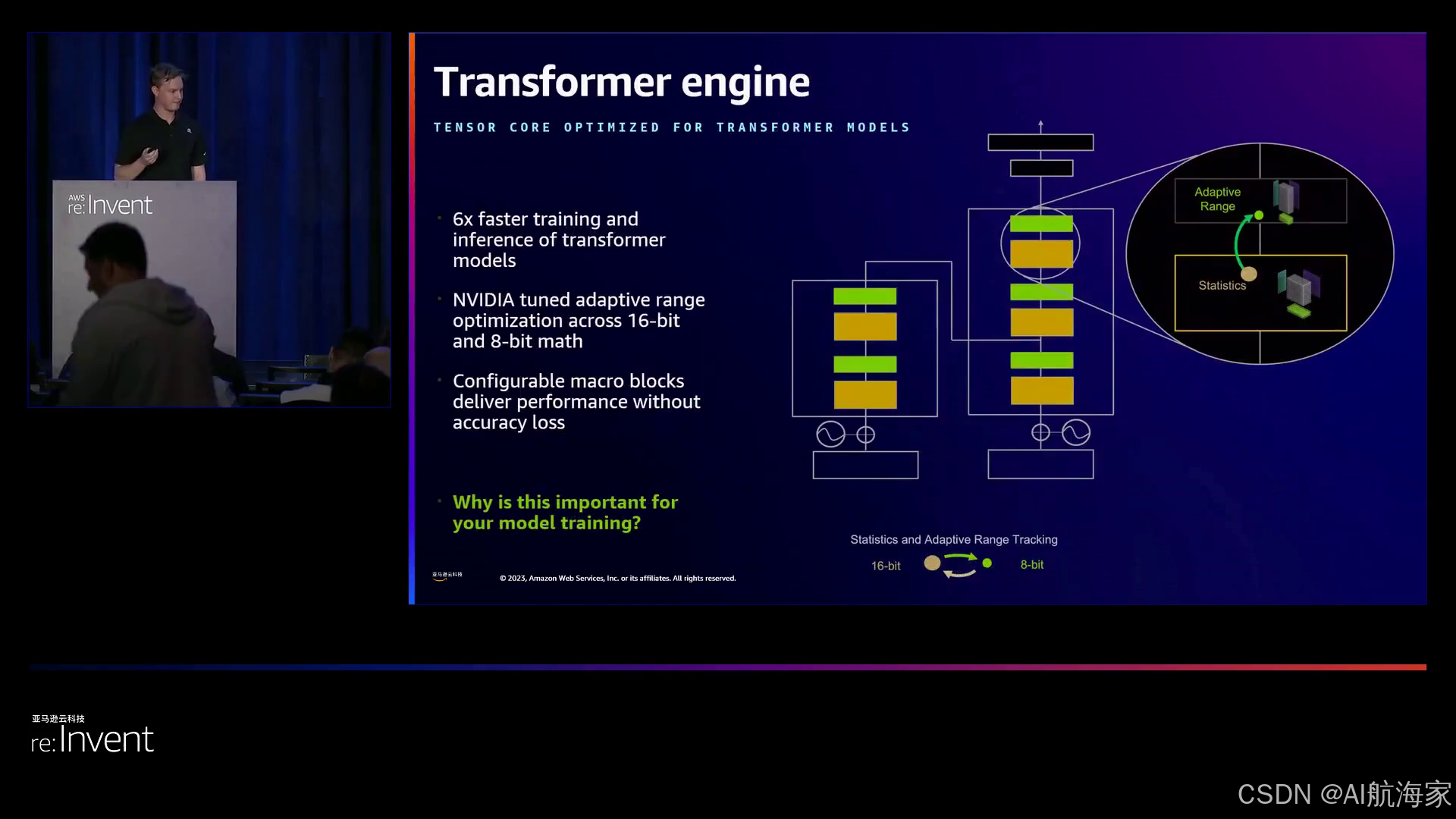
当Peter揭示NVIDIA最新的H100 GPU的能力时,观众们一窥未来科技的风采。这款先进芯片配备了革命性的Transformer Engine,可以动态调整神经网络中数学运算的精度,从而实现更快的训练和推理速度。第四代NVLink确保GPU之间的网络传输速度极快,而机密计算支持为敏感工作负载增添了额外的安全层。
Peter展示了H100在大型语言模型(LLM)方面的性能提升,令观众印象深刻。与前代A100 GPU相比,H100实现了训练时间缩减、P-tuning时间减少,以及推理吞吐量的显著提升,巩固了NVIDIA在生成式AI创新领域的领先地位。
NVIDIA生成式AI框架NeMo成为焦点,Peter深入探讨了它的内部结构。NeMo是一个端到端的解决方案,涵盖了数据管理、分布式训练、模型定制以及与TensorRT、LLM和Triton推理服务器的部署。NeMo的核心Megatron Core库让企业能够将Transformer模型扩展到更大规模,利用张量并行、管道并行和分布式优化器等技术。
Peter强调了NeMo对多种模型架构的支持,包括GPT、T5、BERT以及Stable Diffusion和CLIP等多模态模型。然而,NeMo真正的力量在于其模型定制工具,让企业能够根据特定需求对模型进行微调。无论是提示工程、P-tuning、参数高效微调,还是通过强化学习进行指令微调(RLHF),NeMo都为企业提供了全面的工具,让他们能够量身定制生成式AI模型。
Peter介绍了NeMo的数据管理工具,展示了GPU加速的数据处理、去重和过滤能力。这个工具让企业能够从海量数据中筛选出高质量、相关的信息,确保模型训练时不会受到重复和无关内容的影响。
考虑到配置和优化大规模模型的复杂性,Peter推出了NeMo的自动配置工具,为企业提供了一条生命线。该工具会考虑训练约束,并提供模型大小和配置的建议,消除了猜测的需要,确保资源利用的高效性。例如,如果一家企业有16个节点可用于6天的训练,该工具可能会建议使用5B参数模型作为合适选择。
Peter还讨论了NVIDIA的基础模型,如GPT-8B、GPT-22B和GPT-43B,它们分别满足不同的响应时间和准确性需求。此外,NeMo对社区模型如Falcon、LLaMA和MPT的支持,体现了NVIDIA致力于构建开放和协作的生态系统。
针对生成式AI领域的一个关键问题,Peter阐述了NeMo的检索增强模型(InforM)和防护措施。这些功能让企业能够控制和引导模型输出,确保主题相关性、安全性和可靠性,从而降低不受约束的生成式模型带来的风险。
当Jehan接手演讲时,焦点转移到了生成式AI推理方面。Jehan强调了在生产环境中部署模型所面临的挑战,并强调了可靠和可扩展解决方案的必要性。
