



使用Amazon Amplify构建全栈AI应用
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Amazon Web Services Amplify AI Kit, Build Full-Stack Ai Applications, Define Ai Functionality, Secure Data Access, Conversational Interfaces, Ai Tools]
导读
Generative AI正在改变全栈开发。在本次会议中,了解Amazon Amplify、Amazon Q和Amazon Bedrock如何协同工作,以简化生成式AI应用的构建过程。了解Amplify如何使开发人员能够构建由Amazon Bedrock支持的AI驱动功能,如智能搜索、摘要生成、内容创作和交互式聊天机器人。本次会议还将演示Amplify与Amazon Q如何加速您的开发过程。
演讲精华
以下是小编为您整理的本次演讲的精华。
视频一开始,受人尊敬的演讲者Danny Banks、Amazon Amplify团队的首席设计技术专家、Banjo Biami、热衷于构建和人工智能的高级开发者代言人、以及Ali Spittel、曾在Amplify团队工作四年的北美开发者代言人主管进行了自我介绍。
Ali概述了他们将要探讨的主题,包括Amplify AI工具包、亚马逊的AI构建工具,以及构建AI后端、聊天用户界面、对话式搜索和现场编码的演示。为了了解观众的熟悉程度,她询问了他们之前是否使用过Amplify,有相当多的人举手表示熟悉。然后她要求观众对自己的AI能力进行1到5的评分,收到了不同程度的回应,表明他们的专业水平各不相同。
Danny继而阐释了亚马逊云科技 AI堆栈,分为三个不同层次。在最基础的层面,他提到了像Amazon Trainium和Amazon Inferentia这样的定制芯片,以及连接到EC2实例的GPU,用于训练自定义模型、微调和推理端点。他强调了Amazon SageMaker是一套全面的功能,专为希望训练自己的模型、管理自定义数据集和利用机器学习数据管道的机器学习从业者而设计。
在上一层,Danny表示,这是大多数构建者和开发者通过Amazon Bedrock利用AI的地方,可以访问各种模型,包括Claude、Metatravel和亚马逊自己的模型。
在最顶层,有一些应用程序在幕后利用了生成式AI,比如Amazon CodeWhisperer,旨在让软件开发人员可以无缝地集成到IDE和控制台中,以及更多面向企业用户的Amazon CodeGuru,主要用例是与PDF对话。
为了说明Amazon Bedrock上可用模型的广度,Danny展示了一张幻灯片,但警告说由于Anthropic、Cohere和Meta Stability AI等提供商不断推出新模型,这张幻灯片很快就会过时。他强调,通过修改一行代码,使用Converse API就可以灵活地尝试不同的模型。
Danny演示了使用简单的扩散模型生成抽象绘画的能力,强调更详细的提示会产生更好的结果,突出了提示工程既是一门艺术,也是一门科学。
