




Reliability, Availability, and Serviceability (RAS), for A-profile architecture
源自 https://developer.arm.com/documentation/102105/latest/
1 Introduction to RAS
1.1 Faults,Errors,and failures
三个概念的区分:
• A failure is the event of deviation from correct service. This includes data corruption, data loss, and service loss.
• An error is the deviation from correct service. An incorrect value that has an error is corrupt.
• A fault is the cause of the error.
There are many sources of faults in a system, including both software and hardware faults:
• Hardware faults originate in, or affect, hardware.
• Software faults affect software, that is programs or data.
The RAS Extension and RAS System Architecture primarily address errors produced from hardware faults. These fall into two main areas:
• 1. Transient faults.
• 2. Non-transient or persistent faults.
1.2 General taxonomy of errors(错误分类)
1.2.1 Error detection
When a component accesses memory or other state, an error might be detected in that memory or state.
The error might be corrected or deferred by the component, or signaled to another component as either a deferred error or a detected error.
1.2.2 Error propagation
An error is propagated by deviations from correct service, including when any of the following occurs that would not have been permitted to occur had the fault not been activated:
1)错误传播的场景有如下:
• 1. A corrupt value is passed from producer to consumer.
一个损坏的值从生产者传递给消费者
• 2. A transaction or other operation occurs that should not have occurred.
发生了不应该发生的事务或其他操作
• 3. A transaction or other operation that should have occurred does not occur.
本应发生的事务处理或其他操作没有发生
• 4. A loss of uniprocessor semantics or any other loss of coherency in a multiprocessor coherent system is observed.
多核处理器系统中有一致性损失的行为
• 5. Changing the timing and/or order of transactions or other operations such that the timing and/or order of those transactions or operations is incorrect. In this case, the service interface defines acceptable timings and/or orders for transactions and other operations.
改变了 timing 或者 transactions 的顺序
An error is silently propagated by the producer of a transaction if the consumer of the transaction cannot detect the error and consumes an undetected error because of the transaction. This might be because of one of the following:
2)错误被 Producer 静默传播的原因有如下:
• 1. The error is present on the transaction, but was not detected by the producer. The error is silently propagated by the producer.
Transaction中存在该错误,但生产者没有检测到该错误,错误由生产者无声地传播
• 2. The error is present on the transaction, but was not signaled to the consumer as an error. For example, a corrupt value was passed in the transaction with no indication that it was corrupt. The error is silently propagated by the producer.
该错误存在于事务中,但没有将其作为错误的信号发送给消费者。例如,在事务中传递了一个损坏的值,但没有显示它已损坏。错误由生产者无声地传播。
如上两者的差别是,第一种是 Producer 也检测不出来,所以传播下去了;另一种是 Producer 没有做错误标记给到 Consumer 传播了下去。
Errors might be propagated by components in a system until one of the following occurs:
3)错误可能由系统中的组件传播,直到发生以下情况之一为止
• They are masked and do not affect the outcome of the system.
The error might be masked because a corrupt value is discarded or overwritten, or the error is detected and removed.
它们被 Masked 了,并且不会影响系统的结果,错误可能被丢弃或覆盖,或者错误被检测并删除。
• They affect the service interface of the system and possibly cause failure. If the error has been silently propagated to the service interface then:
– This is a Silent Data Corruption (SDC).
– The rate of such failures, measured as the number of failures per billion device-hours of operation, is called the SDC Failure-in-Time (FIT) rate.
Alternatively, the error might have been detected, causing the system to invoke error handling and recovery.
它们会影响系统的服务接口,并有可能导致故障。如果错误已静默传播到服务接口,则:
– 这是静默数据损坏(SDC, Silent Data Corruption)
– 这种故障率,以每十亿个设备运行小时的故障数来衡量,称为SDC实时故障(FIT,Failure-in-Time)率
1.2.3 Infected and poisoned
The state of a component becomes infected when the component consumes an uncorrected error that updates
the state.
当组件使用一个更新状态的未更正错误时,该组件的状态将受到感染
A value is poisoned in the state of a component if it is marked as being in error, such that a subsequent access of
the state will detect the value is so marked and is treated as a detected error.
如果一个值被标记为错误,则它在组件状态下poisoned,这样该状态的后续访问将检测到该值被标记并被视为检测到的错误
Poison is used to defer an error.
Poison 是用来延缓错误的
1.2.4 Containable and uncontainable(可控制和不可控制)
An undetected error is uncontained at the component that failed to detect it.
未检测到的错误对于未能检测到它的组件而言是 不可控制的
A silently propagated error is uncontained at the component that silently propagated it.
静默传播的错误是 不可控制的
A detected uncorrected error is uncontainable at the component if it might be uncontained at the component.
检测到不可纠正的错误,对于组件来说也是不可控制的
A detected uncorrected error is containable at the component if it is not uncontainable at the component. If
the component cannot determine whether a detected uncorrected error is uncontainable or containable at the
component, then the component treats the detected uncorrected error as uncontainable at the component.
An error that is uncontainable at a component might be containable at the system level.
组件上无法控制的错误可能在系统级别上控制
Note:
Reporting an error as containable allows software to contain the error. This does not mean that hardware has
contained the error
报告一个可包含的错误允许软件包含该错误。这并不意味着硬件已经包含了这个错误
1.3 Techniques for improving reliability, availability, and serviceability
1.3.1 Fault prevention and fault removal(故障预防和故障排除)
Fault prevention and fault removal are two techniques for handling faults. Fault prevention and fault removal
mechanisms are IMPLEMENTATION DEFINED.
Fault prevention techniques are outside the scope of the architecture.
故障预防技术超出了体系结构的范围
A fault that is removed is a corrected error and might be recorded and generate a fault handling interrupt, but it
is not propagated. This means that it is not consumed and does not cause service failure.
故障排除 – 举例:一个纠正的错误,可能被记录并产生一个故障处理中断,但它没有传播。这意味着它没有被使用,也不会导致服务失败
A common technique to detect and correct errors is the use of an Error Detection and Correction Code (EDAC),
more commonly referred to as simply an Error Correction Code (ECC). ECC schemes use mathematical codes
to detect and correct an error in a value in memory. The size of the value is the protection granule for the ECC
scheme.
