




论文标题: FinePOSE: Fine-grained Prompt-driven 3D Human Pose Estimation via Diffusion Models
代码仓库:https://github.com/PKU-ICST-MIPL/FinePOSE_CVPR2024
前言
在 3D 人体姿态估计领域,如何有效地利用文本语义信息一直是一个难点。CVPR 2024 的 FinePOSE 提出了一种基于扩散模型的细粒度提示驱动框架,通过引入 CLIP 和多层次的 Prompt 机制,显著提升了姿态估计的精度。
本文将结合论文架构图,逐行解析 FinePOSE 的核心代码实现(mixste_finepose.py),理解这个模型是如何一步步将文本、时间和空间信息融合在一起的。
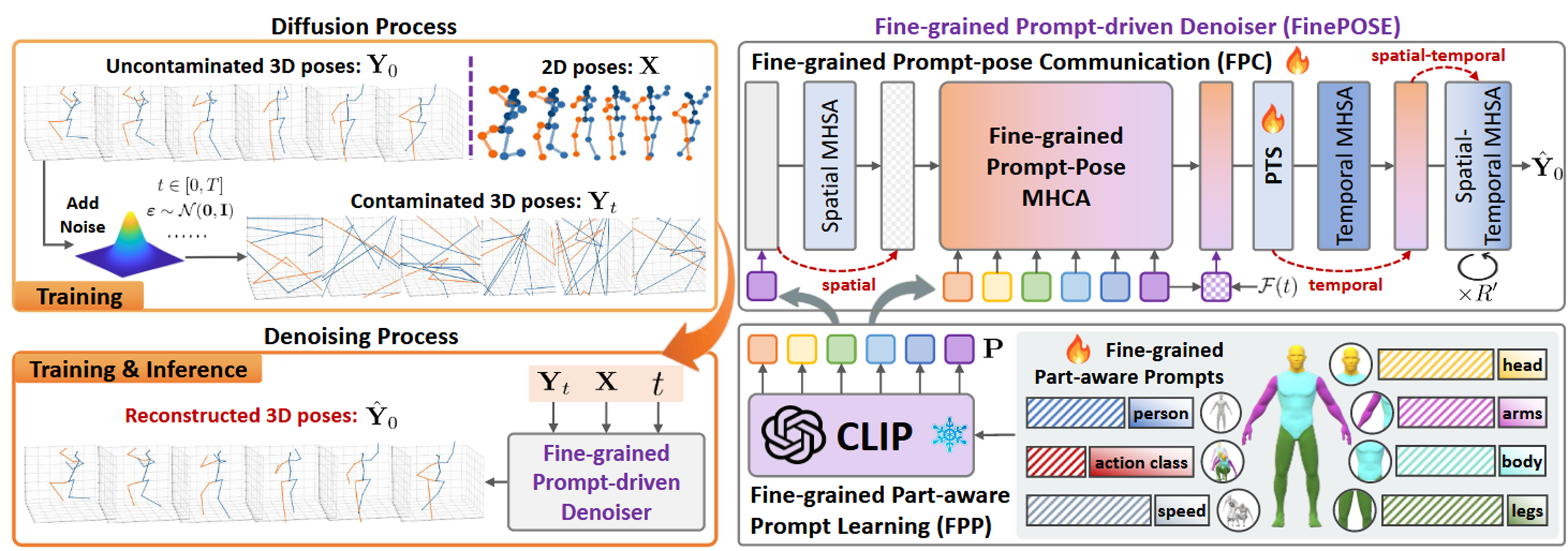
一、 Transformer 构建块
FinePOSE 里无论是处理空间的 STE 还是处理时间的 TTE,它们底层调用的都是以下三个标准类。
1. MLP
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0., changedim=False, currentdim=0, depth=0):
"""
初始化 MLP 模块。
Args:
in_features (int): 输入特征的维度。
hidden_features (int, optional): 隐藏层的维度。如果为 None,则默认等于输入维度。通常 hidden_features 会比 in_features 大 (比如 4 倍)。
out_features (int, optional): 输出特征的维度。如果为 None,则默认等于输入维度。
act_layer (nn.Module, optional): 激活函数层,默认为 GELU (Gaussian Error Linear Units)。
drop (float, optional): Dropout 丢弃率,用于防止过拟合。
changedim, currentdim, depth: (这些参数在当前代码逻辑中似乎未被直接使用,可能是为了兼容某些特殊的动态调整接口保留的冗余参数)
"""
super().__init__() # 初始化父类 nn.Module
# 处理默认参数:如果没指定输出/隐藏层维度,就设为和输入一样
out_features = out_features or in_features
hidden_features = hidden_features or in_features
# 第一层全连接:将特征从 in_features 映射到 hidden_features (通常是升维)
self.fc1 = nn.Linear(in_features, hidden_features)
# 激活函数:引入非线性因素,让网络能拟合复杂函数
self.act = act_layer()
# 第二层全连接:将特征从 hidden_features 映射回 out_features (通常是降维回原尺寸)
self.fc2 = nn.Linear(hidden_features, out_features)
# Dropout 层:随机丢弃神经元,防止过拟合
self.drop = nn.Dropout(drop)
def forward(self, x):
"""
前向传播逻辑
输入 x 的形状通常为: [Batch, ..., in_features]
"""
# 1. 线性变换 (升维)
x = self.fc1(x)
# 2. 非线性激活 (GELU)
x = self.act(x)
# 3. 第一次 Dropout
x = self.drop(x)
# 4. 线性变换 (降维/恢复维度)
x = self.fc2(x)
# 5. 第二次 Dropout
x = self.drop(x)
# 返回处理后的特征
return x2. Attention
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., comb=False, vis=False):
"""
Args:
dim (int): 输入特征维度。
num_heads (int): 多头注意力的头数。
qkv_bias (bool): 生成 Q,K,V 的线性层是否使用偏置。
qk_scale (float): 手动设置缩放因子,如果为 None 则使用默认的 1/sqrt(head_dim)。
attn_drop (float): 注意力矩阵的 Dropout 率。
proj_drop (float): 输出投影层的 Dropout 率。
comb (bool): 一个特殊的开关,用于切换注意力计算的维度顺序 (可能是为了适配特定的时空注意力变体)。
vis (bool): 是否开启可视化模式 (代码中似乎仅作为标志位)。
"""
super().__init__()
self.num_heads = num_heads
# 计算每个头的维度
head_dim = dim // num_heads
# 缩放因子:防止点积结果过大导致 Softmax 梯度消失
self.scale = qk_scale or head_dim ** -0.5
# 定义生成 Q, K, V 的全连接层
# 输出维度是 dim * 3,因为它要同时生成 Q, K, V 三份数据
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
# 输出投影层:把多头的结果融合回原来的维度
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.comb = comb # 组合模式开关
self.vis = vis # 可视化开关
def forward(self, x, vis=False):
"""
