



使用开放表格式构建大规模事务性数据湖
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Apache Iceberg, Open Table Formats, Transactional Data Lakes, Schema Evolution, Performance Optimization, Fine-Grained Access]
导读
利用亚马逊云科技分析服务和开放表格式(OTFs)构建大规模事务性数据湖,从而改变您的数据格局。生成式AI和机器学习的兴起需要强大且可扩展的数据基础设施,而OTFs为现代数据架构提供了一个前沿解决方案。学习大规模运营表格的最佳实践,重点关注高性能、成本优化和卓越运营。本次会议还涵盖了流数据挑战,展示了OTFs如何为流式工作负载实现无缝的架构演进和强大的可靠性。
演讲精华
以下是小编为您整理的本次演讲的精华。
会议开始时,Radhika Ravirala询问观众当前有多少人在运行数据湖,99%的人举手表示已广泛采用数据湖。当被问及谁在数据湖中使用Apache Iceberg时,有相当一部分人举手,展示了Iceberg日益增长的人气。
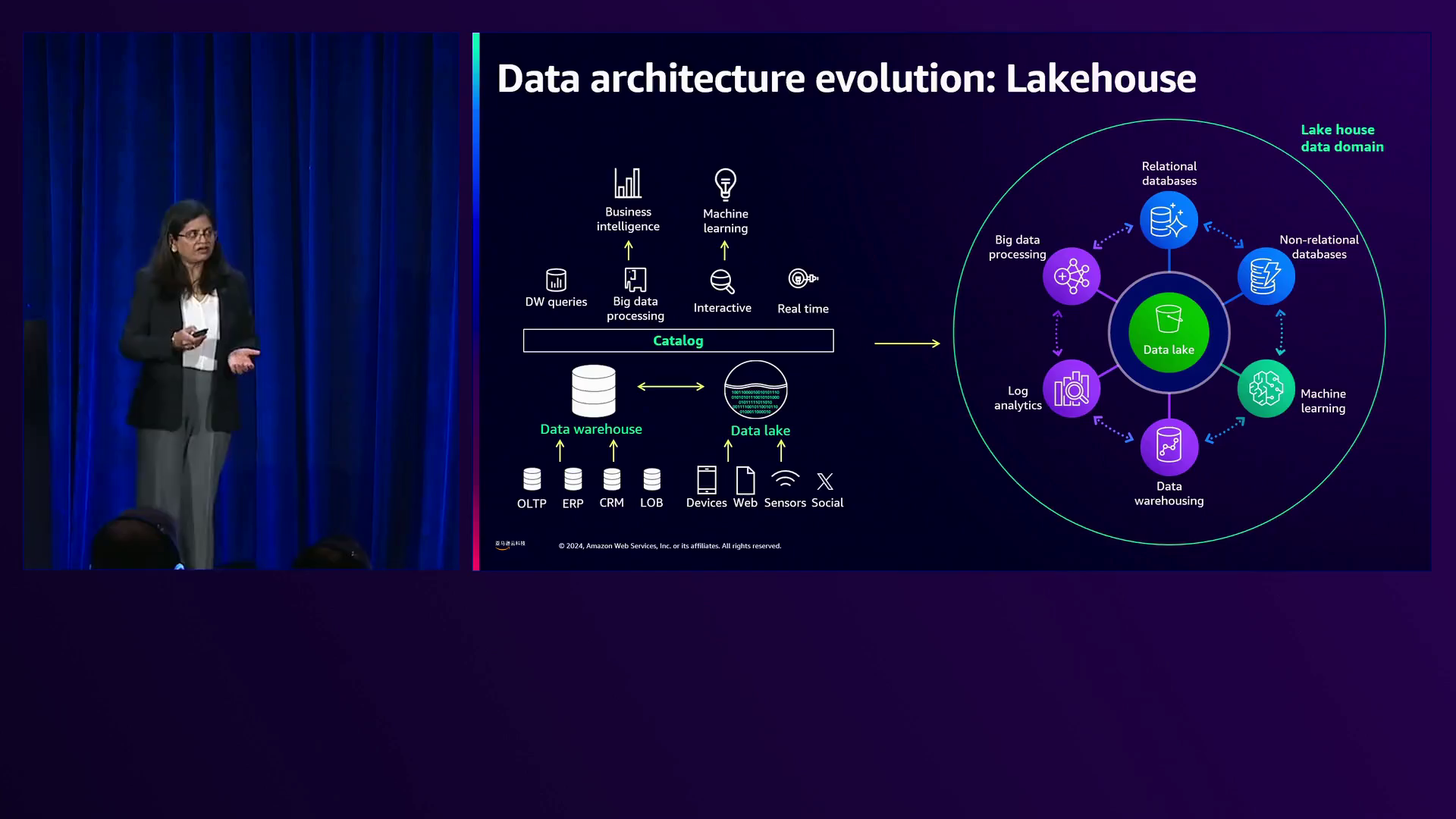
Radhika提供了历史背景,解释早期的事务数据湖采用关系数据库系统的形式,在对聚合数据运行大型复杂分析查询时存在局限性。为解决这一问题,出现了内部数据仓库和OLAP系统,但其底层RDBMS使扩展变得困难,主节点支持所有写请求,主节点和副本支持读请求,使扩展在成本和时间方面都变得昂贵。
Hadoop作为一种解决方案出现,允许弹性扩展以及独立扩展计算和存储资源。然而,数据湖缺乏ACID属性、高性能数据布局和细粒度治理能力,权限仅在文件级别可用。云对象存储的出现使现代“湖仓”架构成为可能,结合了数据湖和数据仓库的优势。但传统数据湖仍然面临着需要持续更新、一致性能、分区更新和符合法规等挑战。
