




 本文通过逻辑电路与神经网络的类比,解释了深层神经网络在处理复杂任务时的高效性,如语音识别、图像识别等,并探讨了端到端学习在深度学习领域的应用。
本文通过逻辑电路与神经网络的类比,解释了深层神经网络在处理复杂任务时的高效性,如语音识别、图像识别等,并探讨了端到端学习在深度学习领域的应用。
文章目录
前言
接上节内容:李宏毅学习笔记11.Why Deep(上)。本节课老师从他老本行EE(Electronic Engineering)逻辑电路类比了神经网络,讲解了为什么神经网络有层次的时候高效的原因。
公式输入请参考:在线Latex公式
打个比方(Analogy)
| 逻辑电路 | 神经网络 |
|---|---|
| 由逻辑门构成 | 由神经元构成 |
| 两层的逻辑门可以表示任意的逻辑函数(Boolean function) | 一个隐藏层可以表示任意连续函数 |
| 用多层逻辑门设计电路会更简单 | 用多层神经元表示函数更简单 |
| 需要的逻辑门更少 | 需要的参数更少 |
神经网络需要的参数少,好处多多,不容易overfitting,需要比较少的data就完成训练(再次强调这点与我们平时认为NN需要大量数据训练的观点相悖)。
举个栗子(奇偶校验parity check)
先祭上奇偶校验的真值表:
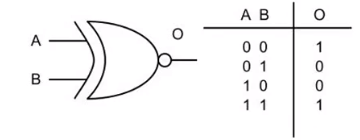
如果有如下电路:
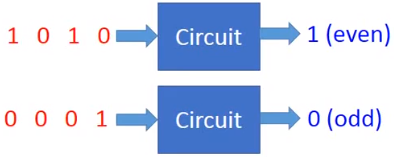
如果使用两层逻辑电路:For input sequence with d bits, Two-layer circuit need
O
(
2
d
)
O(2^d)
O(2d) gates.
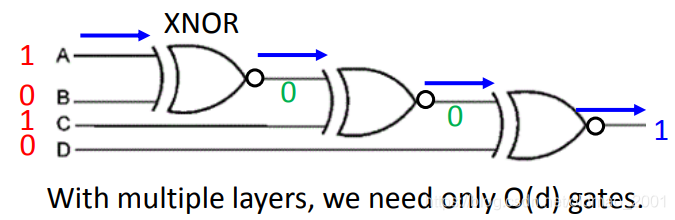
如果用多层逻辑电路:With multiple layers, we need only
O
(
d
)
O(d)
O(d) gates.
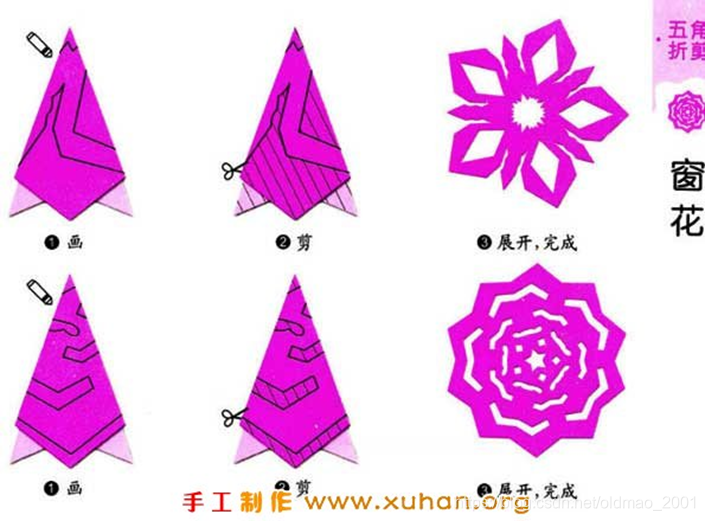
另外一个栗子(剪窗花)
折了再剪,只用剪几下就能构造出更加复杂的形状,这个与神经网络有什么联系?