检测和纠正错误的一种常见技术是使用错误检测和校正代码(EDAC),这通常被称为简单的错误校正代码(ECC)。ECC方案使用数学代码来检测和纠正内存中的一个值中的错误。该值的大小为ECC方案的保护颗粒。
The RAS Extension and RAS System Architecture do not require implementation any fault removal schemes,
including ECC
RAS扩展和RAS系统体系结构不需要实现任何故障消除方案,包括ECC
1.3.2 Error handling and recovery(错误处理和恢复)
A fault that is not removed gives rise to an uncorrected error.
未消除的故障会导致不纠正的错误(1bit ECC积累成 2bit ECC错误)
Error recovery is the process by which software and hardware minimize the impact of an uncorrected error.
错误恢复是指软件和硬件尽量减少未纠正错误的影响的过程
Error recovery methods include:
错误恢复方法包括:
• Deferring an error from a fault. An error is deferred by hardware if hardware can make forward progress
without consuming the error. Deferring the error means(延迟错误意味着):
– 1. The fault might become masked later (fault removal). For example, because the corrupt value is
overwritten before it is consumed.
故障可能稍后masked(故障排除),例如,因为损坏的值在 consumed 之前被 Overwritten
– If the deferred error is later consumed, then the error is reported at the point of consumption. For
example, if the deferred error is consumed by a Processing element (PE) then the consumer PE
generates an error exception. This can give better results in terms of error recovery in the case where
the original producer of the data is not known when the error was deferred. For example because a
latent error was detected.
如果稍后 Consumed 了延迟错误,则会在消耗点报告该错误。
例如,如果延迟错误被处理元素(PE)消耗,则消费者PE将生成一个错误异常。
在错误被延迟时不知道数据的原始生产者的情况下,这可以在错误恢复方面提供更好的结果。例如,因为检测到了一个潜在的错误
A common technique to defer an error is to replace the corrupt value with a poisoned value, for example in
memory or in a transaction.
延迟错误的一种常见技术是用 poisoned 的值替换损坏的值,例如在内存或 transaction 中。
• Preventing further propagation of the error, that is containing the error. In particular, preventing silent
propagation of the error.
防止错误的进一步传播,即包含该错误。特别是,防止错误的无声传播
• Reducing the severity of a failure by invoking a service failure mode:
– This is a Detected Uncorrected Error (DUE).
– The rate of such failures gives the DUE FIT rate.
– The type of service failure mode depends on what is acceptable to the service.
A software error recovery agent is typically invoked when hardware detects an error it cannot correct, defer, or
remove.
当硬件检测到一个无法纠正、延迟或删除的错误时,通常会调用软件错误恢复代理
An error recovery agent also provides information to the operator through error logs to improve serviceability,
for example to help with the identification of a Field Replaceable Unit (FRU).
错误恢复代理还通过错误日志向操作员提供信息,以提高可服务性,例如,帮助识别现场可替换单元(FRU)。
The RAS Extension and RAS System Architecture provide optional common programmers’ models to record
information about an error in an error record.
RAS扩展和RAS系统体系结构提供了可选的通用程序员模型,以记录错误记录中有关错误的信息。
The RAS Extension describes the behavior of a PE when an error is signaled to it by the system, including
invoking a service failure mode by taking an error exception, and optional mechanisms to limit propagation of
an error.
RAS扩展描述了当系统向错误发出信号时PE的行为,包括通过采取错误异常调用服务失败模式,以及限制错误传播的可选机制。
The RAS Extension and RAS System Architecture do not require systems to implement error recovery
mechanisms, including poison, and do not require systems to limit the silent propagation of errors.
RAS扩展机制和RAS系统体系结构不要求系统实现错误恢复机制,包括毒药机制,也不要求系统限制错误的静默传播。
1.3.3 Fault handling
Fault handling by software is the process by which software diagnoses and responds to faults to improve
availability.
软件故障处理是指软件诊断故障并响应故障以提高可用性的过程
Fault handling methods include:
故障处理方法包括
• 1. Predictive Failure Analysis (PFA), using information recorded by hardware to trigger pre-emptive action.
预测性故障分析(PFA),使用硬件记录的信息来触发先发制人的行动
The RAS Extension and RAS System Architecture provide optional mechanisms to allow the reporting of errors
and warnings to a fault handling agent, and to record information about the fault in an error record. It is the
responsibility of the error recovery and fault handling processes to collate the error record data and write it to an
error log.
RAS扩展和RAS系统体系结构提供了可选的机制,以允许向错误处理代理报告错误和警告,并在错误记录中记录有关错误的信息。错误恢复和错误处理过程的责任是整理错误记录数据,并将其写入错误日志
The detailed nature of the fault handling agent is outside the scope of this architecture. Fault handling and error
recovery might be independent agents
故障处理代理的详细性质超出了此体系结构的范围。故障处理和错误恢复可能是独立的代理
2 RAS Extension for A-profile
2.1 PE error handling
2.1.1 PE error detection
When a PE accesses memory or other state, an error might be detected in that memory or state, and corrected,
deferred, or signaled to the PE as a detected error with an in-band error response.
当PE访问内存或其他状态时,可能在该内存或状态中检测到错误,并通过带内错误响应纠正、延迟或信号给PE
When an error is detected by a component on a read or a cache maintenance operation from the PE:
1)当组件在从PE执行读取或高速缓存维护操作时检测到错误时:
– 1. If the error can be corrected, it is corrected and corrected data is returned.
如果错误可以纠正,则被纠正并返回纠正后的数据
– 2. If the error cannot be corrected and can be deferred, it is deferred. For example, on a load by poisoning
the PE state, if this is supported by the PE implementation.
如果错误不能纠正且可以延迟,则会延迟;例如,在一个负载上,如果PE实现支持它,则通过 Poisoning PE状态
– If the error cannot be corrected and if implemented and enabled at the component, the detected error
is signaled to the PE as an in-band error response.
如果错误无法被纠正,如果在组件上实现和启用,检测到的错误将作为带内错误响应发送给PE
When an error is detected by a component consuming a write from the PE:
2)当使用从PE写入的组件检测到错误时:
– If the error can be corrected, it is corrected.
如果这个错误可以纠正,它就可以纠正
– If the error cannot be corrected and can be deferred, it is deferred to the consumer. For example, by
poisoning the location being written.
如果错误不能被纠正,并且可以延迟,则会延迟给消费者。例如,通过 Poisoning 到被写入的位置
– If the error cannot be corrected and if implemented and enabled at the component, the detected error
is signaled to the PE as an in-band error response.