Gio Matilda随后深入探讨了Apache Iceberg的技术细节,解释它是一种多引擎开放表格式,提供了运行删除、删除、合并和更新操作的能力,实现了ACID事务。Iceberg的架构由三层组成:存储快照(表示表随时间的状态)的元数据文件、包含清单列表的清单列表,以及指向实际数据文件的清单。
Iceberg支持两个主要概念:写时复制和读时合并。在写时复制场景中,Iceberg指示查询引擎在更新、插入或删除期间重写整个数据,使写操作更加昂贵,但不会影响读取性能。在读时合并场景中,更新和删除会导致添加日志文件,使写入更快,但需要查询引擎在读取时扫描这些日志文件。
Gio进行了技术深入探讨,解释在写时复制场景中,新文件会被重写,创建一个指向新数据文件的新清单,创建一个指向清单文件的新清单列表,最后,元数据文件会获得一个指向新清单列表的新快照。在读时合并场景中,会创建新的增量或日志文件,创建一个指向旧文件和新文件的清单文件,创建一个指向旧清单列表和新清单列表的新清单列表,并更新元数据文件以指向新的清单列表。
Iceberg支持模式演化,允许通过添加、删除、重命名或重新排序列来更改表模式,而无需数据操作或移动。它还支持分区演化,允许更改分区方案而无需数据移动或查询重写。Gio举了一个按月分区的销售表的例子,将分区更改为日期,导致3月份产生31个新分区,而无需额外成本或查询重写。
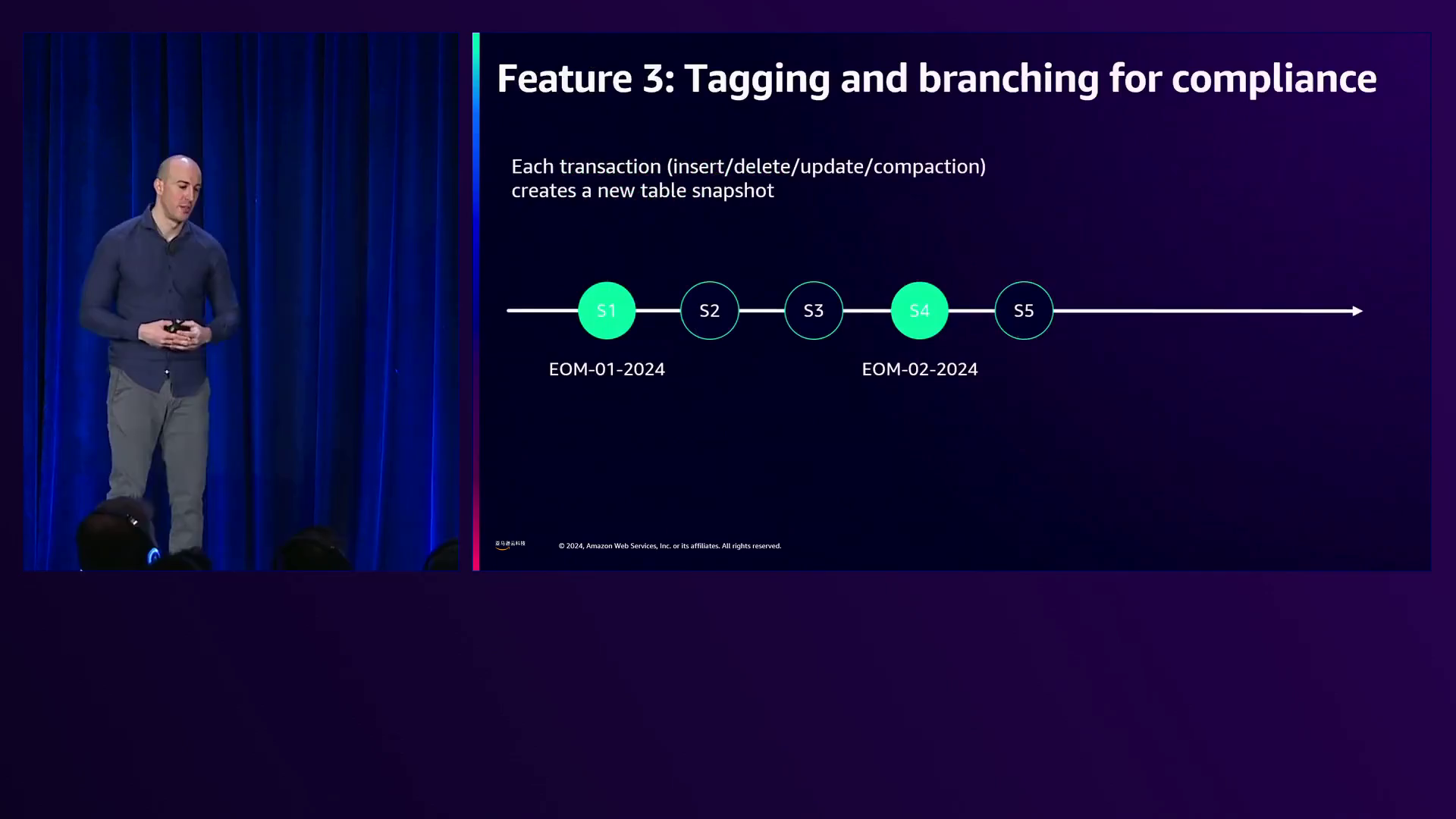
Iceberg通过分支、标记和快照过期等功能提供数据完整性和一致性。Gio用一个事件时间线进行了说明,其中快照被标记为“月底”等标签,而“过期快照”操作会删除任何未标记的快照,从而实现对标记快照的时间旅行。
为了性能优化,Iceberg支持隐藏分区,消除了为相关属性单独创建列的需要。Gio举了一个包含“级别”、“事件时间”和“事件日期”(分区)列的表的例子,按“事件时间”过滤查询将需要扫描所有数据。使用隐藏分区,分区基于“事件时间的日期”等函数,自动实现部分扫描。
Iceberg还支持随机前缀,将请求分散到S3上,以减少节流并提高性能。Gio提到,一个内部亚马逊云科技客户Amazon Ads报告使用该功能后,性能提高了22%,错误503节流情况也大幅减少。