前向传播
输入 x: [Batch, N (序列长度), C (特征维度)]
"""
B, N, C = x.shape
# 1. 生成 Q, K, V
# self.qkv(x) -> [B, N, 3*C]
# reshape -> [B, N, 3, num_heads, head_dim]
# permute -> [3, B, num_heads, N, head_dim]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# 分离出 Q, K, V
# q, k, v 的形状都是 [B, num_heads, N, head_dim]
q, k, v = qkv[0], qkv[1], qkv[2]
# 2. 计算注意力分数 (Attention Score)
if self.comb == True:
# 特殊模式:可能是在进行通道注意力 (Channel Attention) 或某种转置计算
# q.transpose(-2, -1) -> [B, num_heads, head_dim, N]
# attn = [B, num_heads, head_dim, N] @ [B, num_heads, N, head_dim] -> [B, num_heads, head_dim, head_dim]
# 这种计算方式得到的注意力图大小是 head_dim * head_dim,关注的是特征通道间的关系
attn = (q.transpose(-2, -1) @ k) * self.scale
elif self.comb == False:
# 标准模式:空间/时间注意力 (Spatial/Temporal Attention)
# k.transpose(-2, -1) -> [B, num_heads, head_dim, N]
# attn = [B, num_heads, N, head_dim] @ [B, num_heads, head_dim, N] -> [B, num_heads, N, N]
# 这种计算方式得到的注意力图大小是 N * N,关注的是序列元素间的关系 (例如帧与帧)
attn = (q @ k.transpose(-2, -1)) * self.scale
# 3. Softmax 归一化
# 将分数转换为概率分布 (0~1 之间,和为 1)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# 4. 加权求和 (Weighted Sum)
if self.comb == True:
# 特殊模式的后续处理
x = (attn @ v.transpose(-2, -1)).transpose(-2, -1)
x = rearrange(x, 'B H N C -> B N (H C)')
elif self.comb == False:
# 标准模式:利用注意力概率对 V 进行加权
# [B, num_heads, N, N] @ [B, num_heads, N, head_dim] -> [B, num_heads, N, head_dim]
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # 还原形状为 [B, N, C]
# 5. 输出投影
x = self.proj(x)
x = self.proj_drop(x)
return x3. Block
这是 STE 和 TTE 共用的核心模块
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., attention=Attention, qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, comb=False, changedim=False, currentdim=0, depth=0, vis=False):
"""
Args:
dim (int): 输入/输出特征维度。
num_heads (int): 注意力头数。
mlp_ratio (float): MLP 隐藏层的放大倍数 (通常为 4)。
attention (class): 使用的 Attention 类 (默认为上面定义的 Attention)。
drop_path (float): 随机深度 (Stochastic Depth) 的概率,用于训练深层网络。
changedim (bool): 是否改变特征维度 (这是该模型的一个特殊设计,可能用于构建 U-Net 形状的 Transformer)。
currentdim, depth: 用于控制 changedim 逻辑的参数。
"""
super().__init__()
self.changedim = changedim
self.currentdim = currentdim
self.depth = depth
if self.changedim:
assert self.depth > 0 # 如果开启维度变化,必须指定总深度
# 第一个 LayerNorm (用于 Attention 之前)
self.norm1 = norm_layer(dim)
# Attention 模块
self.attn = attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, comb=comb, vis=vis)
# DropPath (随机深度):在训练时随机丢弃整个残差分支,有助于深层网络的训练
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# 第二个 LayerNorm (用于 MLP 之前)
self.norm2 = norm_layer(dim)
# MLP 模块
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
