




 本文介绍了大小端模式的概念,大端模式将数据的高字节存放在低地址,小端模式则相反。大小端模式主要与CPU相关,与操作系统和编译器无关。提供了通过强制类型转换判断大小端的方法,并展示了大小端转换的宏定义和函数实现。
本文介绍了大小端模式的概念,大端模式将数据的高字节存放在低地址,小端模式则相反。大小端模式主要与CPU相关,与操作系统和编译器无关。提供了通过强制类型转换判断大小端的方法,并展示了大小端转换的宏定义和函数实现。
正确区分大小端模式
嵌入式开发经常会遇到大小端的问题,往往学习后,过一段时间就又忘记了,这里总结一下,希望给大家留下深刻的记忆。
字节顺序是指占内存多于一个字节类型的数据在内存中的存放顺序,通常有小端和大端两种字节顺序,这两种你只需要深刻地记住其中的一种就可以,另一种恰好和它相反,不需要刻意记忆了,那么我们就记住“大端模式”吧。
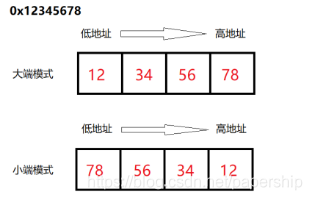
大端模式(Big-Endian):是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中。
说明:通常数据在内存中的存储是按照内存地址由低地址到高地址的顺序存储的,大端模式有点儿类似于把数据看做是一个字符串,然后按照字符串从左到右的顺序来存储,地址由小向大增加,而数据从高位往低位放,数据的存储方向和我们的阅读习惯(方向)一致。
小端模式(Little-Endian):是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。数据的存储方向和我们的阅读习惯(方向)不一致。
例子如下:
初学者往往被一些信息误导,而有这样的疑惑,例如:操作系统是大端还是小端存储?编译器是大端还是小端编译?CPU是大端还是小端?
其实,大小端主要有用于存储的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7555
7555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











