



提出背景
在VDSR提出之前,SRCNN等基于卷积神经网络(CNN)的模型已被应用于SISR任务,并取得了一定的成功。然而,这些模型存在以下局限性:
-
上下文信息有限:SRCNN等模型主要依赖于小范围的图像区域,无法充分利用大范围的上下文信息来恢复图像细节。
-
训练收敛速度慢:由于网络结构较浅,模型在训练过程中收敛速度较慢,影响了训练效率。
-
单一放大倍率:这些模型通常针对特定的放大倍率进行训练,缺乏对多种放大倍率的适应性。
解决方案
-
利用更深的网络结构加深网络深度:通过构建20层的深度卷积网络,扩大感受野,从而利用更大范围的上下文信息,提高图像细节的恢复能力。
-
采用残差学习加速训练:采用残差学习策略,直接学习高分辨率图像与低分辨率图像之间的差异(残差),加速模型的训练收敛。
-
多尺度训练:在训练过程中,结合不同放大倍率的图像数据,使单个模型能够适应多种放大倍率的超分辨率任务,提升模型的通用性。
模型架构
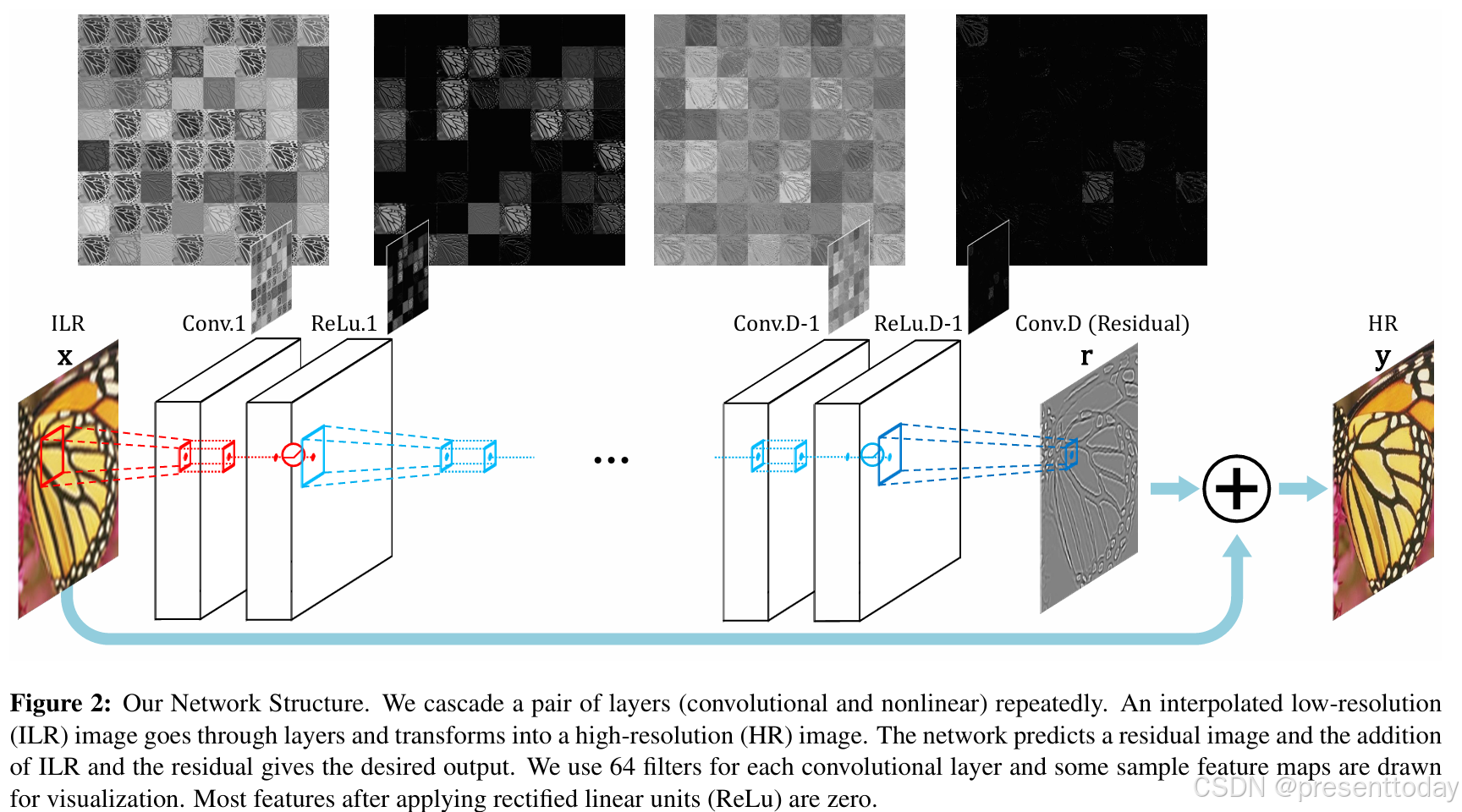
注释翻译:我们的网络结构。我们重复级联一对层(卷积层和非线性层)。一个插值后的低分辨率(ILR)图像经过各层处理并转换为高分辨率(HR)图像。网络预测一个残差图像,将ILR图像与残差相加得到期望的输出。我们为每个卷积层使用64个滤波器,并绘制了一些特征图以供可视化。应用整流线性单元(ReLU)后,大多数特征值为零。
VDSR使用了一个深度达20层的卷积神经网络,每层由3×3的小卷积核构成。除了第一层和最后一层,其余层都包含64个3×3的卷积核(第一层处理输入图像,最后一层输出残差图像)。这种深度和小卷积核设计旨在高效地利用大范围的图像上下文信息,从而提高超分辨率的精确度。(高效是因为卷积核比较小,计算量相对大卷积核小,而利用大范围的图像上下文信息是通过将小卷积核堆叠扩大感受野)
需要注意的细节:
1.输入图像并不是原始的低分辨率图像,而是插值后的低分辨率图像
2.在卷积前填充0以保证输入的图像大小和输出图像大小相同
模型训练
目标函数:VDSR的目标是使模型输出的高分辨率图像与真实的高分辨率图像尽可能接近。为此,使用了均方误差(Mean Squared Error, MSE)作为损失函数。具体来说,给定一个插值后的低分辨率图像和对应的真实高分辨率图像
,模型
的输出记为预测的残差图像,由此得到目标函数
高学习率与梯度截断:由于VDSR网络较深(20层卷积层),直接使用高学习率可能会导致梯度爆炸问题,影响训练稳定性,因此作者采用可调节梯度裁剪策略。可调节的梯度裁剪策略使得梯度在更新时被限制在一个动态范围内(根据当前的学习率进行裁剪),这样可以防止梯度爆炸,同时保持模型的训练稳定性
实验
实验证明了两件事:
1.深层次的网络对SR任务很重要,深层网络可以利用图像更多的上下文信息,并能用更多的非线性层来模拟复杂函数。
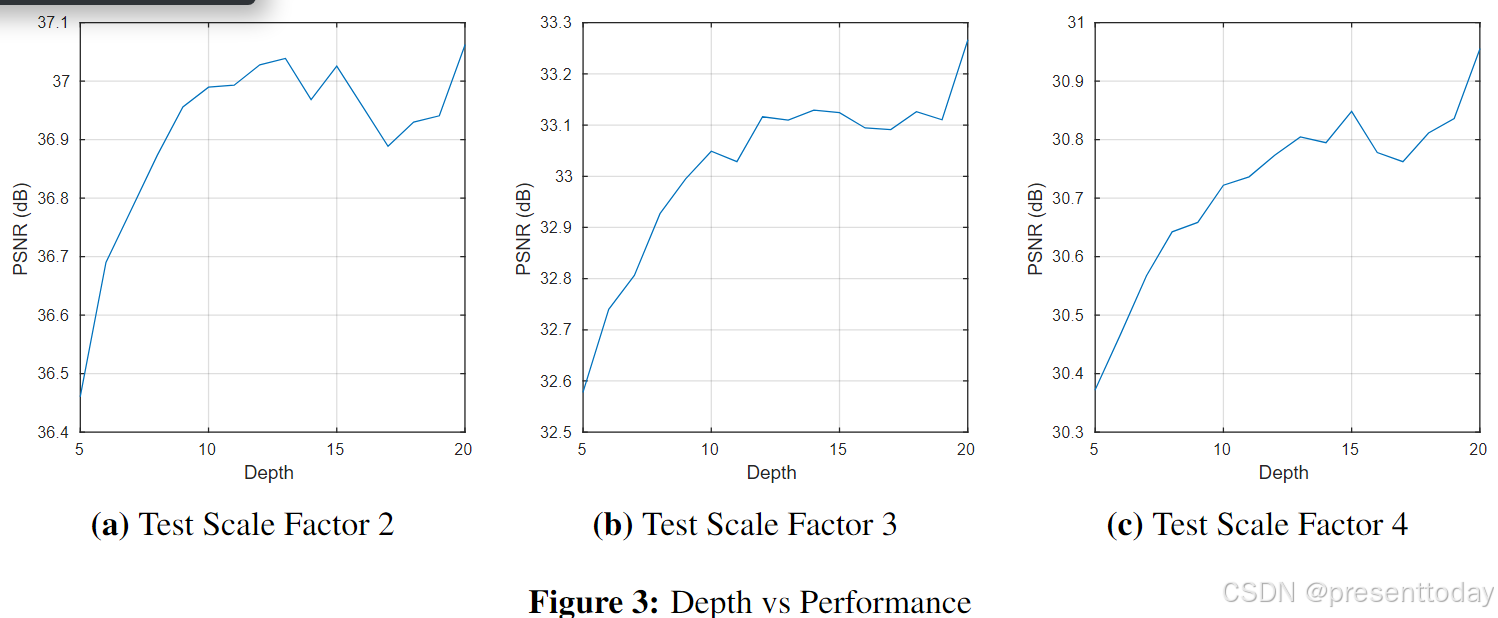
2.使用单个网络的方法与使用为多个尺度训练的多个网络的方法的性能一样好,而且单个网络的参数量还更少。

1)当train和Test使用统一尺度因子时(×2,×2),模型效果很好,但当Test和train使用不同的尺度因子(×2,×3),效果会显著降低.。因此在单一尺度上训练的网络无法处理其他尺度是数据
2)当尺度比较小时,多尺度(×2,3)(×2,4)(×2,3,4)训练的效果与单尺度训练的网络的结果相当。当尺度增大时,多尺度训练得到的网络效果更好。
总结
VDSR通过深度网络和残差学习,在单图像超分辨率任务中达到了卓越的效果。这种方法不仅提高了精度,而且具有多尺度处理的灵活性,适用于多种放大倍率需求。

















 1万+
1万+





 到【灌水乐园】发言
到【灌水乐园】发言