如果错误无法被纠正,如果在组件上实现和启用,检测到的错误将作为带内错误响应发送给PE
2.1.2 PE error propagation
The program-visible architectural state of the PE, referred to as the PE state, includes:
• General-purpose, SIMD&FP, and SVE registers.
• System registers.
• Special-purpose registers.
• PSTATE.
An error is consumed by the PE by any of the following:
1)PE被以下任何一个项一个错误 Consumed:
• 1. An instruction commits the corruption into the PE state.
指令会将损坏提交到PE状态
• 2. The error is on an instruction fetch and the corrupt instruction is committed for execution.
错误在指令获取上,损坏的指令被提交执行
• 3. The error is on a translation table walk for a committed load, store, or instruction fetch.
错误已经位于提交加载、存储或指令获取的转换表中
An error is propagated by the PE by one or more of the following occurring that would not have been permitted
to occur had the fault not been activated:
2)PE通过以下一个或多个事件传播错误,如果故障没有被激活,就不允许发生这些错误:
• Consumption of the corrupt value by any instruction, propagating the error to the target(s) of the instruction.
This includes:
通过任何指令 Consumered 损坏的值,将错误传播到指令的目标值,这包括:
– A store of a corrupt value.
一个损坏值的写
– A write of a corrupt value to a System register, Special-purpose register, or PSTATE. Infecting a
System register state might mean that the PE generates transactions that would not otherwise be
permitted.
一个写,到了系统寄存器、特殊用途寄存器或PSTATE的损坏值。感染系统注册状态可能意味着PE生成以其他方式不被允许的 transaction
• Any operation occurring that should not have occurred, including:
任何不应该发生的操作,包括:
– 1. A load, translation table walk, or instruction fetch that would not have been permitted, including those
from hardware speculation or prefetching.
不允许的加载、转换表行走或指令获取,包括那些来自硬件猜测或预取的获取
– 2. A store to an incorrect address, or a store that would not have been made or not permitted.
地址错误的写,或者不会创建或不允许的写
– 3. A direct or indirect write to a Special-purpose or System register that would not have been made or
not permitted.
直接或间接写入特殊目的或系统寄存器的文件,不允许或不允许
– 4. Assertion of any signal, such as an interrupt, that would not have been asserted.
对不会被断言的任何信号,如中断的断言
• Any operation not occurring that should have occurred.
任何没有发生的本应该发生的操作。
• Causing the PE to take an imprecise exception, other than an error exception in response to the error itself.
See the section Definition of a precise exception in the Arm® Architecture Reference Manual, for A-profile
architecture.
导致PE采取不精确的异常,而不是响应错误本身的错误异常
• The PE discarding data that it holds in a modified state.
PE丢弃它在修改状态下保存的数据
• Any other loss of required uniprocessor semantics, ordering, or coherency
所需的单处理器语义、顺序或一致性的任何其他损失
An error propagated by the PE is silently propagated by the PE only if all of the following are true:
只有当以下所有错误均为真时,PE传播的错误才会由PE静默传播:
-
The propagation is not part of the required operation of the PE in taking an error exception generated by
the error.
该传播不是PE在接受由该错误产生的错误异常时所需的操作的一部分。 -
The propagation is not part of the required operation of the PE executing an ESB instruction that
synchronizes the error.
传播不是PE执行同步错误的ESB指令所需操作的一部分 -
The error is not signaled to the consumer as a detected error or deferred error.
该错误不会作为检测到的错误或延迟错误发送给使用者 -
Any of the following are true:
• The corrupt value is held in other than the general-purpose, SIMD&FP, or SVE registers.
损坏值保存在 general-purpose、SIMD&FP或SVE寄存器中
• The error is propagated by an instruction in program order before either taking an error exception
generated by the error or executing an ESB instruction that synchronizes the error, and is propagated
to outside of the general-purpose, SIMD&FP, or SVE registers
在错误接受由错误产生的错误异常或执行同步错误的ESB指令之前,错误通过程序顺序的指令传播,并传播到通用、SIMD&FP或SVE寄存器之外
• The error is propagated other than by an instruction that consumes the corrupt value as an input
operand but otherwise behaves correctly.
错误的传播方式不是指令将损坏的值作为输入操作数,但其他指令行为正确
2.1.3 Other errors

RAS扩展主要处理PE之外的组件检测到的错误,比如内存,以及PE消耗的错误。在实现PE的处理器内可能会检测到其他错误。如果该错误不是PE状态下的错误,则该错误可能被视为另一个组件检测到的错误。
In the following examples, the component reports these errors to a RAS System Architecture node that
implements error records and records the errors, and might generate one or more of a fault handling interrupt,
error recovery interrupt, or critical error interrupt depending on the features and configuration of the node.
Example
A processor cache can be treated as a component outside the PE.
The cache detects an error in the cache state that cannot be corrected:
• 1) If the error is detected in dirty cache data being evicted from the cache when the PE makes an access,
then the error might be deferred by the cache writing poison in the evicted cache data.
• 2) If the PE is performing a partial write that does not completely overwrite the protection granule,
then the error might be deferred by the cache writing poison to the cache location, and/or evicting
the cache line with poison. Deferring the error means the error is not consumed by the PE.
Otherwise, the cache component generates the in-band error response to the PE
处理器高速缓存可以被视为PE之外的组件。
缓存检测到在缓存状态中存在无法纠正的错误:
- 如果在PE访问 evicted 的 dirty cache 数据中检测到错误,此时,该 error might be deferred writing poison in the evicted cache data.;
- 如果PE正在执行一个Partial Write,该错误可能会被延迟 writing poison 到缓存位置, 延迟该错误意味着PE没有消耗该错误
**否则,缓存组件将生成对PE的 in-band error response **
Example
A processor’s interface to memory can be treated as a component outside the PE.
A processor detects a corrupt or poisoned value being returned on the interface that is not being signaled
as an in-band error response and cannot be corrected or deferred. For example in response to an
non-cacheable read or a cache refill.
