







 本文介绍了如何使用Python的numpy库生成正太分布序列,并通过两种方法(collections.Counter和np.unique)进行统计,最后展示了如何绘制直方图。文中详细解释了各个函数的使用和代码逻辑。
本文介绍了如何使用Python的numpy库生成正太分布序列,并通过两种方法(collections.Counter和np.unique)进行统计,最后展示了如何绘制直方图。文中详细解释了各个函数的使用和代码逻辑。
目录
首先使用numpy库的random.normal()函数生成一个正太分布的序列
1.第一种是引用collections库的Counter函数
首先使用numpy库的random.normal()函数生成一个正太分布的序列
import numpy as np
n = 100000
ex = 1000
de = 20
y = np.random.normal(ex, de, n)
y = np.round(y).astype(int) # 将y的每个元素四舍五入为整数
print(y)代码中random.normal()中的三个参数,ex是正太分布的平均值,de是正太分布的均方差,n是生成数据的数目,代码中是生成100000个以平均值1000,均方差为20的正太分布的数据
其中,np.round(y)是用来设置四舍五入后小数点位置的,默认小数点为0位,np.round(y,2)则是保留两位小数
.astype(int)是将array数组数据转换成指定int类型的数据
输出:
[1004 1008 969 ... 981 996 1012]两种方法
1.第一种是引用collections库的Counter函数
from collections import Counter
y = Counter(y)
print('y=', y)
y = dict(Counter(y))
print('y=', y) Counter(y)是返回y中的值,以及对应值出现的次数
dict()是用来数据转换为字典类型数据的方法
输出:
y= Counter({998: 2045, 1001: 2041, 1000: 2012, 1004: 2007, 999: 1983, 1003: 1973, 1006: 1967, 995: 1962, 1002: 1953, 1007: 1933, 996: 1927, 1005: 1912, 1008: 1897, 997: 1895, 991: 1843, 993: 1818, 992: 1816, 1009: 1782, 994: 1779, 1010: 1753, 990: 1746, 1011: 1738, 989: 1713, 1012: 1683, 987: 1639, 1014: 1612, 1013: 1604, 988: 1595, 986: 1561, 985: 1508, 1015: 1488, 1016: 1457, 984: 1423, 983: 1421, 1018: 1373, 1017: 1366, 982: 1308, 981: 1272, 1020: 1233, 980: 1201, 1019: 1195, 1021: 1187, 979: 1113, 978: 1075, 1022: 1044, 977: 1021, 1023: 1008, 976: 987, 1024: 974, 1025: 918, 975: 863, 1026: 849, 974: 830, 1028: 807, 972: 780, 973: 779, 1027: 773, 1029: 727, 971: 712, 1030: 661, 969: 660, 970: 648, 1031: 578, 968: 577, 967: 522, 1032: 521, 1034: 490, 1033: 480, 966: 467, 1035: 452, 965: 448, 1036: 423, 963: 386, 1037: 368, 964: 367, 962: 332, 1038: 330, 961: 299, 1039: 287, 1041: 277, 1040: 275, 960: 259, 959: 226, 1042: 220, 958: 219, 957: 207, 1043: 202, 956: 180, 1044: 177, 1045: 172, 955: 158, 954: 137, 1047: 134, 1046: 122, 953: 120, 952: 114, 1049: 108, 1048: 105, 951: 103, 950: 99, 1050: 95, 1051: 78, 947: 65, 1052: 64, 949: 63, 948: 60, 946: 49, 944: 48, 1053: 46, 1054: 42, 1056: 40, 1055: 40, 1057: 37, 1058: 35, 943: 35, 945: 32, 941: 28, 939: 27, 1059: 24, 1060: 23, 1062: 23, 1061: 20, 940: 19, 937: 17, 1064: 17, 942: 17, 938: 17, 1067: 11, 935: 10, 1068: 9, 933: 9, 1063: 9, 1066: 8, 934: 8, 932: 7, 1069: 7, 1071: 6, 928: 6, 925: 6, 1073: 5, 1065: 5, 936: 5, 1070: 5, 930: 4, 926: 4, 1075: 3, 931: 3, 1078: 2, 929: 2, 927: 2, 920: 2, 1072: 2, 1082: 1, 1077: 1, 1079: 1, 923: 1, 922: 1, 924: 1, 1081: 1, 1076: 1})
