



本文仅作学习记录,文中内容大部分来源于参考学习链接,如有侵权速删~
一、R-CNN
论文网址:[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation
参考学习链接: 深度学习之目标检测R-CNN模型算法流程详解说明(超详细理论篇)_rcnn-优快云博客
R-CNN:Region-based Convolutional Neural Networks
RCNN的创新之处在于将深度学习引入目标检测的各个阶段。通过使用CNN提取特征,RCNN能够学习到更具有判别性的特征表示,从而提高了目标检测的准确性。此外,RCNN还引入了候选区域的生成机制,避免了对整个图像进行密集的滑动窗口搜索,从而大大提高了算法的效率。
RCNN的改进算法,如Fast R-CNN、Faster R-CNN和Mask R-CNN等。
RCNN的核心思想是将目标检测问题转化为一系列的候选区域(region proposal)的分类问题。首先,它使用一个基于选择性搜索(Selective Search)的方法生成一组可能包含目标的候选区域。然后,对每个候选区域,RCNN通过在该区域上进行前向传播来提取固定长度的特征向量。这些特征向量随后被输入到一个独立的SVM分类器中,以判断该区域是否包含目标,同时还有一个边界框回归器用于精确定位目标的位置。

2、Selective Search
Hierarchical Grouping Algorithm
图像中区域特征比像素更具代表性,作者使用Felzenszwalb and Huttenlocher的方法产生图像初始区域,使用贪心算法对区域进行迭代分组:
- 计算所有邻近区域之间的相似性;
- 两个最相似的区域被组合在一起;
- 计算合并区域和相邻区域的相似度;
- 重复2、3过程,直到整个图像变为一个地区。
3、Compute CNN features
由于卷积神经网络中包含了全连接层,因此在输入后续卷积神经网络之前需要先将候选区域缩放到统一大小,论文中采用的是227×227。
至于候选区域的缩放方法,论文的补充材料部分中一共讨论了若干种缩放方法:
- 各向异性缩放:不管图像形状尺寸,直接将图像缩放至指定大小。
- 各向同性缩放:将候选区域进行扩充至正方形,随后进行缩放裁剪,如果扩充至图像边缘,直接用均值进行填充;直接裁剪候选区域之后用均值将其填充至指定大小。
将2000候选区域缩放到227x227pixel,接着将候选区域输入事先训练好的AlexNet CNN网络获取4096维的特征得到2000×4096维矩阵。
4、Classify regions
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
非极大值抑制剔除重叠建议框:
重叠度(IOU):衡量bounding box的定位精度。
5、微调区域位置
RCNN使用线性回归器对位置进行微调微调,得到更加准确的边界框,对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
二、Fast R-CNN
论文网址:https://arxiv.org/pdf/1504.08083
参考学习链接:深度学习之目标检测Fast-RCNN模型算法流程详解说明(超详细理论篇)_fast rcnn 的目标检测流程-优快云博客
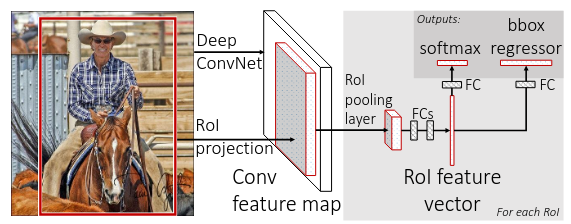
算法流程:
- 输入图像;
- 通过深度网络中的卷积层(VGG、Alexnet、Resnet等中的卷积层)对图像进行特征提取,得到图片的特征图;
- 通过选择性搜索算法得到图像的感兴趣区域(通常取2000个);