回到之前讲logistics regression划分异或坐标点的例子:
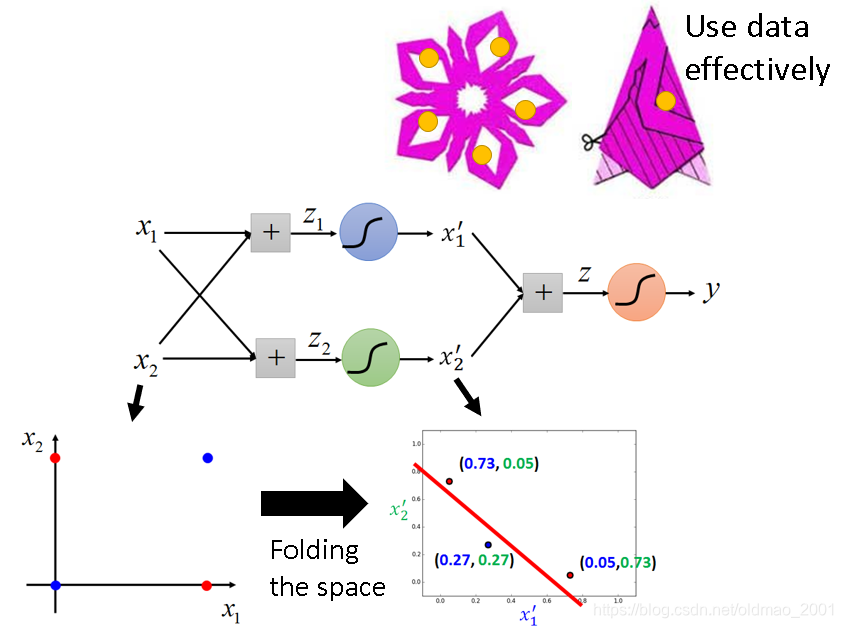
这个坐标变换过程可以看成空间的折叠,还真的和剪窗花还挺像。妙的是下面的类比:
把剪窗花看过做是training,要剪的纸看做training data,上图中斜线部分看做是positive example,减掉部分看做是negative example,由于把纸做了折叠,原来复杂positive example组成的形状变成简单可分(剪),上面的窗花上黄点的地方剪一下,展开就会在五个地方出现黄点,也就是神经网络会比较有效率的使用data。
小实验toy example
PS:看ng深度学习课程第二课结束有采访Bengio的视频,里面Bengio也提到在做toy experiment。看来在深度学习领域,一上手就大数据跑估计是比较浪费时间,在做实验时间要先toy experiment弄弄。
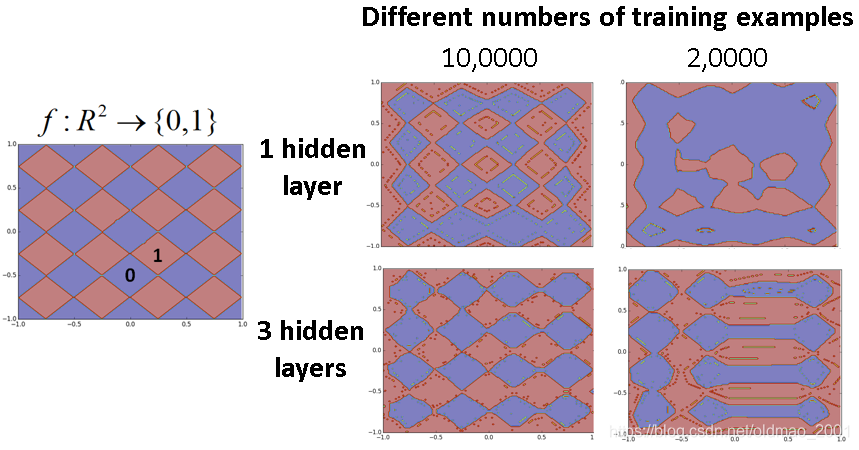
左边是函数,输入的是对应的X,Y坐标,输出为0(蓝色)和1(红色),函数形状就是菱形的纹路。
右边分1个隐藏层和3个隐藏层在不同training example个数的学习效果,这里要注意的是1个隐藏层和3个隐藏层的参数是基本相同的。可以看出,10万个training data的时候两个神经网络都差不多,当只有2万的training data的时候3个隐藏层的神经网络的结果还是比较好。
端到端学习End-to-End
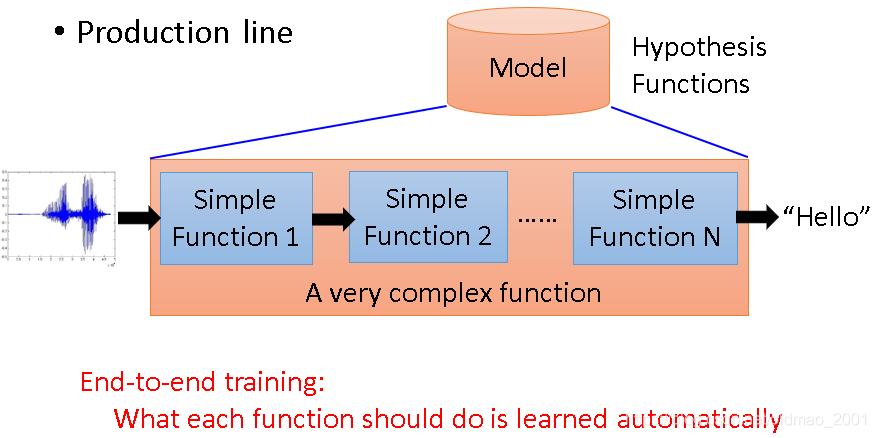
这里贴下知乎上王赟对端到端的回答:
传统的语音识别系统,是由许多个模块组成的,包括声学模型、发音词典、语言模型。其中声学模型和语言模型是需要训练的。这些模块的训练一般都是独立进行的,各有各的目标函数,比如声学模型的训练目标是最大化训练语音的概率,语言模型的训练目标是最小化perplexity(困惑度)。由于各个模块在训练时不能互相取长补短,训练的目标函数又与系统整体的性能指标(一般是词错误率 WER)有偏差,这样训练出的网络往往达不到最优性能。
针对这个问题,一般有两种解决方案:
端到端训练(end-to-end training):一般指的是在训练好语言模型后,将声学模型和语言模型接在一起,以 WER 或它的一种近似为目标函数去训练声学模型。由于训练声学模型时要计算系统整体的输出,所以称为「端到端」训练。可以看出这种方法并没有彻底解决问题,因为语言模型还是独立训练的。
端到端模型(end-to-end models):系统中不再有独立的声学模型、发音词典、语言模型等模块,而是从输入端(语音波形或特征序列)到输出端(单词或字符序列)直接用一个神经网络相连,让这个神经网络来承担原先所有模块的功能。典型的代表如使用 CTC 的 EESEN [1]、使用注意力机制的 Listen, Attend and Spell [2]。这种模型非常简洁,但灵活性就差一些:一般来说用于训练语言模型的文本数据比较容易大量获取,但不与语音配对的文本数据无法用于训练端到端的模型。因此,端到端模型也常常再外接一个语言模型,用于在解码时调整候选输出的排名(rescoring),如 [1]。
参考文献:
[1] Yajie Miao, Mohammad Gowayyed, and Florian Metze, “EESEN: End-to-End Speech Recognition using Deep RNN Models and WFST-based Decoding,” in Proc. ASRU 2015.
[2] William Chan, et al. “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in Proc. ICASSP 2016.
