







 本文介绍了如何基于OpenCV 4.x的DNN模块和TensorFlow的MaskRCNN模型实现目标检测和实例分割。MaskRCNN不仅能检测物体边界框,还能获取物体的灰度或二值mask。文中提到了Inception系列的backbone网络在CPU上的运行可行性,并概述了MaskRCNN在网络结构上的改进,包括R-CNN、Fast R-CNN和Faster R-CNN的发展。此外,还提供了PyTorch和TensorFlow的实现示例。
本文介绍了如何基于OpenCV 4.x的DNN模块和TensorFlow的MaskRCNN模型实现目标检测和实例分割。MaskRCNN不仅能检测物体边界框,还能获取物体的灰度或二值mask。文中提到了Inception系列的backbone网络在CPU上的运行可行性,并概述了MaskRCNN在网络结构上的改进,包括R-CNN、Fast R-CNN和Faster R-CNN的发展。此外,还提供了PyTorch和TensorFlow的实现示例。
原文:MaskRCNN 基于OpenCV DNN的目标检测与实例分割 - AIUAI
这里主要记录基于 OpenCV 4.x DNN 模块和 TensorFlow MaskRCNN 开源模型的目标检测与实例分割 的实现.
MaskRCNN 不仅可以检测图片或视频帧中的物体边界框,还可以得到物体的灰度图或二值 mask 图.
在 TensorFlow Object Detection Model Zoo 中提供了基于不同 backbone 网络结构,基于 MSCOCO 数据集,得到的预训练模型,如 InceptionV2, ResNet50, ResNet101, Inception-ResNetV2. 也可以采用提供的工具自定义训练MaskRCNN 模型 - train your own models.
其中,基于 Inception 系列 的 backbone 网络速度是最快的,可以尝试在 CPU 上进行运行.
1. MaskRCNN 简介
语义分割:是指基于某些准则将图片分为不同的像素组,如基于颜色(color)、纹理(texture)等. 得到的像素组有时也被叫作超像素(super-pixels). 语义分割尝试将图片中的每一个像素进行分类.
实例分割:旨在检测图片中的特定物体,同时创建物体的 mask. 实例分割还可以看作是一种目标检测,其输出是物体的 mask,而不只是物体的边界框. 实例分割并不对图片中的每个像素进行标注. 如图:

图1 - 实例分割例示.
MaskRCNN 是 R-CNN 系列的改进.
R-CNN - CVPR2014 是目标检测算法,其基于 selective search 算法生成 region proposals,然后再分别逐个采用 CNN 对每个 proposed region 进行处理,输出物体的类别标签和对应的边界框.
Fast R-CNN - ICCV2015 提升了 R-CNN 算法的速度,通过采用 RoIPool 层,基于 CNN 一次处理所有的 proposed regions.
Faster R-CNN - PAMI2017进一步提升算法的速度,其主要是采用 RPN(Region Proposal Network) 网络来进行 region proposal 处理. RPN 网络和物体分类与边界框检测网络同时对共享的 feature maps 进行处理,因此具有更快的推断速度. 在单张 GPU 上, Faster R-CNN 运行速率可达到 5 fps.
Mask R-CNN - ICCV2017 对 Faster R-CNN 进行改进,其新增了一个和物体类别和物体边界框预测网络分支并行的 mask 预测网络分支,如下图2. 虽然在 Faster R-CNN 添加了一个小的输出分支,但仍能够在单张 GPU 运行速率 5 fps.
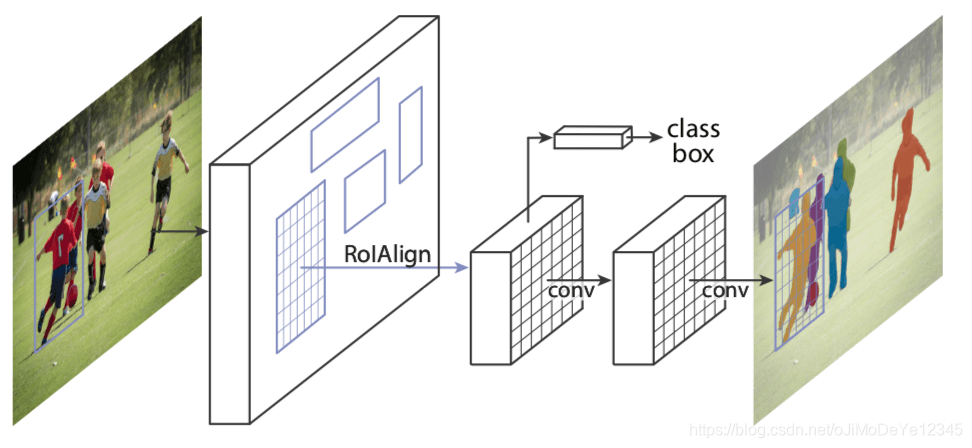
图2 - Mask-RCNN 网络结构
MaskRCNN 网络结构中的 RPN 网络对每张图片产生约 300 个 region proposals.
训练时,每个 region proposals(ROIs) 传递到目标检测网络和 mask 预测网络. 其中,对于每个给定 ROI,mask 预测分支可以与目标检测分支并行地进行,因此,网络可以预测属于所有物体类别的 masks.
推断时,region proposals 经过 NMS 处理,只对 top scoring 100 的检测边界框,才送入 mask 预测分支进行处理. 因此,对于 100 个 ROIs 和 90 个物体类别,MaskRCNN 网络的 mask 预测分支输出为 100x90x15x15 的 4D tensor,其中每个 mask 的尺寸为 15x15.
例如,对于图1 中的 sheep 物体类,MaskRCNN 检测到两个物体. 对于每个物体,目标检测分支输出包含预测的物体概率分数(即:物体属于预测类别的概率),以及检测到的物体的边界框的坐标位置 - (left, top, right, bottom). 其中 class id 用于从 mask 预测分支的输出中提取对应的物体 mask. 如下图:

图3 - MaskRCNN 预测的 sheep mask.
MaskRCNN 的 mask 预测分支得到的 masks 可以进行阈值化,以得到二值 mask.
类似于 Faster R-CNN,MaskRCNN 可以灵活的选择不同的 backbone 网络结构. 例如采用 InceptionV2 backbone 结构,其速度快,同时能够得到比 ResNeXt-101 更好的结果.
MaskRCNN 网络可以在较大的图片尺寸上进行处理,其将输入图像调整尺寸,如将图片最小边尺寸保持为 800 pixels.
2. MaskRCNN DNN 实现
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
from __future__ import division
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
import os
import random
class general_maskrcnn_dnn(object):
def __init__(self, modelpath):
self.conf_threshold = 0.5 # Confidence threshold
self.mask_threshold = 0.3 # Mask threshold
self.colors = [[ 0., 255., 0.],
[ 0., 0., 255.],
[255., 0., 0.],
[ 0., 255., 255.],
[255., 255., 0.],
[255., 0., 255.],
[ 80., 70., 180.],
[250., 80., 190.],
[245., 145., 50.],
[ 70., 150., 250.],
[ 50., 190., 190.], ]
self.maskrcnn_model = self.get_maskrcnn_net(modelpath)
self.classes = self.get_classes_name()
def get_classes_name(self):
# Load names of classes
classesFile = "mscoco_labels.names"
classes = None
with open(classesFile, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
return classes
def get_maskrcnn_net(self, modelpath):
pbtxt_file = os.path.join(modelpath, './graph.pbtxt')
pb_file = os.path.join(modelpath, './frozen_inference_graph.pb')
maskrcnn_model = cv2.dnn.readNetFromTensorflow(pb_file, pbtxt_file)
maskrcnn_model.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
maskrcnn_model.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
return maskrcnn_model
def postprocess(self, boxes, masks, img_height, img_width):
# 对于每个帧,提取每个检测到的对象的边界框和掩码
# 掩模的输出大小为NxCxHxW
# N - 检测到的框数
# C - 课程数量(不包括背景)
# HxW - 分割形状
numClasses = masks.shape[1]
numDetections = boxes.shape[2]
results = []
for i in range(numDetections):
box = boxes[0, 0, i]
mask = masks[i]
score = box[2]
if score > self.conf_threshold:
left = int(img_width * box[3])
top = int(img_height * box[4])
right = int(img_width * box[5])
bottom = int(img_height * box[6])
left = max(0, min(left, img_width - 1))
top = max(0, min(top, img_height - 1))
right = max(0, min(right, img_width - 1))
bottom = max(0, min(bottom, img_height - 1))
result = {
}
result["score"] = score
result["classid"] = int(box[1])
result["box"] = (left, top, right, bottom)
result["mask"] = mask[int(box[1])]
results.append(result)
return results
def predict(self, imgfile):
img_cv2 = cv2.imread(imgfile)
img_height, img_width, _ = img_cv2.shape
# 从框架创建4D blob。
blob = cv2.dnn.blobFromImage(img_cv2, swapRB=True, crop=True)
# 设置网络的输入
self.maskrcnn_model.setInput(blob)
# 运行正向传递以从输出层获取输出
boxes, masks = self.maskrcnn_model.forward(
['detection_out_final', 'detection_masks'])
# 为每个检测到的对象提取边界框和蒙版
results = self.postprocess(boxes, masks, img_height, img_width)
return results
def vis_res(self, img_file, results):
img_cv2 = cv2.imread(img_file)
for result in results:
# box
left, top, right, bottom = result["box"]
cv2.rectangle(img_cv2,
(left, top),
(right, bottom),
(255, 178, 50), 3)
# class label
classid = result["classid"]
score = result["score"]
label  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