Radhika随后讨论了亚马逊云科技的产品努力,强调了持续的Spark性能改进,最新的EMR 7.5版本在处理Iceberg 1.6数据集时比最新的Apache Spark版本快3.6倍,而EMR 7.1和Iceberg 1.5.2数据集则快2.7倍。
对于粗粒度权限,亚马逊云科技引入了S3访问授权,允许在S3前缀上定义权限,并通过诸如EMR之类的引擎对Hudi和Delta Lake(通过EMRFS连接器)和Iceberg(通过S3 File I/O连接器)进行强制执行。
对于细粒度访问控制,Lake Formation集成使得对通过EMR Serverless(2022年夏季推出)和Glue 5.0(2022年11月推出)上的Spark作业访问的Iceberg表具有表级、行级、列级和单元格级别的权限。
Glue数据目录现在支持多方言视图,允许一次定义视图,并从多个分析引擎(如Redshift和Athena)查询,细粒度访问控制在Lake Formation中定义。它还支持多目录支持、Iceberg表的自动压缩、快照保留以降低成本、元数据和数据联合以及改进的统计信息更新。
亚马逊云科技宣布了SageMaker Lakehouse,这是一个统一平台,用于访问多个来源的数据以进行分析和AI计划,支持Iceberg等开放表格式,并使用Glue数据目录和Lake Formation集成了细粒度访问控制。
Kinesis Data Firehose现在支持写入Iceberg表,实现流式传输、模式演化、PII数据过滤,以及连接客户VPC内的数据库(如MySQL和PostgreSQL)。
Radhika强调了几个事务数据湖的客户使用案例:
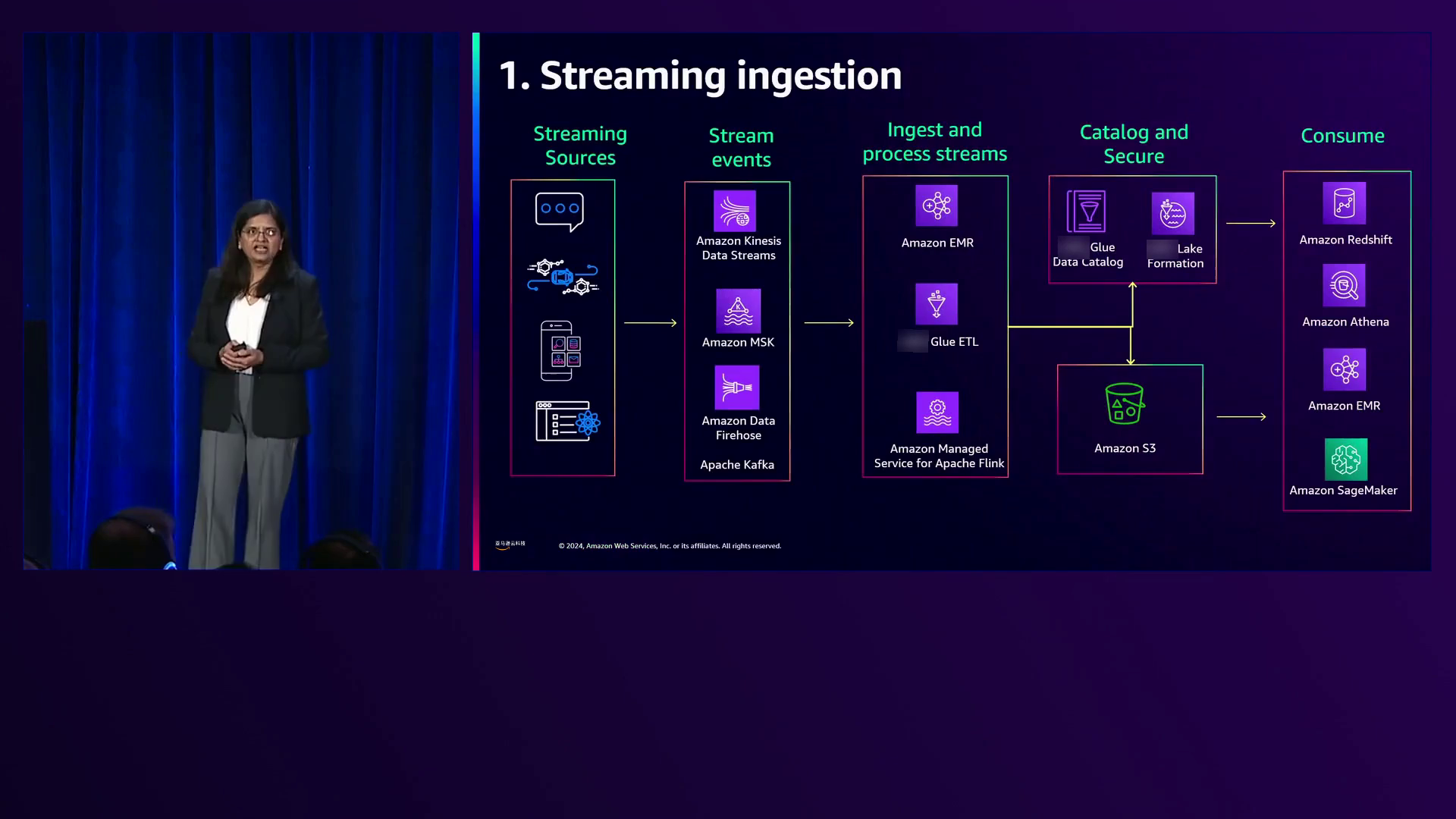
1)流式传输:组织有许多不断通过Apache Kafka、Amazon MSK、Kinesis Data Streams和Kinesis Data Firehose等服务流式传输数据的源。这些数据被摄取、由流处理引擎(如EMR、Glue、ETL和Amazon Managed Service for Apache Flink)处理,然后存储、整理、编目和保护,以供Redshift、Athena、EMR和SageMaker等服务消费。
