







参考
https://zhuanlan.zhihu.com/p/60607178
Survival Strategies for the Robot Rebellion
与其道听途说,不如少走点弯路,轻松跟我来全面剖析 darknet 官网!_darknetguanwnag-优快云博客
目录
1 准备数据集
搞一个名为dataset的文件夹

里面有四个子文件夹,子文件夹的名称是标签的名称,里面放着对应标签的图像。我们这里选择 飞机、湖泊、猫、狗 各500张图像进行训练

子文件夹的图像文件名格式为 [类别名]_ID

我们简单看一下另外三个种类


也可以不像我上面那样命名,只需要修改 darknet/src/data.c 就行了,具体的就该方法在最后遇到问题的第一个有写
2 创建训练文件夹
首先在darknet目录下创建custom_classification这个文件夹

custom_classification中包含如下文件

下面我们说一下每个文件的内容
2.1 dataset
dataset是数据集,也就是我们准备的4类图像
2.2 trained_models
这个文件夹是空的,里面要放训练好的模型
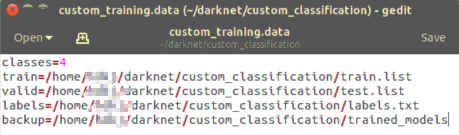
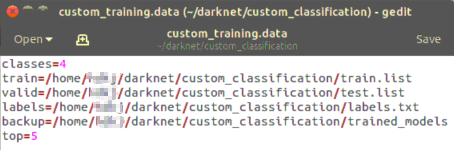
2.3 custom_training.data
是一个文本文档,用gedit就能创建,创建后改个尾缀就行

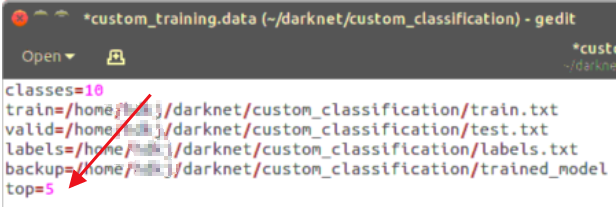
打开后有如下内容
- classes 种类数
- train 训练集图片路径
- valid 测试集图片路径
- labels 标签名称
- backup 训练后模型存放路径
在data中设置top这个键在训练中是没有用的,在测试中有用。如果设置为top=5,那么在测试的时候会给出5个置信最高的结果
2.4 get_train_val.py
功能是创建test.list与train.list这两个文件
代码的意思是 把dataset中所有图像的绝对路径放到列表里 -> 随机列表顺序 -> 把随机后的列表写到test.list与train.list中
import os
import random
train_file_list = []
val_file_list = []
folder_list = os.listdir('/home/suyu/darknet/custom_classification/dataset/')
for folder_name in folder_list:
a = 0
for filename in os.listdir('dataset/' + folder_name):
print(filename)
if a < len(os.listdir('dataset/' + folder_name))*0.8: #train
train_file_list.append('/home/suyu/darknet/custom_classification/dataset/' + folder_name + '/' + filename)
else: #test
val_file_list.append('/home/suyu/darknet/custom_classification/dataset/' + folder_name + '/' + filename)
a = a + 1
random.shuffle(train_file_list)
random.shuffle(val_file_list)
train_txt = open('train.list','w')
for i in train_file_list:
print(i)
print(i,file=train_txt,flush=True)
val_txt = open('test.list','w')
for j in val_file_list:
print(j)
print(j,file=val_txt,flush=True)
2.5 labels.txt