转而介绍Amazon CodeWhisperer,Danny解释说它可以无缝集成到Visual Studio Code等IDE中,用户可以免费安装,从而可以提出问题、分析代码库,并获得内联聊天补全和代码建议。
Ali介绍了Amazon Amplify,这是一款为前端和全栈开发人员量身定制的工具,包含了构建Web和移动应用程序所需的一切。使用Amplify,开发人员可以在几分钟内创建由数据库支持的API,仅用几行代码就可以实现与公司品牌相符的定制和安全的身份验证流程,部署由Next.js或Astro等框架构建的服务器端渲染应用程序,集成由Amazon S3支持的文件存储,以及添加无服务器功能。
Ali强调最近推出的亚马逊云科技 Amplify Gen 2,这是第一代基于CLI的工具的进化版本,使开发人员能够用TypeScript编写整个后端,使用TypeScript定义数据、身份验证、存储和其他组件,全部建立在Amazon CDK之上。虽然Amplify可以开箱即用地简化某些服务的使用,只需很少的代码,但CDK集成使其能够无缝连接任何200多个亚马逊云科技服务,而不需要相同级别的抽象。
为了演示创建Amplify应用程序,Ali演示了使用npm create amplify@latest命令初始化应用程序的过程,该命令会安装必要的依赖项。完成后,运行amplify sandbox命令会为每个开发人员设置一个隔离的开发环境,使他们能够在开发阶段快速部署资源,而不会干扰其他团队成员或部署环境。
深入探讨Amplify Data,Ali展示了如何使用全栈TypeScript创建数据模型,确保类型安全的数据获取和建模。授权规则在代码中定义,可以通过一行代码实现基于所有者的授权等功能。实时API默认启用,与静态API相比无需额外代码。此外,Amplify Data支持几乎任何数据源,不限于DynamoDB。
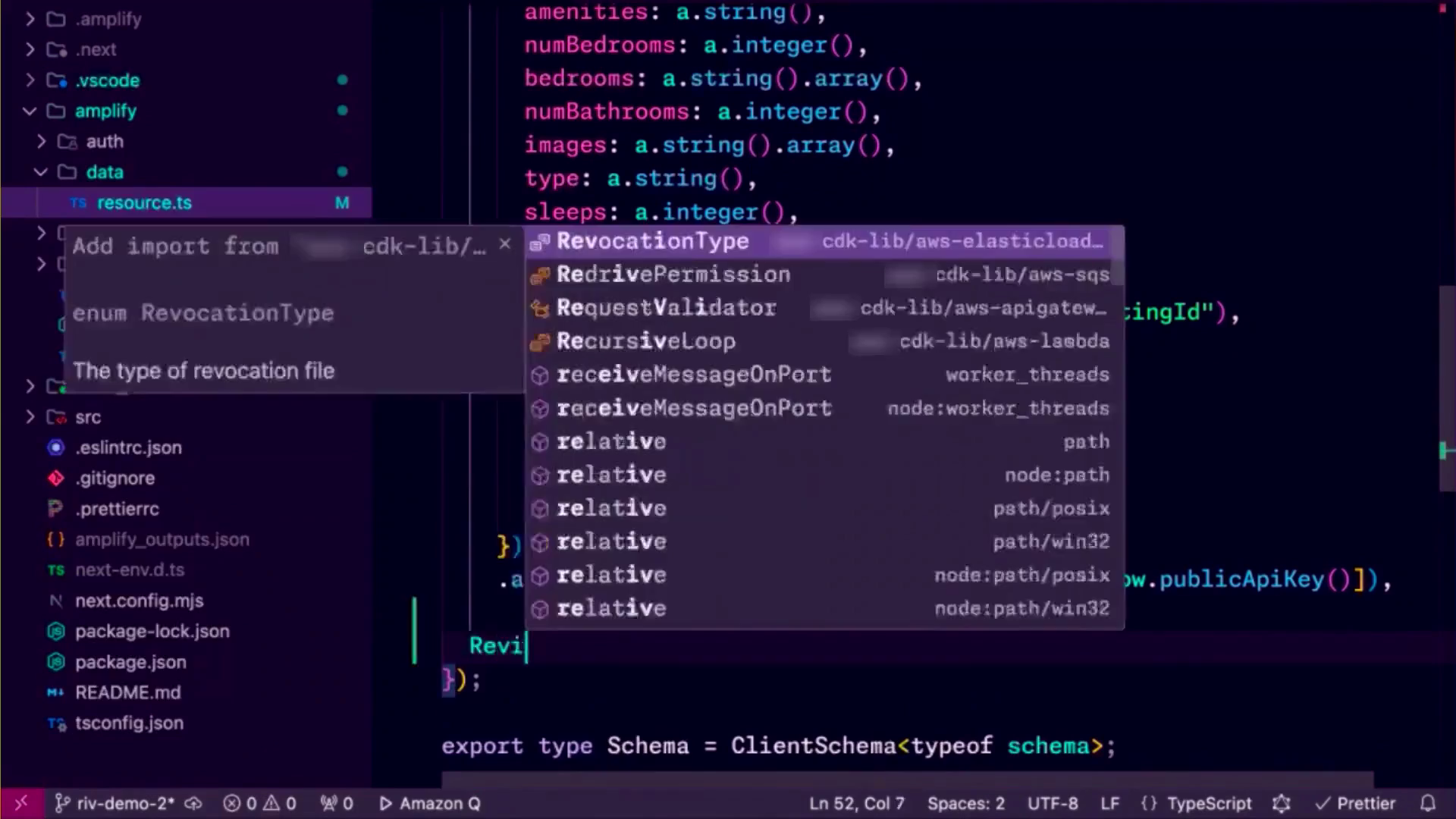
Ali演示了在Amplify中添加新模型,利用Amazon CodeWhisperer生成一个“review”模型并建议字段。她根据自己的需求修改了一些字段,如文本和分数,并添加了日期字段。底部的授权规则允许基于所有者的身份验证和公共API密钥,还可以进一步指定公共API密钥的只读访问权限。
在客户端,Ali展示了如何在前端与数据模型交互,通过提供之前定义的listing、reviewer、date、text和score字段来创建新的review。要列出数据库中的评论,她展示了client.models.review.list命令。
Amplify中的身份验证遵循类似的模式,可以启用定制的身份验证流程和登录体验,以满足应用程序的需求,并进行细粒度的访问控制。Ali演示了通过在TypeScript代码中定义电子邮件验证来添加身份验证,包括带有表情符号的自定义验证电子邮件主题行。在客户端,她使用了React的Authenticator组件,将需要身份验证的所需内容包装在其中,这个组件提供了一个完整的登录体验。她展示了创建新账户、验证电子邮件以及自定义主题行的实际效果。
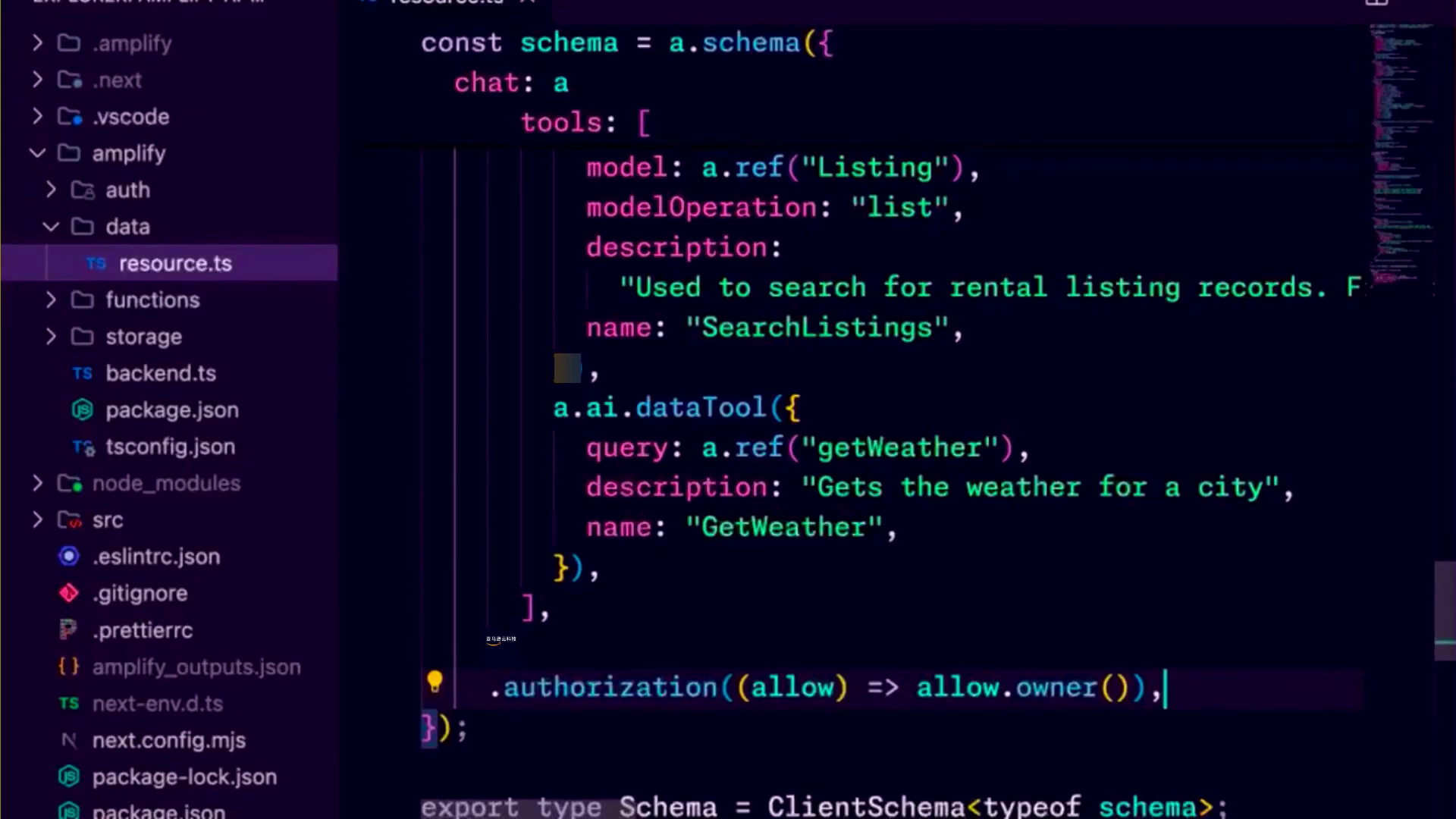