- 对得到的感兴趣区域进行ROI pooling(感兴趣区域池化):即通过坐标投影的方法,在特征图上得到输入图像中的感兴趣区域对应的特征区域,并对该区域进行最大值池化,这样就得到了感兴趣区域的特征,并且统一了特征大小,如图2所示;
- 对ROI pooling层的输出(即感兴趣区域对应的特征图最大值池化后的特征)作为每个感兴趣区域的特征向量;
- 将感兴趣区域的特征向量与全连接层相连,并定义了多任务损失函数,分别与softmax分类器和boxbounding回归器相连,分别得到当前感兴趣区域的类别及坐标包围框;
- 对所有得到的包围框进行非极大值抑制(NMS),得到最终的检测结果。
ROI Pooling(Region of Interest)
它的输入是特征图,输出则是大小固定的channel x H x W的vector。ROI Pooling是将一个个大小不同的region proposals,映射成大小固定的(W x H)的矩形框。它的作用是根据region proposals的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和输出回归框操作。它可以加速处理速度。
ROI Pooling有两个输入,一个是图片进入CNN后的特征图,另一个是区域的边框。ROI 的输出是一个region_nums x channels x W x H的向量。
RoI可以看成是SPP的简化版本,原版SPP是多尺度池化后进行concat组成新特征,而RoI只使用一个尺度,可以将任意维度的特征矩阵缩放成固定维度。论文中的具体做法是,把高和宽都平均分为7*7的小块,然后在每一个小块做max pooling操作,channel维度不变,这样做能使输出维度固定,同时RoI Pooling不是多尺度的池化,梯度回传非常方便,为fine-tune卷积层提供了条件。(SPP Net不能fine-tune卷积层)
三、Faster R-CNN
论文网址:https://arxiv.org/pdf/1506.01497
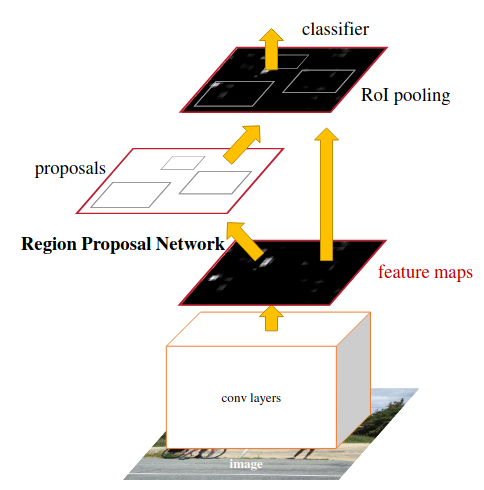
这篇写的好详细:
https://zhuanlan.zhihu.com/p/31426458
一文读懂Faster RCNN(大白话,超详细解析)-优快云博客
主要创新:提出了区域提议网络(RPN)!!!
- 在Faster RCNN中,输入图像通过 CNN。这些特征图将用于区域提议网络(RPN)以生成区域提议,并用于生成特征图以用于稍后的 RoI 池化。
- 不再使用SS。 因此,整个网络是一个端到端的深度学习网络,对于梯度传播提高目标检测精度至关重要。
- 与Fast RCNN类似,对于每个 region proposal,RoI pooling 都在proposal 上进行,最后通过网络,即全连接层。最后,输出分类和边界框。
四、Mask R-CNN 实例分割
论文网址:https://arxiv.org/pdf/1703.06870
参考学习链接:Mask RCNN 超详细图文入门(含代码+原文)_mask rcnn代码-优快云博客
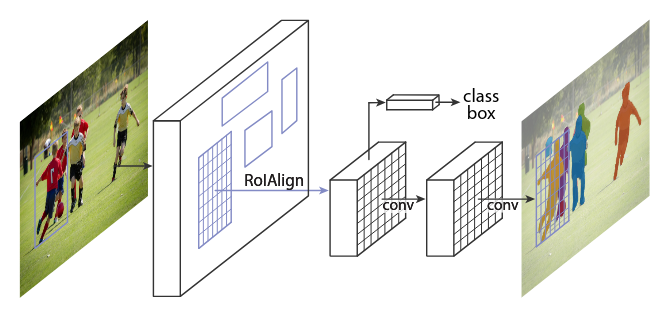
Mask RCNN,架构非常接近Faster RCNN。主要区别在于,在网络的末端,还有另一个头,即上图中的掩码分支,用于生成掩码进行实例分割。还有把Faster RCNN中的ROI Pooling换成了ROIAlign。
先写到这吧,本来是想着重写Faster R-CNN的,希望有时间补上~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









