







文章目录
前言
唉研二了,学习cs224n,记录笔记。 b站观看链接
听了一节课发现听不进去,先看PPT了解一下再说吧,打算对部分模块进行单独学习。
一、Word2vec(1.2)
00在传统的自然语言处理中将单词表示为离散的符号——这是一种本地化的表示。即one-hot 表示
两个向量(hotel 和·motel)是正交的。对于一个热向量来说,没有相似性的自然概念!
11分布语义学:一个词的意义是由经常出现在附近的词给出的
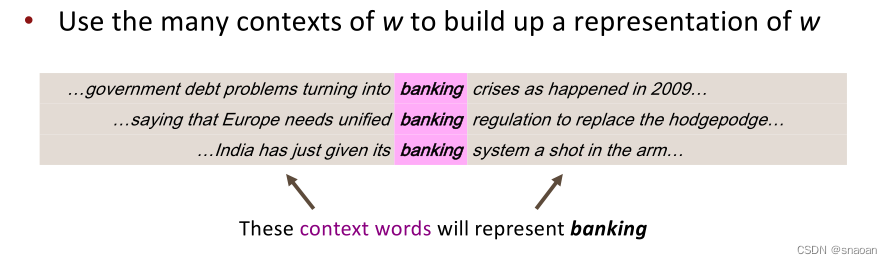 单词向量也称为单词Embedding或(神经)单词表示—(相似上下文的单词的vector应该相似)—,它们是一种分布式表示
单词向量也称为单词Embedding或(神经)单词表示—(相似上下文的单词的vector应该相似)—,它们是一种分布式表示

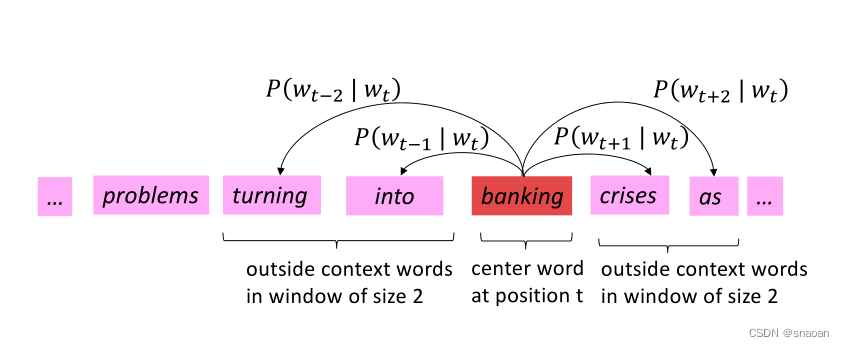
word2vec的原理——根据单词的上下文去预测单词出现,然后让整体的概率最大化。学习这样一个神经网络,然后选择隐藏作为vector表示。
因为Word2Vec的最终目的不是为了得到一个语言模型,也不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物:词向量矩阵。
Word2vec 最有价值的是让不带语义信息的词带上了语义信息,其次把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
目标函数
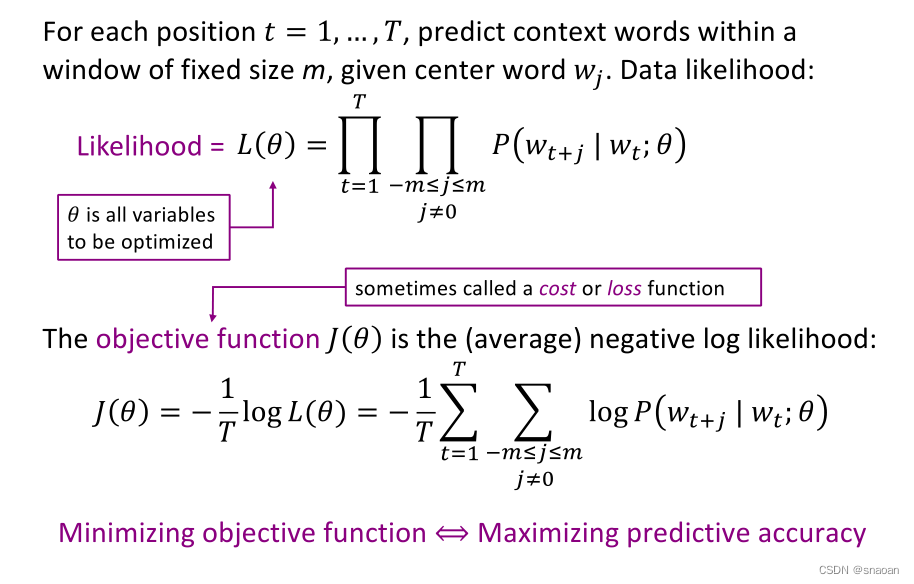 一般我们是最小化目标函数,所以进行了取log和负平均的操作。
一般我们是最小化目标函数,所以进行了取log和负平均的操作。
如何求最小化的J(θ)??
为了求出上面损失函数最里面的概率 P 对每个单词都用2个vector表示:
当w是中心词时,表示为Vw
当w是上下文词时,表示为 Uw
这样更容易optimization。
预测函数和激活函数
预测函数中中心词生成背景词的概率可以使用 softmax 函数进行定义
 分子的点积用来表示o和c之间相似程度
分子的点积用来表示o和c之间相似程度
分母基于整个词表,给出归一化后的概率分布。
SGD
随机梯度下降法(SGD)是一类近似求梯度的方法,每次使用小部分样本甚至只使用一个样本来求梯度进行参数更新。
随机选择几个样本而不是每次迭代整个数据集。
”batch”,数据集中用于计算梯度每次迭代的样本数。
glove
语料库中单词出现的统计(共现矩阵)是学习词向量表示的无监督学习算法的重要资料。
 Glove模型目标:词的向量化表示,使得向量之间尽可能多蕴含语义和语法信息。
Glove模型目标:词的向量化表示,使得向量之间尽可能多蕴含语义和语法信息。
方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
词向量评估
 skip-gram、CBOW每次都是用一个窗口中的信息更新出词向量
skip-gram、CBOW每次都是用一个窗口中的信息更新出词向量
Glove则是用了全局的信息(共线矩阵),也就是多个窗口进行更新
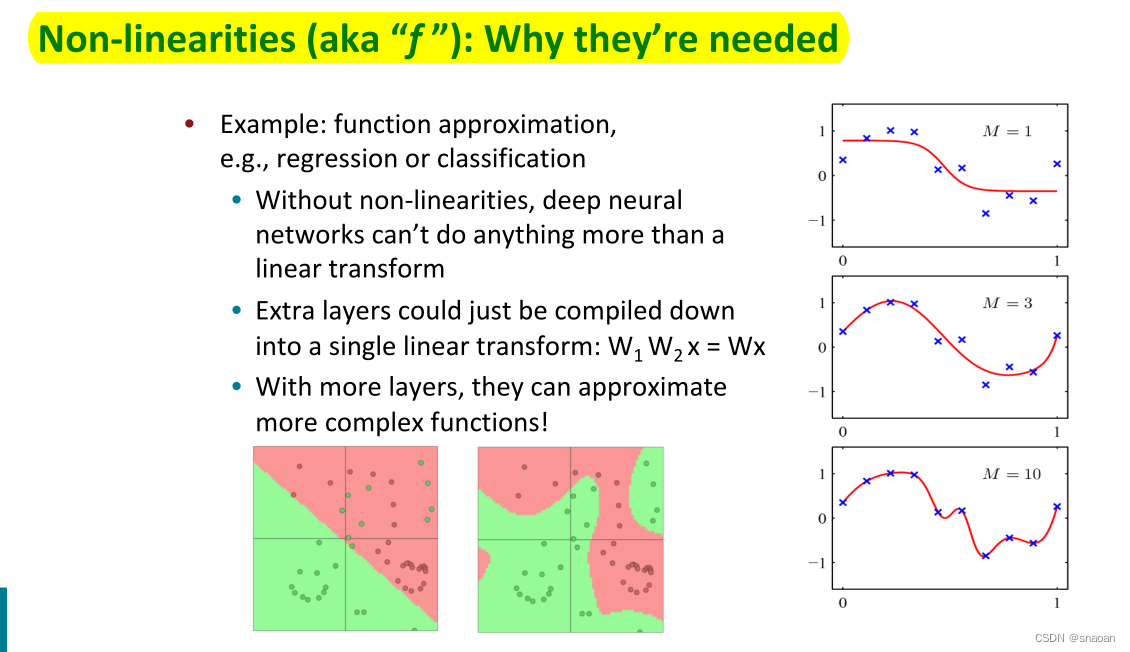
神经网络
是一种计算模型,由大量的节点(或神经元)直接相互关联而构成
二、神经网络(3)

梯度:
雅可比矩阵梯度:

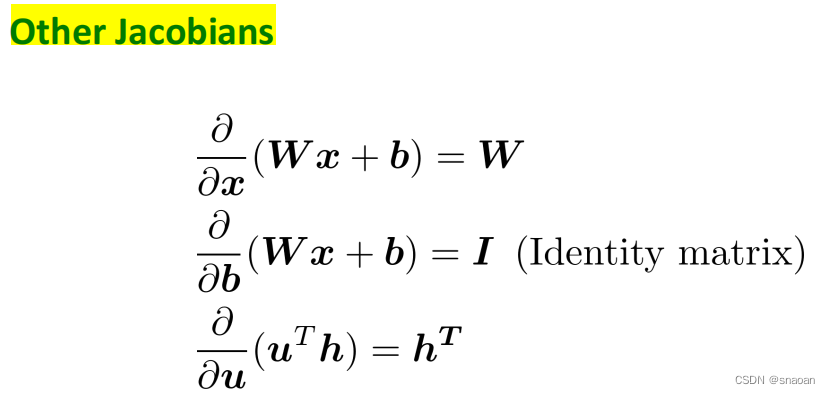

神经网络:
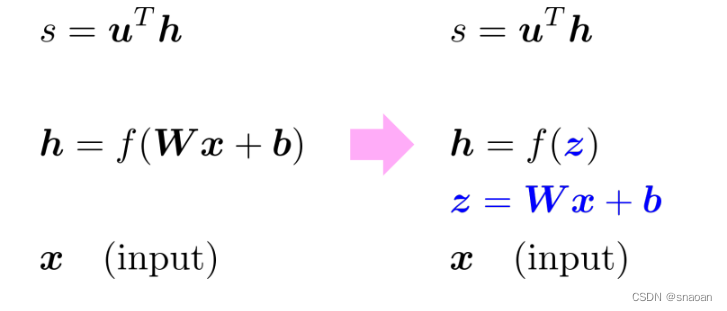


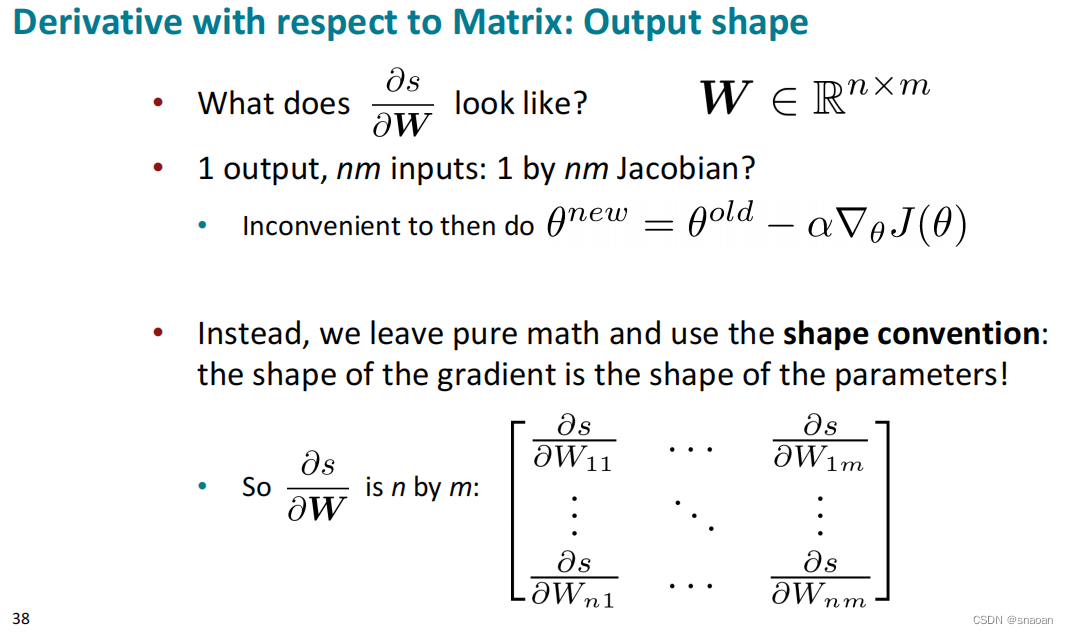

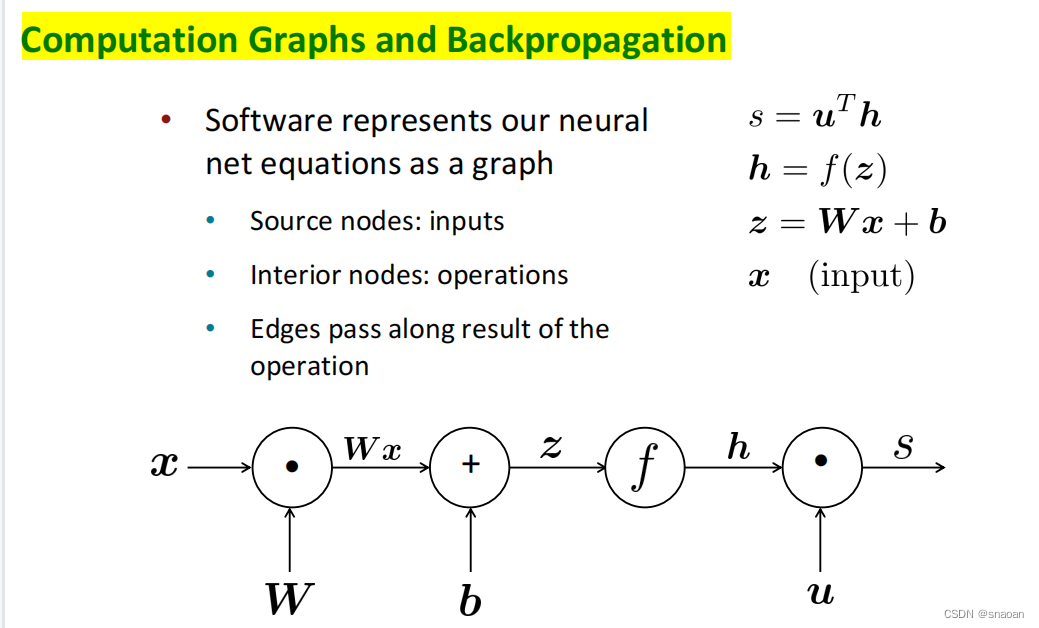
前向传播和后向传播:
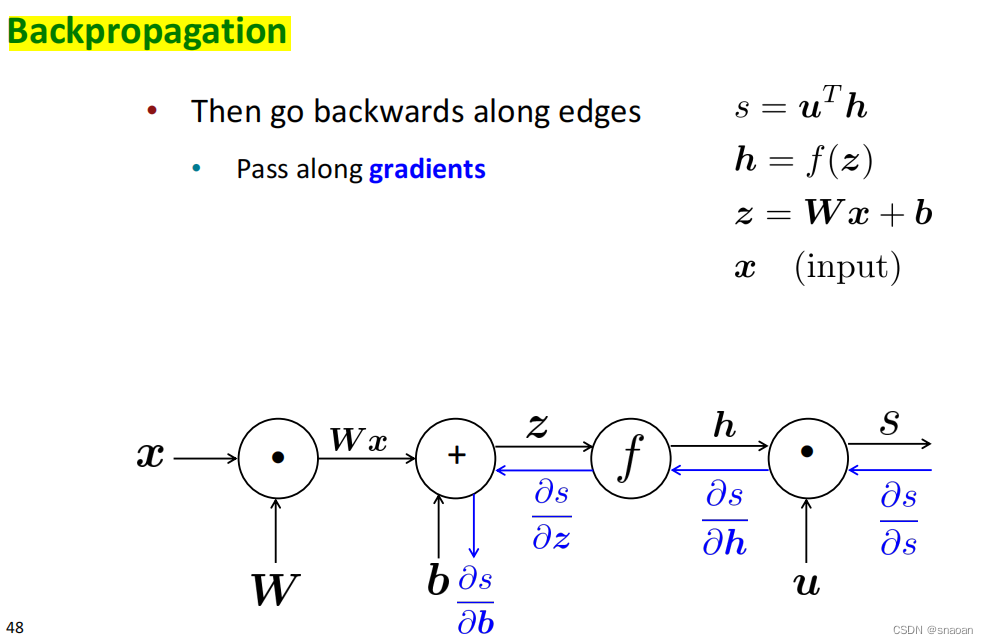
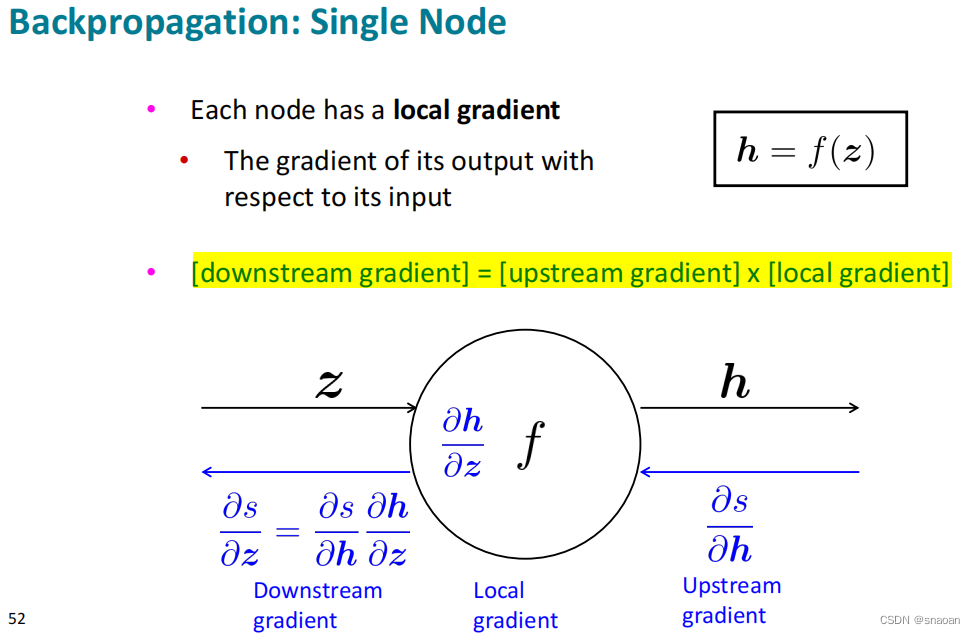
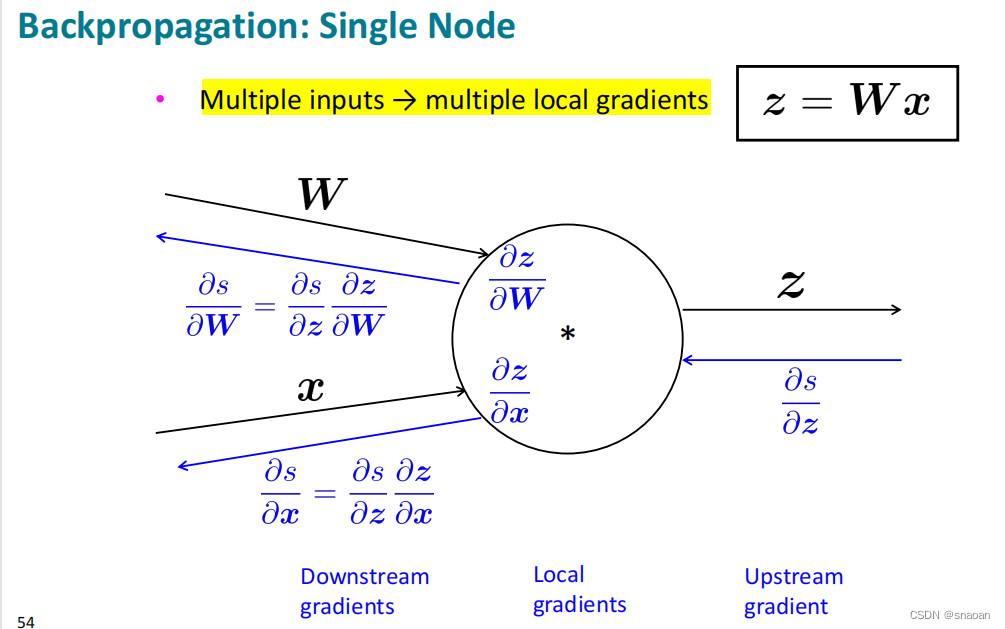
三、Dependency Parsing 依存句法分析(4)
句法分析(Syntactic Parsing),两种典型的句法结构表示:
(1)短语结构句法:依托上下文无关文法,S代表起始符号,如NP和VP分别表示名词短语和动词短语。
(2)依存结构句法:依托依存文法,如sub和obj分别表示主语和宾语,root表示虚拟根节点,其指向整个句子的核心谓词。
句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。依存句法分析属于浅层句法分析。
依存分析一般有两个视角:
(1)组成关系(Consistency):Constituency Grammar。使用短语结构语法将单词放入嵌套的组件中。

