







生成对抗网络(GAN)的断点续训问题——savemodel的使用
1.问题简介
最近使用GAN做图像生成,发现有时候数据集大网络层数多时,训练需要很长时间,若是中途因为服务器问题或者人为问题意外停止训练,那么续训练这一操作则需要完成。因此参考了tf官网给出的几种方法对断点续训做出了实验,并完成了这一工作。
checkpoint的不可行性
最先想到的是checkpoint,但是checkpoint存在的问题是需要结合fit训练,而GAN需要两个或多个Model交替训练,fit显然不够合理,但fit的epochs设置为1时,每次都去保存检查点又拖慢网络进度,因此这里作者认为checkpoint不可行。
savemodel
因此作者去tf官网找到了其他保存模型的方式,选择了savemodel的方法。在开始train时,先检查有无保存的model,如果有就去下载并使用,没有则正常初始化开始训练。
在特定代码位置指定多少epoch保存一次model,完成续训
2.解决办法1
使用save +load_model
但存在版本不兼容问题
关键代码如下
if os.path.exists('G_model') and os.path.exists('D_model'):
print('-------------load the model-----------------')
self.discriminator = models.load_model('D_model') # 下载已有的模型及参数
self.generator = models.load_model('G_model')
···
···
if epoch % 1000 == 0:
self.generator.save('G_model')
self.discriminator.save('D_model')
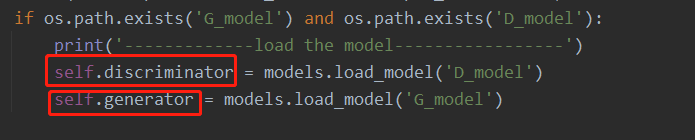
这里的红框内是判别器和鉴别器模型(Model)
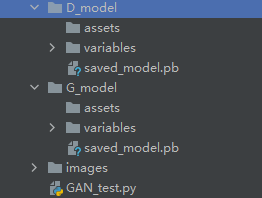
这是保存目录
全部代码如下
有关代码讲解文章最后有逐行讲解视频链接
from __future__ import print_function, division
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, ZeroPadding2D
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import models
import os
import matplotlib.pyplot as plt
import sys
import numpy as np
class GAN():
def __init__(self):
self.img_rows = 28 # 图片长
self.img_cols = 28 # 图片宽
self.channels = 1 # 通道数
self.img_shape = (self.img_rows, self.img_cols, self.channels) # 28*28*1
self.latent_dim = 784 # 生成器输入 噪声 100维
optimizer = Adam(0.0002, 0.5)
# 优化器
self.discriminator = self.build_discriminator() # 构建判别器
# 二进制交叉熵损失函数
# Adam优化器
# 用于训练判别器
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# y和y_都是数值 ‘accuracy’
# y_和y都是独热码(概率分布y)使用 ‘categorical_accuracy’
# y_是数值,y是独热码(概率分布)则使用 ‘sparse_categorical_accuracy’
# compile中写入损失函数和优化器
# 构建生成器
self.generator = self.build_generator()
# 以下用于训练生成器,此时不更新判别器参数
z = Input(shape=(self.latent_dim,)) # 按latent_dim个神经元的批次输入 接收输入
img = self.generator(z)
# 对于combined模型,我们只训练生成器
self.discriminator.trainable = False
# 鉴别器将生成的图像作为输入并确定有效性 validity
validity = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# 训练生成器骗过鉴别器
self.combined = Model(z, validity) # 叠加模型
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer) # 叠加模型
def build_generator(self):
model = Sequential() # 堆叠,通过叠加多层,构建深度神经网络。
# 一层全连接
# 输入100维度 批量为25的随机噪声
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary() # # 输出各层参数情况
noise = Input(shape=(self.latent_dim,)) # 接收输入
img = model(noise) # 生成图片
return Model(noise, img) # 返回输入为噪声 预测值为图片的Model模型给self.generator
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape)) # 将图片尺寸拉成1维
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img) # 输出概率
return Model(img, validity) # 由图像生成可能性的Model
def train(self, epochs, batch_size=128, sample_interval=50):
if os.path.exists('G_model') and os.path.exists('D_model'):
print('-------------load the model-----------------')
self.discriminator = models.load_model('D_model')
self.generator = models.load_model('G_model')
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# x_train.shape : 60000*28*28
# Rescale -1 to 1
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3) # x_train.shape : 60000*28*28*1 在第三维扩展1个维度
# 标签 batch_size行 每行一个标签
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size) # idx 是0到6w中的整数随机数组成的32个元素的一维数组
imgs = X_train[idx] # 32*28*28*1
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Generate a batch of new images
gen_imgs = self.generator.predict(noise) # 生成32张图像
# Train the discriminator , 输入batch个真实图片对应标签1和batch个虚假图片对应标签0 以此来训练判别器,第一次生成器还很弱 随着以后不断训练而变强
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# 噪声 32*100
# Train the generator (to have the discriminator label samples as valid)
g_loss = self.combined.train_on_batch(noise, valid)
# 对生成器+判别器两个叠加网络训练,只更新生成器参数来训练生成器,因为训练生成器的过程判别器只用于判别,不能更新判别器的参数
# 绘制进度图
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# 每二百轮保存一次
if epoch % sample_interval == 0:
self.sample_images(epoch)
if epoch % 1000 == 0:
self.generator.save('G_model')
self.discriminator.save('D_model')
# 保存图片
def sample_images(self, epoch):
r, c = 5, 5
# noise 二维 25*100 的张量
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# 25*28*28*1
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
# 将图像表示重新划分到0-1
fig, axs = plt.subplots(r, c) # plt.subplots()是一个函数,返回一个包含figure和 axes坐标 对象的元组。
# 因此,使用fig,ax = plt.subplots()将元组分解为fig和axs两个变量。
cnt = 0 # 定义一个计数器
for i in range(r):
for j in range(c): # 第一行第一列
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off') # 不显示坐标尺寸
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, sample_interval=200)
3.解决办法2
关键代码如下
if os.path.exists('saved_model/discriminator_weights.hdf5') and os.path.exists('saved_model/generator_weights.hdf5'):
self.discriminator.load_weights('saved_model/discriminator_weights.hdf5')
