







 相机标定是计算相机内、外参数及畸变矫正的过程,对三维视觉应用至关重要。它恢复图像正常,使多相机在同一坐标系工作,应用于机械臂、自动驾驶、图像拼接和深度重建等领域。单目相机标定关注相机自身模型和相对位姿,而双目相机标定涉及相机间相对位姿,广泛用于全景拼接和AR等。
相机标定是计算相机内、外参数及畸变矫正的过程,对三维视觉应用至关重要。它恢复图像正常,使多相机在同一坐标系工作,应用于机械臂、自动驾驶、图像拼接和深度重建等领域。单目相机标定关注相机自身模型和相对位姿,而双目相机标定涉及相机间相对位姿,广泛用于全景拼接和AR等。
1. 相机标定的定义及作用
相机标定是指借助标定板来计算单个或多个相机的内参、外参和镜头畸变参数。

作用:
将畸变的图像恢复为正常的图像,为后续进行拼接、SLAM等奠定基础。
多相机标定可以将所有相机输出变换到同一个坐标系。
相机标定是三维视觉应用的必备步骤,广泛应用于机械臂、机器人定位建图、自动驾驶汽车/智能手机标定、图像拼接、三维重建。
2. 为什么需要相机标定
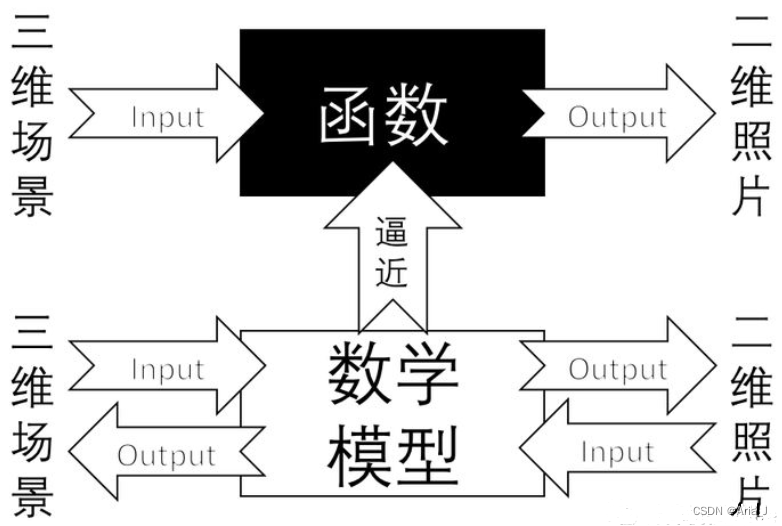
真实世界是三维的,而相机拍摄的图像是二维的,其中必然会丢失距离/深度信息。抽象成数学问题就是相机类似一个映射函数,将输入的三维场景映射成一个二维图片(可能是灰度图像也可能是彩色图像)。