Danny接手将AI和Amplify的概念结合起来,对Amplify AI工具包感到兴奋,这是团队在过去一年中一直在构建的。他承认,虽然这不是Amplify在这段时间内的唯一新增功能,但它确实是他一年多来工作的重点,其起源可以追溯到去年的re:Invent大会。
与开发人员的对话凝聚了三个关键主题,塑造了Amplify AI工具包的发展。第一个主题是为Amazon Bedrock提供代码优先的开发人员体验,建立在Amplify Gen 2的功能之上,使开发人员能够在TypeScript文件中定义他们的AI功能,特别是在Amplify数据资源文件中。这种方法利用了每个开发人员的沙箱,支持本地开发和云开发人员沙箱中的实时更新,与AppSync API和Bedrock中的Lambdas等实际云资源交互。准备就绪后,推送分支会触发Amplify同时部署后端和前端,确保无缝同步。
第二个主题是为大型语言模型(LLM)提供对数据的安全访问,强调了数据访问在构建沉浸式生成式AI应用程序中的重要性。Amplify Gen 2后端数据构造简化了这一过程,可以轻松地让LLM访问在Amplify中定义的数据或任何外部数据源或亚马逊云科技服务。
第三个主题是加强对话式界面的开发,旨在超越传统的聊天机器人界面,通过创建生成式UI,让LLM能够以自定义组件作出响应,使任何人都可以轻松构建对话式体验,无论是聊天机器人、对话式搜索还是其他交互式界面。
为了说明这些概念,Danny继续构建一个评论总结功能,概述了三个关键点:通过AppSync为客户端请求提供对Amazon Bedrock的安全访问、基于后端定义的类型安全客户端,以及用于处理状态和网络请求的React钩子。
Danny已经使用React、Next.js和Amplify构建了一个简单的度假房屋租赁应用程序,类似于Vrbo或Airbnb,用户可以浏览房源、阅读评论并预订住宿。他要引入的新功能是一个“生成总结”按钮,点击后将调用Amazon Bedrock来生成所选房源评论的AI总结。
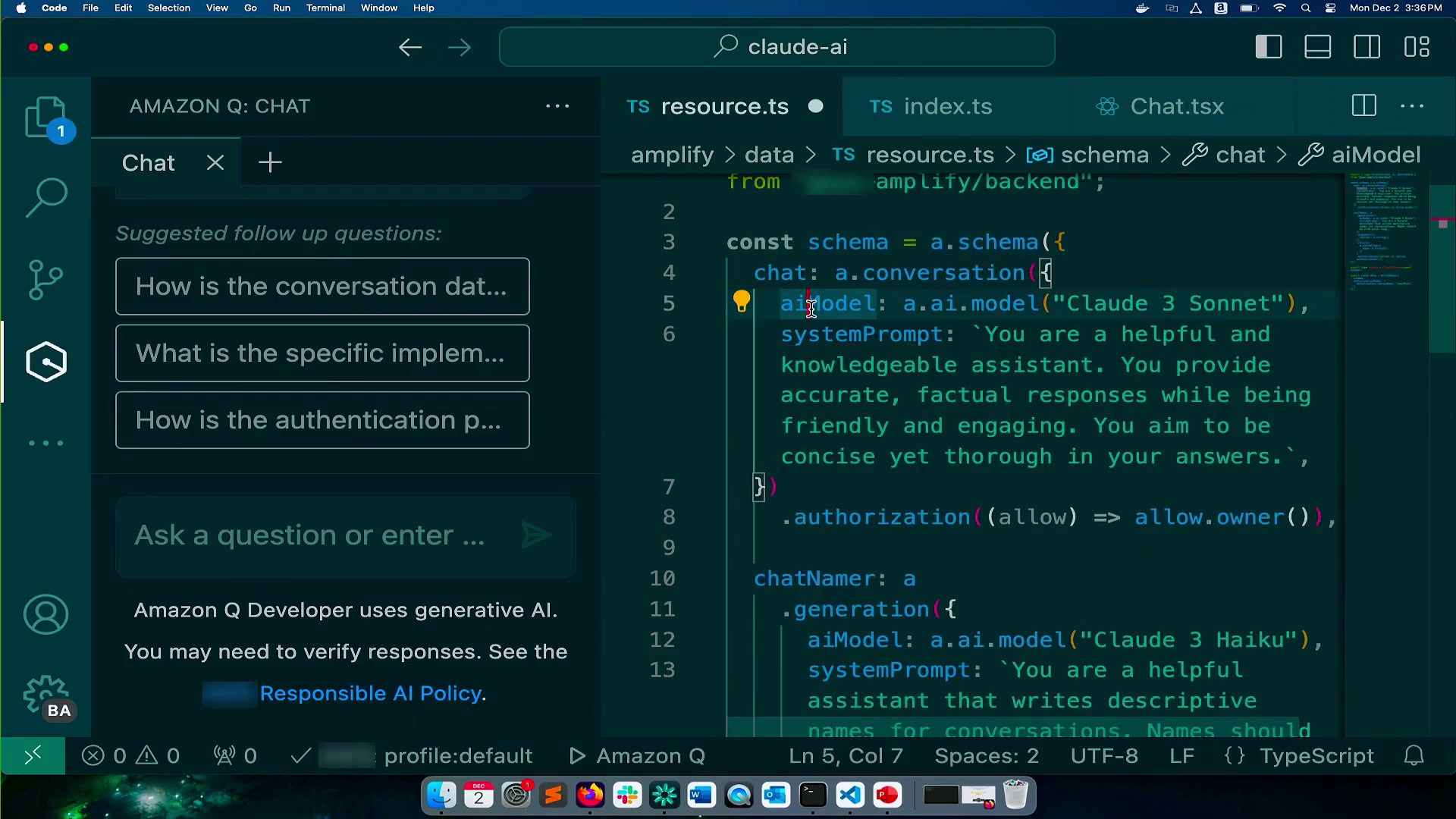
在Amplify数据资源文件中,Danny添加了一个名为“Review Summarizer”的新生成式API,指定它将生成数据。然后,他从Bedrock中选择要使用的AI模型,在这种情况下是Claude 3.5 Sonnet。他定义了一个系统提示,概述了所需的行为:提供评论的简明总结,可能包括对总结长度的指导。他指定了此函数的参数或输入,即表示评论的字符串数组。预期的输出是一个具有summary属性的对象,其中包含一个字符串。为了确保适当的授权,Danny将规则设置为只允许经过身份验证的用户访问此API。
转到React组件,Danny移除了一个模拟实现,并使用了来自Amplify AI Kit的useAIGenerationReact钩子,该钩子基于后端定义是类型安全的,可以识别reviewSummarizer生成路由。它返回React状态和一个处理程序,Danny在用户点击“生成总结”按钮时调用该处理程序,Amplify AI Kit会处理其余部分。
随着这些更改,应用程序现在具有“生成摘要”按钮。当用户点击它时,请求将发送到 AppSync,AppSync 将使用数据调用 Bedrock,接收 AI 生成的摘要,并将其显示给用户。Danny强调,这一功能仅需几十行代码即可实现,所有代码都在单一代码库中,无需离开 IDE。
