



深入探索亚马逊DynamoDB
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, DynamoDB, ]
导读
本次会议深入探讨了Amazon DynamoDB,分享了DynamoDB的架构设计以及如何实现客户期望的可扩展性和响应时间的见解。您将深入了解DynamoDB的各项功能,包括TTL、全局表和MemDS的实现方式。
演讲精华
以下是小编为您整理的本次演讲的精华。
在不断演进的云计算领域,构建大规模应用程序已成为一项复杂的挑战。客户要求精确的性能、可预测的响应时间,并能够无缝处理大规模工作负载。正是在这种背景下,亚马逊云科技开发了DynamoDB,这是一种全托管的NoSQL数据库服务,旨在提供任何规模下的可预测低延迟。Amazon DynamoDB团队的高级主要工程师Amrith在亚马逊云科技 re:Invent 2024大会上深入探讨了这项强大服务的复杂性。
Amrith首先承认构建能够大规模运行的应用程序的复杂性,强调DynamoDB是一种精心设计的工具,旨在简化这一艰巨任务。他强调团队致力于分享他们的经验教训,目的是让开发人员能够构建健壮的应用程序,同时避免他们在这一过程中遇到的陷阱。Amrith对团队取得的成就感到骄傲,他渴望展示他们所取得的非凡成就。
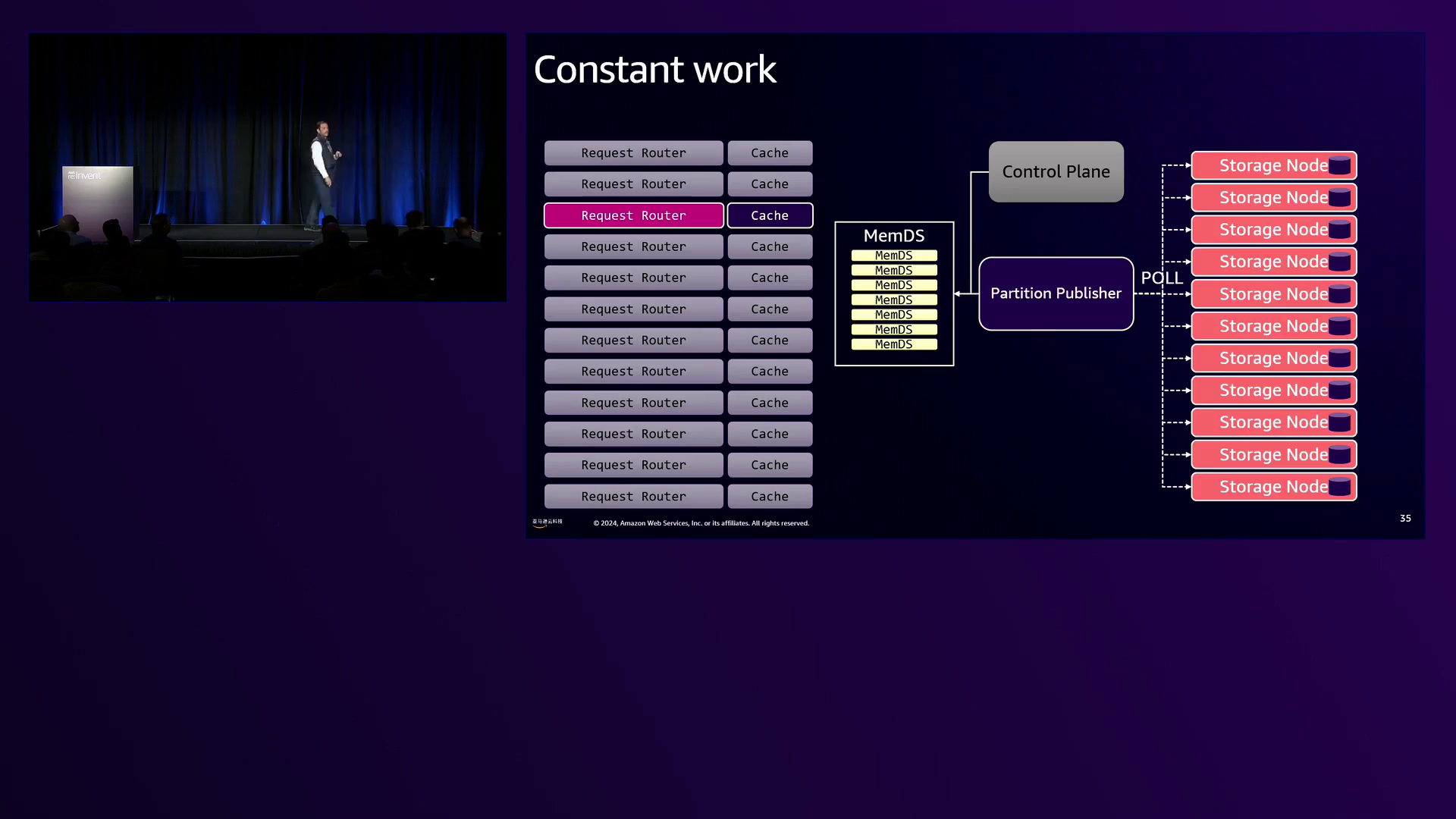
演讲首先简要概述了DynamoDB的架构,阐明了其设计原则的基本理念。Amrith解释说,DynamoDB中的所有数据都存储在表或索引中,这些表或索引在多个可用区(AZ)中的多个存储节点之间进行了水平分区。这种分区策略确保了高可用性和容错能力,因为每个分区都有三个副本,其中一个副本被指定为处理写入和强一致性读取的领导者。Amrith强调,DynamoDB是一种无服务器服务,这意味着亚马逊云科技负责供应和管理底层基础设施,从而免去了客户供应和维护服务器的负担。
接下来,Amrith深入探讨了元数据存储(MMDS)的复杂细节,这是一个内存分布式数据库,在跟踪数据在分区之间的位置方面发挥着关键作用。MMDS的设计旨在避免瓶颈,它不使用持久存储,而是采用最终一致的模型和版本控制,以无缝处理分区分割和移动。这种创新方法利用了缓存、对冲请求和恒定工作模式,以确保大规模下的可预测性能。
Amrith强调的一个关键挑战是需要在几十微秒内确定数据的位置,这是MMDS所实现的壮举。他解释说,当请求到达请求路由器时,它必须对请求进行身份验证和授权、确保符合资源策略,并确定所请求数据的位置。这个过程每秒必须执行数亿次,凸显了MMDS在促进快速数据检索方面的关键作用。
Amrith深入探讨了MMDS的细节,将其描述为一个并行数据库,由数百个节点组成,这些节点几乎同步地维护分区元数据。为了减轻陈旧数据的风险,MMDS采用了版本控制和最终一致的缓存,确保及时为请求提供服务,同时保持数据完整性。Amrith强调,在可能的情况下,采用最终一致性是很重要的,因为同步系统可能会引入可变性和不可预测的大规模性能。
演讲接着转向讨论新推出的Warm Throughput功能,这是直接响应客户对更好了解其表可以服务的流量的要求。Amrith解释说,客户经常询问他们表中的分区数量,以衡量其系统可以处理的最大流量。然而,这种方法是次优的,因为它没有考虑到DynamoDB分区策略的动态性质。