y= {1002: 1953, 996: 1927, 1027: 773, 1021: 1187, 1008: 1897, 1003: 1973, 998: 2045, 989: 1713, 1017: 1366, 1037: 368, 965: 448, 990: 1746, 1024: 974, 974: 830, 969: 660, 976: 987, 958: 219, 1009: 1782, 987: 1639, 1001: 2041, 986: 1561, 1022: 1044, 1004: 2007, 973: 779, 1005: 1912, 975: 863, 1042: 220, 972: 780, 988: 1595, 1000: 2012, 994: 1779, 966: 467, 1016: 1457, 1010: 1753, 982: 1308, 1013: 1604, 978: 1075, 970: 648, 1023: 1008, 991: 1843, 1006: 1967, 946: 49, 983: 1421, 984: 1423, 985: 1508, 1036: 423, 999: 1983, 1025: 918, 1007: 1933, 1056: 40, 1028: 807, 997: 1895, 977: 1021, 1030: 661, 968: 577, 960: 259, 1011: 1738, 981: 1272, 1029: 727, 1051: 78, 995: 1962, 1014: 1612, 1026: 849, 956: 180, 1043: 202, 992: 1816, 945: 32, 980: 1201, 967: 522, 1018: 1373, 971: 712, 993: 1818, 1047: 134, 1045: 172, 1019: 1195, 1020: 1233, 964: 367, 1031: 578, 1032: 521, 1038: 330, 959: 226, 1015: 1488, 1033: 480, 1012: 1683, 957: 207, 1044: 177, 1034: 490, 955: 158, 963: 386, 1035: 452, 1040: 275, 1053: 46, 939: 27, 1050: 95, 961: 299, 952: 114, 1057: 37, 1048: 105, 1046: 122, 940: 19, 951: 103, 962: 332, 1075: 3, 1055: 40, 979: 1113, 1041: 277, 950: 99, 948: 60, 1039: 287, 1052: 64, 1049: 108, 1067: 11, 954: 137, 1061: 20, 1054: 42, 937: 17, 944: 48, 1064: 17, 1060: 23, 953: 120, 1058: 35, 1068: 9, 1066: 8, 947: 65, 933: 9, 941: 28, 1071: 6, 942: 17, 938: 17, 1082: 1, 934: 8, 1063: 9, 949: 63, 932: 7, 1073: 5, 935: 10, 1069: 7, 943: 35, 930: 4, 1065: 5, 936: 5, 928: 6, 926: 4, 1059: 24, 1062: 23, 1078: 2, 931: 3, 1070: 5, 929: 2, 925: 6, 1077: 1, 1079: 1, 923: 1, 927: 2, 920: 2, 922: 1, 924: 1, 1072: 2, 1081: 1, 1076: 1}
接下来,对该数据进行排序
y = sorted(y.items(), key=lambda item: item[1], reverse=False)
print(y)
cps, count = zip(*y)
print(cps)
print(count)
plt.scatter(cps, count)
plt.xlabel('值')
plt.xlim(0, 2000)
plt.ylabel('次数')
plt.ylim((0, 2500))
plt.show()y = sorted(y.items(), key=lambda item: item[1], reverse=False),是按照字典value值从小到大进行排序,对应输出:
y= [(1094, 1), (1080, 1), (1090, 1), (1081, 1), (910, 1), (1078, 1), (923, 1), (1070, 2), (925, 2), (1075, 2), (1076, 2), (928, 2), (924, 2), (1074, 2), (1072, 2), (934, 3), (921, 3), (932, 4), (926, 4), (927, 4), (931, 4), (1069, 5), (1071, 5), (1068, 5), (1073, 5), (1067, 5), (930, 5), (929, 5), (1066, 8), (933, 9), (935, 10), (937, 13), (1065, 13), (1064, 14), (936, 14), (939, 15), (938, 16), (1062, 17), (940, 18), (1063, 19), (1061, 21), (1060, 22), (1059, 23), (941, 23), (1057, 24), (942, 32), (944, 34), (1056, 37), (945, 37), (943, 38), (1058, 40), (1055, 44), (1054, 52), (947, 53), (946, 56), (1053, 58), (949, 59), (948, 72), (1052, 74), (1051, 75), (950, 83), (951, 99), (1050, 104), (1048, 114), (1049, 118), (952, 121), (953, 124), (1047, 129), (1046, 144), (954, 150), (1045, 159), (957, 168), (955, 172), (956, 177), (1043, 183), (1044, 192), (1042, 213), (959, 217), (958, 232), (1041, 242), (1040, 266), (960, 287), (961, 293), (1038, 304), (1039, 331), (962, 333), (1036, 371), (964, 380), (963, 383), (1037, 384), (1035, 452), (965, 455), (966, 468), (1033, 477), (1034, 520), (967, 545), (1032, 545), (1031, 585), (968, 591), (969, 627), (1030, 635), (970, 647), (1029, 686), (971, 701), (1028, 747), (1027, 797), (973, 806), (972, 807), (1026, 837), (974, 853), (1025, 876), (975, 947), (1024, 974), (976, 977), (977, 979), (1021, 1056), (1023, 1058), (978, 1065), (1022, 1140), (1020, 1181), (979, 1187), (980, 1198), (981, 1234), (982, 1296), (1019, 1327), (1018, 1344), (1016, 1380), (1017, 1412), (983, 1422), (984, 1469), (986, 1543), (1014, 1552), (1015, 1554), (987, 1576), (985, 1580), (1012, 1603), (1013, 1671), (990, 1688), (989, 1694), (1011, 1715), (1010, 1729), (988, 1758), (992, 1767), (991, 1778), (1009, 1786), (993, 1841), (994, 1869), (1008, 1878), (1007, 1892), (1005, 1916), (1003, 1940), (1004, 1942), (995, 1961), (998, 1968), (1006, 1969), (1002, 1977), (1000, 1980), (999, 1982), (997, 1986), (996, 1990), (1001, 2019)]
zip(*)是将列表拆成几个列表,例如zip(*[(11,22),(12,23),(,13,24)]),将得到两个列表[11,12,13],[22,23,24],对应输出:
(1094, 1080, 1090, 1081, 910, 1078, 923, 1070, 925, 1075, 1076, 928, 924, 1074, 1072, 934, 921, 932, 926, 927, 931, 1069, 1071, 1068, 1073, 1067, 930, 929, 1066, 933, 935, 937, 1065, 1064, 936, 939, 938, 1062, 940, 1063, 1061, 1060, 1059, 941, 1057, 942, 944, 1056, 945, 943, 1058, 1055, 1054, 947, 946, 1053, 949, 948, 1052, 1051, 950, 951, 1050, 1048, 1049, 952, 953, 1047, 1046, 954, 1045, 957, 955, 956, 1043, 1044, 1042, 959, 958, 1041, 1040, 960, 961, 1038, 1039, 962, 1036, 964, 963, 