Ali接手添加对话式搜索体验,概述了四个要求:支持多轮对话和流式响应、多模式搜索以允许上传图像、能够查询应用程序现有数据中的房源信息、以及使用自定义 UI 组件以交互方式显示结果,而不是纯文本聊天界面。
预期的体验是用户说“给我看看这种风格的房源”并上传一张图像,然后大型语言模型(LLM)将搜索数据库中具有类似风格的房源,并使用 UI 组件而不是纯文本来呈现。
Ali首先返回数据文件,选择 AI 模型Claude 3.5 Haiku。她创建了一个系统提示,将 LLM 定义为一个有助于房屋租赁查找的助手,并添加了一个基于所有者身份验证的授权模型。
接下来,Ali在 React 中使用 useAIConversation 钩子,检索消息并将它们插入 AIConversation 组件。她传入消息、加载微调器和 handleSendMessage 函数,创建了一个由 Amazon Bedrock 提供支持的安全聊天,实现与 LLM 的对话,仅需几十行代码即可完成。
回到数据资源文件,Ali添加了工具以授予 LLM 访问应用程序中的数据。她选择“Listing”模型,并创建了一个名为“searchListing”的工具来搜索租赁房源。现在,当被要求寻找“海边的租赁房源”时,LLM 可以查询数据库中已有的房源并建议相关选项。
Danny插话深入探讨工具的概念,也称为函数调用,它为 LLM 提供了访问某些数据或信息的方式。由于 LLM 是在大量静态数据上训练的,因此它们缺乏关于当前世界状态或应用程序特定细节的知识。
该过程涉及描述 LLM 可以访问的工具,例如一个接受城市字符串作为输入的 getWeather 工具。当收到诸如“拉斯维加斯的天气如何?”这样的用户消息时,并给出了 getWeather 工具的定义,LLM 可能会回应“嘿,我想调用 getWeather 工具,输入为’拉斯维加斯’”。
然后由应用程序所有者或代码来调用该工具,例如 getWeather 函数或 API,并将结果传回给 LLM。然后,LLM 会收到包含结果的消息历史记录,从而可以继续其思考过程。这个循环可能会发生多次,LLM 可以选择多个工具依次使用,需要开发人员管理编排。
Amplify AI Kit 旨在减轻这种无差别的繁重工作,通过处理工具调用和编排。如前所示,开发人员只需定义一个数据工具并授予它访问“Listings”等模型的权限。Amplify AI Kit 然后向 LLM 描述工具的输入,在请求时调用工具,检索数据,以结果重新提示 LLM,并将响应流式传输回客户端。
至关重要的是,Amplify AI Kit 代表用户授权工具调用,确保 LLM 无法访问超出用户权限的数据。例如,在一个待办事项应用程序中,每个用户只能看到自己的任务,如果用户询问“我有哪些未完成的待办事项?”时,LLM 将只能访问该用户的任务,而不是系统中的所有任务。
Danny强调,在构建具有数据访问权限的生成式应用程序时,他们投入了大量精力来确保适当的授权和访问级别,将所有内容通过 Amazon AppSync 作为 AI 网关层进行管理。