The memory interface component generates the in-band error response to the PE
处理器与内存的接口可以被视为PE之外的组件。
处理器检测到接口上返回的损坏或中毒值,该值未被指示为带内错误响应,且无法纠正或延迟。例如,in response to an non-cacheable read or a cache refill。
内存接口组件生成对PE的带内错误响应
2.2 Generating error exceptions
An error exception is generated when a detected error is signaled to the PE as an in-band error response
to an architecturally-executed memory access or cache maintenance operation. This includes any explicit
data access, instruction fetch, translation table walk, or hardware update to the translation tables made by an
architecturally-executed instruction
当检测到的错误作为对架构执行的内存访问或缓存维护操作的带内错误响应发送给PE时,将产生错误异常。这包括对由架构上执行的指令生成的转换表的任何显式数据访问、指令获取、转换表行走或硬件更新
An error exception is taken as an asynchronous SError interrupt, a synchronous External Data Abort exception,
or a synchronous External Instruction Abort exception.
错误异常被视为异步错误中断、同步外部数据中止异常或同步外部指令中止异常。
2.3 Taking error exceptions
If FEAT_DoubleFault is implemented, then an error exception is taken as a synchronous External abort exception
for all non-speculative:
• Instruction fetches.
• Translation table walks and hardware updates of translation tables on instruction fetches.
如果实现了FEAT_DoubleFault,那么一个错误异常将被视为所有非投机性的:指令获取的同步外部中止异常。•翻译表行走和指令获取时翻译表的硬件更新。
2.3.1 PE error state recording in the exception syndrome

• Uncontainable(UC).
• Unrecoverable state(UEU).
• Recoverable state (UER).
• Recoverable state (UER).
• Restartable state (UEO).
• Corrected (CE).
• Uncategorized error.
• IMPLEMENTATION DEFINED syndrome.
2.3.2 PE error state classification
The recorded PE error state is defined by the rules in this section.
Uncontainable (UC) – 无法控制的:
If and only if all of the following are true, then on taking an error exception the PE error state is recorded as
Uncontainable (UC):
• One or more of the following are true:
– The error has been silently propagated by the PE.
– The PE determines that software is not able to recover execution from the preferred return address of
the exception and the error is not synchronized by Error synchronization events.
– The PE determines that software is not able to recover execution from the preferred return address
of the exception and the error exception is taken as a synchronous External abort to AArch64 state.
(That is, the type of error exception does not support reporting the PE error state as Unrecoverable
state (UEU).)
– The implementation has elected to record the PE error state as Uncontainable (UC).
• The error exception is not taken as a synchronous External abort to AArch32 state.
• The implementation has not elected to record the PE error state as IMPLEMENTATION DEFINED syndrome
or Uncategorized error, or the type of error exception does not support reporting the PE error state as
IMPLEMENTATION DEFINED syndrome or Uncategorized error
如果且仅当以下所有错误均为true,则在发生错误异常时,PE错误状态被记录为不可包含(UC):
- 以下一个或多个为true:
a. -该错误已由PE静默传播。
b. -PE确定软件无法从异常的首选返回地址恢复执行,并且该错误没有被错误同步事件同步。
c. -PE确定软件无法从异常的首选返回地址恢复执行,并且错误异常被视为同步外部中止到AArch64状态。(也就是说,错误异常的类型不支持将PE错误状态报告为不可恢复状态(UEU)。)
d. –实现已选择将PE错误状态记录为不可控制(UC)。- 该错误异常不被视为对AArch32状态的同步外部中止。
- 实现没有选择将PE错误状态记录为实现定义综合征或未分类错误,或者错误异常的类型不支持将PE错误状态报告为实现定义综合征或未分类的错误。
Unrecoverable state (UEU) – 不可恢复状态:
• The error has not been silently propagated by the PE.
• The error exception is taken as an SError interrupt exception.
• One or more of the following are true:
– The PE determines that software is not able to recover execution from the preferred return address of
the exception and the error is synchronized by Error synchronization events.
– The implementation has elected to record the PE error state as Unrecoverable state (UEU).
• The implementation has not elected to record the PE error state as Uncontainable (UC), IMPLEMENTATION
DEFINED syndrome, or Uncategorized error
如果且仅当以下所有数项都为真,那么在出现错误异常时,PE错误状态被记录为不可恢复状态(UEU):
- •PE没有无声默传播错误。
- •该错误异常被视为一个错误中断异常(an SError interrupt exception.)
- •以下一个或多个为真:
-PE确定软件无法从异常的首选返回地址恢复执行,并且错误通过错误同步事件进行同步。
-实现已选择将PE错误状态记录为不可恢复状态(UEU)。- •实现没有选择将PE错误状态记录为不可控制(UC)、实现定义综合征或未分类错误
Recoverable state (UER) – 可恢复状态
• The error has not been silently propagated by the PE.
• The error exception is not taken as a synchronous External abort to AArch32 state.
• The PE determines that software is able to recover execution from the preferred return address of the
exception.
• One or more of the following are true:
– The PE determines that software must take action to locate and repair the error to successfully
recover execution. This might be because the exception was taken before the error was architecturally
consumed by the PE, at the point when the PE was not be able to make correct progress without either
consuming the error or otherwise making the state of the PE unrecoverable.
– The implementation has elected to record the PE error state as Recoverable state (UER).
• The implementation has not elected to record the PE error state as Unrecoverable state (UEU),
Uncontainable (UC), IMPLEMENTATION DEFINED syndrome, or Uncategorized error.
如果且仅当以下所有数项都为真,那么在出现错误异常时,PE错误状态被记录为可恢复状态(UER):
•1)该错误没有被PE静默传播。
•2)该错误异常不被视为对AArch32状态的同步外部中止。
•3)PE确定软件能够从异常的首选返回地址恢复执行。
•以下一个或多个为真:
a. -PE确定软件必须采取行动来定位并修复错误,才能成功恢复执行。这可能是因为该异常是在PE在架构上被错误占用之前发生的,此时PE无法在不消耗错误或使PE的状态不可恢复的情况下取得正确的进展。
b. –实现已选择将PE错误状态记录为可恢复状态(UER)。•实现没有选择将PE错误状态记录为不可恢复状态(UEU)、不可控制状态(UC)、实现定义综合征或未分类错误。
Restartable state (UEO) – 可重启状态:
If and only if all of the following are true, then on taking an error exception the PE error state is recorded as
Restartable state (UEO):
• The error has not been silently propagated by the PE.
• The error exception is not taken as a synchronous External abort to AArch32 state.
• The PE determines that software can recover execution from the preferred return address of the exception
without the need for software to take action to locate and repair the error first.
• One or more of the following are true:
– The error is an uncorrected error. This includes a deferred error.
– The error is a corrected error and the error exception is not taken as an SError interrupt taken to
AArch64 state.
– The implementation has elected to record the PE error state as Restartable state (UEO).
