




public class ImplGenertor implements Genertor {
@Override
public T next() {
return null;
}
}
2、传入泛型实参
在 new 出类的实例时,和普通的类没区别。
public class ImplGenertor2 implements Genertor {
@Override
public String next() {
return null;
}
}
泛型方法
泛型方法的 定义在 「修饰符与返回值」 的中间。示例代码如下所示:
public T genericMethod(T…a){
return a[a.length/2];
}
泛型方法,是在调用方法的时候指明泛型的具体类型,泛型方法可以在任何地方和任何场景中使用,包括普通类和泛型类。
泛型类中定义的普通方法和泛型方法的区别
在普通方法中:
// 虽然在方法中使用了泛型,但是这并不是一个泛型方法。
// 这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类已经声明过的泛型。
// 所以在这个方法中才可以继续使用 T 这个泛型。
public T getKey(){
return key;
}
在泛型方法中:
/**
- 这才是一个真正的泛型方法。
- 首先在 public 与返回值之间的 必不可少,这表明这是一个泛型方法,并且声明了一个泛型 T
- 这个 T 可以出现在这个泛型方法的任意位置,泛型的数量也可以为任意多个。
*/
public <T,K> K showKeyName(Generic container){
// …
}
4)、限定类型变量
public class ClassBorder {
…
}
public class GenericRaw<T extends ArrayList&Comparable> {
…
}
-<T extends Comparable>:「T 表示应该绑定类型的子类型,Comparable 表示绑定类型,子类型和绑定类型可以是类也可以是接口」。
- 「extends 左右都允许有多个,如 T,V extends Comparable&Serializable」。
- 「注意限定类型中,只允许有一个类,而且如果有类,这个类必须是限定列表的第一个」。
- 「限定类型变量既可以用在泛型方法上也可以用在泛型类上」。
5)、泛型中的约束和局限性
- 1、不能用基本类型实例化类型参数。
- 2、运行时类型查询只适用于原始类型。
- 3、泛型类的静态上下文中类型变量失效:不能在静态域或方法中引用类型变量。因为泛型是要在对象创建的时候才知道是什么类型的,而对象创建的代码执行先后顺序是 static 的部分,然后才是构造函数等等。所以在对象初始化之前 static 的部分已经执行了,如果你在静态部分引用泛型,那么毫无疑问虚拟机根本不知道是什么东西,因为这个时候类还没有初始化。
- 4、不能创建参数化类型的数组,但是可以定义参数化类型的数组。
- 5、不能实例化类型变量。
- 6、不能使用 try-catch 捕获泛型类的实例。
6)、泛型类型的继承规则
泛型类可以继承或者扩展其他泛型类,比如 List 和 ArrayList:
private static class ExtendPair extends Pair{
…
}
7)、通配符类型
?extends X:「表示类型的上界,类型参数是 X 的子类」。?super X:「表示类型的下界,类型参数是 X 的超类」。
?extends X
如果其中提供了 get 和 set 类型参数变量的方法的话,set 方法是不允许被调用的,会出现编译错误,而 get 方法则没问题。
?extends X 表示类型的上界,类型参数是 X 的子类,那么可以肯定的说,get 方法返回的一定是个 X(不管是 X 或者 X 的子类)编译器是可以确定知道的。但是 set 方法只知道传入的是个 X,至于具体是 X 的哪个子类,是不知道的。
因此,「?extends X 主要用于安全地访问数据,可以访问 X 及其子类型,并且不能写入非 null 的数据」。
?super X
如果其中提供了 get 和 set 类型参数变量的方法的话,set 方法可以被调用,且能传入的参数只能是 X 或者 X 的子类。而 get 方法只会返回一个 Object 类型的值。
? super X 表示类型的下界,类型参数是 X 的超类(包括 X 本身),那么可以肯定的说,get 方法返回的一定是个 X 的超类,那么到底是哪个超类?不知道,但是可以肯定的说,Object 一定是它的超类,所以 get 方法返回 Object。编译器是可以确定知道的。对于 set 方法来说,编译器不知道它需要的确切类型,但是 X 和 X 的子类可以安全的转型为 X。
因此,「?super X 主要用于安全地写入数据,可以写入 X 及其子类型」。
无限定的通配符 ?