# --- 特殊的维度调整逻辑 (类似 U-Net 的下采样/上采样) ---
if self.changedim and self.currentdim < self.depth//2:
# 如果在网络的前半部分,进行降维 (Reduction)
# 使用 1x1 卷积将维度减半: dim -> dim // 2
self.reduction = nn.Conv1d(dim, dim//2, kernel_size=1)
elif self.changedim and depth > self.currentdim > self.depth//2:
# 如果在网络的后半部分,进行升维 (Improve/Expansion)
# 使用 1x1 卷积将维度翻倍: dim -> dim * 2
self.improve = nn.Conv1d(dim, dim*2, kernel_size=1)
self.vis = vis
def forward(self, x, vis=False):
"""
前向传播
输入 x: [Batch, Sequence, Dim]
"""
# 1. Attention 分支 (Pre-Norm 结构)
# x = x + DropPath(Attention(LayerNorm(x)))
x = x + self.drop_path(self.attn(self.norm1(x), vis=vis))
# 2. MLP 分支
# x = x + DropPath(MLP(LayerNorm(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
# 3. 维度调整 (可选)
# 这里的 rearrange 操作是为了适配 Conv1d 的输入格式 (Batch, Channel, Length)
if self.changedim and self.currentdim < self.depth//2:
x = rearrange(x, 'b t c -> b c t') # 交换维度,把特征放到第 1 维
x = self.reduction(x) # 降维
x = rearrange(x, 'b c t -> b t c') # 换回来
elif self.changedim and self.depth > self.currentdim > self.depth//2:
x = rearrange(x, 'b t c -> b c t')
x = self.improve(x) # 升维
x = rearrange(x, 'b c t -> b t c')
return x二、 核心组件
1. FPP模块核心
可学习向量(ctx_subject、ctx_verb、ctx_speed、ctx_head、ctx_body、ctx_arm、ctx_leg)在模型初始化部分进行定义。
为了从加了噪声的3D姿态重建出纯净的3D姿态,FinePOSE使用常规的2D关键点X、t和细粒度、部位感知的提示嵌入P来指导去噪过程。我们利用FPP模块来学习这个P。FPP模块在提示嵌入空间中编码了三种与姿态相关的信息,包括其动作类别、粗粒度和细粒度的人体部位(如“人、头、身体、手臂、腿”)以及运动学信息“速度”。
P的形状是K,L,D,K是文本提示的数量、L是每个提示中的token数量、D是token嵌入的维度。K=7,且text分别表示{人, [动作类别], 速度, 头, 身体, 手臂, 腿},每个文本提示的前四个token与可学习向量拼在一起作为最终嵌入。可学习向量通过u=0、标准差为0.02的高斯分布初始化。
def encode_text(self, text, pre_text_tensor):
"""
处理文本提示,实现 FPP 模块的核心功能
将原始文本与可学习向量结合,并提取全局和细粒度特征
"""
# 使用冻结的 CLIP 模型将文本 ID 转换为初始向量表示
with torch.no_grad():
# x 是动作类别的嵌入,维度为 [Batch, 77, 512]
# .type() 确保数据精度与 CLIP 模型一致,通常是半精度或单精度
x = self.clip_text.token_embedding(text).type(self.clip_text.dtype)
# pre_text_tensor 是其他 6 个静态属性的嵌入,维度为 [Batch, 6, 77, 512]
pre_text_tensor = self.clip_text.token_embedding(pre_text_tensor).type(self.clip_text.dtype)
#构建混合提示:处理 Subject 部分
# 获取可学习参数,维度为 [M, 512]
learnable_prompt_subject = self.ctx_subject
# 增加 Batch 维度并广播,维度变为 [Batch, M, 512]
learnable_prompt_subject = learnable_prompt_subject.view(1, self.ctx_subject.shape[0], self.ctx_subject.shape[1])
learnable_prompt_subject = learnable_prompt_subject.repeat(x.shape[0], 1, 1)
# 将可学习向量与原始文本的前几个 token 拼接
# 这里取 pre_text_tensor 的第 0 个属性
learnable_prompt_subject = torch.cat((learnable_prompt_subject, pre_text_tensor[:, 0, :self.remain_len, :]), dim=1)
# 构建混合提示:处理 Verb 部分
# 注意这里的硬提示来自输入的动态文本 x
learnable_prompt_verb = self.ctx_verb