(2)依赖关系(Dependency):Dependency Parsing。句子的从属结构显示哪些词依赖于(修饰或是)哪些词。这些单词之间的二元非对称关系称为依赖关系,并被描述为从head到dependent。通常这些依赖关系形成一个树结构。经常用语法关系的名称进行分类(主语,介词宾语,同位语等)。有时会将假根节点作为head添加到树中,所以每个单词都依赖于一个节点。
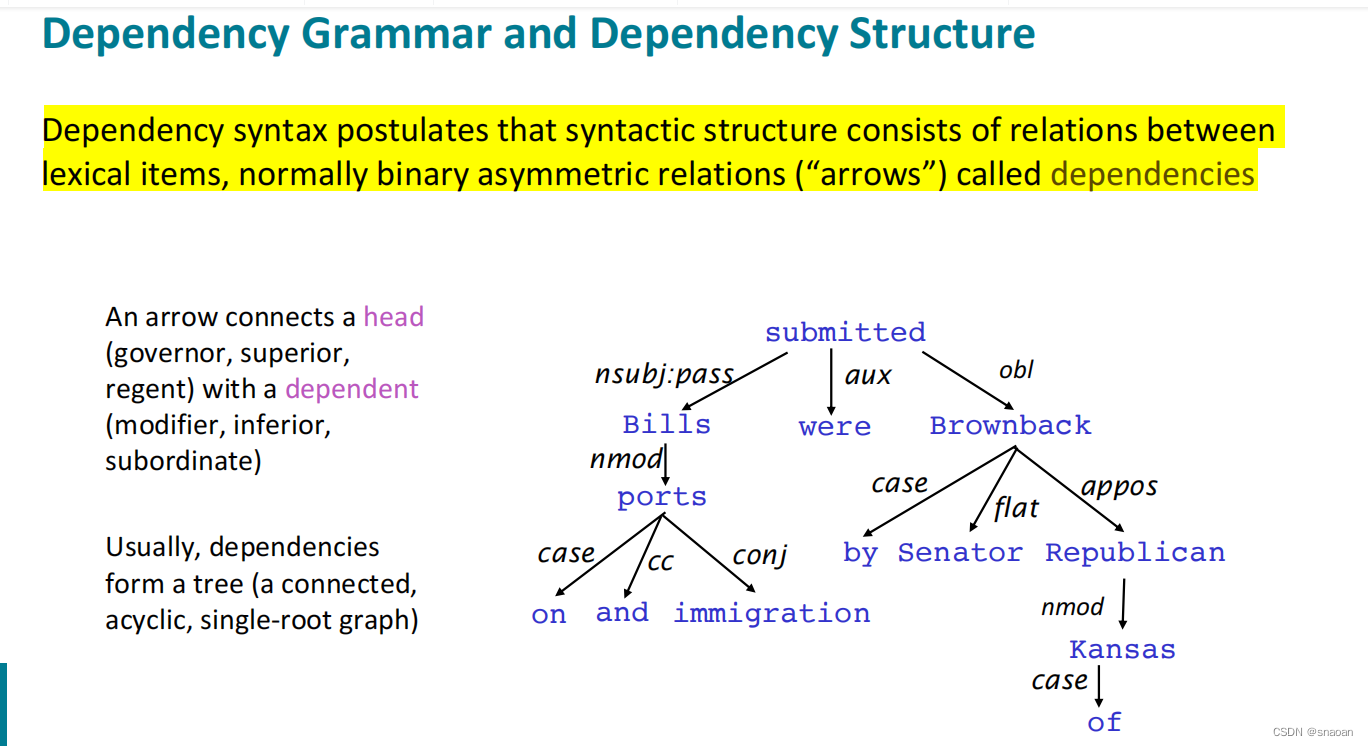
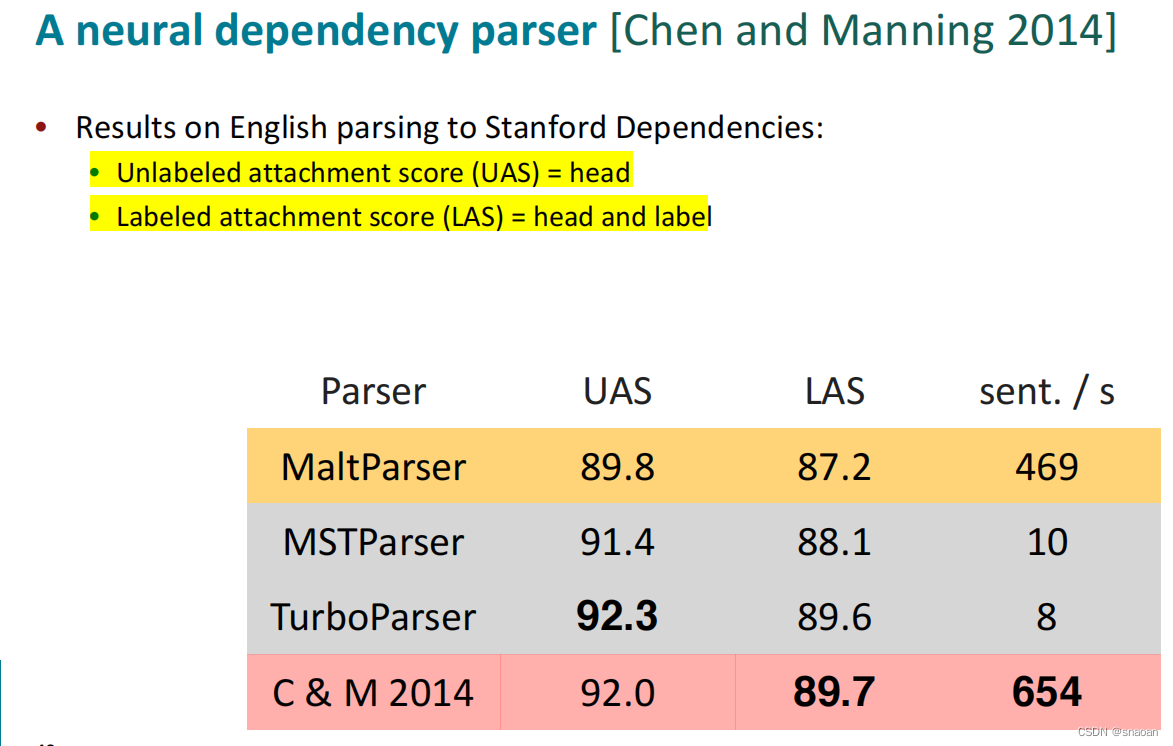
依存分析的评价
UAS (unlabeled attachment score) 指 无标记依存正确率 ,不考虑依存关系的类型,只考虑依存关系的对应单词是否正确,如父节点被正确识别的准确率;
LAS (labeled attachment score) 指有标记依存正确率,同时考虑依存关系的对应单词以及依存关系类型,即词的父节点,以及与父节点的句法关系都被正确识别的概率。
ps:
四、语言模型和RNN(5)
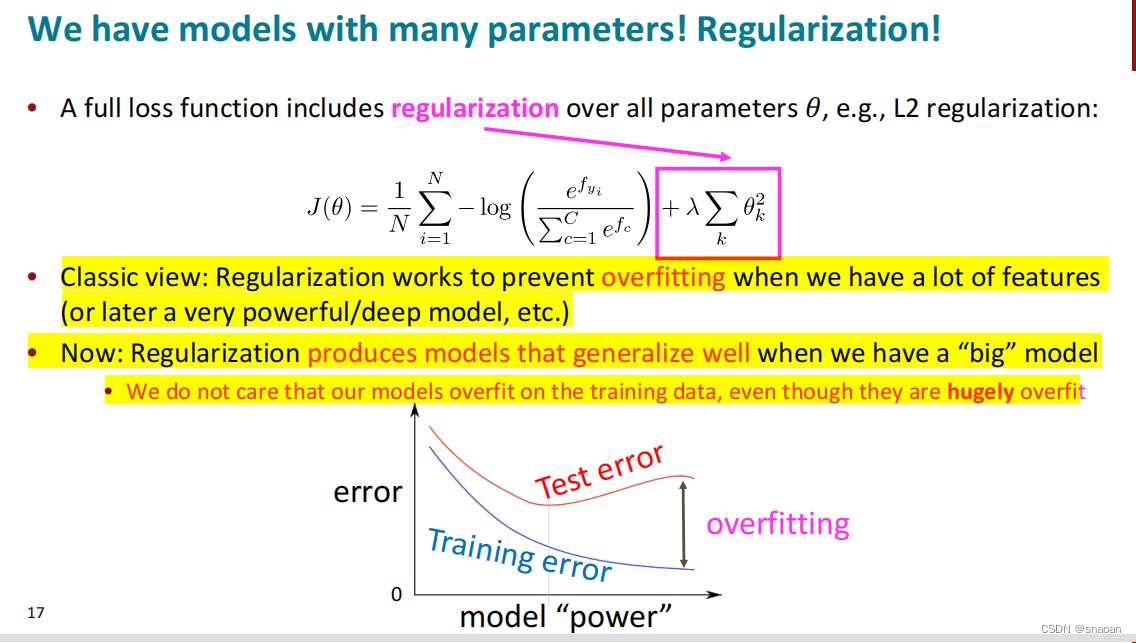
如果特征很多,为了防止过拟合,可以对损失函数加上正则化
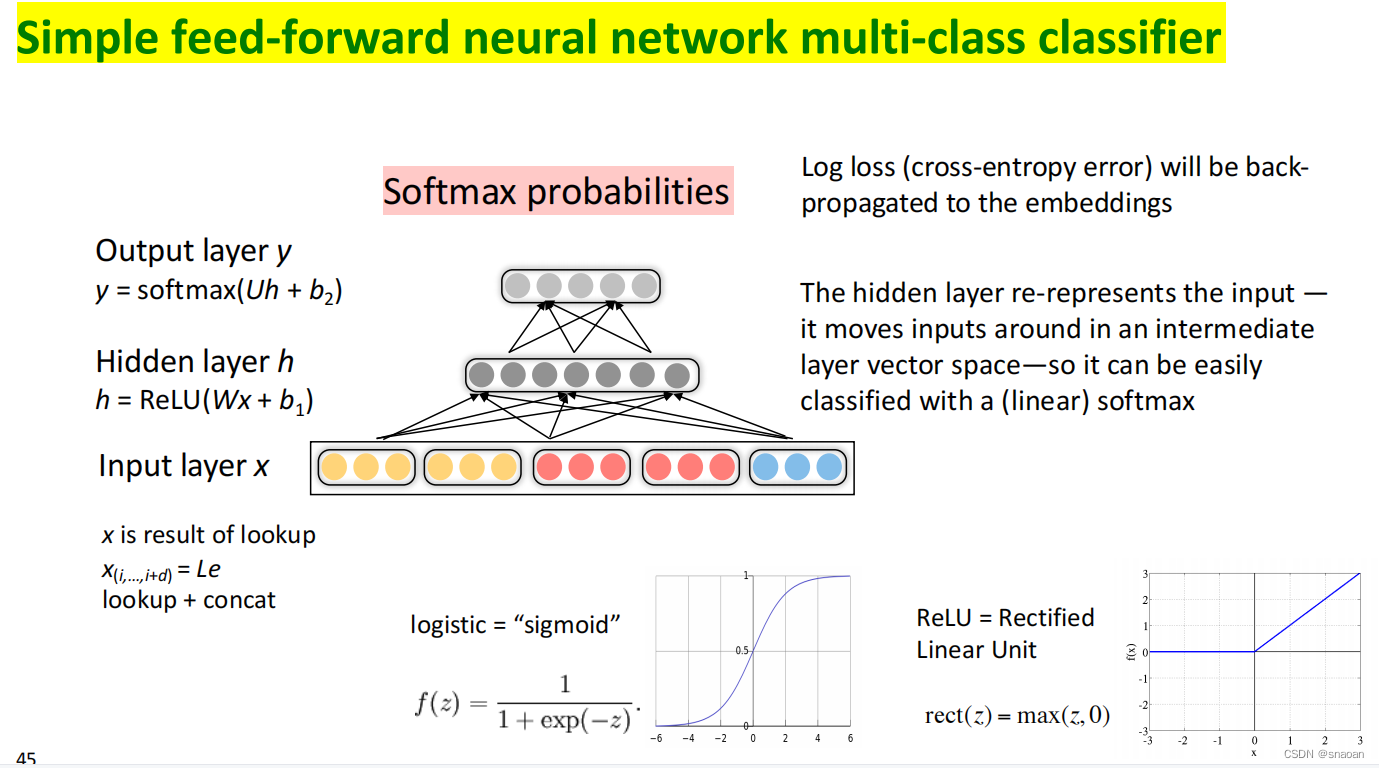
常见激活函数