1037, 1035, 965, 966, 1033, 1034, 967, 1032, 1031, 968, 969, 1030, 970, 1029, 971, 1028, 1027, 973, 972, 1026, 974, 1025, 975, 1024, 976, 977, 1021, 1023, 978, 1022, 1020, 979, 980, 981, 982, 1019, 1018, 1016, 1017, 983, 984, 986, 1014, 1015, 987, 985, 1012, 1013, 990, 989, 1011, 1010, 988, 992, 991, 1009, 993, 994, 1008, 1007, 1005, 1003, 1004, 995, 998, 1006, 1002, 1000, 999, 997, 996, 1001)
(1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 8, 9, 10, 13, 13, 14, 14, 15, 16, 17, 18, 19, 21, 22, 23, 23, 24, 32, 34, 37, 37, 38, 40, 44, 52, 53, 56, 58, 59, 72, 74, 75, 83, 99, 104, 114, 118, 121, 124, 129, 144, 150, 159, 168, 172, 177, 183, 192, 213, 217, 232, 242, 266, 287, 293, 304, 331, 333, 371, 380, 383, 384, 452, 455, 468, 477, 520, 545, 545, 585, 591, 627, 635, 647, 686, 701, 747, 797, 806, 807, 837, 853, 876, 947, 974, 977, 979, 1056, 1058, 1065, 1140, 1181, 1187, 1198, 1234, 1296, 1327, 1344, 1380, 1412, 1422, 1469, 1543, 1552, 1554, 1576, 1580, 1603, 1671, 1688, 1694, 1715, 1729, 1758, 1767, 1778, 1786, 1841, 1869, 1878, 1892, 1916, 1940, 1942, 1961, 1968, 1969, 1977, 1980, 1982, 1986, 1990, 2019)
这样就得到了,正太分布对应的点了,横轴标是值,纵坐标是这些值出现的次数
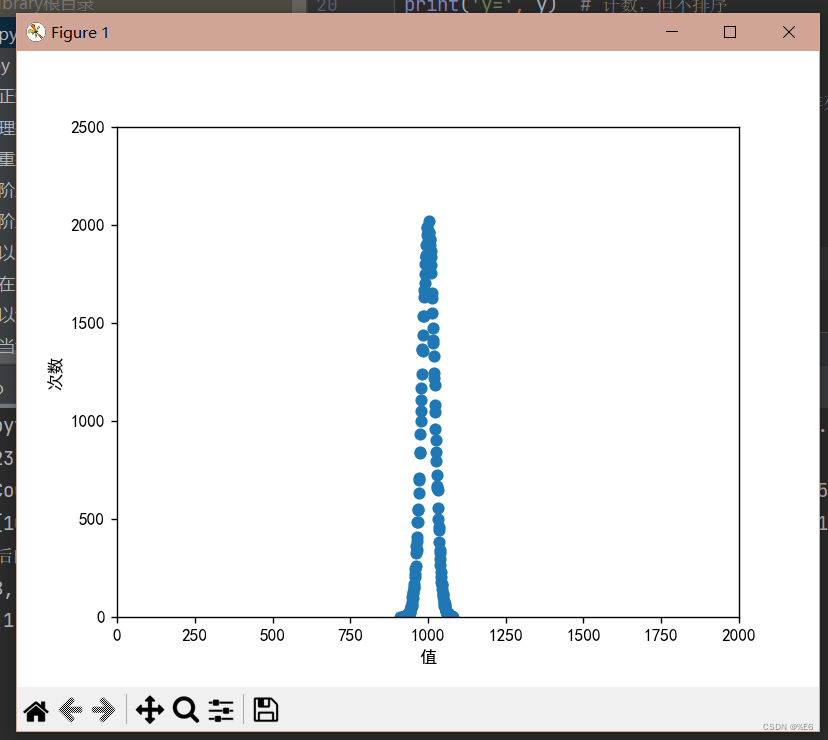
我坐标轴能使用中文的原因是加上这两行代码:
plt.rcParams['font.sans-serif'] = 'SimHei' # 解决图标中文
plt.rc('axes', unicode_minus=False) # 解决负数
2.使用np.unique方法
numpy.unique(ar, return_index=False, return_inverse=False, return_counts=False)
可以返回最多四个数组
可以返回 数组的唯一值,ar是输入的数组,只输入ar时,返回在ar中的唯一元素的数组br
return_index,为True时返回一个唯一元素在ar数组中的位置的数组
return_inverse,为True时返回一个唯一元素在br数组中的位置的数组
return_counts,为True时返回一个唯一元素出现的次数的数组
例如:
x = [1007, 957, 993, 982, 1015, 998, 974, 993, 1014, 1016]
a, b, c, d = np.unique(x, return_index=True, return_inverse=True, return_counts=True)
print('唯一元素=', a) # 从小到大排列
print('元素位置=', b)
print('元素位置=', c)
print('出现次数=', d)输出:
唯一元素= [ 957 974 982 993 998 1007 1014 1015 1016]
元素位置= [1 6 3 2 5 0 8 4 9]
元素位置= [5 0 3 2 7 4 1 3 6 8]
出现次数= [1 1 1 2 1 1 1 1 1]学了np.unique()方法后,我们只要用到np.unique(ar,return_counts=True)就行了
import numpy as np
import matplotlib.pyplot as plt
n = 100000
ex = 1000
de = 20
y = np.random.normal(ex, de, n)
y = np.round(y).astype(int) # 将y的每个元素四舍五入为整数
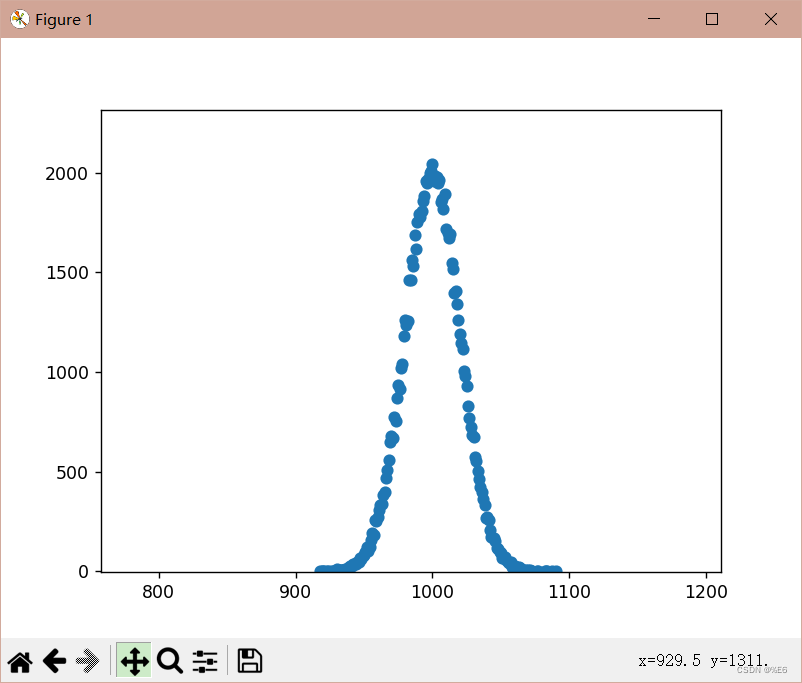
un, cnt = np.unique(y, return_counts=True)
plt.scatter(un, cnt)
plt.show()输出:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









