



论文链接:https://arxiv.org/pdf/2108.00406
探究超分模型中“语义”信息的动机
SR 网络在特定场景下优于传统方法,但在泛化能力上却较差。在盲 SR 中,输入测试图像的退化类型是未知的。传统方法对不同的图像一视同仁,不区分退化类型,因此它们的性能通常是稳定和可预测的。盲超分任务的一个代表解决方案CinCGAN,能够把退化的 LR 图片映射为去退化作用之后的 HR 图片。但是作者发现 CinCGAN 的应用范围非常有限,即:如果训练数据中未包含输入图像的退化,即测试数据集与训练数据集不同,则 CinCGAN 将无法将退化的输入转换为干净的输入。作者进一步发现,CinCGAN 似乎没有处理输入图像并保留所有原始缺陷,而不是在图像中产生额外的伪影。换句话说,网络似乎会弄清楚其训练数据分布中的特定退化类型,而分布不匹配可能会使网络“关闭”其能力

图1:不同退化输入图像及其由 CinCGAN 和 BM3D 生成的对应输出。CinCGAN 在 DIV2K-mild 数据集上以无配对的方式训练。如果输入图像符合训练数据的分布,CinCGAN 将生成比 BM3D 更好的恢复结果(a)。然而,当输入图像的退化类型超出训练数据分布时,CinCGAN 往往会忽略未见过的退化类型,并几乎保持输入图像不变(b 和 c)。另一方面,传统方法 BM3D 在所有输入图像上均表现出稳定的性能,并具有类似的去噪效果,无论输入的退化类型如何
---
深度SR网络中的深度退化表示
由于最终输出总是来自 CNN 层中的特征,文中将高维 CNN 特征图转换为可以在散点图中可视化的低维数据点用于解释 CNN 的深层特征。具体操作是:PCA 把特征的维度降为50,再使用 t-SNE 降为2维进行可视化。
实验1:CinCGAN模型的语义信息是什么
由于 CinCGAN 模型对于不同的输入表现非常不同,作者比较了从三个测试数据集生成的特征:1) DIV2K-mild:CinCGAN 中使用的训练和测试数据,这些数据是从 DIV2K 数据集合成的,包含噪声、模糊、像素偏移和其他降级。2) DIV2K-noise20:将高斯噪声 (σ = 20) 添加到 DIV2K 集。3) Hollywood100:从好莱坞数据集中选择的 100 张图像,包含现实世界的老胶片退化。每个测试数据集包括 100 张图像。
这3个不同的数据集通过 CinCGAN 模型的可视化结果如下图(a)所示, 可以看到该模型对各种退化具有很强的特征可区分性。内容一致但退化类型不同的图像会分离到不同的群集中。这种现象符合作者的观察,即 CinCGAN 确实以不同的方式处理各种退化输入。它自然而然地揭示了 CinCGAN 中深度表示的“语义”,这些语义与退化类型而不是图像内容密切相关。这与分类任务的表现(语义信息相似的点才会聚集在一起)不相同,这说明 CinCGAN 模型中包含的语义信息与图像的退化类型密切相关,而不是与图像的内容信息密切相关
实验2:由CinCGAN模型推广至通用的基于GAN的SR架构
基于实验1的发现,作者想知道这种退化相关的语义信息是否在 SR 网络中是普遍存在的。在浅层网络SRCNN中,使用与CinCGAN相同的数据训练并对最后一层的特征表示可视化后发现,该网络无法明确区分不同的退化(如图b、图c)(作者由此推测与退化相关的语义只存在于深层模型中)。除此之外,作者使用了一个通用的基于 GAN 的 SR 架构 SRGAN-wGR (wGR 和 woGR 的意思分别表示网络是否有全局残差来重复可视化实验,区别如下图e。SRGAN只使用 DIV2K 数据集进行训练,其中只有双三次下采样的 LR 图像,没有其他退化作用。作者使用三个不同退化类型的数据集进行测试:1) DIV2K-clean:原始的 DIV2K 验证集,仅包含双三次下采样退化,符合训练数据分布。2) DIV2K-blur:在 DIV2K-clean 集中使用高斯模糊内核引入模糊退化。内核宽度从每个图像的 [2, 4] 中随机采样,内核大小固定为 15 × 15。3) DIV2K-noise:将高斯噪声添加到 DIV2K-clean 中使其包含额外的噪声信息。这三个测试数据集在图像内容上是一致的,但在退化类型上有所不同。
由图d可以看出来自相同退化类型的数据集的数据点聚类在一起。而对于不同退化类型的数据集,即使它们的图像内容相同,它们对应的数据点仍然属于不同的聚类中心。这3个数据集是完全相同的图像内容,只是退化作用不一样,结果是聚类成为了不同的3类,这个结果很好地说明了 SR 任务的语义信息其实是退化作用而不是图像内容(这种语义信息被作者称之为深度退化表示)。
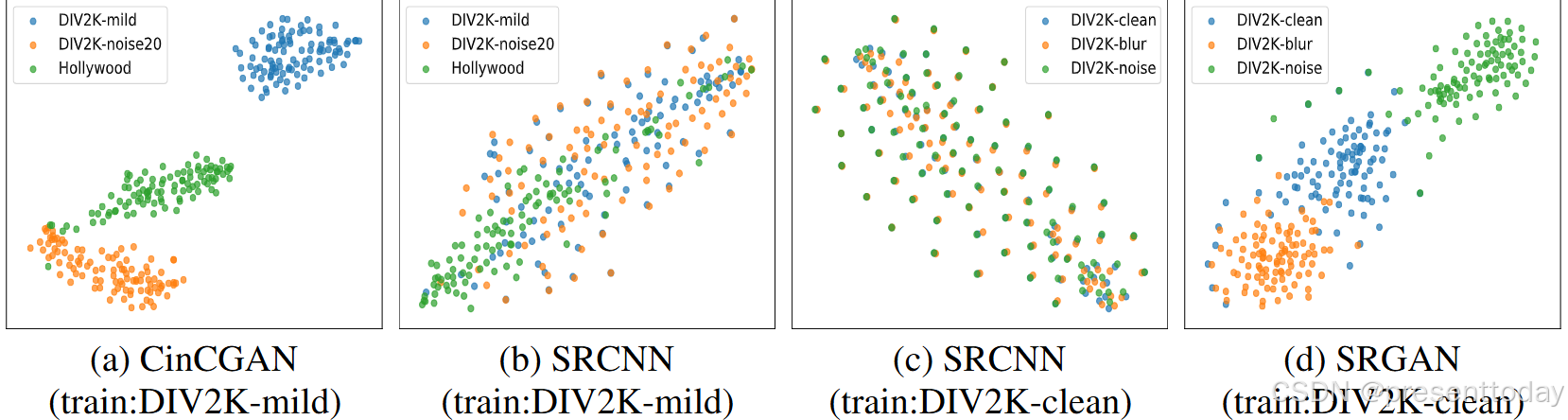
图2:3个不同的数据集通过 CinCGAN 模型 (a) 和SRCNN模型(b)(c)以及SRGAN 模型 (d) 的可视化结果
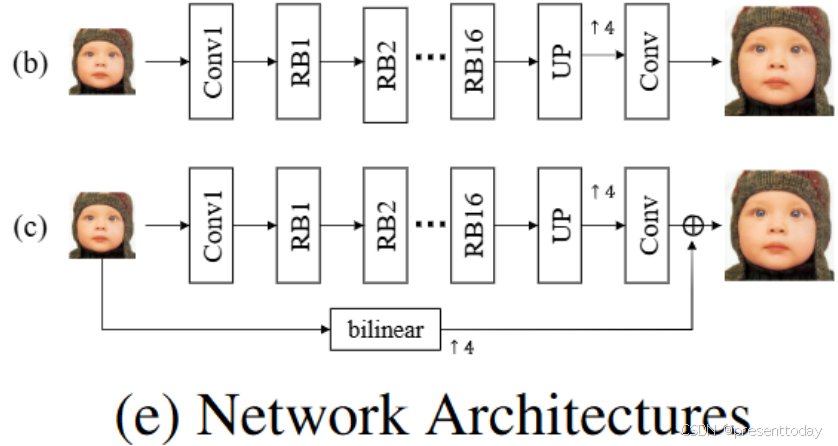
图3:s. (e)-b: SRResNet-woGR (没有全局残差). (e)-c:SRResNet (有全局残差). “RB1” r代表第一个残差模块.
---
超分模型和分类模型中 "语义" 信息的区别
在高级视觉中,分类是最具代表性的任务之一,由于已经有了人为预定义的对象类语义标签作为监督,分类网络被天然地被赋予了语义辨别的能力。作者以 ResNet-18 为例,在 CIFAR-10 数据集上测试,各个层的特征输出可视化结果如下图所示,从中可知,随着网络层数的加深,不同类别的图片的特征区分度更加明显且分类网络的语义信息与人工预先定义的类别标签是一致的。