语言建模的任务:预测下一个单词是什么。

马尔科夫假设

n-gram模型的稀疏问题(解决:平滑加后退)、存储问题


基于窗口的神经网络语言模型,也可用于命名实体识别
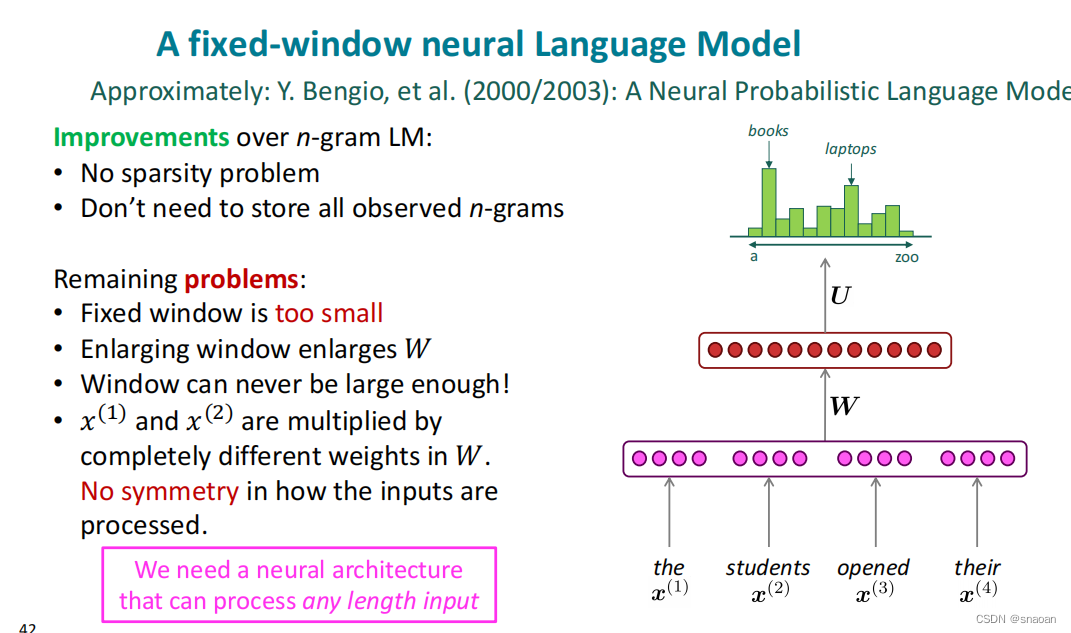
改进:没有稀疏性问题;不需要观察到所有的n-grams
问题:固定窗口太小,即使窗口再大也可能不够、扩大窗口就需要扩大权重矩阵W 、
乘以完全不同的权重、输入的处理不对称
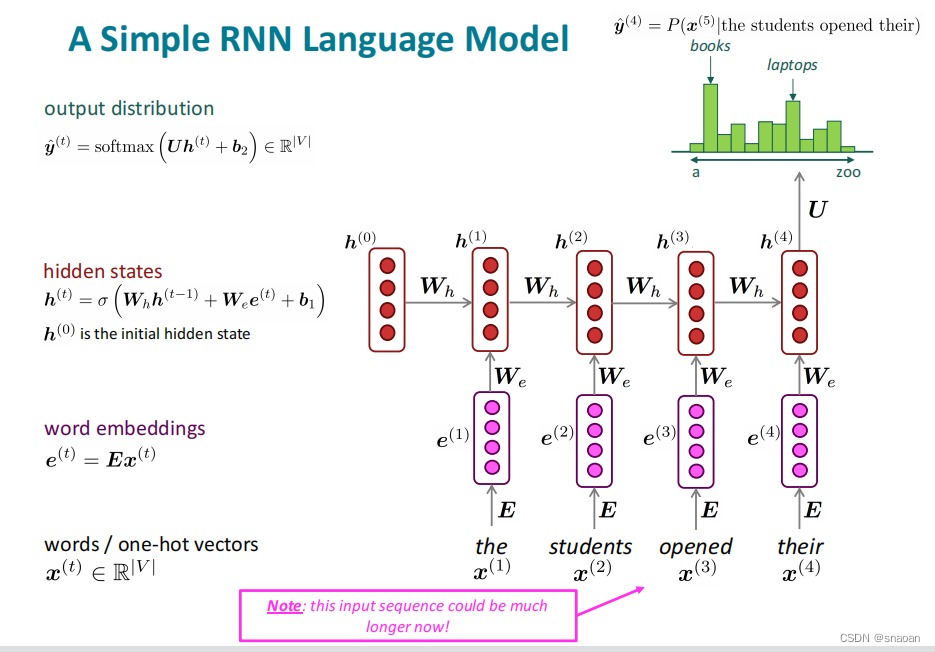 优势:可以处理任意长度的input
优势:可以处理任意长度的input
步骤 t 的计算可以使用来自之前所有步骤的信息,而不仅是一个窗口
模型大小不会 随着输入的增加而增加