NVIDIA的Triton推理服务器应运而生,这是一个开源解决方案,承诺提供快速、可扩展和简化的跨框架、查询类型和平台的推理。Jehan介绍了Triton的架构,揭示了动态批处理、模型编排和全面监控功能的精妙组合,确保了资源利用的最优化和与现有基础设施的无缝集成。目前,Amazon Search、Amazon Ads和Amazon Catalog等团队都在利用Triton来最大化GPU利用率。
Triton的优化功能,如并发模型执行和模型分析器,让企业能够微调配置,实现性能和效率的最大化。业务逻辑脚本和流式推理的解耦模式进一步增强了Triton的灵活性,满足现代企业的多样化需求。
Jehan的演讲转向了NVIDIA的GPU优化推理解决方案TensorRT,它利用量化、层融合等优化技术,从NVIDIA硬件中提取出更好的性能。观众亲眼目睹了TensorRT带来的加速,包括计算机视觉领域的加速、语音识别领域的提升,以及NLP、Transformer、语音合成和推荐系统等领域的改进。
然而,真正的亮点是专为大型语言模型而设计的TensorRT LM。TensorRT LM承诺提供卓越的性能、多GPU和多节点支持,以及与Triton推理服务器的无缝集成。Jehan带领观众了解了使用TensorRT LM的工作流程,从PyTorch和NeMo等框架中编译模型,到与Triton的部署。
Inflat Batching技术是TensorRT LM的核心,它能够最大限度地利用GPU,处理不同序列长度的输入,而无需填充,这一创新令观众印象深刻。
Jehan的演讲以GPT-J 6B和LLaMA 7B等模型的性能基准测试作为结束,展示了NVIDIA解决方案的切实优势。观众亲眼见证了GPT-J 6B实现的性能提升,以及LLaMA 7B利用张量并行技术突破单GPU限制,取得的加速效果。
随着这场引人入胜的演讲落下帷幕,Peter和Jehan向观众发出了行动号召,并提供了丰富的资源,让他们能够踏上探索生成式AI的旅程。NVIDIA全面的解决方案,从NeMo的训练到Triton和TensorRT LM的优化推理,成为了创新的引领者,为企业在全球范围内简化生成式AI的采用铺平了道路。
在科技日新月异的时代,NVIDIA以开拓者的姿态铭刻了自己的名字,不断突破极限,让企业能够驾驭变革性的生成式人工智能的力量。凭借对创新、协作和优化的坚定承诺,NVIDIA为生成式人工智能铺平了道路,使其不再是遥不可及的梦想,而是各种规模和行业的企业都可以触及的现实。
下面是一些演讲现场的精彩瞬间:
在这一重要时刻,演讲者概述了当天的议程,包括亚马逊云科技团队在生成式人工智能领域的工作、NVIDIA人工智能在亚马逊云科技上的应用、相关软硬件以及框架等内容。