为了演示添加基于自定义查询的数据工具,Danny定义了一个 getWeather 函数,使用 API 密钥访问外部 API。然后,他指定 LLM 可以访问这个名为 getWeather 的工具,无需描述输入,因为它们已在自定义查询定义中定义。
回到对话,当 Danny 问“那里的天气怎么样?”时,LLM 根据之前的上下文意识到是指加利福尼亚州圣地亚哥附近的米申海滩。它调用 getWeather 工具,输入“米申海滩”,Amplify AI Kit 负责调用该工具,返回结果,并以温度、风速等详细信息作出回应,提供丰富的对话体验。
然而,Ali指出 UI 仍然很基础,建议使用自定义组件来增强它。她更新了 AIConversation 组件,显示当前登录用户的用户名和头像,并在 LLM 的响应中渲染 markdown 格式以提高可读性。
Ali随后引入了上传图像进行搜索查询并使用自定义 UI 组件进行响应的功能。在 AIConversation 组件中,她启用了图像上传附件,并将响应组件定义为普通的 React 组件,这些组件可以具有内部状态并获取数据。这些组件,如房源卡片和预订卡片,接受诸如房源 ID 的属性,允许 LLM 使用这些组件而不是纯文本进行响应。
回到演示,Ali提示 LLM“给我看看这种风格的房源”,并上传一张海滩图像。LLM 理解图像,查询数据库中的海滩房源,并通过渲染相关详细信息的房源组件作出响应,仅需大约 50 行代码,无需离开 IDE。
然后,Danny将话题转交给 Banjo,讨论 Amazon Bedrock 知识库。
Banjo解释说,知识库是一个完全托管的检索增强生成(RAG)工作流,允许用户上传数据源(如 PDF),并使 LLM 能够提取和与这些信息进行交互。当用户询问与内容相关的问题时,知识库管道会将文本分块为可管理的部分,通过嵌入模型将文本转换为数值向量,并将这些向量存储在向量存储中。用户的问题也会通过嵌入模型,然后算法可以从向量存储中搜索相关上下文,并将其包含在 LLM 的提示中,从而根据提供的上下文产生更相关的响应。
Banjo演示了如何使用 亚马逊云科技 AppSync JavaScript 解析器将 Amazon Bedrock 知识库连接到对话组件。他定义了一个请求和响应函数,AppSync JavaScript 解析器将调用这些函数,指定要访问知识库 API 的资源路径并传入检索查询参数。结果将被字符串化并发送回来。
定义了 JavaScript 解析器后,Banjo在数据模式中创建了一个自定义查询,指定参数(输入为字符串)、引用 JavaScript 解析器的处理程序、数据源和预期的返回类型(字符串)。他还添加了授权规则,只允许经过身份验证的用户使用知识库。
最后,Banjo使用自定义查询添加了一个 AI 工具,提供了描述和名称,从而将知识库连接到对话组件。
Banjo接着进行了现场编码演示,利用了来自 GitHub 上 亚马逊云科技 Samples 存储库的 Amplify AI 示例。该存储库包含了创建聊天机器人的基本示例,如“你好,我能为你做些什么?”以及解释各种 AI 系统及其功能的响应。
作为一个更偏重于 AI 任务而非前端开发的 Python 开发者,Banjo利用 Amazon CodeWhisperer来帮助理解代码库。他演示了在 CodeWhisperer 中使用 “@workspace” 命令,询问“这个存储库是做什么的?”。CodeWhisperer智能地扫描整个存储库,包括 README 文件,并提供了项目用途的简明总结。
