



Amazon EKS :分析的数据平台
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Carpenter, Data Processing Platforms, Kubernetes Cluster Optimization, Spark Workload Management, Observability Metrics Integration, Developer Enablement Strategies]
导读
随着在Amazon EKS上运行分析工作负载的需求持续增长,数据工程师需要自助工具来创建运行分析作业的基础设施。本次会议提供了关于领先组织如何现代化其数据平台的实用见解,从传统的基础设施即代码管道转变为基础设施即Kubernetes API。通过使用亚马逊云科技 Controllers for Kubernetes (ACK)等开源技术,数据平台团队可以帮助数据工程师创建按需命名空间和集群,这些集群完全配备运行分析作业的能力,从而简化他们的工作流程。
演讲精华
以下是小编为您整理的本次演讲的精华。
在数据分析的年鼿中,亚马逊云科技 re:Invent 2024年大会矗立为创新的灯塔,见证了协作力量的威力,预示了数据、平台和组织增长交汇处的变革潜力。Roland Barcia的话语引起了强烈共鸣,强调了数据在当代环境中的关键作用,尤其是在生成式人工智能和大型语言模型的背景下。他的见解阐明了数据的多方面性质,包括多种格式和角色,从分析师和开发人员到用户和决策者,所有人都利用数据的力量来做出关键决策。
Christina Ananov的专业知识体现在精心设计的三层集群构建方法上,针对分析工作负载的独特需求进行了优化。第一层专注于建立生产就绪集群,具有强大的网络功能。值得注意的是,她建议使用一个特殊的不可路由IP范围,具体是两个/16 CIDR块,以避免IPv4耗尽并获得130个IP用于节点和Pod。在VPC CNI配置方面,Christina建议将最大ENI数量设置为1,将每个节点的最大Pod数量设置为静态值30或根据实例大小和Linux版本自动确定的值。这种策略旨在减少VPC CNI与EC2 API的通信量,通过启用前缀委派,将16个IP打包在一个查询中,从而减少查询次数。
转而关注集群架构中的关键组件CoreDNS,Christina强调通过利用托管缩放来实现主动缩放的重要性,该功能自5月起适用于EKS版本1.25和CoreDNS版本1.9或更高版本。与此同时,她建议部署Node Local DNS,这是一个缓存查询并减轻CoreDNS负载的DaemonSet。此外,她建议将节点级ndots值设置为2,减少不必要的查询并缓解CoreDNS Pod的压力。在计算缩放方面,Christina阐明了从开源Cluster Autoscaler过渡到Carpenter的过程,后者是一个由亚马逊云科技开发的项目,不仅考虑CPU和内存需求,还考虑了选择实例时的成本效率。Carpenter的优势体现在能够在不到一分钟的时间内扩展实例,与Cluster Autoscaler平均2-3分钟形成鲜明对比。
Christina的见解深入探讨了Spark作业执行的细节,其中驱动程序Pod管理作业、调度执行器并处理中断。在这种情况下,她建议在按需实例上部署驱动程序Pod,同时利用深度折扣的Spot容量来运行执行器。这种策略旨在在可靠性和成本效率之间取得平衡。在存储方面,Christina强调了利用内置SSD驱动器的实例的优势,将它们设置为RAID 0以获得最佳性能。对于短期运行的作业,这种配置是理想的,而长期运行的作业则需要使用EBS卷来实现检查点和无缝实例中断处理。
在图像优化方面,Christina的建议集中在最小化实例供应和Pod就绪之间的时间,目标是在一分钟以内。策略包括利用跨区域复制托管在ECR上的镜像、实施拉取缓存以及使用S3挂载点来存储大文件,从而减小镜像大小并加快下载速度。可观察性成为一个关键支柱,Christina建议监控Kubernetes控制平面、VPC CNI和EBS的API限制指标,以及网络性能指标,以检测由于连接跟踪表饱和而导致的潜在数据包丢失。