Warm Throughput功能通过提供一个API来解决这个问题,允许客户确定他们的表或索引可以服务的即时流量。此外,客户还可以设置这个阈值,使他们能够主动为预期的流量高峰做好准备,例如节假日或特殊活动期间经历的高峰。Amrith演示了这一功能的简单性,展示了使用describe table命令来检索当前的warm throughput设置,以及使用update table命令根据需要修改这些设置。
Amrith强调了Warm Throughput的优势,特别是对于按需表,客户只需为他们发出的请求付费。通过提前提高warm throughput以应对预期的流量高峰,客户可以确保他们的表做好了处理增加的工作负载的准备,而不会产生节流或尾部延迟。这一功能与预配模式表的自动缩放无缝集成,支持并发更新而不会产生干扰。
在转向讨论强一致性全局表的主题时,Amrith承认当天早些时候在主题演讲中宣布了在全局表中支持多区域强一致性。他将这一新功能与现有的异步全局表进行了对比,后者在区域之间提供最终一致性,缺乏读写一致性保证。
Amrith解释说,多区域强一致性(MRSC)功能(亲切地称为“mercy”)利用了一个多区域有序日志来提供跨区域的强读写一致性。虽然写入是异步复制的,但它们的顺序是严格保持的,确保每个区域中的回调发生的顺序与写入记录在日志中的顺序相同。这种排序保证,加上心跳机制,确保一致性读取反映了全球范围内所有先前的写入。
Amrith通过几个示例演示了MRSC的强大功能,展示了它如何使应用程序能够全局生成唯一的序列号,并在需要时维护密集的序列号。他强调了这一功能在涉及金融交易或其他需要跨区域强一致性保证的场景中的实用性。
在整个演讲过程中,Amrith融入了DynamoDB团队在大规模构建应用程序方面的宝贵经验教训和最佳实践。他强调在可能的情况下采用最终一致性的重要性,因为同步系统可能会引入不可预测的性能和复杂性。Amrith还提倡使用对冲请求来实现可预测的延迟,这是受谷歌“Tail at Scale”论文的启发,其中涉及发送多个请求并使用第一组结果。
Amrith强调的另一个关键原则是恒定工作的概念,即保持稳定的运行状态,以确保可预测的性能和可用性。他通过缓存系统的例子来说明这一原则,强调以恒定的速率服务缓存未命中的重要性,以避免在缓存失效或软件部署期间过载底层元数据存储。
Amrith还谈到了团队在缓存方面的经验教训,提倡使用生存时间(TTL)机制来优雅地过期陈旧数据,而不是依赖于同步缓存失效,后者在大规模情况下可能会引入可变性和复杂性。他鼓励开发人员利用与DynamoDB的长连接,因为这种方法不仅避免了频繁TLS握手的开销,而且还可以从请求路由器采用的缓存机制中获益。
总之,Amrith的演讲全面深入地探讨了DynamoDB,这是一项经过精心设计的服务,旨在提供任何规模下的可预测低延迟。通过分享团队的经验教训和最佳实践,Amrith让开发人员能够构建健壮、高性能的应用程序,充分利用DynamoDB的先进功能,如Warm Throughput和MRSC全局表。这次演讲凸显了亚马逊云科技在持续创新方面的承诺,以及为客户提供必要工具和知识以在不断演进的云计算世界中取得成功的决心。
下面是一些演讲现场的精彩瞬间:
演讲者强调了理解DynamoDB这一强大工具的内部运作机制的重要性,并分享了从其开发过程中获得的见解,以帮助开发人员更高效地构建复杂应用程序。