• The implementation has not elected to record the PE error state as any of Recoverable state
(UER), Unrecoverable state (UEU), Uncontainable (UC), IMPLEMENTATION DEFINED syndrome, or
Uncategorized error.
如果且仅当以下所有数项都为真,那么在发生错误异常时,PE错误状态被记录为可重启状态(UEO):
1)•该错误没有被PE静默传播。
2)•该错误异常不被视为对AArch32状态的同步外部中止。
3)•PE确定软件可以从异常的首选返回地址恢复执行,而不需要软件采取行动首先查找和修复错误。
4)•以下一个或多个为真:
a.-该错误为未更正的错误。这包括一个被延迟的错误。
b.–该错误是一个纠正的错误,该错误异常不被视为一个错误中断采取到AArch64状态。
c.–实现已选择将PE错误状态记录为可重启状态(UEO)。
5) •实现没有选择将PE错误状态记录为可恢复状态(UER)、不可恢复状态(UEU)、不可控制(UC)、实现定义综合征或未分类的错误。
Corrected (CE)–可纠正错误:
• The error has been corrected and not silently propagated by the PE.
• The error exception is taken as an SError interrupt taken to AArch64 state.
• Software can recover execution from the preferred return address of the exception. Because the error has
been corrected, software does not need to take action to locate and repair the error.
• The implementation has not elected to record the PE error state as any other type
如果且仅当以下所有错误都为真,则在采取错误异常时,PE错误状态被记录为纠正(CE):
- •错误已被纠正,并没有由PE无声地传播。
- •错误异常被视为处于AArch64状态的错误中断。
- •软件可以从异常的首选返回地址恢复执行。由于该错误已被纠正,因此软件不需要采取行动来定位和修复该错误。
- •实现没有选择将PE错误状态记录为任何其他类型。
Uncategorized error:
• The error exception is taken as an asynchronous SError interrupt taken to AArch64 state.
• The implementation has elected to record the PE error state as an Uncategorized error
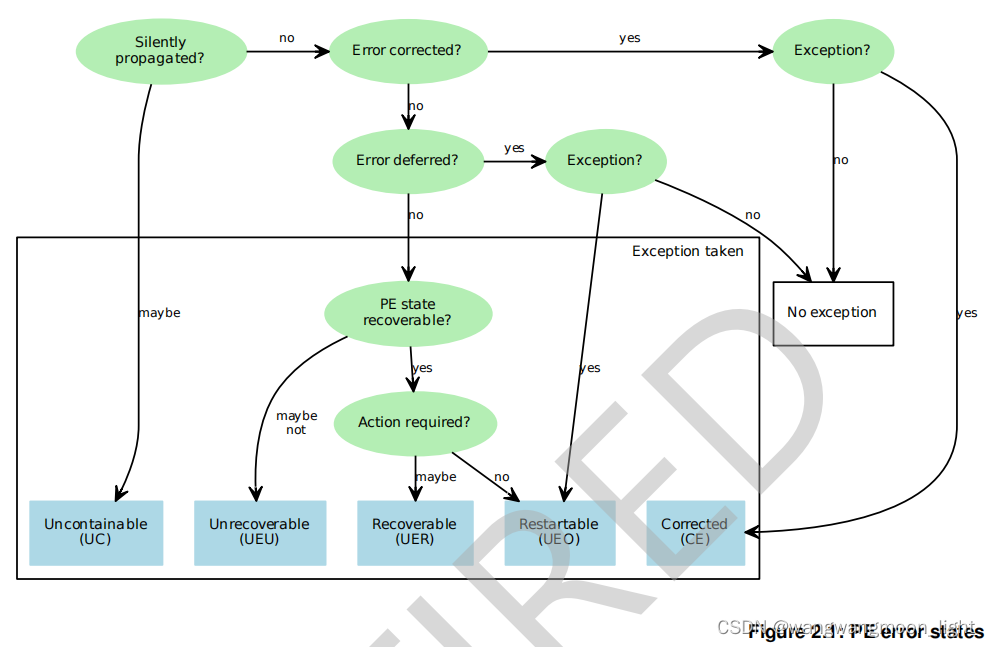
2.3.2.1 Using the PE error state classification – 2024.03.24
Multiple physical and/or virtual SError interrupt conditions might be pending together. The architecture does not define relative priorities for asynchronous exceptions
多个物理和/或虚拟错误中断条件可能一起挂起,该体系结构没有定义异步异常的相对优先级。
2.3.3 Multiple SError interrupts
2.3.4 Target Exception level for External abort and SError interrupt exceptions taken to
AArch64 state
2.3.5 Target mode for External abort and SError interrupt exceptions taken to AArch32 state
2.4 Error synchronization event
The RAS Extension defines the Error synchronization event and the ESB instruction.
2.4.1 ESB and Virtual SError interrupt exceptions
2.4.2 Extension for synchronization at exception entry and return
2.4.3 Error synchronization barriers in a minimal implementation
2.5 Virtual SError interrupts
2.6 Error records in the PE
When an error is recorded by a PE node, one or more of the following might be generated, according to the configuration of the node:
• A fault handling interrupt.
• An error recovery interrupt.
• A critical error interrupt.
• An in-band error response
当一个PE节点记录了一个错误时,可能会根据该节点的配置,生成以下一个或多个错误:
•一个故障处理中断
•一个错误恢复中断
•一个严重的错误中断
•一个带内错误响应
3 RAS System Architecture
RAS系统架构为一个节点定义了以下特性:
Error detection and correction
The level of error correction and detection implemented at a component is IMPLEMENTATION DEFINED.
A node might include the control to disable error reporting and recording of detected errors, for example
while software initializes the component.
It is IMPLEMENTATION DEFINED whether error detection and correction is fully disabled at the component when reporting and recording are disabled at the node.
在组件上实现的错误校正和检测的级别被定义了实现。节点可能包括禁用错误报告和记录检测到的错误的控件,例如在软件初始化组件时。该实现定义了在节点上禁用报告和记录时,是否在组件上完全禁用错误检测和纠正。
Fault handling interrupt
Asynchronous reporting of all or some recorded errors by an interrupt, that is, Corrected errors, Deferred
errors, and Uncorrected errors. It is IMPLEMENTATION DEFINED whether a node provides a single control for all errors, or a first control for Corrected errors and a second control for all other detected errors.
