




走向鲁棒的视觉问题回答: 通过对比学习,最大限度地利用有偏样本
提出问题:
视觉问答(VQA)模型通常依赖于虚假的相关性,即语言先验。使得其在分布外(OOD)测试数据面前表现不好。最近的方法通过减少偏倚样本对模型训练的影响,在克服这个问题方面取得了一些进展。但是,其在分布外(OOD)测试数据的改进严重牺牲了分布(ID)数据(由偏置样本主导)上的性能。
解决方法和创新点:
提出了一种新颖的对比学习方法,MMBS。它通过充分利用有偏样本来构建鲁棒的VQA模型。
具体来说,通过从原始训练样本中消除与语言先验相关的信息来构建用于对比学习的正样本,并探索出了几种策略来使用构建的正样本进行训练。这种方法没有破坏有偏样本在模型训练中的重要性,而是精确地利用有偏样本获得了有助于推理的无偏信息。
在分布外(OOD)测试数据集VQA- CP v2上的性能很有竞争力,同时在分布(ID)数据集VQA v2上保持了稳定的性能。
方法:
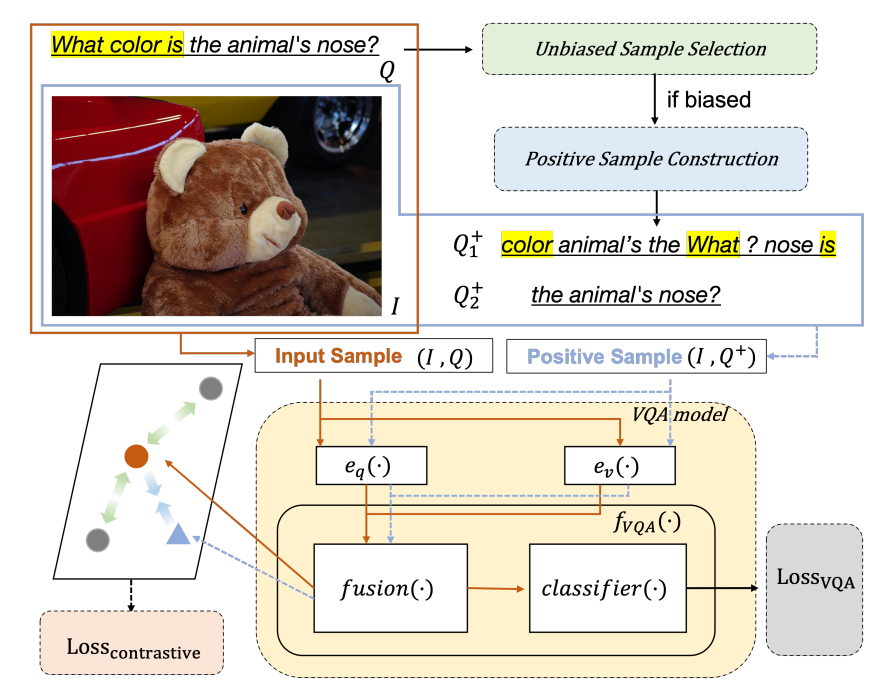
其中,问题类别词用黄色高亮显示。橙色圆圈和蓝色三角形表示原始样本和正样本的跨模态表示。同批次的其他样本为负样本,用灰色圆圈表示。
MMBS模型构造:(1)一个骨干VQA模型;
(2)一个正样本构建模块;
(3)一个无偏样本选择模块;
(4)对比学习目标。
1.骨干VQA模型
骨干VQA模型在MMBS中可以自由选择。大多数现有的VQA模型由四个部分组成:问题编码器eq(·)、图像编码器ev(·)、融合函数F(·)和分类器clf(·)。
训练目标:最小化多标签软损失Lvqa,可以形式化如下:
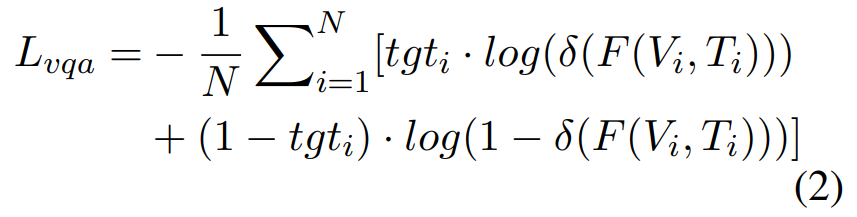
2.正样本构造
为了充分利用有偏样本中所包含的无偏信息,首先要构建排除有偏信息的正样本。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