在每个时间步上应用相同的权重,因此在处理输入时具有对称性
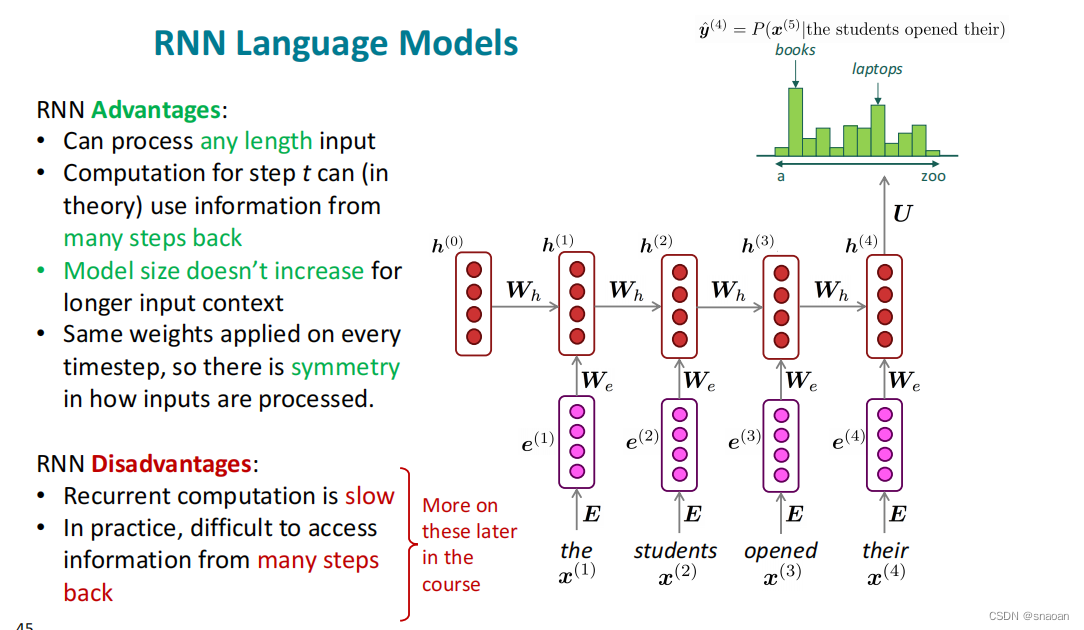
劣势:RNN计算速度慢。每个时间 t 的计算都要先计算之前的序列,即不能并行计算多个时间步。
很难从许多步骤中获取信息,因为存在梯度消失和爆炸问题。
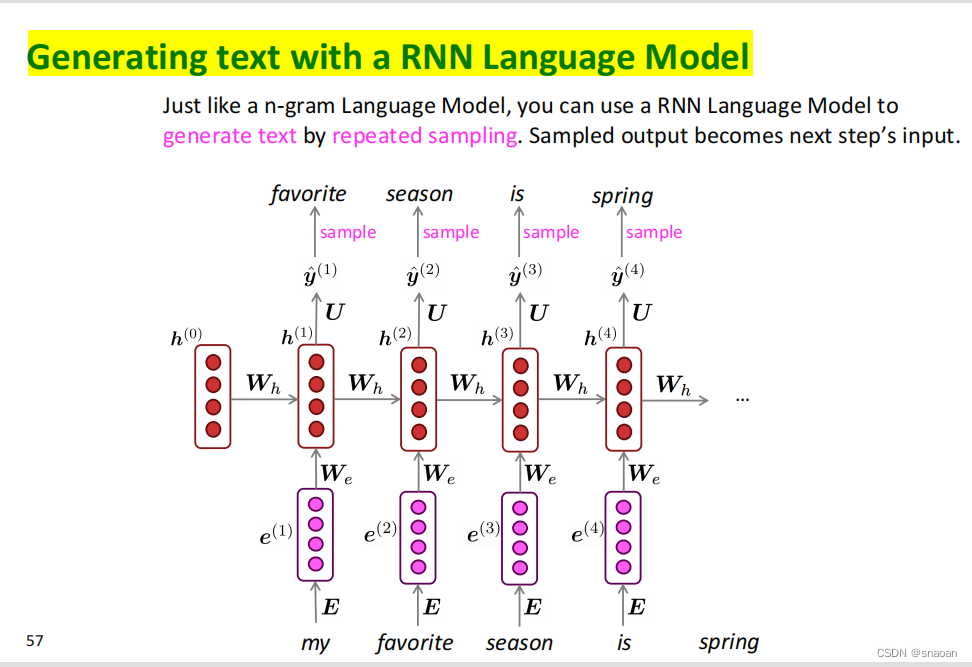
五、RNN和LSTM(6)

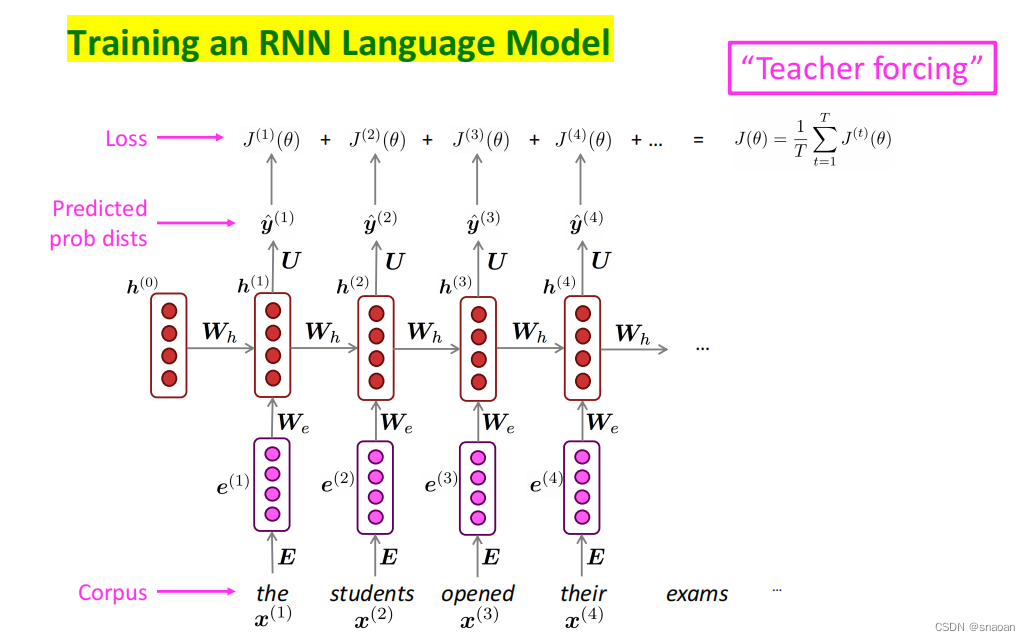

RNN的梯度消失与爆炸
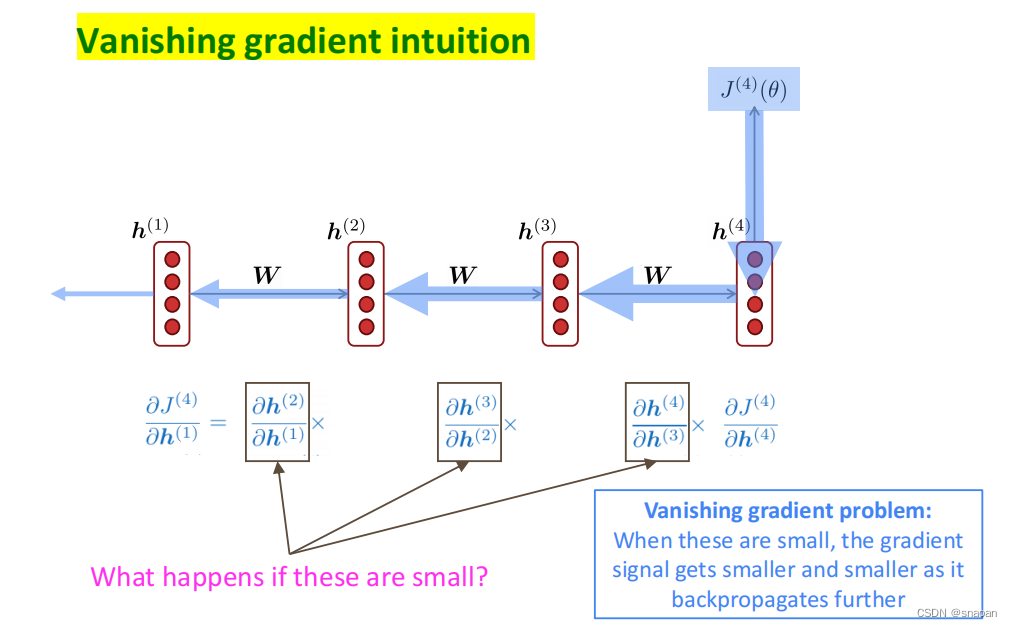
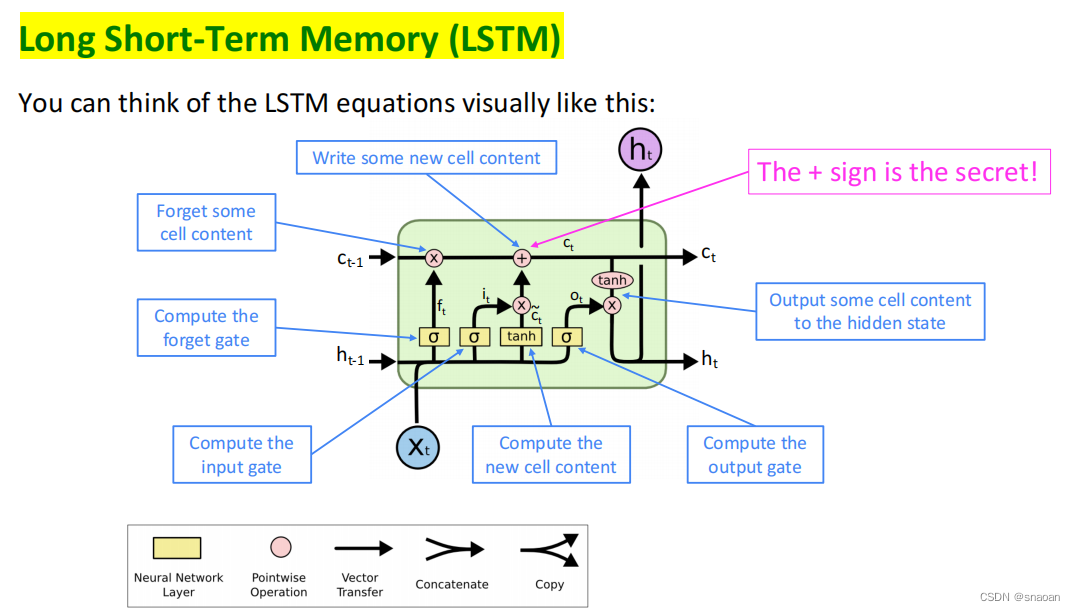
解决:LSTM

