







 本文介绍使用jieba进行中文分词的方法,并利用Spark的Word2Vec算法计算词向量。通过腾讯开源的800万词数据集,演示如何应用Scipy库进行余弦相似度计算,最后引入LSH局部敏感哈希算法优化相似度近邻搜索。
本文介绍使用jieba进行中文分词的方法,并利用Spark的Word2Vec算法计算词向量。通过腾讯开源的800万词数据集,演示如何应用Scipy库进行余弦相似度计算,最后引入LSH局部敏感哈希算法优化相似度近邻搜索。
视频
地址在:添加链接描述
流程图
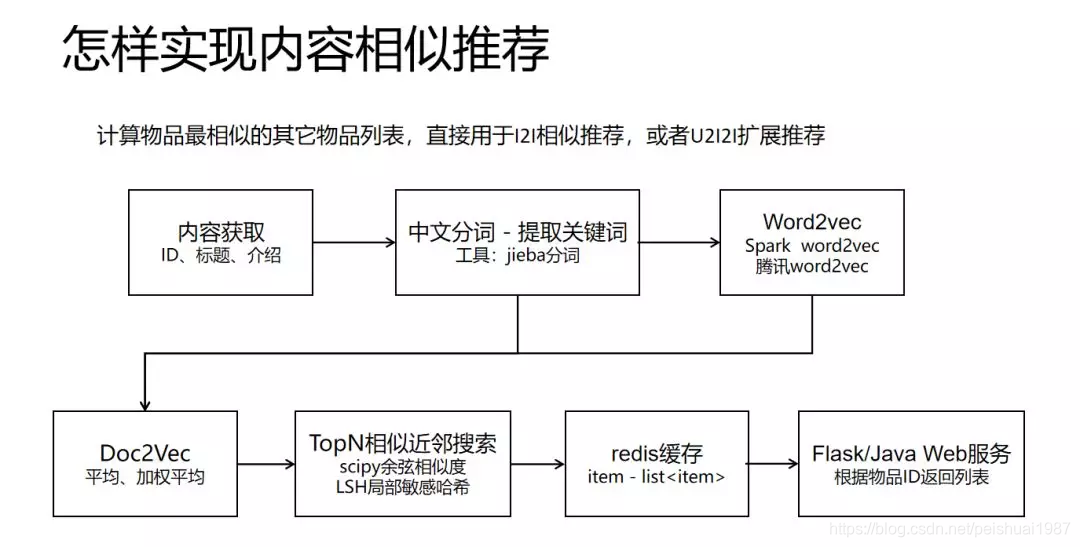
本视频涉及的相关资源:
1、jieba中文分词库:
https://github.com/fxsjy/jieba
2、spark word2vec计算:
http://spark.apache.org/docs/latest/ml-features.html#word2vec
3、腾讯开源800万word2vec数据:
https://ai.tencent.com/ailab/nlp/embedding.html
4、Scipy的相似度计算函数:
https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.spatial.distance.cosine.html
5、相似度近邻搜索优化算法LSH局部敏感哈希
http://spark.apache.org/docs/latest/ml-features.html#locality-sensitive-hashing



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