Banjo赞赏 CodeWhisperer 能够理解整个代码库并提供相关信息,这使其成为开发人员在特定领域或技术栈上不是专家时的宝贵工具。
继续探索,Banjo注意到当前实现使用的是 Claude 3.5 Haiku 模型。他决定将模型更新为 Claude 3.5 Sonnet,并使用 CodeWhisperer 的内联聊天功能改进系统提示,只需一个命令即可生成必要的代码更改。
接下来,Banjo希望更改应用程序的背景颜色,摆脱其基本外观。再次利用 CodeWhisperer 的功能,他询问在哪里可以修改背景颜色,CodeWhisperer建议了两个选项。根据建议,Banjo导航到主题索引 CSS 文件,并使用 CodeWhisperer“将背景更新为浅蓝色”,生成并接受必要的 CSS 代码更改。刷新应用程序后,背景颜色已经更新。
Banjo对 Amazon CodeWhisperer 表示赞赏,它极大地简化了他的工作流程,无需不断查阅外部资源,尤其是作为一名相对新手的前端开发人员。
Ali最后提供了 Amplify AI 文档的链接 docs.amplify.aws.ai,这是她和 Danny精心设计的 URL,并展示了一个可以直接将与会者带到文档的二维码。
总而言之,这段视频全面介绍了Amplify AI 工具包,这是一款强大的工具,可以简化全栈生成式 AI 应用程序的开发。它提供了一种基于代码的体验,使用 TypeScript 定义 AI 功能,为大型语言模型(LLM)提供对应用程序数据的安全访问,并提供工具来构建具有自定义 UI 组件的丰富对话界面。
通过现场演示和编码示例,演讲者展示了使用Amplify将 AI 功能无缝集成到 Web 和移动应用程序的简易性。他们强调了与 Amazon Bedrock 的无缝集成,使开发人员能够利用各种大型语言模型,如Claude 3.5 Sonnet、Claude 3.5 Haiku和亚马逊自己的模型,以及访问来自 Anthropic、Cohere 和 Meta Stability AI 等提供商的模型,并且可以通过使用 Converse API 修改单行代码来灵活地进行实验。
Amplify AI 工具包简化了创建 AI 驱动功能的过程,如评论总结、对话式搜索和知识库集成。它处理了工具调用、编排和授权的复杂性,将所有内容通过Amazon AppSync 作为 AI 网关层进行管理,确保 LLM 无法访问超出用户权限的数据。
例如,在评论总结演示中,Danny在Amplify数据资源文件中添加了一个名为“Review Summarizer”的新生成式 API,指定了 AI 模型Claude 3.5 Sonnet,定义了一个系统提示来提供评论的简明总结,并将输入设置为字符串数组(评论),预期输出为具有总结字符串属性的对象。然后,他利用了基于后端定义的类型安全的 useAIGeneration React 钩子,当用户点击“生成总结”按钮时调用处理程序,仅用十几行代码就实现了这一功能。