Victor的引人入胜的叙述揭示了Appsflyer的数据处理环境,他们每天处理超过100PB的数据,协调数千个具有不同资源需求的作业,并应对可能快速扩展的动态流量模式,每秒数百万个事件。遵守严格的SLA至关重要,这凸显了及时数据处理对其业务运营的关键性。在优化Spark工作负载的过程中,Appsflyer开启了一段变革之旅,从由配置管理工具管理的EC2实例迁移到Amazon EKS生态系统。
Victor的阐述揭示了Carpenter在解决其扩展和成本效率挑战方面的威力。利用Carpenter的智能算法,Appsflyer在高峰利用期间扩展到大约60个节点,而在利用率下降时又能高效缩减,最小化闲置时间和资源浪费。Appsflyer的计算策略采用了多种实例类型,包括主要选择Graviton Gen 3实例,当容量受限时则使用Graviton Gen 2作为后备选择。值得注意的是,他们的节点池中有15%是裸机节点,这体现了他们追求高性能和直接访问硬件而无需承担虚拟机管理程序开销的决心。
在24小时周期内,Carpenter协调了超过1600次节点创建和终止事件,这一惊人的数字凸显了Appsflyer工作负载的动态性质。Victor的见解揭示,Carpenter的终止处理能力,加上Spark在2分钟内迁移中间数据阶段的能力,缓解了Spot实例中断的影响,确保了严格的SLA得以遵守。可观察性在Appsflyer的数据分析工作中占据核心地位,Victor展示了将Kubernetes、Spark和Carpenter的指标相结合的威力。这种整体方法提供了对数据处理流程的细粒度洞察,使他们能够识别趋势和潜在的业务影响。例如,他们可以发现点击处理占他们工作负载的28%,而另一个数据集相比上周增长了35%。
成本估算成为一个关键方面,Carpenter提供了实例和可用区定价数据。通过将这些信息与Spark和Kubernetes指标相结合,Appsflyer可以近乎实时地计算每分钟的数据处理成本,这一能力赋予了工程和业务决策过程以力量。Victor的叙述强调了自主和控制的理念贯穿Appsflyer的数据工程实践。通过详细的Git结构和自动化工作流,数据工程师可以从单一界面管理基础设施、应用程序和第三方集成,促进了速度并减少了对平台工程师的依赖。
将Spark工作负载迁移到Amazon EKS的变革影响引起了强烈共鸣,Appsflyer实现了60%的成本降低、35%的SLA改善、加强的可观察性以及平台工程师的运营开销大幅减轻。这些切实的好处凸显了亚马逊云科技数据分析平台的巨大价值主张。
此外,该演示还强调了Amazon EMR的威力,这是一项在EKS上运行的托管服务,为客户提供了最佳的两个世界:管理和灵活性,结合了最佳的开源框架。对于那些寻求更加原生的亚马逊云科技体验的人来说,像Amazon Kinesis这样的服务为数据摄取和处理提供了引人注目的替代方案。
数据生命周期成为一个核心主题,包括摄取、工作流管理、数据处理和消费。演示介绍了Amazon MSK(托管流媒体Apache Kafka)、Amazon Step Functions、Apache Airflow和Argo Workflows等强大工具,用于协调和管理这个复杂的生命周期。
值得注意的是,该演示强调了“数据在EKS上”项目的重要性,这是一个协作努力,提供了在EKS上配置模式(如运行Spark、Flink或Kafka)的蓝图和最佳实践。这一倡议使客户能够利用Kubernetes为其数据分析工作负载提供动力,同时受益于亚马逊云科技的专业知识和指导。
总之,亚马逊云科技 re:Invent 2024年大会见证了云上数据分析的变革潜力,展示了真实的客户成功案例和优化性能、可扩展性和成本效率的最佳实践。亚马逊云科技服务、开源工具和Kubernetes生态系统之间的协同效应成为创新的强大催化剂,使组织能够释放数据的全部潜力,推动业务增长。
下面是一些演讲现场的精彩瞬间:
演讲者通过承诺迅速深入探讨这个主题并将话题交给Christina讨论数据,为一场深入、高级的会议做了铺垫。