图4:CIFAR-10 数据集在 ResNet-18 模型下的不同层特征的 t-SNE 可视化结果
在这之后,作者对比了超分模型和分类模型中 "语义" 信息的差异。作者首先在CIFAR-10测试集中加入模糊或者噪声退化(训练集中没有加入退化),如下图所示,在对测试数据进行退化后,分类网络 (ResNet18) 获得的深度表示仍然按对象类别进行聚类,表明这些特征更侧重于高级对象类别信息。相反,SR 网络(SRResNet 和 SRGAN)获得的深度表示在退化类型方面是聚集的。同一对象类别的特征没有聚集在一起,而相同退化类型的特征聚集在一起,显示出不同的“语义”可区分性。这种现象直观地说明了 SR 和分类网络之间深层语义表示的差异,即与退化相关的语义和与内容相关的语义的差异。
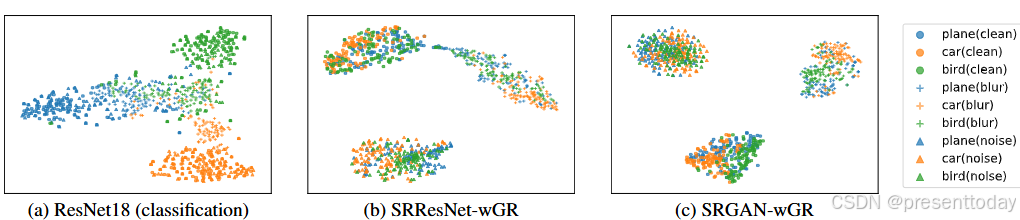
图5:分类网络和 SR 网络之间的特征表示差异。相同的对象类别由相同的颜色表示,相同的图像退化类型由相同的标记形状表示。对于分类网络(a)可以看出是按相同的颜色进行聚类,而 SR 网络是按相同的标记形状进行聚类。
小结
1.超分任务这种 Low-level 任务其语义信息代表这张图像的退化作用,而与这张图像的内容无关,作者将这种语义称为深度退化表示
2.传统方法或者浅层网络无法提取深度退化表示
除此之外,该论文还探讨了SR网络提取深度退化表示的关键(即全局残差学习和GAN-based)、超分模型是否能区分不同退化程度(答案是可以)的图像以及超分模型的泛化性,笔者还没有详细了解,有待更新。

















 8581
8581



 到【灌水乐园】发言
到【灌水乐园】发言