在对话式搜索演示中,Ali选择了 AI 模型Claude 3.5 Haiku,创建了一个系统提示,将 LLM 定义为一个有助于家庭租赁查找的助手,并添加了一个基于所有者身份验证的授权模型。她在 React 中使用了 useAIConversation 钩子,检索消息并将它们插入 AIConversation 组件,传入消息、加载微调器和 handleSendMessage 函数,仅用几十行代码就创建了由 Amazon Bedrock 提供支持的安全聊天。
Ali随后添加了工具,允许 LLM 访问应用程序的数据,选择了“Listing”模型,并创建了一个名为“searchListing”的工具来搜索租赁列表。当被要求查找“海滩附近的租赁列表”时,LLM 现在可以查询数据库中已有的列表,并建议相关选项。
Danny解释了工具的概念,也称为函数调用,它告知 LLM 可以访问某些数据或信息。例如,当提示“拉斯维加斯的天气如何?”并给出一个 getWeather 工具定义,该工具接受城市作为字符串输入时,LLM 可能会回应“嘿,我想调用 getWeather 工具,输入为’拉斯维加斯’”。应用程序代码随后调用该工具,将结果传回给 LLM,并在消息历史记录中添加结果重新提示它,允许它继续思考过程,可能会按顺序调用多个工具。
Amplify AI 工具包处理这种编排,向 LLM 描述工具的输入,在请求时调用工具,检索数据,在结果中重新提示 LLM,并将响应流式传输回客户端。它还代表用户授权工具调用,确保适当的访问级别。例如,在一个待办事项应用程序中,如果用户询问“我有哪些未完成的待办事项?”,LLM 将只能访问该用户的任务,而不是系统中的所有任务。
为了增强 UI,Ali更新了 AIConversation 组件,以显示当前登录用户的用户名和头像,在 LLM 的响应中渲染 Markdown 格式,启用图像上传以进行搜索查询,并定义响应组件,如接受列表 ID 等属性的列表卡片和预订卡片。这允许 LLM 使用自定义 UI 组件而不仅仅是文本进行响应。在演示中,当提示“显示一个有这种氛围的列表”并上传海滩图像时,LLM 会在数据库中查询海滩列表,并渲染相关的列表组件,所有这些都只用了大约 50 行代码,而无需离开 IDE。
Banjo讨论了 Amazon Bedrock 知识库,这是一个完全托管的检索增强生成(RAG)工作流,允许用户上传 PDF 等数据源。知识库管道将文本分块,通过嵌入模型将其转换为存储在向量存储中的数值向量,并对用户的问题执行相同操作。然后,算法从向量存储中搜索相关上下文,将其包含在 LLM 的提示中,从而根据提供的上下文产生更相关的响应。
Banjo演示了使用亚马逊云科技 AppSync JavaScript解析器将知识库连接到对话组件,定义了解析器调用的请求和响应函数,指定了访问知识库 API 的资源路径并传入了检索查询参数。他在数据模式中创建了一个自定义查询,指定了参数(输入为字符串)、引用JavaScript解析器的处理程序、数据源和预期的返回类型(字符串),并添加了授权规则,只允许经过身份验证的用户使用知识库。最后,他使用自定义查询添加了一个 AI 工具,提供了描述和名称,从而有效地连接了知识库。