内容为四个标签的名称
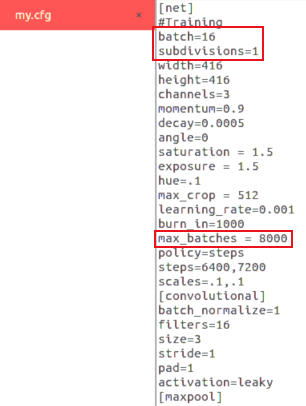
2.6 my.cfg

是训练用的神经网络,我在 使用darknet框架的imagenet数据分类预训练操作-腾讯云开发者社区-腾讯云 抄的
- darknet中提供的VGG,alexnet等cfg训练出来效果不好
[net]
#Training
batch=16
subdivisions=1
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
max_crop = 512
learning_rate=0.001
burn_in=1000
max_batches = 8000
policy=steps
steps=6400,7200
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
#######
[convolutional]
batch_normalize=1
size=1
stride=1
pad=1
filters=128
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
filters=4
size=1
stride=1
pad=1
activation=leaky
[avgpool]
[softmax]
groups = 1
[cost]
type=sse至少需要修改的有这样几个地方
- batch与subdivision根据机器能承受的最大值来
- max_batches 最大的训练batch数,我当前是按照 种类数*2000 来的,实际上不需要运行这么多batch。max_batches并不是越多越好,过多容易过拟合
最后一个输出层,种类是多少个就写多少
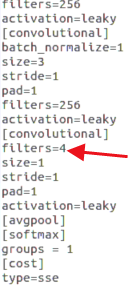
如果不对应在训练中会出现这种错误
![]()
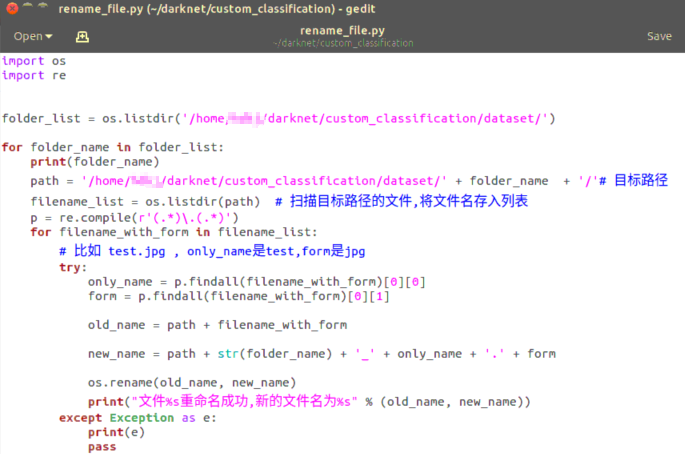
2.7 rename_file.py