「表示对类型没有什么限制,可以把 ?看成所有类型的父类,如 ArrayList<?>」。
8)、虚拟机是如何实现泛型的?
泛型思想早在 C++ 语言的模板(Template)中就开始生根发芽,「在 Java 语言处于还没有出现泛型的版本时,只能通过 Object 是所有类型的父类和类型强制转换两个特点的配合来实现类型泛化」。
由于 Java 语言里面所有的类型都继承于 java.lang.Object,所以 Object 转型成任何对象都是有可能的。但是也因为有无限的可能性,就只有程序员和运行期的虚拟机才知道这个 Object 到底是个什么类型的对象。在编译期间,编译器无法检查这个 Object 的强制转型是否成功,如果仅仅依赖程序员去保障这项操作的正确性,许多 ClassCastException 的风险就会转嫁到程序运行期之中。
此外,泛型技术在 C#/C++ 和 Java 之中的使用方式看似相同,但实现上却有着根本性的分歧,C# 里面的泛型无论在程序源码中、编译后的 IL 中(Intermediate Language,中间语言,这时候泛型是一个占位符),或是运行期的 CLR 中,都是切实存在的,「List<int> 与 List<String> 就是两个不同的类型,它们在系统运行期生成,有自己的虚方法表和类型数据,这种实现称为类型膨胀,基于这种方法实现的泛型称为真实泛型」。
而 「Java 语言中的泛型则不一样,它只在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型(Raw Type,也称为裸类型)了,并且在相应的地方插入了强制转型代码」,因此,对于运行期的 Java 语言来说,ArrayList<int> 与 ArrayList<String> 就是同一个类,所以 「泛型技术实际上是 Java 语言的一颗语法糖,Java 语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型称为伪泛型」。 将一段 Java 代码编译成 Class 文件,然后再用字节码反编译工具进行反编译后,将会发现泛型都不见了,程序又变回了 Java 泛型出现之前的写法,泛型类型都变回了原生类型。
由于 Java 泛型的引入,各种场景(虚拟机解析、反射等)下的方法调用都可能对原有的基础产生影响和新的需求,如在泛型类中如何获取传入的参数化类型等。因此,JCP 组织对虚拟机规范做出了相应的修改,引入了诸如 Signature、LocalVariableTypeTable 等新的属性用于解决伴随泛型而来的参数类型的识别问题,「Signature 是其中最重要的一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息」。修改后的虚拟机规范要求所有能识别 49.0 以上版本的 Class 文件的虚拟机都要能正确地识别 Signature 参数。
最后,「从 Signature 属性的出现我们还可以得出结论,擦除法所谓的擦除,仅仅是对方法的 Code 属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是我们能通过反射手段取得参数化类型的根本依据」。
二、初识 ByteX
ByteX 使用了纯 Java 来编写源码,它是一个基于 Gradle transform api 和 ASM 的字节码插桩平台。
❝
调试:gradle clean :example:assembleRelease -Dorg.gradle.debug=true --no-daemon
❞
1、优势
- 1)、「自动集成到其它宿主和插件一起整合为一个单独的 MainTransformFlow,结合 class 文件多线程并发处理,避免了打包的额外时间呈线性增长」。
- 2)、「插件、宿主之间完全解耦,便于协同开发」。
- 3)、「common module 提供通用的代码复用,每个插件只需专注自身的字节码插桩逻辑」。
2、MainTransformFlow 基本流程
在 MainTransformFlow implements MainProcessHandler 常规处理过程,会遍历两次工程构建中的所有 class。
- 1)、第一次,遍历 traverse 与 traverseAndroidJar 过程,以形成完整的类图。
- 2)、第二次,执行 transform:再遍历一次工程中所有的构建产物,并对 class 文件做处理后输出。
3、如何自定义独立的 TransformFlow?