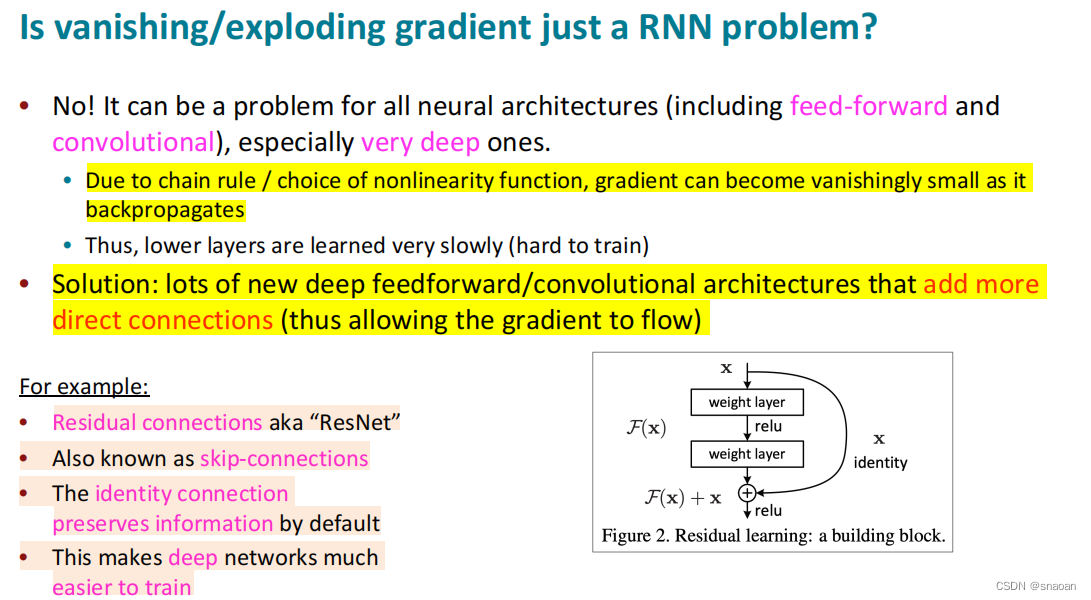
所有神经网络结构都有梯度问题。有对应的解决办法。
由于相同权重矩阵的重复乘法,RNN 特别不稳定。

六、: Machine Translation、 sequence-to-sequence、attention(7)





七、数据、实验(8)
2021的重点?


做实验的技巧


八、Transformer(9)
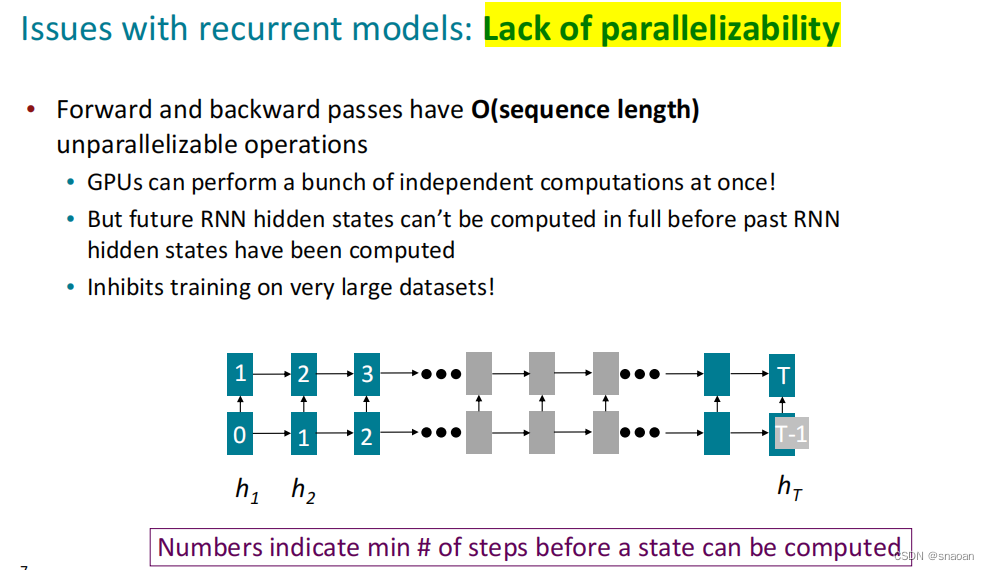
1、RNN存在的两个问题
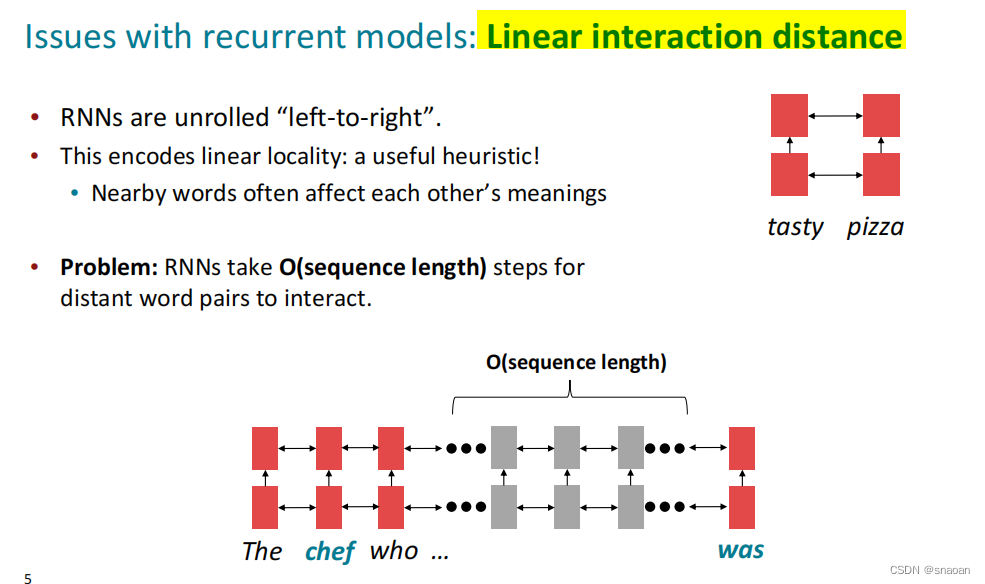
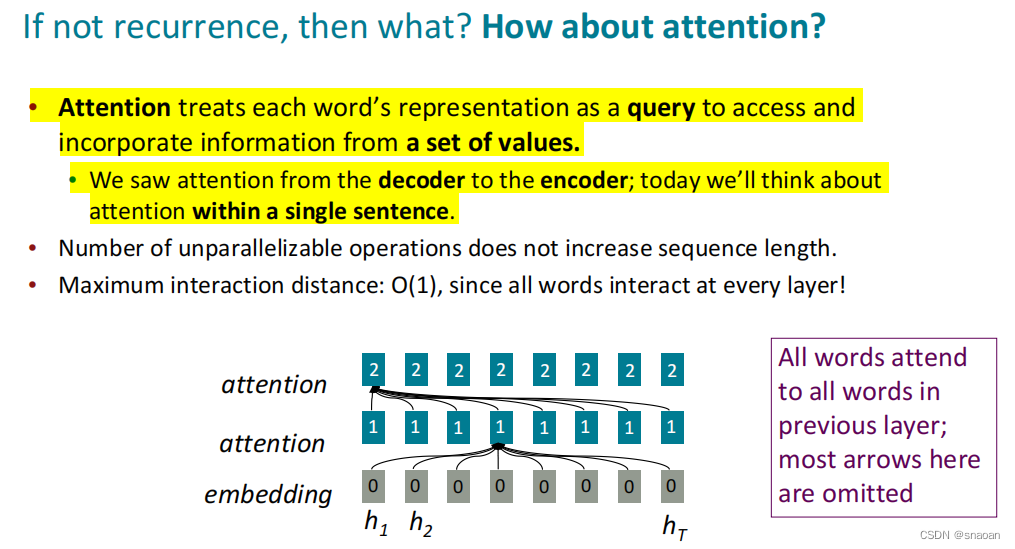
2、注意力机制