learnable_prompt_verb = learnable_prompt_verb.view(1, self.ctx_verb.shape[0], self.ctx_verb.shape[1])
learnable_prompt_verb = learnable_prompt_verb.repeat(x.shape[0], 1, 1)
learnable_prompt_verb = torch.cat((learnable_prompt_verb, x[:, :self.remain_len, :]), dim=1)
# 构建混合提示:处理 Speed 部分
learnable_prompt_speed = self.ctx_speed
learnable_prompt_speed = learnable_prompt_speed.view(1, self.ctx_speed.shape[0], self.ctx_speed.shape[1])
learnable_prompt_speed = learnable_prompt_speed.repeat(x.shape[0], 1, 1)
# 这里取 pre_text_tensor 的第 1 个属性
learnable_prompt_speed = torch.cat((learnable_prompt_speed, pre_text_tensor[:, 1, :self.remain_len, :]), dim=1)
# 构建混合提示:处理身体部位 Head, Body, Arm, Leg
# 分别取 pre_text_tensor 的第 2, 3, 4, 5 个属性进行拼接
learnable_prompt_head = self.ctx_head
learnable_prompt_head = learnable_prompt_head.view(1, self.ctx_head.shape[0], self.ctx_head.shape[1])
learnable_prompt_head = learnable_prompt_head.repeat(x.shape[0], 1, 1)
learnable_prompt_head = torch.cat((learnable_prompt_head, pre_text_tensor[:, 2, :self.remain_len, :]), dim=1)
learnable_prompt_body = self.ctx_body
learnable_prompt_body = learnable_prompt_body.view(1, self.ctx_body.shape[0], self.ctx_body.shape[1])
learnable_prompt_body = learnable_prompt_body.repeat(x.shape[0], 1, 1)
learnable_prompt_body = torch.cat((learnable_prompt_body, pre_text_tensor[:, 3, :self.remain_len, :]), dim=1)
learnable_prompt_arm = self.ctx_arm
learnable_prompt_arm = learnable_prompt_arm.view(1, self.ctx_arm.shape[0], self.ctx_arm.shape[1])
learnable_prompt_arm = learnable_prompt_arm.repeat(x.shape[0], 1, 1)
learnable_prompt_arm = torch.cat((learnable_prompt_arm, pre_text_tensor[:, 4, :self.remain_len, :]), dim=1)
learnable_prompt_leg = self.ctx_leg
learnable_prompt_leg = learnable_prompt_leg.view(1, self.ctx_leg.shape[0], self.ctx_leg.shape[1])
learnable_prompt_leg = learnable_prompt_leg.repeat(x.shape[0], 1, 1)
learnable_prompt_leg = torch.cat((learnable_prompt_leg, pre_text_tensor[:, 5, :self.remain_len, :]), dim=1)
# 将 7 个部分的混合提示拼接成一个超长的序列
# x 的维度变为 [Batch, Total_Length, 512]
x = torch.cat((learnable_prompt_subject, learnable_prompt_verb, learnable_prompt_speed, learnable_prompt_head, learnable_prompt_body, learnable_prompt_arm, learnable_prompt_leg), dim=1)
with torch.no_grad():
# 注入位置信息:CLIP 的位置编码包含了序列顺序信息
x = x + self.clip_text.positional_embedding.type(self.clip_text.dtype)
# 维度调整:PyTorch Transformer 要求输入形状为 [Seq_Len, Batch, Dim]
x = x.permute(1, 0, 2)
# 深度特征交互:让所有的 Prompt 部分利用注意力机制互相交流
x = self.clip_text.transformer(x)
# 层归一化
x = self.clip_text.ln_final(x).type(self.clip_text.dtype)