这个是对dataset中所有图像加标签名的。比如原来是 1.jpg 如果在dog文件夹下就会被修改为 dog_1.jpg
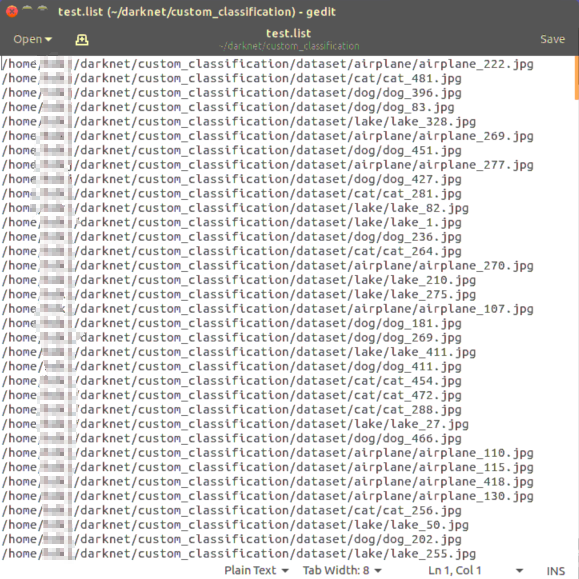
2.8 test.list
测试集图像的绝对路径
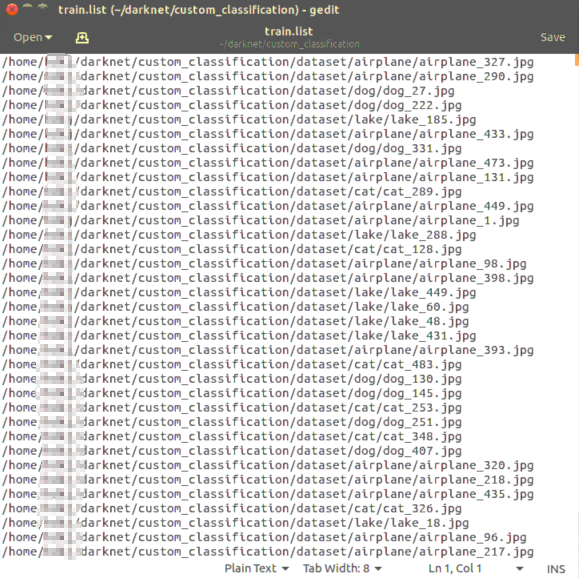
2.9 train.list
训练集图像的绝对路径
3 训练
在darknet路径下执行
- ./darknet classifier train [.data文件绝对路径] [.cfg文件绝对路径]
比如
- ./darknet classifier train /home/suyu/darknet/custom_classification/custom_training.data /home/suyu/darknet/custom_classification/my.cfg
执行后终端会显示一些东西
如果编译时OPENCV=1,那么就会出现一张图像
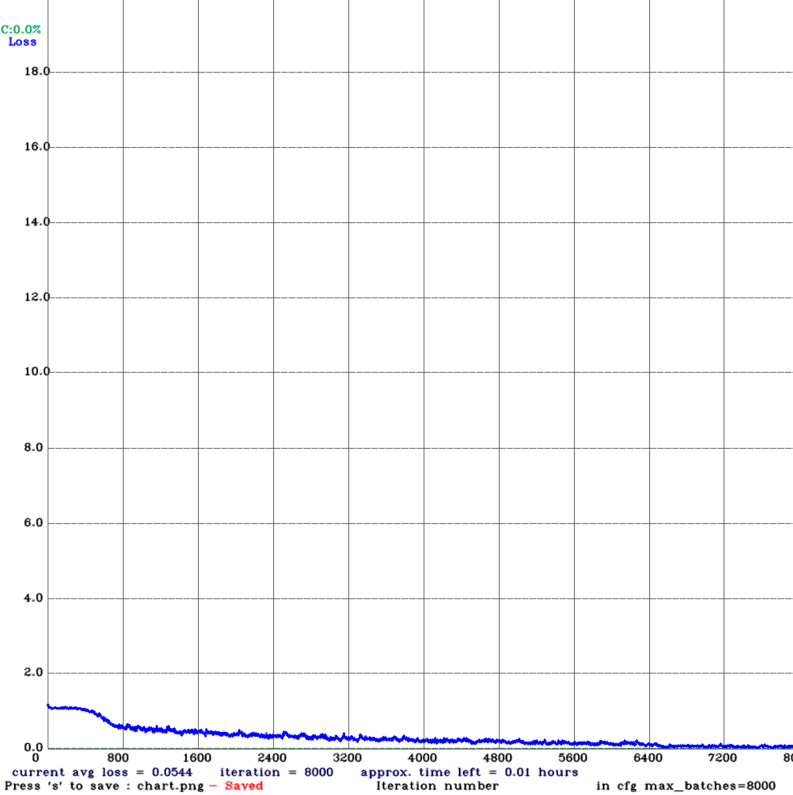
我这里loss下降到了0.05,识别的效果还可以
训练的时间不是很长,像我上面的配置训练时间在1个半小时以内
darknet classifier train支持中继训练(但不支持预训练模型),就是可以在之前训练好的weights文件基础上继续训练,命令为
- ./darknet classifier train [.data文件绝对路径] [.cfg文件绝对路径] [.weights文件路径]
训练完成后会在trained_models中出现模型文件