Jeff Bezos解释了“对冲”技术,即发出两个数据库请求,并使用第一个响应来实现可预测的低延迟,这是Google开创的一种模式。

Amazon S3的元数据服务器每秒处理数亿次请求,确保数据存储的高可用性和持久性。
Amazon DynamoDB的新功能简化了处理流量峰值的过程,消除了复杂的手动步骤和自动扩展可能带来的问题。

演讲者解释了如何处理在不同区域对同一分区键的写入,强调了最终一致性模型以及在收敛期间可能出现的短暂不一致性。

Andy Jassy解释了Amazon DynamoDB如何通过心跳机制实现跨区域强一致的读写,以确保在提供一致读取之前写入已被处理。

演讲者强调了之前关于DynamoDB的演讲,展示了亚马逊云科技分享知识并帮助开发人员利用该服务提供的可预测低延迟保证的决心。

总结
在这个引人入胜的叙述中,我们深入探讨了Amazon DynamoDB这个数据库服务的复杂世界,它被设计用于在任何规模下提供可预测的低延迟。Amrith这位高级主要工程师揭示了DynamoDB卓越性能背后的架构基础。
首先,他阐明了元数据存储(MDS),这是一个内部数据存储,用于促进分区查找,采用版本控制和最终一致性来确保动态分区移动中的数据准确性。这种巧妙的设计避免了锁定机制,提高了可扩展性和弹性。
接下来,Amrith介绍了“热吞吐量”的概念,这是一项最近推出的功能,允许用户指定他们的表可以处理的瞬时流量容量。这种主动方法简化了容量规划,能够无需传统供应方法的复杂性就可以顺利处理流量高峰。
最后,他揭示了针对全局表的突破性“多区域强一致性”(MRSC),这是通过一个跨区域的日志实现的,确保了跨区域的严格写入顺序。这一创新确保了全局读写后一致性,对于要求金融级数据完整性和事务保证的应用程序来说是一大福音。
贯穿整个叙述,Amrith分享了从DynamoDB开发中获得的宝贵见解,提供了关于缓存策略、接受最终一致性以及利用异步操作实现大规模可预测性能的实用建议。他的最后一句话鼓励与会者探索相关会议,深入了解DynamoDB的架构奇迹。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