# 这里的 text_pre_proj 是一个占位符,不改变数据
x = self.text_pre_proj(x)
# 使用可训练的 Transformer 编码器进行领域适配
# 将 CLIP 的通用图像文本特征转化为 3D 姿态领域的文本特征
xf_out = self.textTransEncoder(x)
xf_out = self.text_ln(xf_out)
# 提取全局宏观指令
# text.argmax 找到每句话结束符号的位置,因为结束符 ID 最大
# 提取该位置的向量作为整句话的全局摘要
global_feature = xf_out[text.argmax(dim=-1), torch.arange(xf_out.shape[1])]
# 通过线性层映射,用于后续注入到时间步嵌入中
xf_proj = self.text_proj(global_feature)
# 准备微观细粒度指令
# 调整维度回 [Batch, Seq_Len, Dim],保留完整序列用于后续的跨模态交互
xf_out = xf_out.permute(1, 0, 2)
return xf_proj, xf_out2. PTS 模块核心
# 定义风格化模块
# 作用:将条件嵌入 (emb) 注入到特征 (h) 中,调节特征的分布 (scale & shift)
class StylizationBlock(nn.Module):
def __init__(self, latent_dim, time_embed_dim, dropout):
"""
Args:
latent_dim (int): 输入特征 h 的维度。
time_embed_dim (int): 条件嵌入 emb 的维度 (例如时间步编码)。
dropout (float): Dropout 概率。
"""
super().__init__()
# 1. 条件映射层
# 将条件向量映射为两倍的特征维度 (因为要生成 scale 和 shift 两个参数)
self.emb_layers = nn.Sequential(
nn.SiLU(), # 激活函数
nn.Linear(time_embed_dim, 2 * latent_dim), # 线性层: dim -> 2*dim
)
# 2. 归一化层
# 对输入特征 h 进行标准化
self.norm = nn.LayerNorm(latent_dim)
# 3. 输出层
self.out_layers = nn.Sequential(
nn.SiLU(),
nn.Dropout(p=dropout),
# 使用 zero_module 初始化,意味着初始输出为 0 (不改变主干流)
zero_module(nn.Linear(latent_dim, latent_dim)),
)
def forward(self, h, emb):
"""
前向传播
输入 h: [Batch, Sequence (T), Dim (D)] - 主干特征
输入 emb: [Batch, Dim (D)] 或 [Batch, 1, Dim] - 条件嵌入 (例如时间编码)
"""
B, T, D = h.shape
# 调整 emb 形状以匹配 h
emb = emb.view(B, T, D)
# 1. 计算 Scale 和 Shift
# 通过 MLP 处理条件向量
# [:, 0:1, :] 表示只取第一个时间步的特征
emb_out = self.emb_layers(emb)[:,0:1,:] # 形状: [B, 1, 2*D]
# 将结果切分为两份:缩放因子 (scale) 和 平移因子 (shift)
# chunk(..., 2, dim=2) -> [B, 1, D], [B, 1, D]
scale, shift = torch.chunk(emb_out, 2, dim=2)
# 2. 适应性归一化
# 公式: y = norm(x) * (1 + scale) + shift
# 这是条件生成的核心:利用外部条件来“调制”特征的均值和方差
h = self.norm(h) * (1 + scale) + shift
# 3. 输出处理
h = self.out_layers(h)
return h
3. FPC 模块核心
# 定义时序交叉注意力模块
# 作用:计算动作序列 (Query) 与文本序列 (Key/Value) 之间的注意力,实现多模态融合
class TemporalCrossAttention(nn.Module):
def __init__(self, latent_dim, text_latent_dim, num_head, dropout, time_embed_dim):
"""
Args:
latent_dim (int): 动作特征的维度 (D)。
text_latent_dim (int): 文本特征的维度 (L)。
num_head (int): 注意力头数。
time_embed_dim (int): 时间嵌入维度 (用于 StylizationBlock)。
"""
super().__init__()
self.num_head = num_head
# 归一化层
self.norm = nn.LayerNorm(latent_dim)
self.text_norm = nn.LayerNorm(text_latent_dim)
# 生成 Q, K, V 的线性层
# Query 来自动作特征,维度 D
self.query = nn.Linear(latent_dim, latent_dim)
# Key 和 Value 来自文本特征,维度从 L 映射到 D
self.key = nn.Linear(text_latent_dim, latent_dim)
self.value = nn.Linear(text_latent_dim, latent_dim)
self.dropout = nn.Dropout(dropout)