重写 IPlugin 的 provideTransformFlow 即可。
4、类图对象
context.getClassGraph() 获取类图对象,两个 TransformFlow 的类图是隔离的。
5、MainProcessHandler
- 通过复写 process 方法,注册自己的 FlieProcessor 来处理。
- FileProcessor 采用了责任链模式,每个 class 文件都会流经一系列的 FileProcessor 来处理。
6、IPlugin.hookTransformName()
「使用 反射 Hook 方式 将 Transform 注册到 proguard 之后」。
三、ByteX 插件平台构建流程探秘
添加 apply plugin: ‘bytex’ 之后,bytex 可以在 Gradle 的构建流程中起作用了。这里的插件 id 为 bytex,我们找到 bytex.properties 文件,查看里面映射的实现类,如下所示:
implementation-class=com.ss.android.ugc.bytex.base.ByteXPlugin
可以看到,bytex 的实现类为 ByteXPlugin,其源码如下所示:
public class ByteXPlugin implements Plugin {
@Override
public void apply(@NotNull Project project) {
// 1
AppExtension android = project.getExtensions().getByType(AppExtension.class);
// 2
ByteXExtension extension = project.getExtensions().create(“ByteX”, ByteXExtension.class);
// 3
android.registerTransform(new ByteXTransform(new Context(project, android, extension)));
}
}
首先,注释1处,获取 Android 为 App 提供的扩展属性 AppExtension 实例。然后,在注释2处,获取 ByteX 自身创建的扩展属性 ByteXExtension 实例。最后,在注释3处,注册 ByteXTransform 实例。ByteXTransform 继承了抽象类 CommonTransform,其实现了关键的 transform 方法,其实现源码如下所示:
@Override
public final void transform(TransformInvocation transformInvocation) throws TransformException, InterruptedException, IOException {
super.transform(transformInvocation);
// 1、如果不是增量模式,则清楚输出目录的文件。
if (!transformInvocation.isIncremental()) {
transformInvocation.getOutputProvider().deleteAll();
}
// 2、获取 transformContext 实例。
TransformContext transformContext = getTransformContext(transformInvocation);
// 3、初始化 HtmlReporter(生成 ByteX 构建产生日志的 HTML 文件)
init(transformContext);
// 4、过滤掉没有打开插件开关的 plugin。
List plugins = getPlugins().stream().filter(p -> p.enable(transformContext)).collect(Collectors.toList());
Timer timer = new Timer();
// 5、创建一个 transformEngine 实例。
TransformEngine transformEngine = new TransformEngine(transformContext);
try {
if (!plugins.isEmpty()) {
// 6、使用 PriorityQueue 对每一个 TransformFlow 进行优先级排序(在这里添加的是与之对应的实现类 MainTransformFlow)。
Queue flowSet = new PriorityQueue<>((o1, o2) -> o2.getPriority() - o1.getPriority());
MainTransformFlow commonFlow = new MainTransformFlow(transformEngine);
flowSet.add(commonFlow);
for (int i = 0; i < plugins.size(); i++) {
// 7、给每一个 Plugin 注册 MainTransformFlow,其实质是将每一个 Plugin 的 MainProcessHandler 添加到 MainTransformFlow 中的 handlers 列表中。