4 darknet命令预测
./darknet classifier predict [.data文件路径] [.cfg文件路径] [.weights文件路径] [预测图像路径]
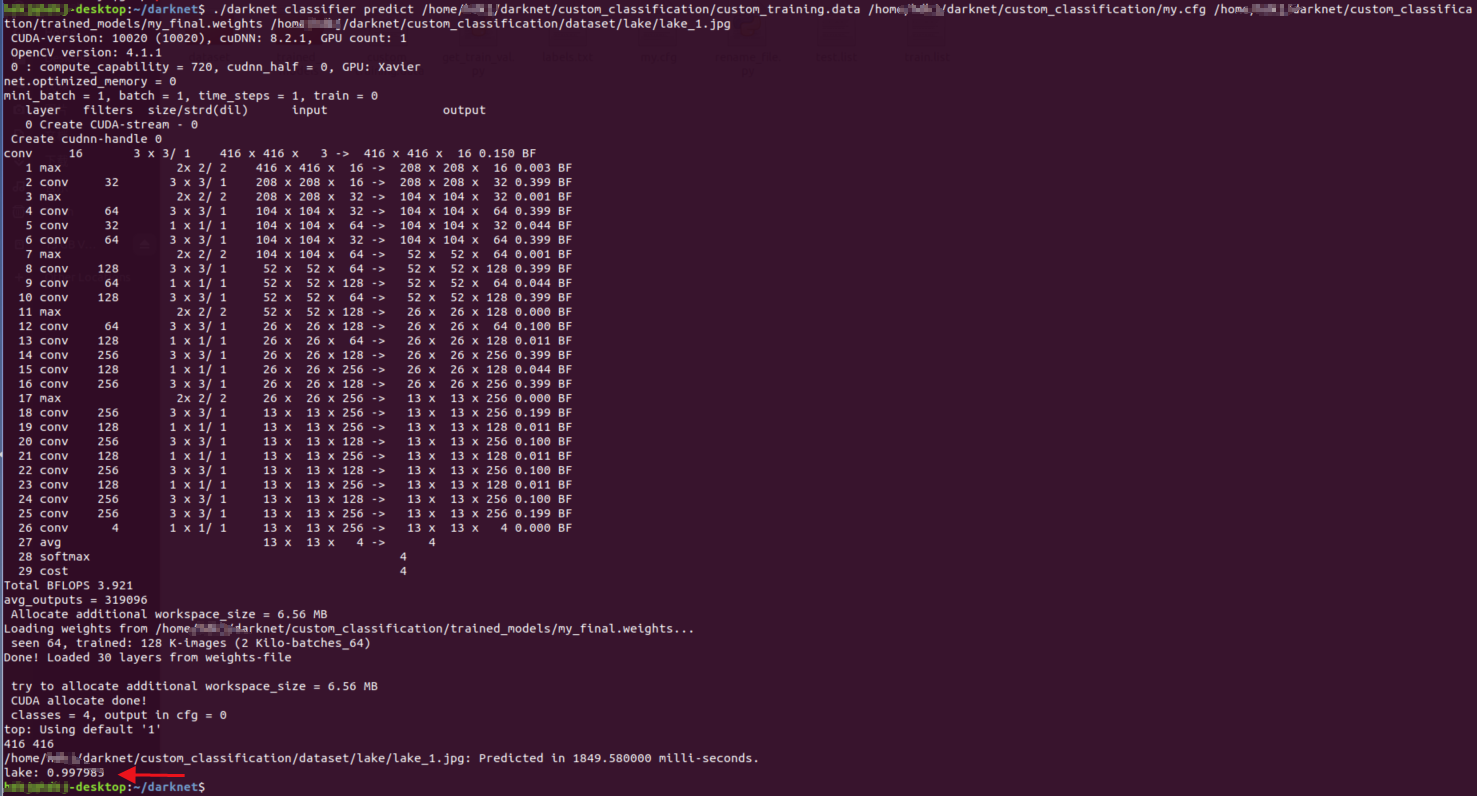
预测默认显示置信度最高的结果,如果你在.data文件中加入top这个键,比如写上top=5,那么就会显示置信度最高的前五个结果
由于我们只有4个标签,所以这里显示了4个