# 输出投影层:使用 StylizationBlock,不仅融合信息,还注入时间步信息
self.proj_out = StylizationBlock(latent_dim, time_embed_dim, dropout)
def forward(self, x, xf, emb):
"""
前向传播
输入 x: [Batch, T (Frames), D] - 动作特征序列
输入 xf: [Batch, N (Text Tokens), L] - 文本特征序列 (来自 CLIP)
输入 emb: [Batch, D] - 时间步嵌入
"""
B, T, D = x.shape
N = xf.shape[1] # 文本长度 (例如 77)
H = self.num_head
# 1. 生成 Query (来自动作 x)
# [B, T, D] -> [B, T, D] -> [B, T, 1, D]
query = self.query(self.norm(x)).unsqueeze(2)
# 2. 生成 Key (来自文本 xf)
# [B, N, L] -> [B, N, D] -> [B, 1, N, D]
key = self.key(self.text_norm(xf)).unsqueeze(1)
# 这里有个 repeat 操作,可能是为了处理文本 Batch 和动作 Batch 大小不一致的情况
key = key.repeat(int(B/key.shape[0]), 1, 1, 1)
# 3. 重塑维度以适应多头 (Multi-head)
# Query: [B, T, H, D/H]
query = query.view(B, T, H, -1)
# Key: [B, N, H, D/H]
key = key.view(B, N, H, -1)
# 4. 计算注意力分数
# 使用 einsum 进行张量乘法
# 'bnhd, bmhd -> bnmh' 含义:
# b: Batch, n: T (frames), m: N (text tokens), h: Head, d: Dim
# 计算每个帧 (n) 与每个文本 token (m) 的相关性
attention = torch.einsum('bnhd,bmhd->bnmh', query, key) / math.sqrt(D // H)
# Softmax 归一化 (在文本长度 m 维度上)
weight = self.dropout(F.softmax(attention, dim=2))
# 5. 生成 Value (来自文本 xf)
value = self.value(self.text_norm(xf)).unsqueeze(1)
value = value.repeat(int(B/value.shape[0]), 1, 1, 1)
value = value.view(B, N, H, -1)
# 6. 加权求和
# 'bnmh, bmhd -> bnhd'
# 用算出来的权重 (weight) 去加权文本的 Value
# 结果是每个帧都融合了相关的文本信息
y = torch.einsum('bnmh,bmhd->bnhd', weight, value).reshape(B, T, D)
# 7. 输出处理与残差连接
# 通过 StylizationBlock 进一步注入时间步信息 emb
# 残差连接
y = x + self.proj_out(y, emb)
return y三、 主模型架构 (MixSTE2)
1. 模型初始化
class MixSTE2(nn.Module):
def __init__(self, num_frame=9, num_joints=17, in_chans=2, embed_dim_ratio=32, depth=4,
num_heads=8, mlp_ratio=2., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.2, norm_layer=None, is_train=True):
"""
Args:
num_frame (int): 输入序列的帧数。
num_joints (int): 每帧姿态的关节点数量。
in_chans (int): 输入通道数,对于 2D 关键点,通常是 2 (x, y)。
embed_dim_ratio (int): 嵌入维度的大小。
depth (int): Transformer 编码器的深度(Block 的数量)。
num_heads (int): 多头注意力机制的头数。
mlp_ratio (float): MLP 层的隐藏维度与嵌入维度的比率。
qkv_bias (bool): 是否为 QKV 线性层启用偏置。
qk_scale (float): QK 缩放因子。
drop_rate (float): Dropout 率。
attn_drop_rate (float): Attention Dropout 率。
drop_path_rate (float): Stochastic Depth 的衰减率。
norm_layer (nn.Module): 归一化层,默认为 LayerNorm。
is_train (bool): 标记模型是否处于训练模式。
"""
super().__init__()
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
embed_dim = embed_dim_ratio # 嵌入维度
out_dim = 3 # 输出维度,3D 坐标 (x, y, z)
self.is_train = is_train
# 姿态嵌入模块
# 线性层,将每个关节点的输入特征(2D坐标+带噪3D坐标)映射到高维嵌入空间。
# in_chans + 3 表示输入是 2D(x,y) + 3D(x,y,z) = 5 维
self.Spatial_patch_to_embedding = nn.Linear(in_chans + 3, embed_dim_ratio)