IPlugin plugin = plugins.get(i);
TransformFlow flow = plugin.registerTransformFlow(commonFlow, transformContext);
if (!flowSet.contains(flow)) {
flowSet.add(flow);
}
}
while (!flowSet.isEmpty()) {
TransformFlow flow = flowSet.poll();
if (flow != null) {
if (flowSet.size() == 0) {
flow.asTail();
}
// 8、按指定优先级执行每一个 TransformFlow 的 run 方法,默认只有一个 MainTransformFlow 实例。
flow.run();
// 9、获取流中的 graph 类图对象并清除。
Graph graph = flow.getClassGraph();
if (graph != null) {
//clear the class diagram.we won’t use it anymore
graph.clear();
}
}
}
} else {
transformEngine.skip();
}
// 10
afterTransform(transformInvocation);
} catch (Throwable throwable) {
LevelLog.sDefaultLogger.e(throwable.getClass().getName(), throwable);
throw throwable;
} finally {
for (IPlugin plugin : plugins) {
try {
plugin.afterExecute();
} catch (Throwable throwable) {
LevelLog.sDefaultLogger.e(“do afterExecute”, throwable);
}
}
transformContext.release();
release();
timer.record(“Total cost time = [%s ms]”);
if (BooleanProperty.ENABLE_HTML_LOG.value()) {
HtmlReporter.getInstance().createHtmlReporter(getName());
HtmlReporter.getInstance().reset();
}
}
}
在注释7处,调用了 plugin.registerTransformFlow 方法,其源码如下所示:
@Nonnull
@Override
public final TransformFlow registerTransformFlow(@Nonnull MainTransformFlow mainFlow, @Nonnull TransformContext transformContext) {
if (transformFlow == null) {
transformFlow = provideTransformFlow(mainFlow, transformContext);
if (transformFlow == null) {
throw new RuntimeException(“TransformFlow can not be null.”);
}
}
return transformFlow;
}
这里继续调用了 provideTransformFlow 方法,其源码如下所示:
/**
- create a new transformFlow or just return mainFlow and append a handler.
- It will be called by {@link IPlugin#registerTransformFlow(MainTransformFlow, TransformContext)} when
- handle start.
- @param mainFlow main TransformFlow
- @param transformContext handle context
- @return return a new TransformFlow object if you want make a new flow for current plugin
*/
protected TransformFlow provideTransformFlow(@Nonnull MainTransformFlow mainFlow, @Nonnull TransformContext transformContext) {
return mainFlow.appendHandler(this);
}
可以看到,通过调用 mainFlow.appendHandler(this) 方法将每一个 Plugin 的 MainProcessHandler 添加到 MainTransformFlow 中的 handlers 列表之中。
在注释8处,按指定优先级执行了每一个 TransformFlow 的 run 方法,默认只有一个 MainTransformFlow 实例。我们看到了 MianTransformFlow 的 run 方法:
@Override
public void run() throws IOException, InterruptedException {
try {
// 1
beginRun();
// 2
runTransform();
} finally {
// 3
endRun();
}
}
首先,在注释1出,调用了 beginRun 方法,其实现如下:
// AbsTransformFlow
protected void beginRun() {
transformEngine.beginRun();
}
// TransformEngine
public void beginRun(){
context.markRunningState(false);
}
// TransformContext
private final AtomicBoolean running = new AtomicBoolean(false);
void markRunningState(boolean running) {
this.running.set(running);
}
最后,在 TransformContext 实例中使用了一个 AtomicBoolean 实例标记 MainTransformFlow 是否正在运行中。
然后,在注释2处执行了 runTransform 方法,这里就是真正执行 transform 的地方,其源码如下所示:
private void runTransform() throws IOException, InterruptedException {
if (handlers.isEmpty()) return;
Timer timer = new Timer();
timer.startRecord(“PRE_PROCESS”);
timer.startRecord(“INIT”);
// 1、初始化 handlers 列表中的每一个 handler。
for (MainProcessHandler handler : handlers) {
handler.init(transformEngine);
}
timer.stopRecord(“INIT”, “Process init cost time = [%s ms]”);
// 如果不是 跳过 traverse 仅仅只执行 Transform 方法时,才执行 traverse 过程。
if (!isOnePassEnough()) {
if (!handlers.isEmpty() && context.isIncremental()) {
timer.startRecord(“TRAVERSE_INCREMENTAL”);
// 2、如果是 增量模式,则执行 traverseArtifactOnly(仅仅增量遍历产物)调用每一个 plugin 的对应的 MainProcessHandler 的 traverseIncremental 方法。这里最终会调用 ClassFileAnalyzer.handle 方法进行遍历分发操作。
traverseArtifactOnly(getProcessors(Process.TRAVERSE_INCREMENTAL, new ClassFileAnalyzer(context, Process.TRAVERSE_INCREMENTAL, null, handlers)));
timer.stopRecord(“TRAVERSE_INCREMENTAL”, “Process project all .class files cost time = [%s ms]”);
}
handlers.forEach(plugin -> plugin.beforeTraverse(transformEngine));
timer.startRecord(“LOADCACHE”);
// 3、创建一个 CachedGraphBuilder 对象:能够缓存 类图 的 类图构建者对象。
GraphBuilder graphBuilder = new CachedGraphBuilder(context.getGraphCache(), context.isIncremental(), context.shouldSaveCache());
if (context.isIncremental() && !graphBuilder.isCacheValid()) {
// 4、如果是增量更新 && graphBuilder 的缓存失效则直接请求非增量运行。
context.requestNotIncremental();
}
timer.stopRecord(“LOADCACHE”, “Process loading cache cost time = [%s ms]”);
// 5、内部会调用 running.set(true) 来标记正在运行的状态。
running();
if (!handlers.isEmpty()) {
timer.startRecord(“PROJECT_CLASS”);
// 6、执行 traverseArtifactOnly(遍历产物)调用每一个 plugin 的对应的 MainProcessHandler 的 traverse 方法,这里最终会调用 ClassFileAnalyzer.handle 方法进行遍历分发操作。
