






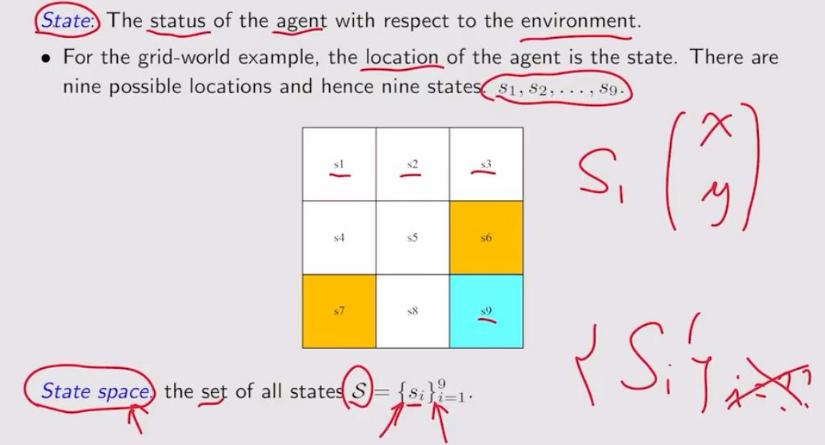
1. state:状态,可以是机器人的位置,速度,加速度等
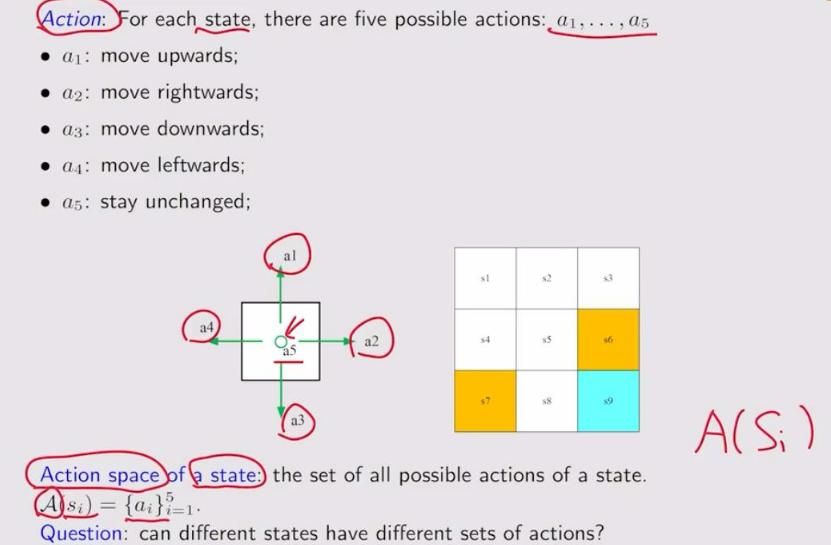
2. action:对于每一个状态,可能的动作
3. state transition:状态转移

3.1 state transition probability:

4. policy:告诉agent在这个状态应该采用哪个action

5. reward:状态转移后的惩罚项

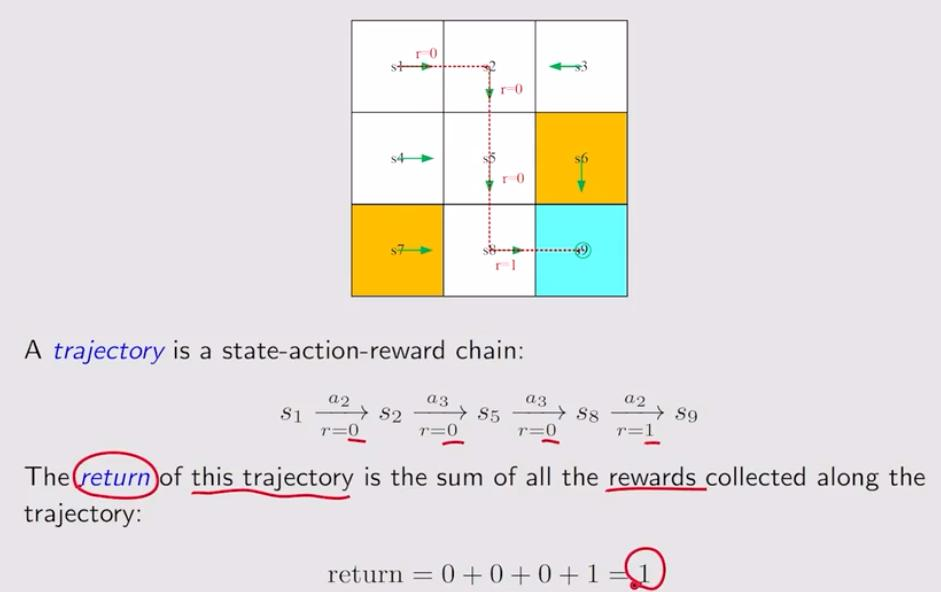
6. trajectory and return
- trajectory:从开始到结束的链路,包含了state,action,reward
- return:针对一个trajectory所有的reward之和
7. discounted return:
看上面的列子,因为有action5(原地不动的动作),所以到target后,可能会一直给a5的动作,导致reward一直为1,return为正无穷
解决方案,引入discounted return:
优点:
- 和变为有限
- 取值趋近于0,更关注眼前
- 取值趋近于1,更关注未来
通过调整discounted rate的值,可以调整学到的policy
8. Episode:有限状态,会有terminal states
- Episode一般是有限步骤,这个任务叫episodic tasks
- 有一些任务是无穷步骤,这个任务叫continuing tasks
- 时间很长的任务也可以定义为continuing tasks
8.1 把episodic转变为continuing tasks:
- 把target state认为是一种特殊的absorbing state
设置它的stage trasnsition probability的时候,如果当前state是target state,那就采取原地不动的action,并且reward = 0 - 把target state认为一种普通的状态,参与policy,reward可能一直是正,return会一直累加
9. Markov decision process(MDP) 框架



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









