



 本文介绍了PyTorch库中张量的使用,包括其优势(如高效计算、GPU支持和与Python原生类型的不同),命名张量、存储视图、元数据管理(如转置和连续性)、以及与numpy的交互。重点强调了张量的内存效率和GPU操作的注意事项。
本文介绍了PyTorch库中张量的使用,包括其优势(如高效计算、GPU支持和与Python原生类型的不同),命名张量、存储视图、元数据管理(如转置和连续性)、以及与numpy的交互。重点强调了张量的内存效率和GPU操作的注意事项。
读书笔记 史蒂文斯
1 简介
torch是python的一个深度学习库,torch使用张量进行计算。
2 优势
张量和python基本类型不同,有如下优势
1 与其他py计算库衔接好
2 计算效率高,速度快
3 可使用gpu加速等
张量内存分布是连续的,类似C等数组内存分布;而py列表的元素实际是对对象的索引的连续内存分布,没有存对象本身。张量默认类型为float(float32)
3 命名张量
1.2以上版本pytorch加入了name特性,较新暂不看
想给一个张量添加新名字但不改变已有名字:tensor_new = tensor_old.refine_names(..., 'namea', 'nameb)
将不同维度张量进行对齐(改变张量的维度使两个张量维度相同):tensor_new = tensor_old.align_as(tensor_target)
4 存储视图
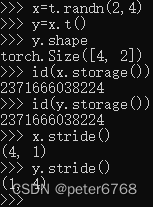
张量的值由torch.Storage实例分配到一片连续内存中,该连续内存为一维数组,即使张量为多维,但分配内存为一维数组,可通过tensor.storage()或tensor.untyped_storage()查看分配的内存数组
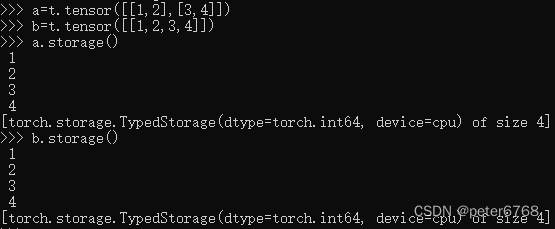
多个张量或不同维度但内容相同的向量,可索引同一片内存对应的张量,无需额外分配内存
tensor部分类型转化方法结尾加下划线表示原地操作
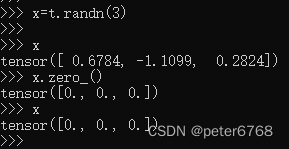
5 张量元数据
为在存储区建立索引,张量需要依赖一些元数据:大小、偏移量和步长,这些都是指针对张量的存储视图而言
大小:即张量的形状shape,是个元组
偏移量:张量中某个元素相对于第一个元素的偏移量。当查看张量切片的offset值,发现offset是相对于原张量的offset,也就是说,改变张量切片,也会改变原张量,可使用tensor.clone()方法复制张量
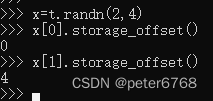
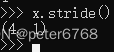
步长:在张量的某个维度中,在分布的连续内存上,移动到下一个值需要移动的offset值,是个元组
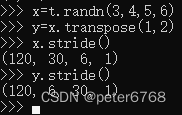
5.1 转置
转置也可在指定维度之间转置
5.2 连续张量
指维度为从低维到高维顺序排列的张量:
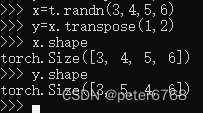
有的方法如果不是连续张量会报错

判断连续张量
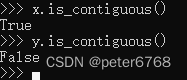
非连续张量是因为其索引顺序和存储区顺序不一致,使用contiguous方法可以重排张量对应的存储区顺序
6 gpu
pytorch支持cuda的gpu和AMD的ROCm
直接在gpu创建张量:t = torch.tensor([1, 2, 3], device='cuda')
用.to()方法将cpu的张量放到gpu上 t_gpu = t_cpu.to(device='cuda')或t_gpu = t_cpu.cuda()或device=torch.device('cuda'); t_gpu = t_cpu.to(device)
若存在多个gpu,可指定放哪个gpu: t_gpu = t_cpu.to(device='cuda:0')
gpu上的张量计算完不会移动到cpu上,如果进行cpu操作会报错,此时需要移动到cpu上,调t_gpu.cpu() 或 t_cpu = t_gpu.to(device='cpu')
7 与numpy交互
7.1 张量和numpy相互转化
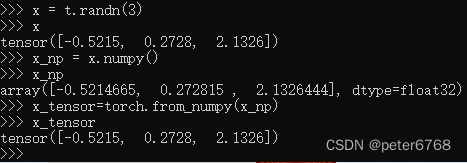
torch默认float32, numpy默认float64,np转化为tensor如果数据类型不一致会报错,需要转化为float32再操作
思考
1 为什么tensor用张量
张量相比py基本list,dict类型有优势,不是存的不是对象索引,而是对象本身,方便操作
2 tensor转置是否分配新内存
不会,只是tensor的元数据会改变,但内存用的是转置前张量分配的内存



















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