通过中断异步报告所有或一些已记录的错误,即已纠正错误、延迟错误和未纠正错误。它定义了节点是为所有错误提供单个控件,还是为纠正错误的第一个控件和对所有其他检测错误的第二个控件.
Corrected error counter
It is IMPLEMENTATION DEFINED whether a node implements a counter for counting errors. Software
can poll the error counter or initialize the counter with a threshold value and receive an interrupt when
the counter overflows. A counter overflows when incrementing the counter results in unsigned integer
overflow.
It is IMPLEMENTATION DEFINED which Corrected errors are counted.
It is IMPLEMENTATION DEFINED and might be UNPREDICTABLE whether Deferred errors and Uncorrected errors are counted by the Corrected error counter.
它定义了一个节点是否实现了一个计数错误的计数器。软件可以轮询错误计数器或用阈值初始化计数器,并在计数器溢出时接收一个中断。当增加计数器时,计数器溢出会导致无符号整数溢出。它是定义了计算修正错误的实现。它是定义的,是否计算延迟错误和未修正错误可能是不可预测的.
Timestamps
It is IMPLEMENTATION DEFINED whether a node records a timestamp in each error record.
In-band error response (external abort)
In-band signaling of detected uncorrected error to the Requester of the transaction. It is also referred to as an external abort.
Corrected errors and errors deferred to the Requester are not reported by such means.
Error recovery interrupt
Asynchronous (out-of-band) reporting of recorded Uncorrected errors by an interrupt. The interrupt can
be used for error recovery, fault handling, or both. Corrected errors are not reported by this means. It
is IMPLEMENTATION DEFINED whether the node provides the control to enable Deferred errors to be
reported in this way. If the control is not provided, then Deferred errors are not reported by this means.
异步(带外)报告通过中断记录的未纠正错误。该中断可用于错误恢复、故障处理,或两者兼用。不会通过此方法报告已更正的错误。它定义了节点是否提供控制来允许以这种方式报告延迟错误。如果没有提供控件,则不通过这种方式报告延迟错误。
Critical Error interrupt
Critical error interrupts provide a mechanism for a node to report a critical error condition to a system
controller for error recovery
严重错误中断为节点提供了一种机制,以便向系统控制器报告严重错误条件以进行错误恢复。
Records
A node implements one or more standard error records. When an error is detected or consumed, syndrome about the error is written to an error record.
一个节点实现了一个或多个标准的错误记录。当检测到或消耗了一个错误时,关于该错误的综合症将被写入一个错误记录。
3.1 Nodes
3.1.1 Multiple error records per node
If a single node implements multiple error records, then all of the following are true:
• The error records are indexed sequentially within a group of error records starting from the first error record for the node.
• For each error record other than the first error record for the node, the following are true:
– The ERRFR.ED field is 0b00.
– ERRFR[63:2] are RES0.
– The ERRCTLR register is RES0.
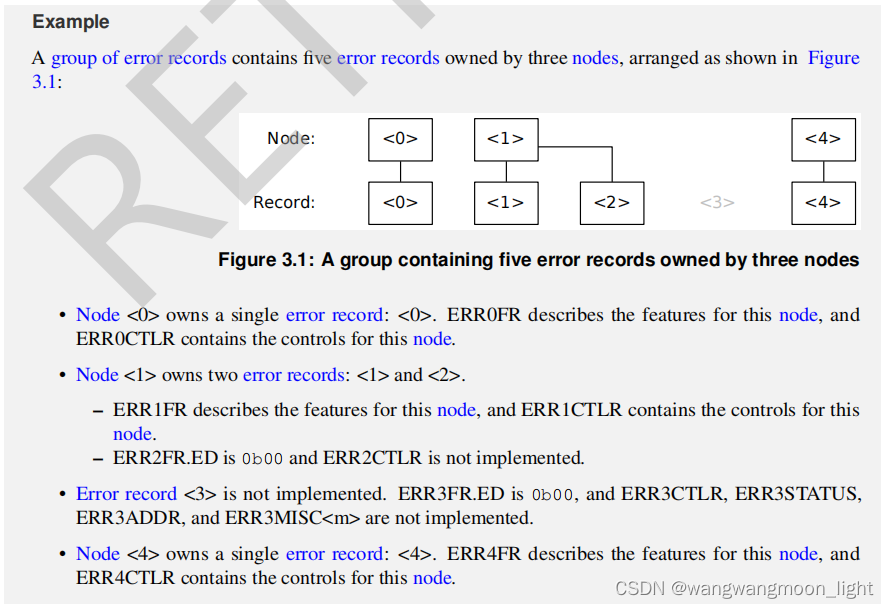
3.2 Detecting and consuming errors
A component detects an error when it detects that a deviation from correct service has occurred or will occur. For example, including but not limited to when any of the following occurs that would not be permitted to occur had the fault not been activated:
• A corrupt value has been or will be passed to a consumer.
• A transaction or other operation occurs or will occur that should not occur.
• A transaction or other operation that should occur does not occur or will not occur.
• A loss of uniprocessor semantics or any other loss of coherency in a multiprocessor coherent system is or will be observed.
• The timing and/or order of transactions or other operations has been or will be changed.
• A latent error has become or will become undetectable.
当组件检测到已发生或将发生偏离正确的服务时,它将检测到错误。例如,包括但不限于发生以下任何情况,如果故障未激活时不允许发生的情况:
• 损坏的值已经或将传递给消费者
• 已发生或将会发生不应该发生的事务或其他操作
• 不应该发生或不会发生的事务或其他操作
• 在多处理器相干系统中,将或将观察到单处理器语义的丢失或任何其他一致性的丢失
• 交易或其他操作的 timing 和/或 order。
• 一个潜在的错误已经成为或将成为无法检测到的错误
Examples of a loss of uniprocessor semantics or other loss of coherency that might occur because of an error include:
• A cache loses data that it holds in a modified state.
• A cache writes back unmodified data
由于错误而可能发生的单处理器语义丢失或其他一致性丢失的例子包括:
• 缓存丢失了它在修改状态下保存的数据
• 高速缓存会将未经修改的数据写回内存
3.3 Standard error record
The RAS System Architecture defines a standard error record and a mechanism to access error records as System registers or as a memory-mapped component.
RAS系统体系结构定义了一种标准错误记录和一种机制,以作为系统寄存器或内存映射组件访问错误记录的方式。
The standard error record contains:
• A status register, ERRSTATUS, for common status fields, such as the type and coarse characterization of the error.