2)数据隐私合规:客户通过EMR、Glue和Flink等流处理服务运行每月GDPR或CCPA删除管道作为批处理作业。遵守数据隐私法规具有挑战性,需要查找和删除特定用户的记录,通常涉及全表扫描和覆盖整个分区。具有事务能力的数据湖和Iceberg支持并发写入以及行级插入和删除,满足这些合规需求。
3)新AI/ML应用:包括使用ChatGPT等基础模型的生成式AI模型在内的一种新型应用,不断查询数据湖,需要新鲜可用的数据。事务数据湖在支持这些应用以及日志分析、数据仓库、关系数据库等方面发挥核心作用。
Gio强调了一个真实客户Amazon Ads的例子,他们报告使用Iceberg的随机前缀功能后,性能提高了22%,错误503节流情况也大幅减少。
Radhika强调亚马逊云科技支持所有三种主要开放表格式(Hudi、Iceberg和Delta Lake),跨Athena、EMR和Glue等服务,并根据客户兴趣、反馈、性能公告和开源社区参与情况,优先为Iceberg推出新功能,亚马逊云科技是Iceberg的重要贡献者。
总之,亚马逊云科技提供了一套全面的服务,支持开放表格式,实现事务能力、性能优化、安全和治理控制,以及分析服务组合中的统一数据访问,使客户能够构建安全、高性能的事务数据湖,加速数据湖现代化努力。
下面是一些演讲现场的精彩瞬间:
Gio Matilda是亚马逊云科技的一位高级经理,在2024年的reInvent大会上进行了演讲。
为了全面支持数据湖房架构,传统的数据湖需要解决持续更新、小文件压缩时性能一致、分区更新以及遵守数据删除法规等挑战。
Gio深入探讨了OTF如何实现从Apache Kafka、Amazon MSK、Kinesis Data Streams和Kinesis Data Firehose等各种来源的数据流式摄取、处理和消费。
演讲者解释了Iceberg中写时复制操作的技术细节,包括创建新文件、清单和快照,全面阐述了该过程。