self.generator.load_weights('saved_model/generator_weights.hdf5')
print('-------------load the model-----------------')
···
···
def save_model(self):
def save(model, model_name):
model_path = "saved_model/%s.json" % model_name
weights_path = "saved_model/%s_weights.hdf5" % model_name
options = {"file_arch": model_path,
"file_weight": weights_path}
json_string = model.to_json()
open(options['file_arch'], 'w').write(json_string)
model.save_weights(options['file_weight'])
save(self.generator, "generator")
save(self.discriminator, "discriminator")
全部代码如下
from __future__ import print_function, division
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, ZeroPadding2D
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import models
import os
import matplotlib.pyplot as plt
import sys
import numpy as np
class GAN():
def __init__(self):
self.img_rows = 28 # 图片长
self.img_cols = 28 # 图片宽
self.channels = 1 # 通道数
self.img_shape = (self.img_rows, self.img_cols, self.channels) # 28*28*1
self.latent_dim = 784 # 生成器输入 噪声 100维
optimizer = Adam(0.0002, 0.5)
# 优化器
self.discriminator = self.build_discriminator() # 构建判别器
# 二进制交叉熵损失函数
# Adam优化器
# 用于训练判别器
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# y和y_都是数值 ‘accuracy’
# y_和y都是独热码(概率分布y)使用 ‘categorical_accuracy’
# y_是数值,y是独热码(概率分布)则使用 ‘sparse_categorical_accuracy’
# compile中写入损失函数和优化器
# 构建生成器
self.generator = self.build_generator()
# 以下用于训练生成器,此时不更新判别器参数
z = Input(shape=(self.latent_dim,)) # 按latent_dim个神经元的批次输入 接收输入
img = self.generator(z)
# 对于combined模型,我们只训练生成器
self.discriminator.trainable = False
# 鉴别器将生成的图像作为输入并确定有效性 validity
validity = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# 训练生成器骗过鉴别器
self.combined = Model(z, validity) # 叠加模型
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer) # 叠加模型
def build_generator(self):
model = Sequential() # 堆叠,通过叠加多层,构建深度神经网络。
# 一层全连接
# 输入100维度 批量为25的随机噪声
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary() # # 输出各层参数情况
noise = Input(shape=(self.latent_dim,)) # 接收输入
img = model(noise) # 生成图片
return Model(noise, img) # 返回输入为噪声 预测值为图片的Model模型给self.generator
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape)) # 将图片尺寸拉成1维
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img) # 输出概率
return Model(img, validity) # 由图像生成可能性的Model
def train(self, epochs, batch_size=128, sample_interval=50):
if os.path.exists('saved_model/discriminator_weights.hdf5') and os.path.exists(
'saved_model/generator_weights.hdf5'):
self.discriminator.load_weights('saved_model/discriminator_weights.hdf5')
self.generator.load_weights('saved_model/generator_weights.hdf5')
print('-------------load the model-----------------')
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# x_train.shape : 60000*28*28
# Rescale -1 to 1
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3) # x_train.shape : 60000*28*28*1 在第三维扩展1个维度
# 标签 batch_size行 每行一个标签
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size) # idx 是0到6w中的整数随机数组成的32个元素的一维数组
imgs = X_train[idx] # 32*28*28*1
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Generate a batch of new images
gen_imgs = self.generator.predict(noise) # 生成32张图像
# Train the discriminator , 输入batch个真实图片对应标签1和batch个虚假图片对应标签0 以此来训练判别器,第一次生成器还很弱 随着以后不断训练而变强
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# 噪声 32*100
# Train the generator (to have the discriminator label samples as valid)
g_loss = self.combined.train_on_batch(noise, valid)
# 对生成器+判别器两个叠加网络训练,只更新生成器参数来训练生成器,因为训练生成器的过程判别器只用于判别,不能更新判别器的参数
# 绘制进度图
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# 每二百轮保存一次
if epoch % sample_interval == 0:
self.sample_images(epoch)
if epoch % 1000 == 0:
self.save_model()
def save_model(self):
def save(model, model_name):
model_path = "saved_model/%s.json" % model_name
weights_path = "saved_model/%s_weights.hdf5" % model_name
options = {"file_arch": model_path,
"file_weight": weights_path}
json_string = model.to_json()
open(options['file_arch'], 'w').write(json_string)
model.save_weights(options['file_weight'])
save(self.generator, "generator")
save(self.discriminator, "discriminator")
# 保存图片
def sample_images(self, epoch):
r, c = 5, 5
# noise 二维 25*100 的张量
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# 25*28*28*1
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
# 将图像表示重新划分到0-1
fig, axs = plt.subplots(r, c) # plt.subplots()是一个函数,返回一个包含figure和 axes坐标 对象的元组。
# 因此,使用fig,ax = plt.subplots()将元组分解为fig和axs两个变量。
cnt = 0 # 定义一个计数器
for i in range(r):
for j in range(c): # 第一行第一列
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off') # 不显示坐标尺寸
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, sample_interval=200)
4.运行结果
在1000轮之后终止程序,重新训练,发现可以完成接续训练,实验可行。



















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