貌似很复杂,我咋看上去有点像AdaBoost.先不管,暂时先这样。
语音识别例子
接下来看例子:
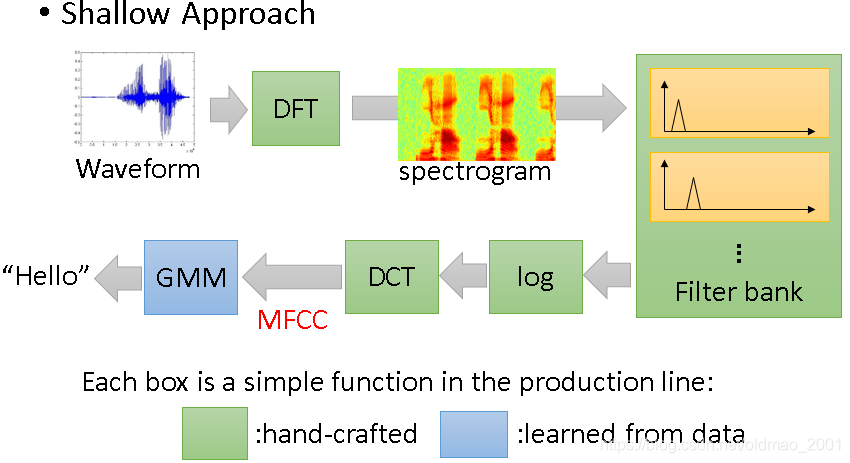
上面是没有深度学习的年代做语音识别的流程,绿色部分是人为弄的(里面的各种函数不认识不要紧,我就认得傅里叶变换。),当然这些绿色的函数是经过很多先贤的很多努力弄出了的,只有最后蓝色的GMM是从数据里面学到的。有了神经网络后,绿色部分就可以用隐藏层代替。
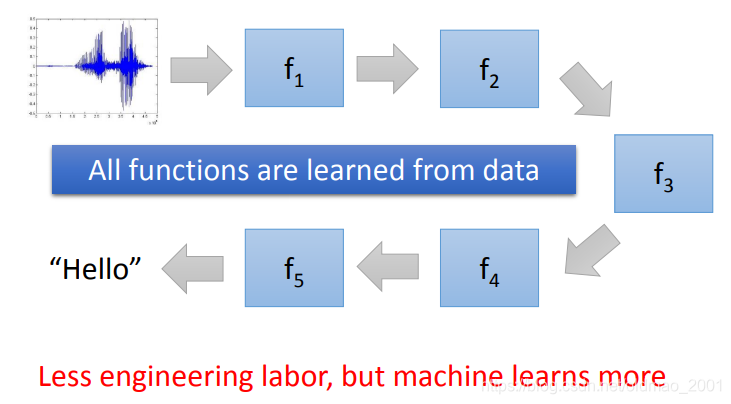
论文控又列举很多实例说了一下DNN在语音识别上做到了哪里,就不展开了。
图像识别例子
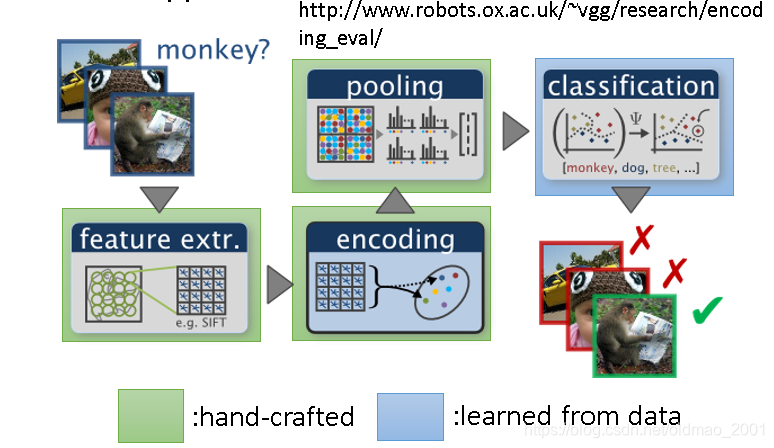
同上,原来绿色+蓝色来弄,现在变成:

更多需要DNN才能解决的复杂task
有些就不多说,直接上图,看得很明白
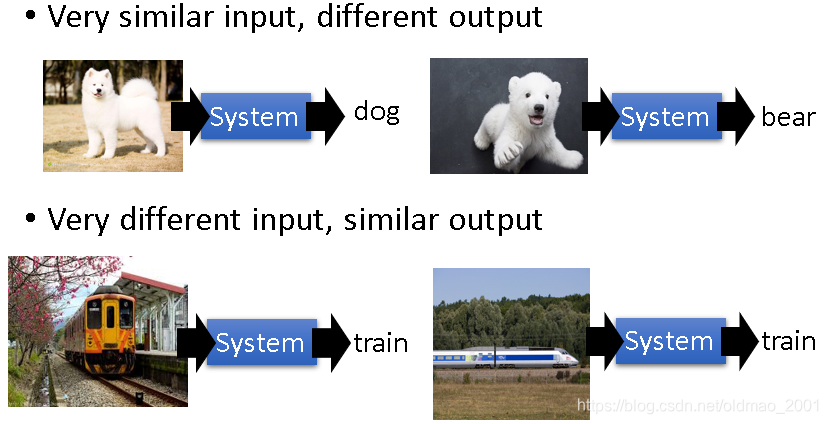
另外一个语音识别的例子:
A. Mohamed, G. Hinton, and G. Penn, “Understanding how Deep Belief Networks Perform Acoustic Modelling,” in ICASSP, 2012.(向Hinton大佬低头),李的本行,所以讲得比较详细。
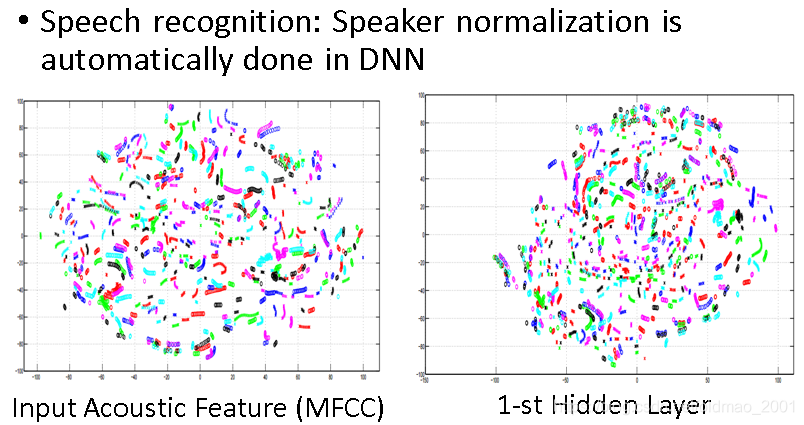