亚马逊云科技与NVIDIA的合作为云端到边缘提供了一系列GPU实例,满足从大规模训练到推理部署的各种需求。

在亚马逊云科技上,NGC是获取NVIDIA软件、容器和预训练模型的重要平台,简化了部署和使用过程。

亚马逊云科技在每个层面都提供了框架,包括RAPIDS、SPARK-CUDF用于数据科学和分析,QMML用于机器学习,Merlin用于推荐系统,TAO和DeepStream用于计算机视觉,ReVA用于语音,Triton Inference Server用于模型推理,以及NeMo用于自然语言处理和生成式人工智能。
通过Transformer Engine的动态适应16位和8位数学运算,H100实现了6倍更快的训练和推理速度,同时保持了精度。
张量并行训练通过将模型层水平分割到不同GPU上,实现了单节点内的并行计算,从而支持更大规模的模型训练。

NVIDIA GPU为从计算机视觉到语音识别等大多数计算密集型工作负载提供动力,并提供NeMo框架用于训练,Triton开源模型服务解决方案用于任何类型的模型和硬件,TensorRT用于在GPU上获得最佳性能,以及人工智能企业支持服务直接获取NVIDIA内部专家的帮助。

总结
该演讲概述了NVIDIA为简化企业采用生成式AI模型而提供的解决方案。它重点介绍了NeMo框架,用于高效大规模训练大型语言模型(LLMs)和多模态模型。NeMo的关键特性包括数据管理工具、采用各种并行化技术的分布式训练、模型定制功能(如提示学习和强化学习)以及高效超参数搜索和模型基准测试工具。
在推理方面,Triton推理服务器被介绍为一种开源解决方案,用于部署具有动态批处理、并发模型执行和模型编排等优化的模型。NVIDIA的推理优化框架TensorRT通过量化、内核融合和多流执行等技术提供了显著的性能提升。最近推出的TensorRT LM软件包专门针对高效部署大型语言模型,支持并行化策略和优化内核。
演讲者强调了NVIDIA全栈AI产品,从优化的软件容器和框架到强大的GPU硬件(如H100张量核GPU)。他们还强调了与亚马逊云科技团队的成功合作,将NVIDIA解决方案集成到亚马逊云科技服务(如SageMaker)中。呼吁企业利用NVIDIA的训练和推理解决方案,包括NeMo框架、Triton推理服务器和TensorRT,以简化和加速生成式AI模型的采用。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。亚马逊云科技致力于成为企业构建和应用生成式AI的首选,通过生成式AI技术栈,提供用于模型训练和推理的基础设施服务、构建生成式AI应用的大模型等工具、以及开箱即用的生成式AI应用。深耕本地、链接全球 – 在中国,亚马逊云科技通过安全、稳定、可信赖的云服务,助力中国企业加速数字化转型和创新,并深度参与全球化市场。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