# 可学习的空间位置编码,为每个关节点学习一个特定的位置嵌入。
# 维度: (1, num_joints, embed_dim)
self.Spatial_pos_embed = nn.Parameter(torch.zeros(1, num_joints, embed_dim_ratio))
# 可学习的时间位置编码,为序列中的每一帧学习一个特定的位置嵌入。
# 维度: (1, num_frame, embed_dim)
self.Temporal_pos_embed = nn.Parameter(torch.zeros(1, num_frame, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
# 时间步和文本提示嵌入模块
# MLP 网络,用于将扩散过程的时间步 t 转换为高维嵌入。
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbeddings(embed_dim_ratio), # 将标量 t 转换为正弦位置编码
nn.Linear(embed_dim_ratio, embed_dim_ratio * 2),
nn.GELU(),
nn.Linear(embed_dim_ratio * 2, embed_dim_ratio),
)
# Transformer 核心模块
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # 随机深度衰减规则
self.block_depth = depth
# 空间Transformer编码器块 (Spatial Transformer Encoder)
# 负责在单帧内对所有关节点之间的空间关系进行建模。
self.STEblocks = nn.ModuleList([
Block(
dim=embed_dim_ratio, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
# 时间Transformer编码器块 (Temporal Transformer Encoder)
# 负责对单个关节点在所有帧之间的时间动态进行建模。
self.TTEblocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.Spatial_norm = norm_layer(embed_dim_ratio)
self.Temporal_norm = norm_layer(embed_dim)
# 输出头
# 最终的线性层,将处理后的高维特征映射回 3D 坐标空间。
self.head = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, out_dim),
)
# 文本处理与交叉注意力模块
# 时间交叉注意力模块,实现图中的 FPC (Fine-grained Prompt-Pose Communication)
# Query 来自姿态特征,Key 和 Value 来自文本提示特征。
self.temporal_cross_attn = TemporalCrossAttention(512, 512, num_heads, drop_rate, 512)
# 文本编码器,用于进一步处理从 CLIP 获得的文本嵌入。
self.text_pre_proj = nn.Identity()
textTransEncoderLayer = nn.TransformerEncoderLayer(
d_model=512, nhead=num_heads, dim_feedforward=2048,
dropout=drop_rate, activation="gelu")
self.textTransEncoder = nn.TransformerEncoder(
textTransEncoderLayer, num_layers=4)
self.text_ln = nn.LayerNorm(512)
# 线性层,用于生成最终注入到姿态特征中的全局文本提示。
self.text_proj = nn.Sequential(
nn.Linear(512, 512)
)
# --- 可学习提示 (FPP) 模块 ---
# 加载预训练的 CLIP 模型,用于将文本转换为初始嵌入。
self.clip_text, _ = clip.load('ViT-B/32', "cpu")
set_requires_grad(self.clip_text, False) # 冻结 CLIP 模型参数
self.remain_len = 4 # 保留原始 token 的长度
# 定义一系列可学习的向量 (context vectors),这些就是 FPP 的核心。
# 它们与原始的文本 token 嵌入拼接在一起,形成新的、可优化的 prompt。
# 每个 `ctx_*` 对应图中的一类细粒度提示(如 person, action class, head, body 等)。
ctx_vectors_subject = torch.empty((7 - self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_subject, std=0.02)
self.ctx_subject = nn.Parameter(ctx_vectors_subject)
ctx_vectors_verb = torch.empty((12 - self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_verb, std=0.02)
self.ctx_verb = nn.Parameter(ctx_vectors_verb)