演讲者解释了如何创建和标记快照,允许回溯到特定时间点,同时删除不必要的快照以优化存储。
亚马逊云科技提供了一套全面、灵活、经济高效且安全的服务,用于构建事务性数据湖,实现更快的洞见和实时业务视图,且不受供应商锁定。

亚马逊云科技提供了强大的平台,用于构建事务性数据湖,使组织能够从数据中发掘宝贵的见解,推动创新。

总结
在这个引人入胜的叙述中,我们踏上了一段探索数据架构演进的旅程,最终抵达了具有变革力量的事务数据湖。讲者Radhika和Gio巧妙地将这项开创性技术的历史背景、技术细节和现实应用编织在一起。
首先,他们追溯了事务数据湖的起源,强调了传统数据仓库的局限性以及Hadoop和数据湖的兴起。然而,这些早期解决方案缺乏现代数据驱动型企业所需的一致性、性能和治理能力。随后,云计算和多功能对象存储的出现为数据湖和数据仓库融合为强大的“湖仓”架构铺平了道路。
讲者们接着深入探讨了由开放表格式(如Apache Iceberg、Apache Hudi和Delta Lake)驱动的事务数据湖的核心。这些格式提供了类似数据库的功能,支持高效的记录级更新、模式和分区演进、数据完整性和一致的性能。Gio对Apache Iceberg的特性(如写时复制、读时合并和隐藏分区)进行了深入探讨,阐明了这些格式的技术实力。
Radhika随后登场,展示了亚马逊云科技致力于优化和丰富事务数据湖的决心。从EMR和Spark的性能增强到Lake Formation和Glue Data Catalog的细粒度访问控制,亚马逊云科技提供了一套全面的服务来释放事务数据湖的全部潜力。与SageMaker Lake House的集成和对流式摄取的支持进一步巩固了亚马逊云科技在这一领域的领导地位。
在结束语中,讲者们强调选择亚马逊云科技事务数据湖的好处,包括灵活性、经济性、实时洞察力、增强的安全性和供应商无关的解决方案。他们邀请观众开启自己的事务数据湖之旅,并承诺亚马逊云科技将持续创新和提供支持。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