traverseArtifactOnly(getProcessors(Process.TRAVERSE, new ClassFileAnalyzer(context, Process.TRAVERSE, graphBuilder, handlers)));
timer.stopRecord(“PROJECT_CLASS”, “Process project all .class files cost time = [%s ms]”);
}
if (!handlers.isEmpty()) {
timer.startRecord(“ANDROID”);
// 7、仅仅遍历 Android.jar
traverseAndroidJarOnly(getProcessors(Process.TRAVERSE_ANDROID, new ClassFileAnalyzer(context, Process.TRAVERSE_ANDROID, graphBuilder, handlers)));
timer.stopRecord(“ANDROID”, “Process android jar cost time = [%s ms]”);
}
timer.startRecord(“SAVECACHE”);
// 8、构建 mClassGraph 类图实例。
mClassGraph = graphBuilder.build();
timer.stopRecord(“SAVECACHE”, “Process saving cache cost time = [%s ms]”);
}
timer.stopRecord(“PRE_PROCESS”, “Collect info cost time = [%s ms]”);
if (!handlers.isEmpty()) {
timer.startRecord(“PROCESS”);
// 9、遍历执行每一个 plugin 的 transform 方法。
transform(getProcessors(Process.TRANSFORM, new ClassFileTransformer(handlers, needPreVerify(), needVerify())));
timer.stopRecord(“PROCESS”, “Transform cost time = [%s ms]”);
}
}
首先,在注释1处,遍历调用了每一个 MainProcessHandler 的 init 方法,它是用于 transform 开始前的初始化实现方法。
MainProcessHandler 接口的 init 方法是一个 default 方法,里面直接调用了每一个 pluign 实现的 init 方法(如果 plugin 没有实现,则仅仅调用 CommonPlugin 的实现的 init 方法:这里通常是用于把不需要处理的文件添加到 mWhiteList 列表),这里可以做一些plugin 的准备工作。
1、仅仅遍历产物
traverseArtifactOnly(getProcessors(Process.TRAVERSE, new ClassFileAnalyzer(context, Process.TRAVERSE, graphBuilder, handlers)));
getProcessors 方法的源码如下所示:
private FileProcessor[] getProcessors(Process process, FileHandler fileHandler) {
List processors = handlers.stream()
.flatMap((Function<MainProcessHandler, Stream>) handler -> handler.process(process).stream())
.collect(Collectors.toList());
switch (process) {
case TRAVERSE_INCREMENTAL:
processors.add(0, new FilterFileProcessor(fileData -> fileData.getStatus() != Status.NOTCHANGED));
processors.add(new IncrementalFileProcessor(handlers, ClassFileProcessor.newInstance(fileHandler)));
break;
case TRAVERSE:
case TRAVERSE_ANDROID:
case TRANSFORM:
processors.add(ClassFileProcessor.newInstance(fileHandler));
processors.add(0, new FilterFileProcessor(fileData -> fileData.getStatus() != Status.NOTCHANGED && fileData.getStatus() != Status.REMOVED))
break;
default:
throw new RuntimeException(“Unknow Process:” + process);
}
return processors.toArray(new FileProcessor[0]);
}