# ... (为 speed, head, body, arm, leg 定义类似的可学习向量) ...
ctx_vectors_speed = torch.empty((10-self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_speed, std=0.02)
self.ctx_speed = nn.Parameter(ctx_vectors_speed)
ctx_vectors_head = torch.empty((10-self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_head, std=0.02)
self.ctx_head = nn.Parameter(ctx_vectors_head)
ctx_vectors_body = torch.empty((10-self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_body, std=0.02)
self.ctx_body = nn.Parameter(ctx_vectors_body)
ctx_vectors_arm = torch.empty((14-self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_arm, std=0.02)
self.ctx_arm = nn.Parameter(ctx_vectors_arm)
ctx_vectors_leg = torch.empty((14-self.remain_len), 512, dtype=self.clip_text.dtype)
nn.init.normal_(ctx_vectors_leg, std=0.02)
self.ctx_leg = nn.Parameter(ctx_vectors_leg)2. Spatial MHSA模块核心
实现全局条件(时间+文本)的注入。
def STE_forward(self, x_2d, x_3d, t, xf_proj):
"""空间编码器前向传播"""
if self.is_train:
# 训练时,输入维度 (batch, frame, joint, channel)
x = torch.cat((x_2d, x_3d), dim=-1) # 拼接 2D 和 3D 姿态
b, f, n, c = x.shape
x = rearrange(x, 'b f n c -> (b f) n c') # (b*f, n, c) 方便进行空间处理
x = self.Spatial_patch_to_embedding(x) # 嵌入到高维
x += self.Spatial_pos_embed # 添加空间位置编码
time_embed = self.time_mlp(t)[:, None, None, :] # (b, 1, 1, dim)
xf_proj = xf_proj.view(xf_proj.shape[0], 1, 1, xf_proj.shape[1])
time_embed = time_embed + xf_proj # 注入全局文本提示
time_embed = time_embed.repeat(1, f, n, 1)
time_embed = rearrange(time_embed, 'b f n c -> (b f) n c')
x += time_embed # 将融合后的嵌入加到每个关节点特征上
else: # 测试时,因为有 num_proposals,所以多一个维度
# 维度 (batch, proposal, frame, joint, channel)
x_2d = x_2d[:, None].repeat(1, x_3d.shape[1], 1, 1, 1)
x = torch.cat((x_2d, x_3d), dim=-1)
b, h, f, n, c = x.shape
x = rearrange(x, 'b h f n c -> (b h f) n c')
# 后续操作与训练时类似
x = self.Spatial_patch_to_embedding(x)
x += self.Spatial_pos_embed
time_embed = self.time_mlp(t)[:, None, None, None, :]
xf_proj = xf_proj.view(xf_proj.shape[0], 1, 1, 1, xf_proj.shape[1])
time_embed = time_embed + xf_proj
time_embed = time_embed.repeat(1, h, f, n, 1)
time_embed = rearrange(time_embed, 'b h f n c -> (b h f) n c')
x += time_embed
x = self.pos_drop(x)
# 通过第一个空间 Transformer Block
blk = self.STEblocks[0]
x = blk(x)
x = self.Spatial_norm(x)
# 维度重排,为时间处理做准备: (b*f, n, dim) -> (b*n, f, dim)
x = rearrange(x, '(b f) n cw -> (b n) f cw', f=f)
return x, time_embed3.Temporal MHSA模块核心
在通过 FPC 模块吸收了文本信息后,数据的视角需要从特征融合切换回时序建模。这一步的核心任务是给数据打上时间戳,并进行初步的轨迹平滑。
def TTE_foward(self, x):
"""
输入 x: [Batch, Frame, Dim]
"""
b, f, _ = x.shape
# 1. 注入时间位置编码
# Transformer 不懂顺序,必需加上 Positional Embedding 才能理解 第1帧 和 第2帧 的区别
x += self.Temporal_pos_embed
x = self.self.pos_drop(x)
# 2. 初始时间建模
# 调用第 0 个时间 Block
# 这一步模型在 Frame 维度进行 Attention,平滑单个关节的运动轨迹
blk = self.TTEblocks[0]
x = blk(x)
x = self.Temporal_norm(x)
return x4.Spatial-Temporal MHSA模块核心
模型进入了一个循环,通过不断地切换空间视角(骨架结构)和时间视角(运动轨迹),对 3D 姿态进行精细打磨。
def ST_foward(self, x):
"""
交替进行时空编码
输入 x: [Batch, Frame, Joint, Dim]
"""
b, f, n, cw = x.shape
# 从第 1 个 Block 开始循环 (因为第 0 个已经被 STE 和 TTE 用掉了)
for i in range(1, self.block_depth):
# A. 空间步
# 维度重排: 'b f n c -> (b f) n c'
# 将 Frame 维度合并到 Batch 中,强迫模型忽略时间,只看单帧内的骨架
x = rearrange(x, 'b f n cw -> (b f) n cw')
steblock = self.STEblocks[i]
x = steblock(x)
x = self.Spatial_norm(x)
# B. 时间步
# 维度重排: '(b f) n c -> (b n) f c'
# 将 Joint 维度合并到 Batch 中,强迫模型忽略骨架,只看单关节的轨迹
x = rearrange(x, '(b f) n cw -> (b n) f cw', f=f)
tteblock = self.TTEblocks[i]
x = tteblock(x)
x = self.Temporal_norm(x)
# 恢复维度,准备进入下一次循环
x = rearrange(x, '(b n) f cw -> b f n cw', n=n)
return x
















 2393
2393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