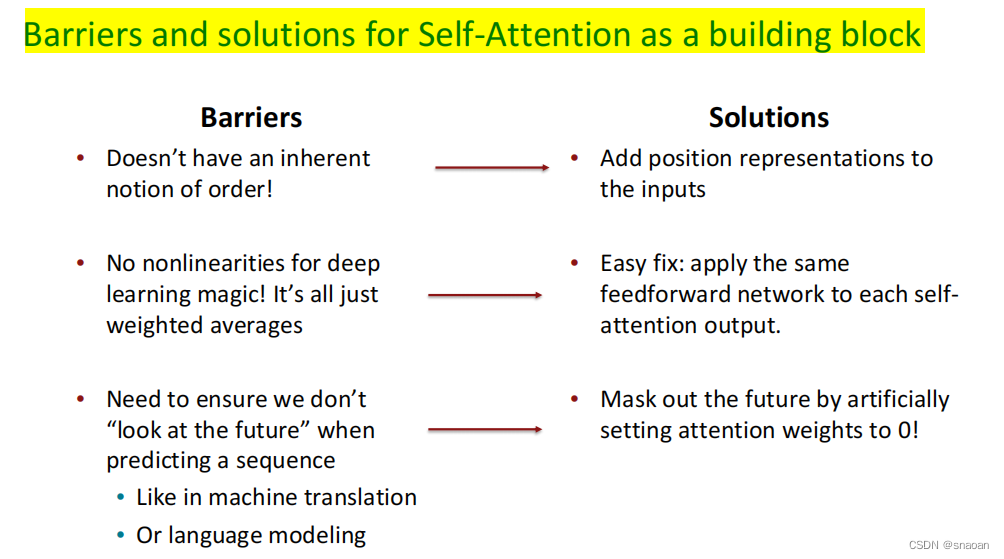
3、transformer结构

残差的好处,平滑损失
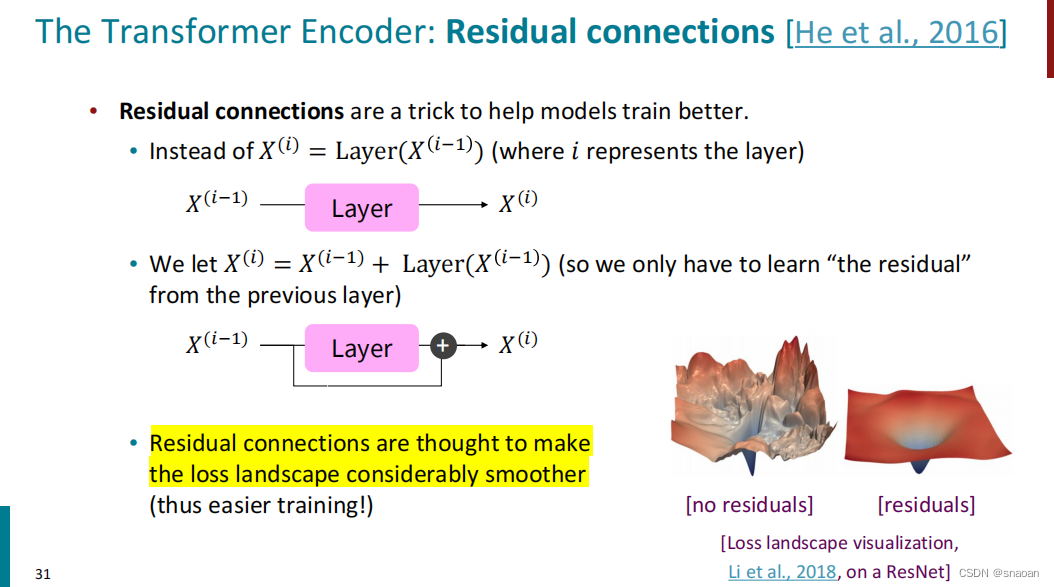
提升Transformer

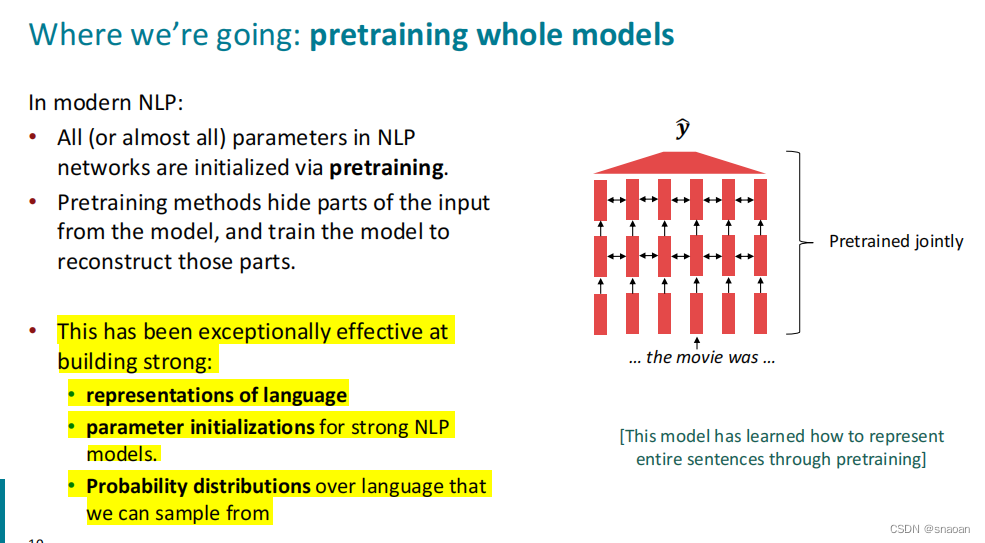
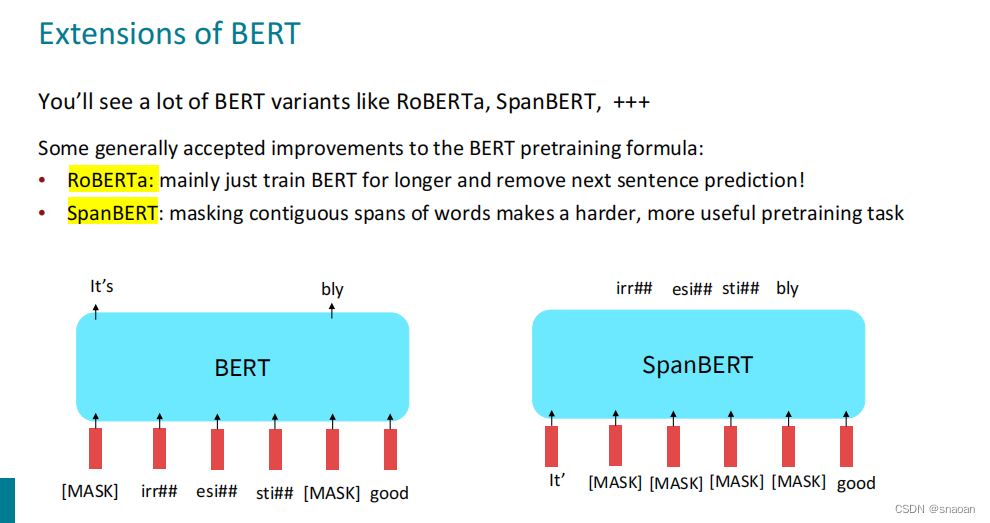
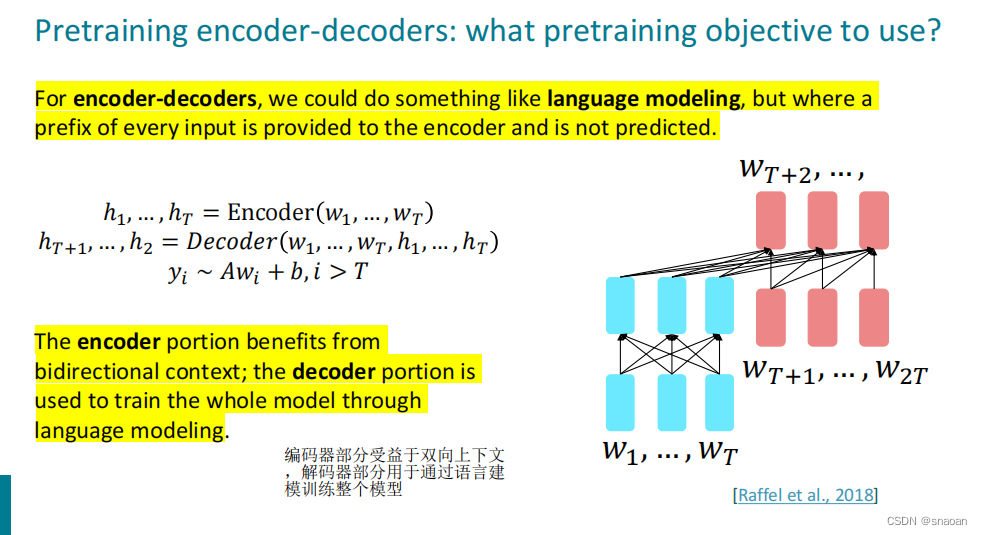
九、pretraining(10)



