




 本文探讨了神经网络参数更新策略,包括梯度下降、反向传播原理及计算图的应用。介绍了正则化、向量化和参数初始化等技巧,以及SGD、Adam优化器的选择和学习率调整方法。
本文探讨了神经网络参数更新策略,包括梯度下降、反向传播原理及计算图的应用。介绍了正则化、向量化和参数初始化等技巧,以及SGD、Adam优化器的选择和学习率调整方法。
本文为笔者学习CS224N所做笔记,所包含内容不限于课程课件和讲义,还包括笔者对机器学习、神经网络的一些理解。所写内容难免有难以理解的地方,甚至可能有错误。如您在阅读中有疑惑或者建议,还望留言指正。笔者不胜感激!
在本章中,将着重讨论以下内容:
- 如何更新神经网络参数?
- 以何种形式保存更新结构?
- 搭建和训练神经网络的技巧.
梯度和导数
上一章提到,应该最小化损失函数。损失函数的参数是神经网络参数,由于梯度的方向是函数上升最快的方向,故若想最小化损失函数,应该按负梯度方向更新参数,即梯度下降。而为了求解损失函数对参数的梯度,就涉及到了微分的问题。
梯度计算
对于上一章提出的简单的神经网络分类器,有如下的形式:
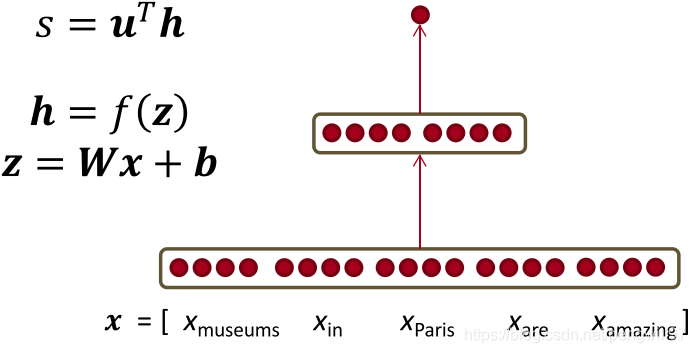
现在计算 ∂ s ∂ W \frac{\partial s}{\partial W} ∂W∂s,根据链式法则,有
∂ s ∂ W = ∂ s ∂ h ⋅ ∂ h ∂ z ⋅ ∂ z ∂ W \frac{\partial s}{\partial W}=\frac{\partial s}{\partial h}·\frac{\partial h}{\partial z}·\frac{\partial z}{\partial W} ∂W∂s=∂h∂s⋅∂z∂h⋅∂W∂z
此处 s , W , h , z s,W,h,z s,W,h,z均为矩阵或者向量的形式,涉及到矩阵求导,较为繁琐。为了简单清楚的阐述其原理,我们求对于 W W W中某个特定元素的求导规则,即计算 ∂ s ∂ W i j \frac{\partial s}{\partial W_{ij}} ∂Wij∂s。同时,我们神经网络用图的方式更加详细的表示出来。
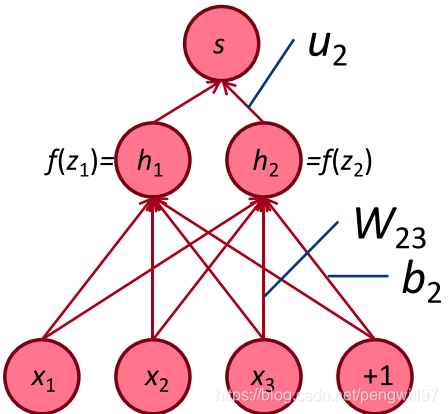
再做一个简化,令 ∂ s ∂ W \frac{\partial s}{\partial W} ∂W∂s链式法则展开的前两项为 δ \delta δ,关注 ∂ z ∂ W \frac{\partial z}{\partial W} ∂W∂z,即
∂ s ∂ W = δ ∂ z ∂ W = δ ∂ ∂ W W x + b \frac{\partial s}{\partial W}=\delta\frac{\partial z}{\partial W}=\delta \frac{\partial}{\partial W}Wx+b ∂<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