这里的 processor 的添加由 增量 进行界定,具体的处理标准如下:
-
TRAVERSE_INCREMENTAL: -
FilterFileProcessor:「按照不同的过程过滤掉不需要的 FileData」。 -
IncrementalFileProcessor:「用于进行 增量文件的处理」。 -
TRAVERSE/TRAVERSE_ANDROID/TRANSFORM: -
FilterFileProcessor:「按照不同的过程过滤掉不需要的 FileData」。 -
ClassFileProcessor:「用于处理 .class 文件」。
2、仅仅遍历 Android Jar 包
traverseAndroidJarOnly(getProcessors(Process.TRAVERSE_ANDROID, new ClassFileAnalyzer(context, Process.TRAVERSE_ANDROID, graphBuilder, handlers)));
3、构建 mClassGraph 类图对象
mClassGraph = graphBuilder.build();
4、执行 Transform
transform(getProcessors(Process.TRANSFORM, new ClassFileTransformer(handlers, needPreVerify(), needVerify())));
transform 的源码如下所示:
// AbsTransformFlow 类中
protected AbsTransformFlow transform(FileProcessor… processors) throws IOException, InterruptedException {
beforeTransform(transformEngine);
transformEngine.transform(isLast, processors);
afterTransform(transformEngine);
return this;
}
1)、beforeTransform(transformEngine)
// MainTransformFlow
@Override
protected AbsTransformFlow beforeTransform(TransformEngine transformEngine) {
// 1
handlers.forEach(plugin -> plugin.beforeTransform(transformEngine));
return this;
}
注释1处,遍历执行 每一个 plugin 的 beforeTransform 方法做一些自身 transform 前的准备工作。
2)、transformEngine.transform(isLast, processors)
// TranformEngine
public void transform(boolean isLast, FileProcessor… processors) {
Schedulers.FORKJOINPOOL().invoke(new PerformTransformTask(context.allFiles(), getProcessorList(processors), isLast, context));
}
Shedulers.FORKJOINPOOL() 方法的源码如下所示:
public class Schedulers {
private static final int cpuCount = Runtime.getRuntime().availableProcessors();
private final static ExecutorService IO = new ThreadPoolExecutor(0, cpuCount * 3,
30L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>());
// 1
private static final ExecutorService COMPUTATION = Executors.newWorkStealingPool(cpuCount);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)

学习分享
①「Android面试真题解析大全」PDF完整高清版+②「Android面试知识体系」学习思维导图压缩包
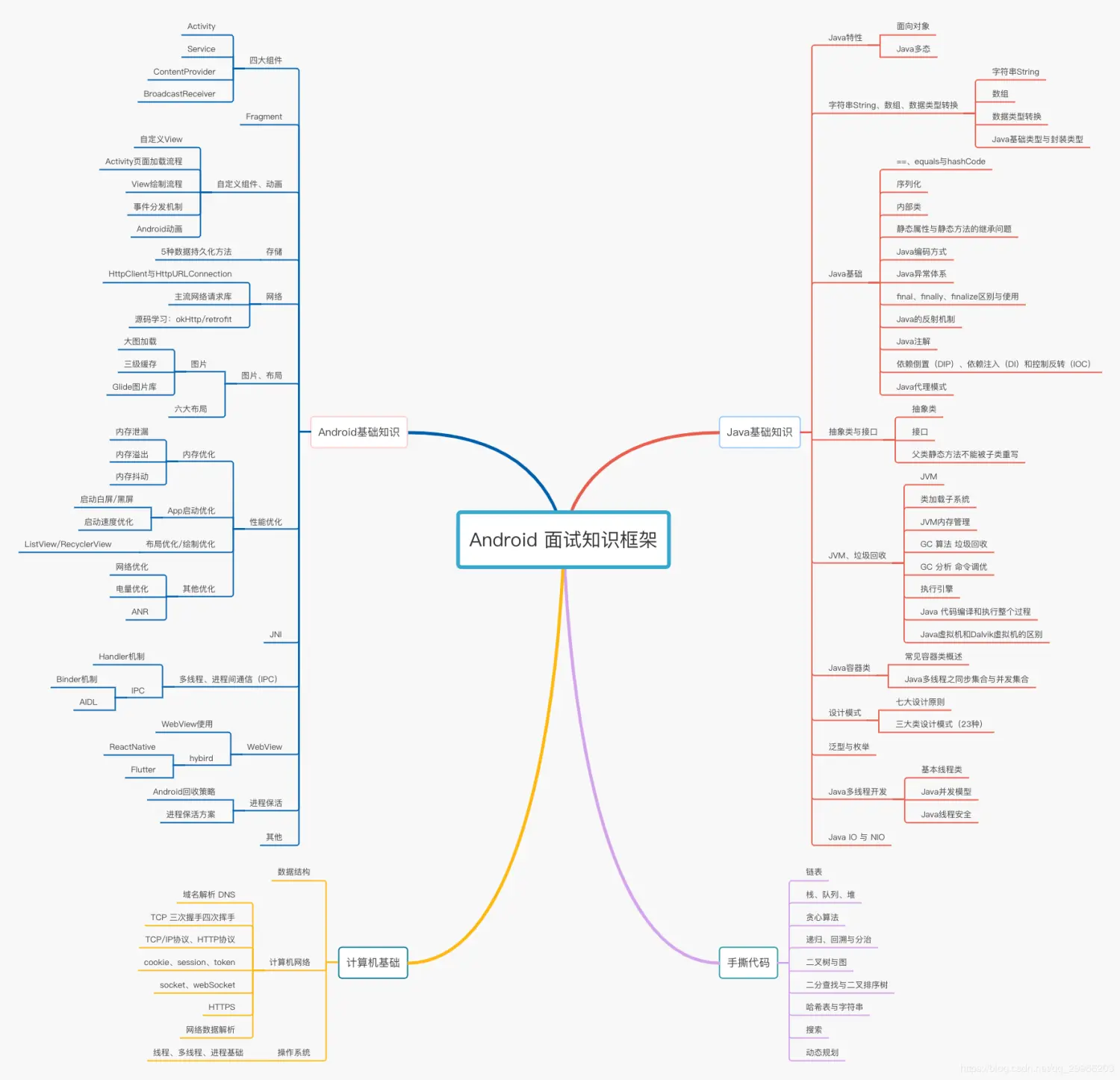

一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
id面试知识体系」学习思维导图压缩包**
[外链图片转存中…(img-eTts03UI-1712412172424)]
[外链图片转存中…(img-L9bnDHCk-1712412172425)]
[外链图片转存中…(img-LULUdoue-1712412172425)]
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算


















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