• An optional address register, ERRADDR.
• IMPLEMENTATION DEFINED status registers, referred to as ERRMISC. Arm recommends these are used for:
– Identifying a FRU.
– Locating the error within the FRU.
– Optionally, a corrected error counter or counters for software to poll the rate of Corrected errors.
– Optionally, a timestamp value for when the error was recorded.
When RAS System Architecture v1.0 is implemented there are two ERRMISC for each error record:
• ERRMISC0.
• ERRMISC1.
When RAS System Architecture v1.1 is implemented there are 4 ERRMISC for each error record:
• ERRMISC0.
• ERRMISC1.
• ERRMISC2.
• ERRMISC3.
3.3.1 Component error states
For a standard error record, the component error state types that can be recorded are:
• Corrected error (CE).
• Deferred error (DE).
• Uncorrected error.
An Uncorrected error is recorded as one of the following sub-types:
• Uncontainable error (UC).
• Unrecoverable error (UEU).
• Recoverable error or Signaled error (UER).
• Restartable error or Latent error (UEO).
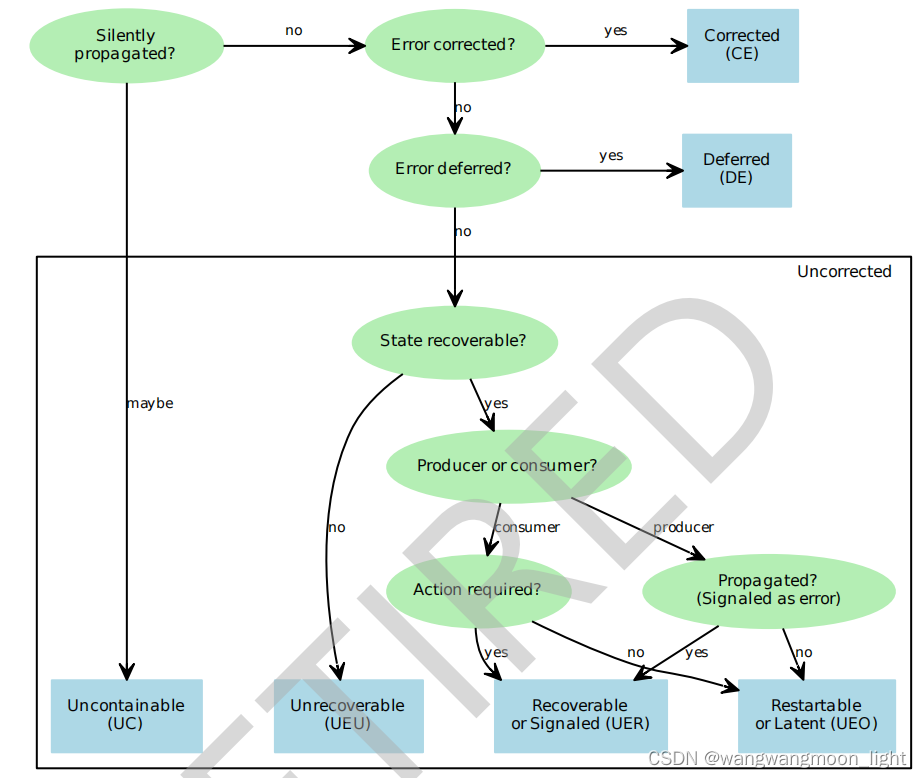
3.3.2 Writing the error record
When a new error is recorded, the node:
• Does one of the following:
– Overwrites the error record with the syndrome for the new error.
– Keeps the syndrome for the previous error
当记录新错误时,节点:执行以下操作之一:
– 使用新错误的综合征覆盖错误记录
– 保留了之前的错误的综合征
3.3.3 Error syndrome
This section provides additional information for some of the error syndrome fields defined in the standard error record.
3.3.3.1 Corrected error field
3.3.3.2 Poison indicator
If supported by a node, then when the syndrome for a Deferred error or Uncorrected error is recorded, the
ERRSTATUS.PN syndrome field is set to indicate that a poisoned value was detected.
如果有节点支持,则当记录延迟错误或未纠正错误的综合征时,ERR状态。PN综合征字段设置为表示检测到 Poison。
3.3.4 Security and Virtualization
A system might process confidential data
3.3.5 Synchronization and error record accesses
3.3.6 Bridges to other architectures
A bridge is a component that passes transactions between two domains.
3.3.7 Software faults
Examples of software faults include:
• Access to memory or peripheral register that is not present. This includes cases where physical address
spaces are physically aliased.
• Access to a peripheral that is not permitted at the completer. For example, a Non-secure access to a Secure register.
• Access to a peripheral that is in an inaccessible state or other illegal access. For example, the peripheral is powered down, or the value written is not supported.
3.4 Error recovery interrupt
If an error recovery interrupt is implemented by a node, then the set of controls for enabling error recovery
interrupts is IMPLEMENTATION DEFINED. Software uses ERRFR to determine what controls are
implemented.
3.5 Fault handling interrupt
If a fault handling interrupt is implemented by a node, then the set of controls for enabling fault handling
interrupts is IMPLEMENTATION DEFINED. Software uses ERRFR to determine what controls are
implemented.
3.6 In-band error response signaling (external aborts)
For a node , if support for in-band error response signaling, also referred to as external aborts, is implemented by the node, then the control for enabling in-band error response signaling, ERRCTLR.UE, might be implemented. Software uses ERRFR to determine what controls are implemented.
3.7 Critical error interrupt
Support for critical error conditions and critical error interrupts at a node is IMPLEMENTATION DEFINED.
Software uses ERRFR to determine what support is implemented.
3.8 Standard format Corrected error counter
The RAS System Architecture defines standard formats for a corrected error counter. Software uses ERRFR to determine whether any standard format corrected error counter is implemented by a node.
3.9 Error recovery, fault handling, and critical error signaling
Error recovery, fault handling, and critical error interrupt requests are normally routed using an interrupt
controller.
3.10 Error recovery reset
A system comprises multiple power and logical domains, each of which might implement one or more reset signals.
The RAS System Architecture defines two classes of reset:
• Cold reset resets all of the logic in a component, including RAS functionality, to a known initial state.
• Error Recovery reset resets some of the logic in the component to a known state.
However, some state is purposefully unchanged by an Error Recovery reset. Unlike Cold reset, any
recorded error syndrome information is preserved by Error Recovery reset.
