







 超级会员免费看
超级会员免费看
 GLIGEN通过引入定位条件(如BBOX、参考图片等)增强Stable Diffusion的控制能力,以实现更精细化的图像生成。模型采用门控Transformer层处理新输入,保留预训练知识并融合定位信息。实验显示,GLIGEN在控制图像生成和质量之间取得良好平衡,具有强大的泛化性。
GLIGEN通过引入定位条件(如BBOX、参考图片等)增强Stable Diffusion的控制能力,以实现更精细化的图像生成。模型采用门控Transformer层处理新输入,保留预训练知识并融合定位信息。实验显示,GLIGEN在控制图像生成和质量之间取得良好平衡,具有强大的泛化性。

🤗关注公众号 funNLPer 快乐白嫖🤗
论文:GLIGEN: Open-Set Grounded Text-to-Image Generation
代码:gligen/GLIGEN
项目地址:GLIGEN
demo地址:gligen demo
文章目录
简单来说GLIEN的出发点与我们之前介绍的 可控生成之ControlNet 类似,都是希望对SD等预训练生成大模型进行精准控制,从而让SD的生成结果更符合人们的期望。
1. 动机
尽管Stable Diffusion生成的图片已经足够让人惊艳,但是存在一个问题是SD只通过文本来控制图像的生成,这造成对模型生成的控制能力不够强大,因为很多图片我们无法详细准确的描述,尤其是图片中各个实体的方位、以及实体的细节等。基于这个问题出发GLIEN提出在模型的输入中增加定位(bouding box)、参考图片等条件,进一步加强对生成的控制。
此外在图像识别领域里,很多图像识别模型都是在预训练模型的基础上增加一些结构来继续训练,从而使得新模型即有预训练学到的大量通用知识,也有再次训练在某个领域的专业知识。作者也希望通过这种方式来训练Stable Diffusion,保证生成模型不遗忘预训练学习到的能力的同时提升模型的控制能力。
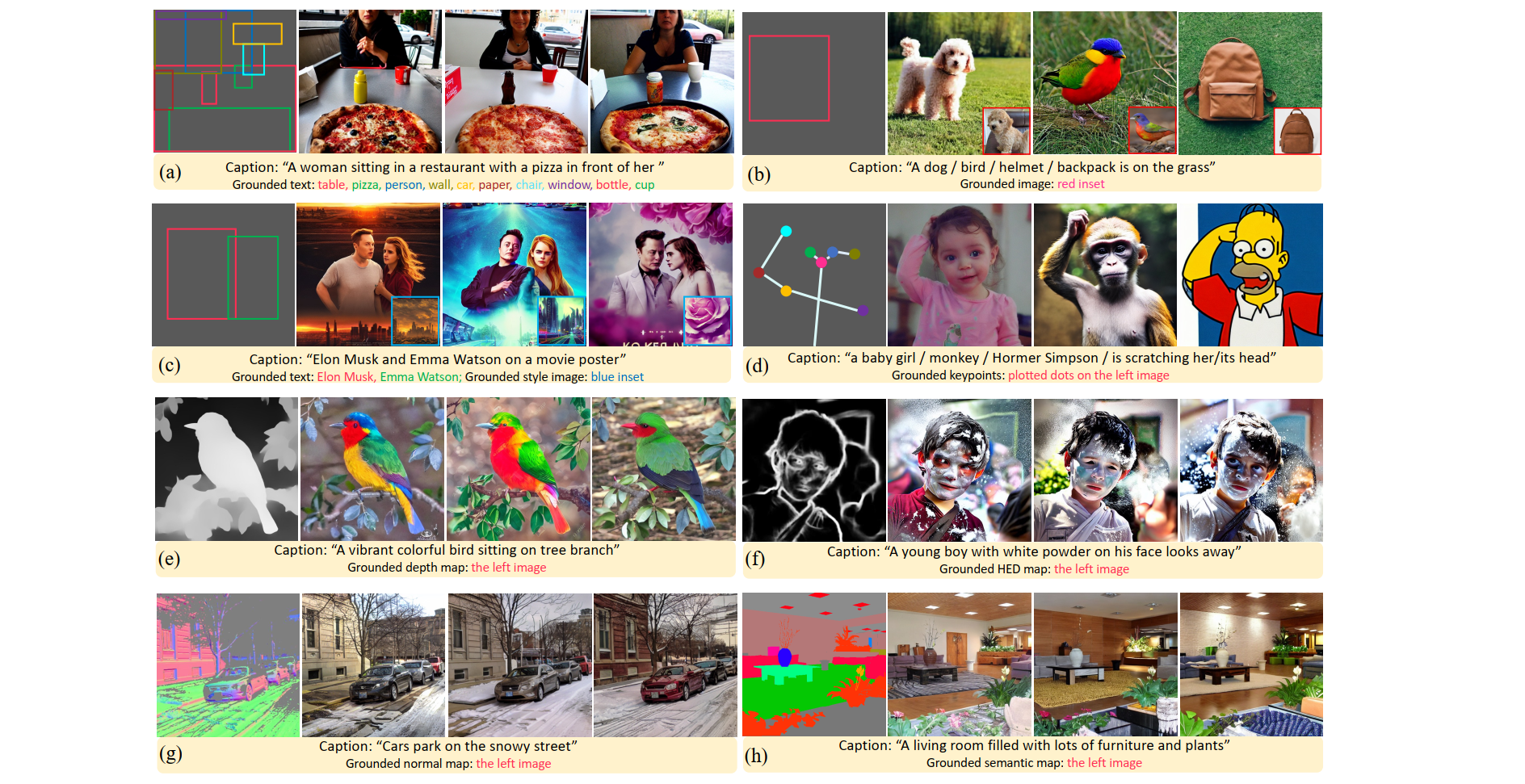
如上图所示,分别展示了 GLIGEN 的不同控制方式。(a) BBOX+实体名称 ;(b)参考图片;(c)风格图片+BBOX+实体名称;(d)关键点;(e)深度图;(f)HED图;(g)法图;(h)语义分割图。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