而相机标定就是使用数学模型和数学方法来近似逼近这一复杂映射函数的过程。标定后的相机即具有了描述这一过程的能力,从而可以用于各种计算机视觉的任务,如深度恢复、三维重建等,本质上都是对丢失的距离信息的恢复。
3. 相机标定到底在标定什么
在实际应用中可以将相机标定分为单目相机标定和多目(双目)相机标定
3.1 单目相机标定
这类应用通常需要相机自身的成像模型参数以及相机相对某个坐标系下的相对位姿。
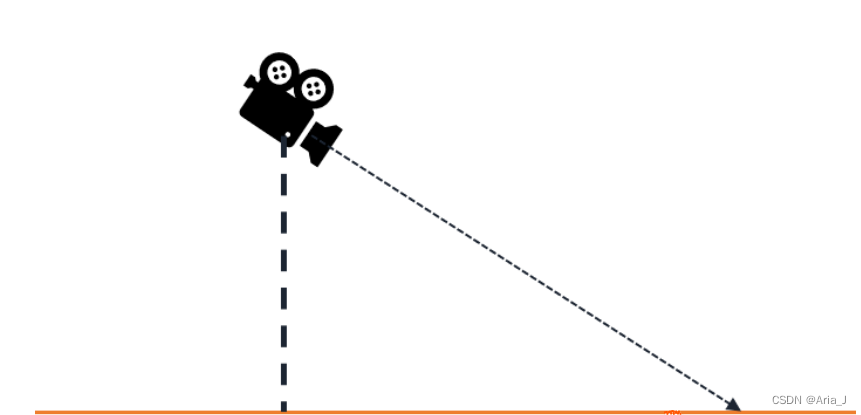
(1)比如下图简单场景,如果能知道相机的朝向以及距离地面的高度,就可以大致估计出相机某个像素对应物体的距离(实际可以测量物体高度或者物体贴近地面)。这种模型在一些简单的车载任务上比较常见,比如推测前车距离。
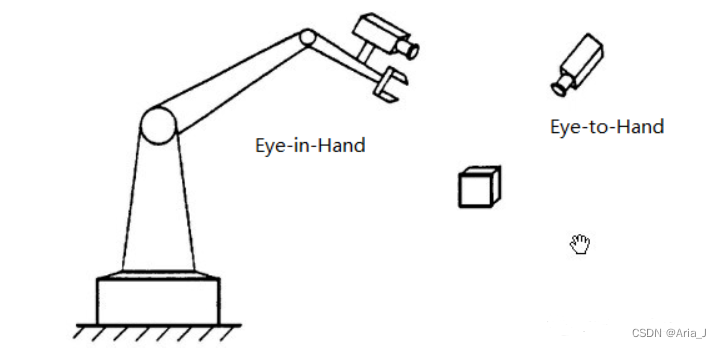
(2)再比如工业上比较常见的机器人控制,需要构建机器人坐标系和其视觉坐标系之间的相对位置关系(也就是手眼标定)
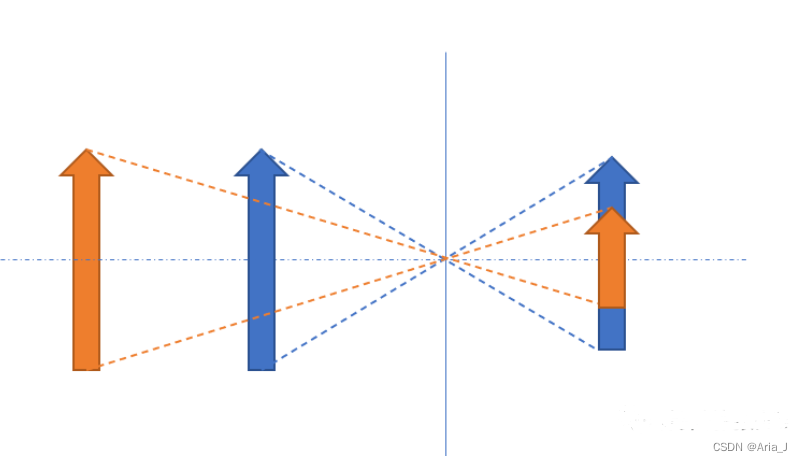
(3)再比如单目深度恢复,一些传统的单目深度恢复通常使用固定尺寸的物体作为标志物,之后移动物体,通过相机中物体大小来判断实际的拍摄距离。
(4)再比如一些SLAM方法,目前有一些自监督的深度学习方法也会使用相对姿态信息作为监督(比如ManyDepth)
3.2 多目(双目)相机标定
这类应用更加常见,通常需要获取相机自身信息,以及各个相机之间的相对位姿信息,有时也需要获取其和某固定坐标系之间的关系。
(1)比如车载全景环视,需要获取四个相机相对位姿以及其和地面坐标系的关系,才能得到最终的全景拼接结果。
(2)再比如AR应用,或者更复杂的相机阵列。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