上图中不同颜色代表的是不同人讲得话,可以看出来同一句话,不同人讲,貌似在二维平面的投影比较难以区分,用一层神经网络进行处理得到右边的图。
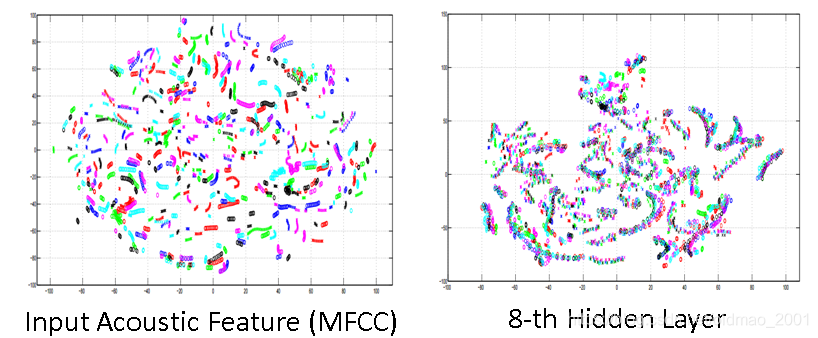
如果加深到八层隐藏层的神经网络就明显分开了。
MNIST手写数字识别的例子也是这样:

其他参考资料
Do Deep Nets Really Need To Be Deep? (by Rich Caruana)
http://research.microsoft.com/apps/video/default.aspx?id=232373&r=1
Deep Learning: Theoretical Motivations (Yoshua Bengio)
http://videolectures.net/deeplearning2015_bengio_theoretical_motivations/
从物理和化学的角度看DL
Connections between physics and deep learning
https://www.youtube.com/watch?v=5MdSE-N0bxs
Why Deep Learning Works: Perspectives from Theoretical Chemistry
https://www.youtube.com/watch?v=kIbKHIPbxiU


















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