Andy Jassy探讨了平台工程的出现,作为一种在Web应用程序和微服务中平衡开发人员自主权和平台标准化的方式。

Carpenter策略通过动态配置最合适的计算资源(包括Graviton实例、现货实例和裸机节点),跨多个可用区域优化成本和性能。

亚马逊展示了他们为扩展和成本效率而优化的配置,利用Amazon Linux 2024、Graviton实例和Spark的功能实现近乎最佳性能。
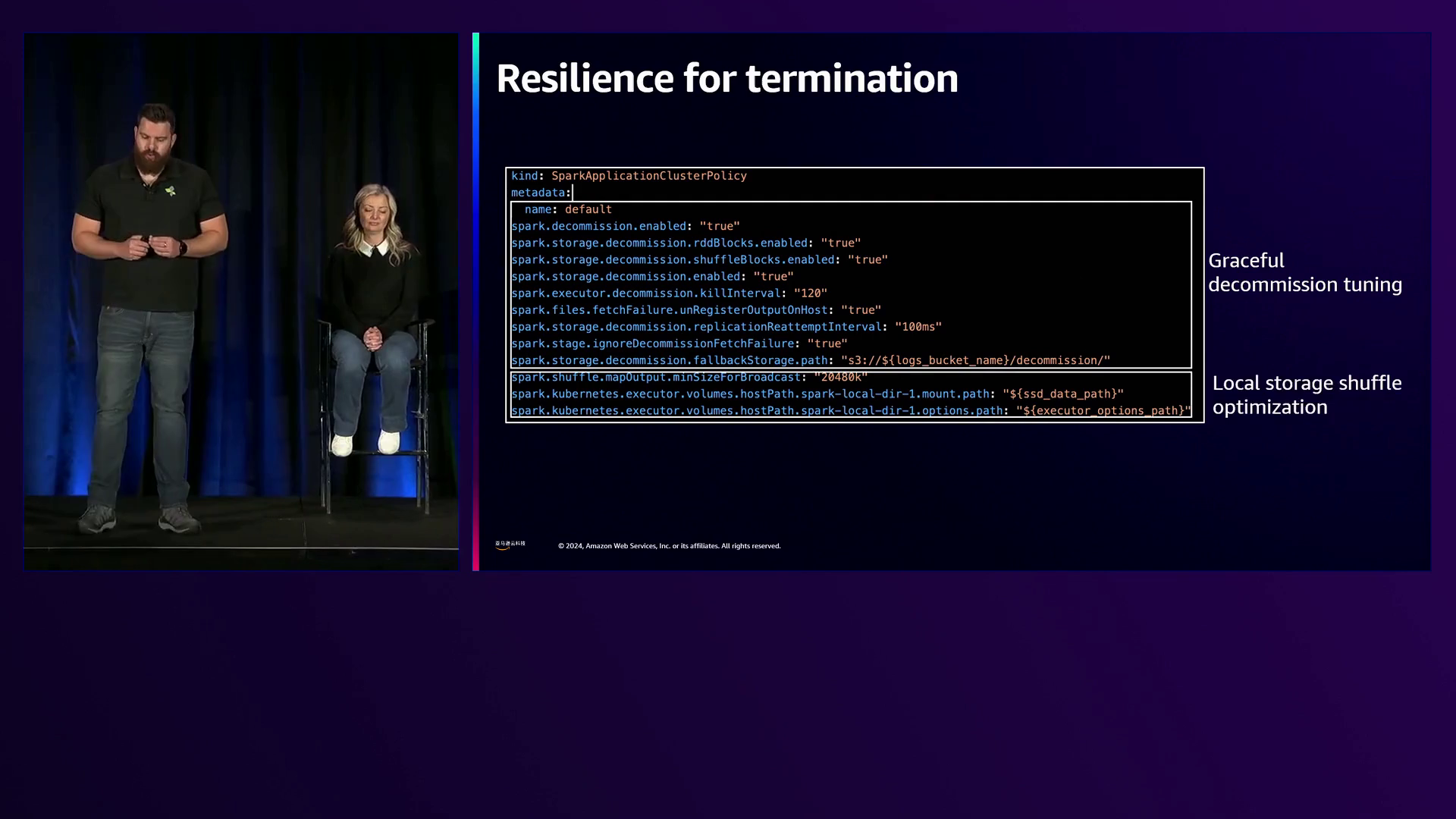
将可观察性指标与成本估算相结合,可以全面了解数据流,从而为成本效益高的数据处理管道做出数据驱动的决策和优化。

采用GitOps进行基础设施和应用程序管理,实现自动化工作流、验证和跨环境快速部署。

通过API和自动化赋予数据工程师自主权和控制权,促进平台提供商与数据专业人士之间的和谐联盟。

总结
在这个引人入胜的叙述中,我们深入探讨了在Amazon EKS上进行数据分析的领域,其中追求效率、可扩展性和成本效益性是重中之重。故事从探索驱动数据处理需求的不同角色和用例开始,从实时决策到历史分析。
随着故事的展开,我们见证了平台工程作为开发人员自主权与标准化、安全性和可扩展性需求之间的桥梁的出现。演讲者随后引导我们通过一种精心设计的三层方法在EKS上构建优化的分析平台,包括网络配置、集群优化以及集成开源工具如Apache Spark和Apache Flink。
叙述在我们了解到AppsFlyer的真实世界经验时出现了一个令人兴奋的转折,在那里,将Spark工作负载从EC2迁移到EKS的战略决策取得了显著的成果。通过实施Carpenter(一种强大的扩展和计算优化工具),AppsFlyer实现了60%的成本降低、35%的SLA改善和增强的可观察性。演讲者揭示了这一成功背后的秘密,包括高效的扩展策略、现场实例终止处理以及从Kubernetes、Spark和Carpenter无缝集成指标。
在故事结束时,演讲者强调了赋予数据工程师对其应用程序和平台的自主权和控制权的重要性,培养一种知识共享和持续改进蓬勃发展的协作环境。这个叙述让我们受到启发,掌握了在Amazon EKS上构建可扩展、高成本效益和高度可观察的数据分析平台的最佳实践和愿景。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









