




本项目对高中试题的知识点进行自动标注,样本是高中的试题,标签是试题涉及的知识点。每个题目涉及到多个知识点,样本如下:
0 [高中, 生物, 分子与细胞, 组成细胞的化学元素, 组成细胞的化合物] 菠菜 土壤 中 吸收 氮 元素 用来 合成 淀粉 纤维素 葡萄糖 核酸 蛋白质 麦芽糖 脂肪酸
1 [高中, 生物, 稳态与环境, 神经调节和体液调节的比较] 下列 生物体 内 信息 传递 叙述 正确 下丘脑 分泌 促 甲状腺 激素 释放 激素 作用 ...
2 [高中, 生物, 生物技术实践, 生物工程技术] 自然 菌样 筛选 理想 生产 菌种 步骤 采集 菌样 富集 培养 纯种 分离 性能 测定 不...
前面【】中的是标签,后面是样本;标签类别共90多个。
1.数据处理
(1)去除包含缺失值的样本
(2)使用空格代替句子中的标点等特殊符号
(3)使用jieba进行分词
(2)(3)两步使用了多线程
(4)对样本进行 zero pad,并转化为id
(5)对多标签分类的标签进行数值化
(6)计算类别权重缓解类别不平衡问题
首先计算每种标签出现概率:p=某种标签出现次数总的样本个数p=\frac{某种标签出现次数}{总的样本个数}p=总的样本个数某种标签出现次数
weight=1log(1.01+p)weight = \frac{1}{log(1.01+p)}weight=log(1.01+p)1
即某个标签出现次数越多,权重越小。
(7)加载预训练词向量
(8)划分数据集train, test, valid,并产生batch_iter
2. 构建模型
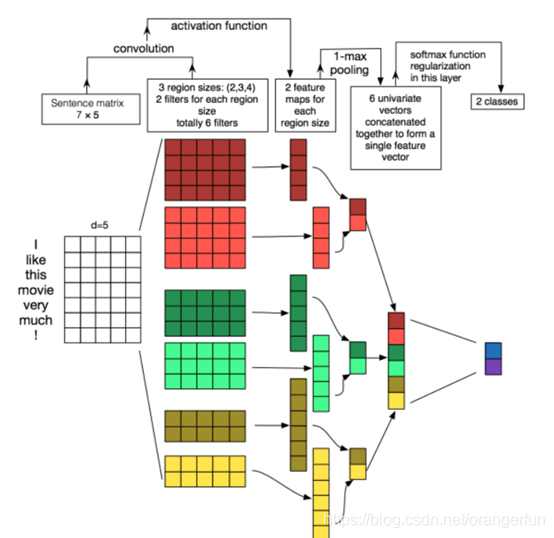
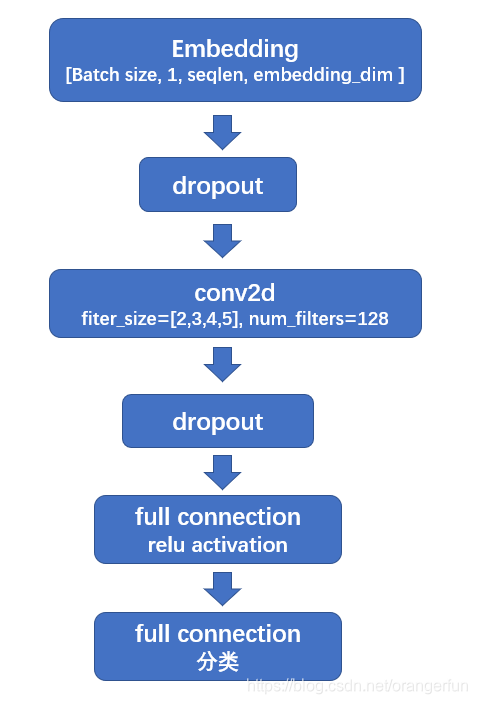
使用[2,3,4,5]四种大小的卷积核,每种尺寸的卷积核为128个,卷积后进行最大化池化。
模型评价指标:macro_F1、micro_F1、accuracy
loss: 二分类交叉熵损失函数


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