5 遇到的问题
5.1 获得了多组标签
参考 Too many or too few labels的问题解决_too few ')' or ']-优快云博客
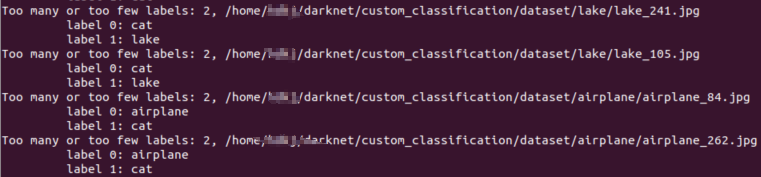
这个问题出现的很离奇,我最初想不明白所有的图像都出现了cat这个标签。网上查了查问题出在 custom_classification 上,custom_classification中包含cat,这就导致了每个图像都获取到了cat标签
现在我不想改变custom_classification这个名字,那么就只能改C代码,然后重新编译
找到src/data.c
添加 suyu_getFilename方法,然后在fill_truth与fill_truth_smooth中应用
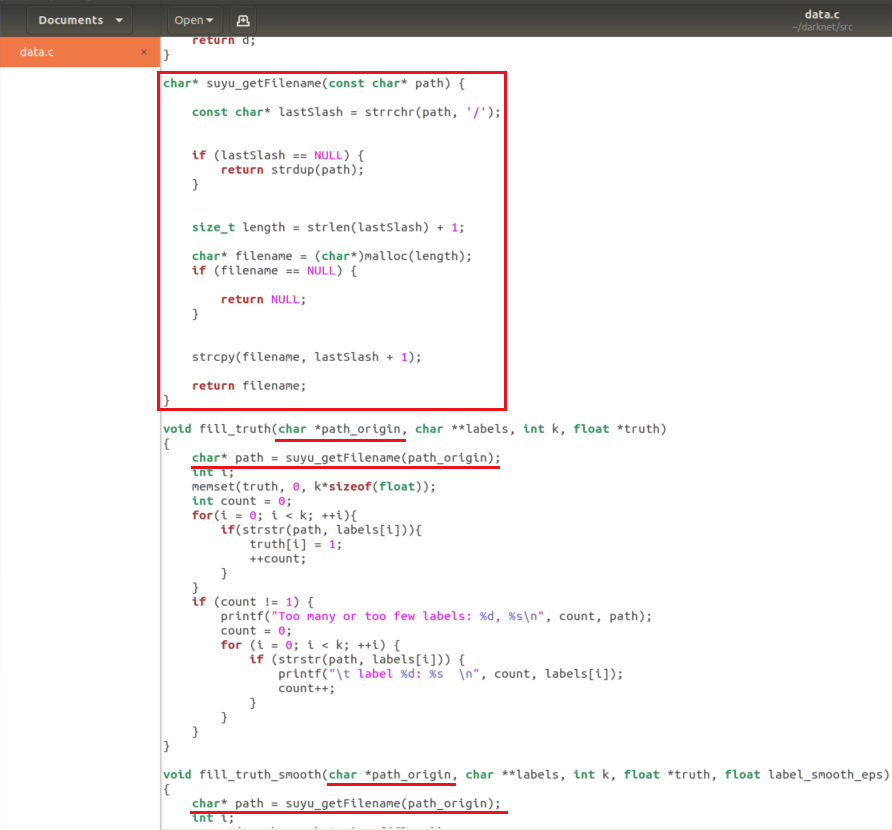
我们简单看一下path的变化,原来的path_origin是所有的绝对路径,目前的path只提取path_origin斜杠后的最后一部分
![]()


















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