3.11 Timestamp extension
The RAS Timestamp Extension is an optional part of RAS System Architecture v1.1.
For a given error record , if the RAS Timestamp Extension is implemented, the timestamp value is recorded in ERRMISC3.
3.12 Common Fault Injection Model Extension
The Common Fault Injection Model Extension is an optional part of RAS System Architecture v1.1.
公共故障注入模型扩展是RAS系统体系结构v1.1中的一个可选部分
Other fault injection mechanisms are permitted. For example, if the Common Fault Injection Model Extension is not implemented, the ERRIMPDEF registers might be used for some other IMPLEMENTATION DEFINED fault injection mechanism.
允许使用其他故障注入机构,例如,如果没有实现通用故障注入模型扩展,则删除>寄存器可能用于其他实现定义的故障注入机制。
4 RAS Extension and RAS System Architecture Registers
4.1 Memory-mapped view
The Reliability, Availability, Serviceability (RAS) System Architecture defines the following reusable formats for memory-mapped error records:
• 4.3.1.3 Memory-mapped error record group view describes a group of error records accessed via a
standard 4KB memory-mapped peripheral.
• 4.3.1.4 Memory-mapped single error record view describes a format for a memory-mapped component
that implements a single error record. This might be implemented as part of the control registers for a
memory-mapped component. In this format, the first register, ERRFR, is at an address aligned to a
multiple of 64 bytes.
The 4.3.1.4 Memory-mapped single error record view might be repeated in the control registers for a
memory-mapped component that implements a small number of error records. Each error record has its
own IMPLEMENTATION DEFINED base within the control registers of the component.
4.2 Reset values
When the node records an error in an error record, depending on the type of error being recorded, it is
IMPLEMENTATION DEFINED whether some fields are set to a zero or unchanged.
In most cases, this is because one of the following applies, and it is IMPLEMENTATION DEFINED which:
• The node sets the field to zero on Cold reset, meaning the value is not required to be changed when the
first error is recorded
• The node sets the field to zero on recording the first error after Cold reset.
To allow for either implementation, software must clear these fields to zero after logging a recorded error and performing a software reset of the error record.
4.3 Error record registers, including memory mapped view
This section describes the error record registers. The descriptions in this section apply whether the error record is accessed:
• Through the indirection mechanism described in 2.6.1 Error record System register view.
• As memory-mapped registers, as described in 4.1 Memory-mapped view.
4.3.1 Register index
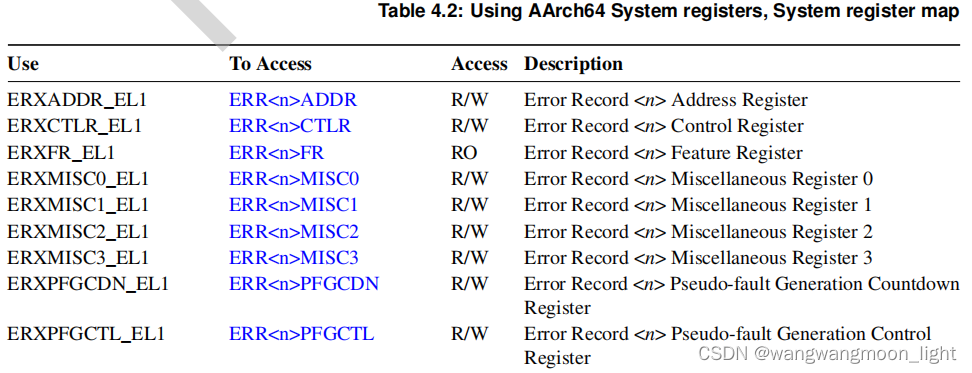
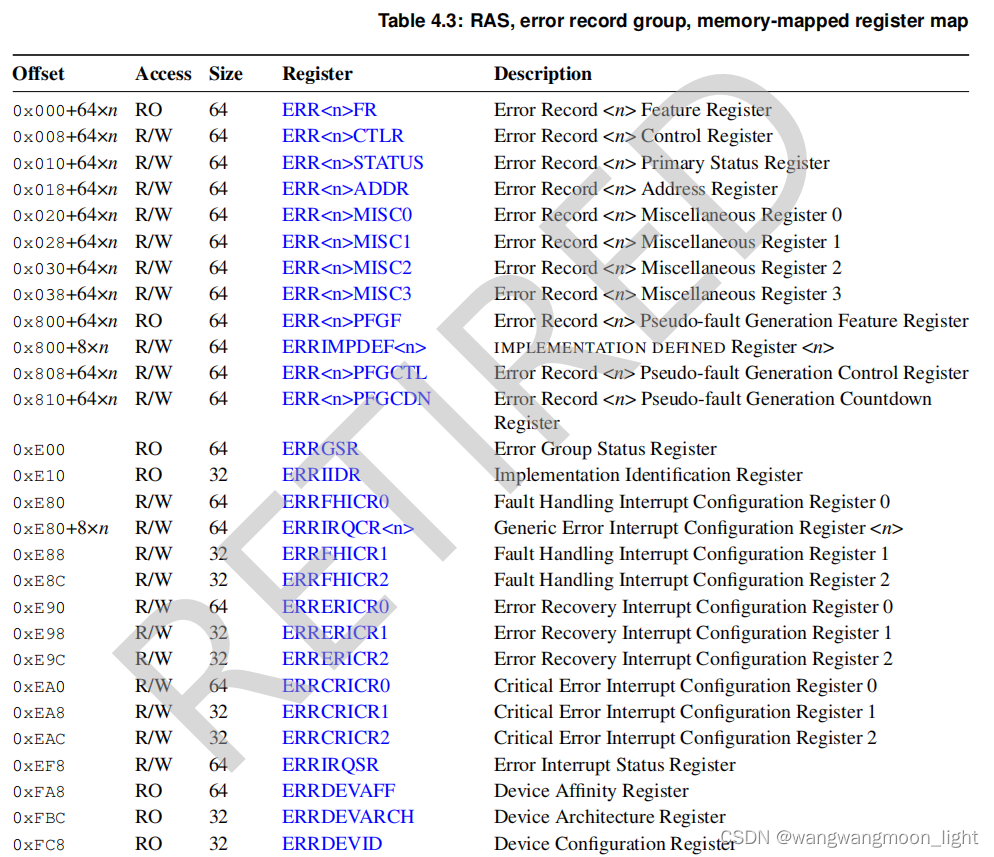

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









