







 该文章探讨了如何在时间演变的图中预测通信网络和交通网络中的路径是否畅通。提出了LRGCN(局部递归图卷积网络)和SAPE(自注意力路径嵌入)方法,LRGCN处理时间和空间相关性,SAPE解决任意长度道路的表示问题。在两个数据集上,模型表现优越,尤其在道路分类任务上达到了最先进的效果。
该文章探讨了如何在时间演变的图中预测通信网络和交通网络中的路径是否畅通。提出了LRGCN(局部递归图卷积网络)和SAPE(自注意力路径嵌入)方法,LRGCN处理时间和空间相关性,SAPE解决任意长度道路的表示问题。在两个数据集上,模型表现优越,尤其在道路分类任务上达到了最先进的效果。
刚接触这个领域,做一些论文笔记 日后汇报、写毕业论文都会用到。如果文章中有理解错误的地方,大家可以一起讨论
摘要
主要是通过利用随时间变化的图,动态的捕捉数据之间的空间依赖性,解决通讯网络与交通网络中路径2分类问题——畅通/堵塞。模型上使用LRGCN与SAPE,其中LRGCN模块主要用来处理数据时间上和空间上的关联性,SAPE(self-attentive path embedding),用于解决不定长道路表示问题,用SAPE方法综合考虑了道路上节点权重问题,并且可以表示任意长的道路。
背景介绍
通讯网络:
-
图的组成:节点为交换机,边是连接交换机的光纤
-
图发生变化的原因:硬件故障导致的链路失效
交通网络:
-
图的构成:节点是传感器(如摄像头),边就是路段
-
图发生变化的原因:自然灾害/事故导致的道路封闭
前人工作:
以往的随时间变化图关注的都是节点分类任务,没有用到道路分类任务上;
任务的挑战:
- 复杂的时间依赖性和结构的动态变化
- 节点观测值的非静态性:季节上的周期性、当天的周期性(早高峰、晚高峰之类的)
- 图结构变化:非常突然的交通事故,同时会伴随着节点上观测值的剧烈变化,如何捕捉这种剧烈的变化对于道路分类任务十分重要
- 道路的长度是任意性的,一条道路可能包含2个路段,也可能包含50个路段。如何统一的表示任意长的道路
主要贡献:
- 第一个研究基于时间演化图的道路分类问题,提出的LRGCN达到了SOTA的效果
- 设计了一种道路表示方法self-attentive path embedding method called SAPE:
- 可以表示任意长度的道路
- 通过自注意力机制学习道路中重要的节点,融入到道路表示中。
- 在两个数据集通讯网络和加利福尼亚州交通数据上,以Macro-F1为评价指标验证了模型优于对比的算法
问题定义:
- 节点集合
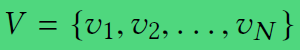
- 表示在时刻t时邻接矩阵的情况(有向图)
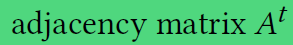
-
特征表示,时刻t时 各个节点特征
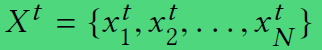
-
序列图"快照"表示:
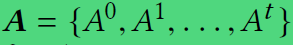
path表示:
一系列节点的组合
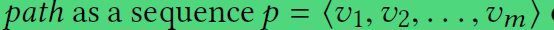
时刻t下,道路节点对应的观测值
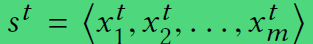
道路 available or not
通讯网络中,不一定是光纤被挖断了这种情况path才不可用,如果服务质量太差也会被认定为不可用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









