




目录
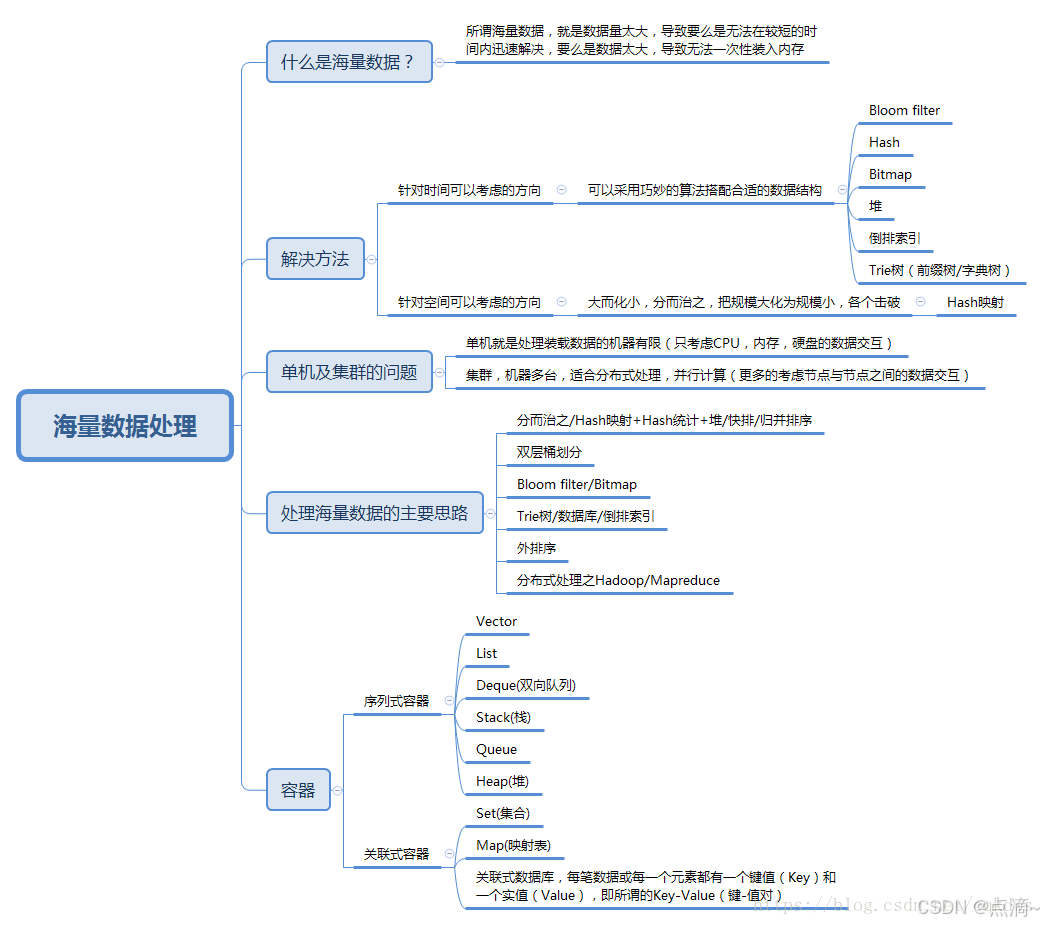
具体案例方法
在内存有限(500M)的情况下,处理一个10G的文件并找出其中重复的两行记录,可以采用外部排序和分块处理的方法。以下是具体步骤:
1. 分块读取文件
-
将10G文件分割成多个小块,每个小块的大小不超过500M。
-
例如,可以将文件分割为20个500M的小文件。
2. 对每个小块进行排序
-
逐块读取文件,对每个小块中的行进行排序。
-
排序后,将每个小块保存为一个临时文件。
3. 归并排序
-
使用归并排序的方法,将所有排序后的小块合并成一个有序的大文件。
-
归并排序时,每次从每个小块中读取一部分数据到内存中,进行比较和合并。
4. 遍历有序文件,找出重复行
-
逐行读取排序后的大文件,比较相邻的两行。
-
如果发现相邻的两行相同,则输出该行作为重复记录。
5. 优化:使用哈希分块
-
如果文件中的行长度不均匀,可以采用哈希分块的方法:
-
对每一行计算哈希值。
-
根据哈希值将行分配到不同的临时文件中。
-
对每个临时文件进行排序和查找重复行。
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









