







 本文是《机器学习实战》第三章的学习笔记,涵盖Mnist数据处理、交叉验证、混淆矩阵、精度评估以及多分类问题。讨论了如何使用交叉验证测量精度,解释了混淆矩阵、ROC曲线的概念,并对比了随机梯度下降和随机森林分类器。此外,还介绍了多类别分类、错误分析、多标签分类和多输出分类的实现。
本文是《机器学习实战》第三章的学习笔记,涵盖Mnist数据处理、交叉验证、混淆矩阵、精度评估以及多分类问题。讨论了如何使用交叉验证测量精度,解释了混淆矩阵、ROC曲线的概念,并对比了随机梯度下降和随机森林分类器。此外,还介绍了多类别分类、错误分析、多标签分类和多输出分类的实现。
机器学习实战 书籍第三章例子学习笔记
书中源码,here
本文地址,here
要分为Mnist数据处理、交叉验证、混淆矩阵、精度、多分类问题等。
加载数据 可以从本地下载
fetch_mldata下载较慢,可以下载到本地
链接:https://pan.baidu.com/s/1fAInuofJ_MJJfvNjY1djsg
提取码:e462
在当前工程目录下新建并拷贝自己下载文件
datasets/mldata/mnist-original.mat
其实从fetch_mldata源码里看到 是从这个目录下加载。
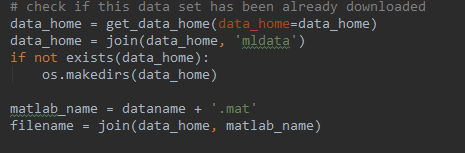
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original',data_home='./datasets')
X, y = mnist["data"], mnist["target"]
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
some_digit = X[36000]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap=plt.get_cmap("binary"), interpolation="nearest")
plt.axis("off")
plt.show()

X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
#打乱数据
import numpy as np
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
训练一个二分类器
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42, max_iter=5, tol=None)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([some_digit])
性能考核
使用交叉验证测量精度
自定义分组
分成3组 每次取一组作为验证 总共三个输出
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pre = clone_clf.predict(X_test_fold)
n_correct = sum(y_pre == y_test_fold)
print(n_correct / len(y_pre))
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
Never5Classifier这里返回全false 判断输入是非5 也就是输入任何数据准确率都可以达到90%
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