十、question answering(11)
由于自己重点不在qa上,快速浏览了一遍而已
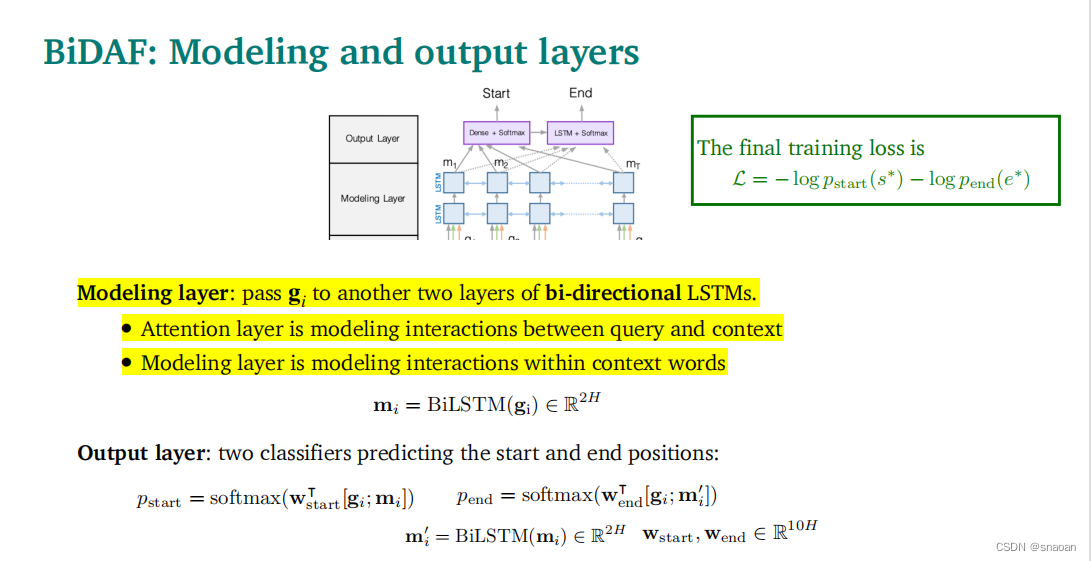
注意力层和建模层
十一、natural language generation(12)
同样粗略过了一下
文本生成任务:机器翻译、对话系统(目标导向、开放式)、故事生成、诗歌生成、文本摘要等
场景:各种数据(图片、表格、提示)->文本,文本 -> 文本




解码


随即缩放?

暴露偏差
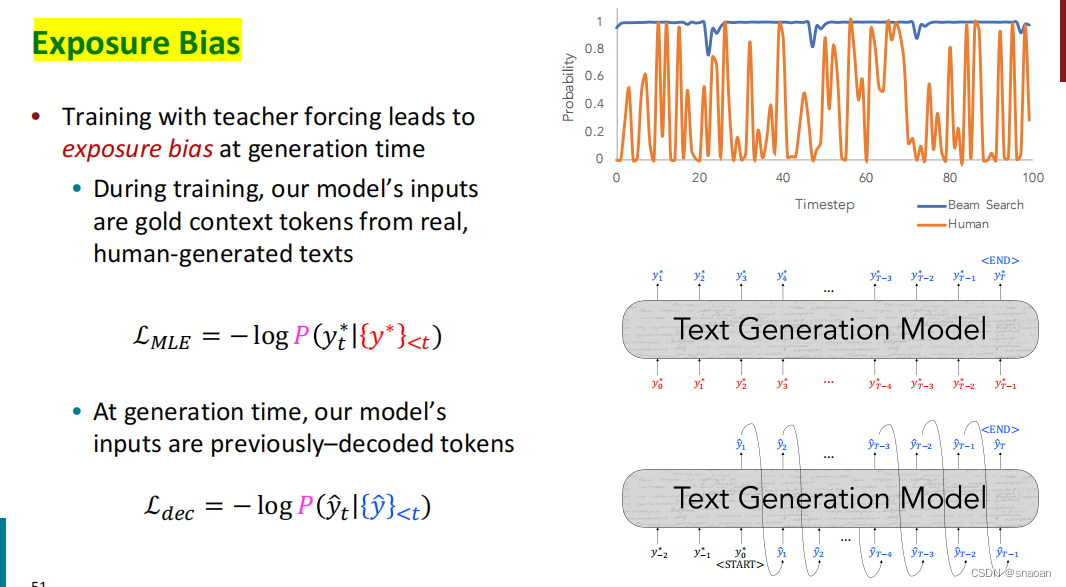
训练要点

评估要点

十二、Coreference Resolution(13)
粗看了一下



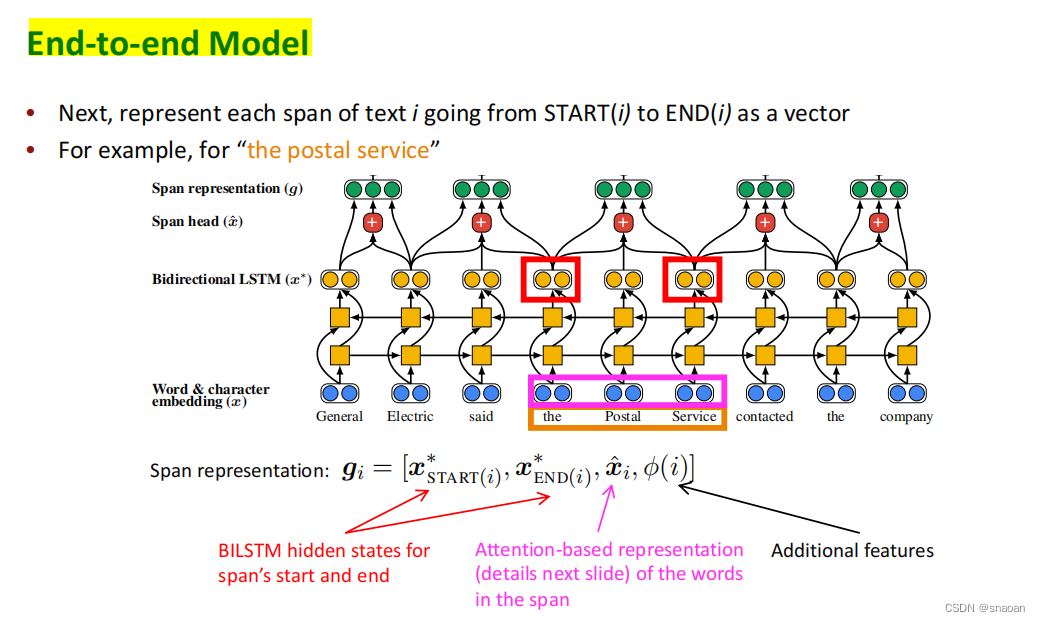
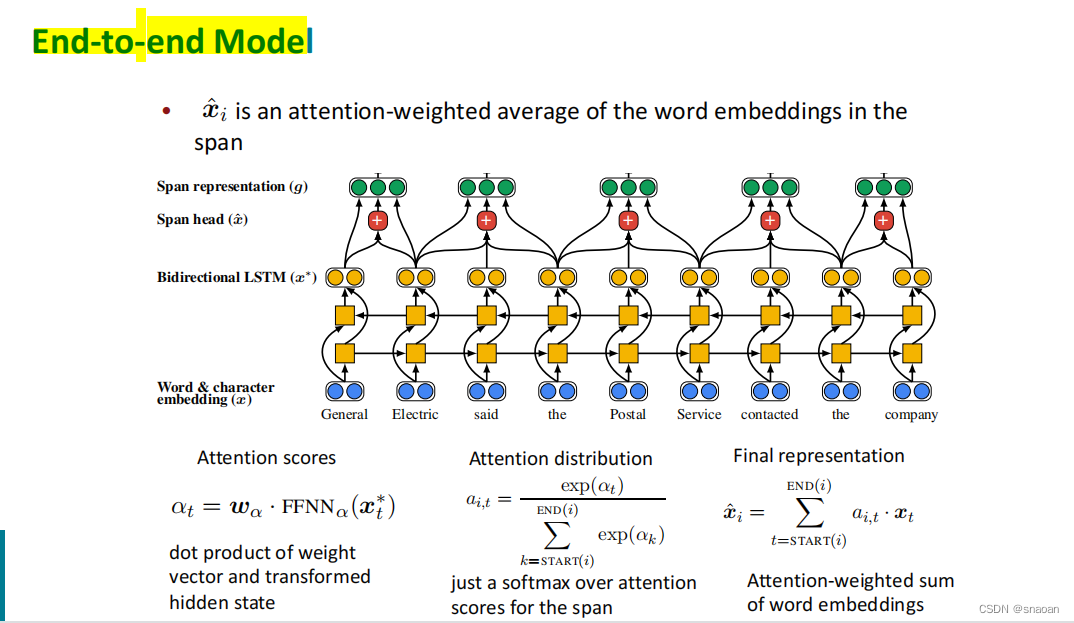
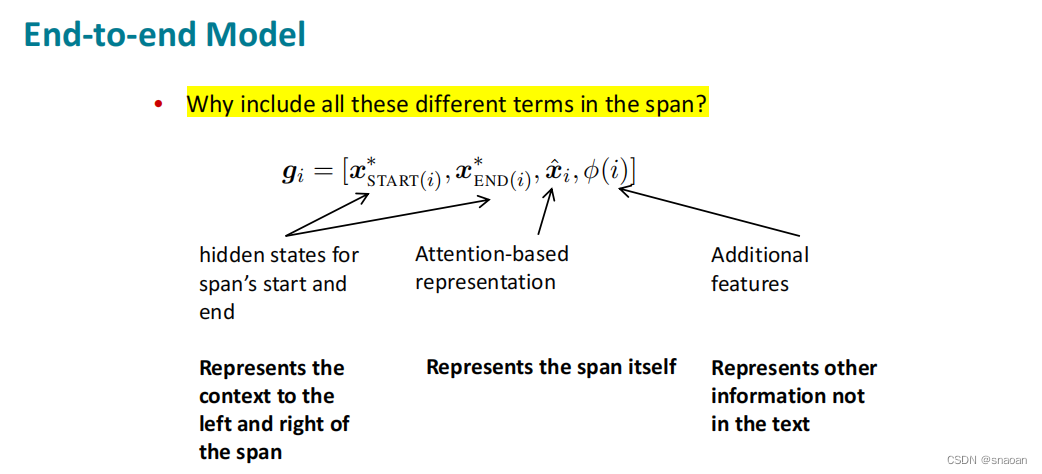
参考资料
1、如何通俗理解Word2Vec
2、【CS224n】(lecture4)Dependency Parsing 依存句法分析

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