在使用来自亚马逊云科技示例存储库的Amplify AI 示例进行现场编码演示时,Banjo利用 Amazon CodeWhisperer来理解代码库,使用CodeWhisperer的内联聊天功能将模型从Claude 3.5 Haiku更新为Claude 3.5 Sonnet,并改进了系统提示。他还在 IDE 中使用CodeWhisperer的指导,将应用程序的背景颜色从基本外观更改为浅蓝色。
总的来说,这段视频将Amplify AI 工具包展示为一种革命性的解决方案,适用于希望在其 Web 和移动应用程序中利用生成式 AI 强大功能的开发人员,并得到了亚马逊云科技强大的基础设施和服务的支持,包括 Amazon Bedrock,它提供了对各种大型语言模型和 AI 服务的访问,只需很少的代码。
下面是一些演讲现场的精彩瞬间:
Danny Banks,Amazon Amplify的首席设计技术专家,在reInvent2024活动上介绍了自己。
演讲者演示了如何使用CodeWhisperer在Amplify控制台中添加新模型、自定义字段和授权规则。
演讲者对讨论Amplify的最新发展感到兴奋,尤其是过去一年为构建生成式人工智能应用程序所做的工作。

演示了如何使用亚马逊云科技 AppSync JavaScript解析器将Amazon Bedrock知识库连接到对话组件。
Amazon CodeWhisperer展示了通过分析代码库的自述文件并提供简明总结来理解和解释代码功能的能力。
一位开发人员展示了Amazon CodeWhisperer如何帮助他们轻松更新代码并更改Web应用程序的背景颜色,而无需导航到其他网站或资源。
总结
在这个引人入胜的会议中,演讲者们深入探讨了使用Amazon Amplify进行全栈AI开发的世界。他们推出了Amplify AI Kit,这是一款革命性的工具,通过提供代码优先的开发者体验、大型语言模型(LLM)的安全数据访问以及无缝集成对话界面,简化了生成式AI应用程序的创建。
会议展示了Amplify AI Kit如何让开发者能够在Amplify数据资源文件中使用TypeScript定义他们的AI功能,包括生成式API和数据工具。这种方法确保了无缝且类型安全的体验,使开发者能够轻松地将他们的前端应用程序连接到Amazon Bedrock并利用各种LLM。通过现场演示,演讲者们展示了构建AI驱动功能的简易性,如评论摘要、对话式搜索界面和知识库集成,同时保持数据访问和授权的安全性。
值得注意的是,该会议强调了通过允许LLM使用自定义React组件进行响应来创建丰富的对话体验的能力,从而使开发者能够打造定制的用户界面。现场编码部分进一步展示了Amazon CodeWhisperer的强大功能,展示了它如何帮助开发者理解和修改代码,即使对于那些不太熟悉前端开发的人也是如此。
会议最后邀请大家进一步探索Amplify AI Kit,承诺在未来,开发者可以轻松利用生成式AI的潜力构建创新和身临其境的应用程序,同时利用亚马逊云科技服务的强大功能和安全性。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。


















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









