







可能有人想问了,Word里面的图不是自己插入的么,为啥还要提取?
但是Word文档中有一些图片可能是我们引用网上的图片,可能自己也记不清来源了,而且有一些文档比较清朝了,图片原图可能也找不到了。所以这里主要记录一个生活小常识。而pdf的话,就必须用代码工具来提取了,不能直接用简单方法。
1 Word文档解压缩原理
- DOCX文件结构原理
Word文档(.docx)是基于Office Open XML格式。这种格式其实本身就是一种基于ZIP压缩的文件格式,它将文档的各种元素(如文本、图片、格式设置等)以一系列XML文件和相关资源文件的形式存储在一个压缩包中。
在.docx文件内部(如果将其解压缩),会发现它包含多个文件夹和文件。其中,“word”文件夹包含了文档的主要内容,如文档正文(document.xml)、样式(styles.xml)、字体(fonts)等相关信息。“media”文件夹用于存储文档中的图片、图表等多媒体文件。
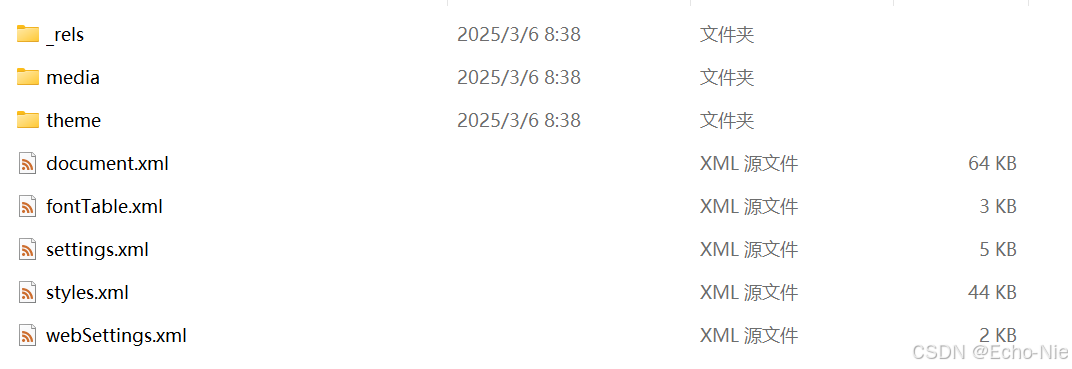
- 后缀更改为RAR后的解压缩原理
当将.docx后缀改为.rar后,解压缩软件(如WinRAR)会将其识别为一个压缩包。因为.docx本身就是一个压缩后的文件格式,其内部结构和RAR压缩包的结构在一定程度上是兼容的,都是将多个文件和文件夹打包并进行压缩。
当使用解压缩软件解压缩这个“RAR”文件(实际上是修改后缀的.docx文件)时,软件会按照压缩包的格式规范来解压文件。由于.docx文件内部本身就有“media”文件夹来存储图片等资源,所以解后压缩就能看到其中的图片文件所在的文件夹,即得到media文件夹及其中的图片。
2 Word提取图片具体步骤
首先就是改后缀名,改为.rar文件,然后直接解压缩,进入word\media就有所有图片了。
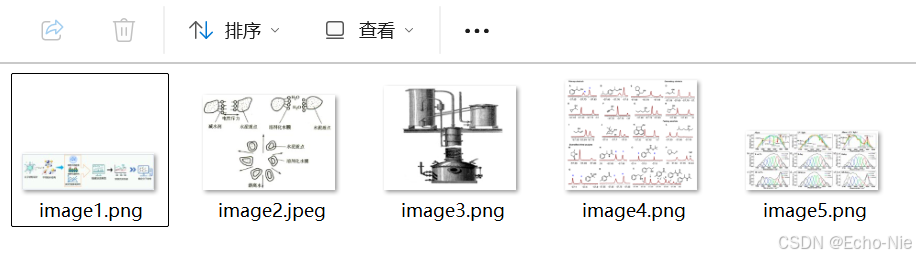
3 提取PDF中的图片
完整代码:https://github.com/Echo-Nie/SomeTools
- 安库
pip install pymupdf
- 导包
import os
import tkinter as tk
from tkinter import filedialog, messagebox
import fitz
- 提取图片的具体逻辑
def extract_images_from_pdf(pdf_path, output_folder):
"""
Extract pictures from PDF files and save to xx folders
"""
try:
# open PDF
pdf_document = fitz.open(pdf_path)
image_count = 0
# for each page of the PDF
for page_number in range(len(pdf_document)):
page = pdf_document.load_page(page_number)
image_list = page.get_images()
# for each pictures
for image_index, img in enumerate(image_list):
xref = img[0]
base_image = pdf_document.extract_image(xref)
image_bytes = base_image["image"]
image_ext = base_image["ext"]
# save pictures
image_filename = f"image_page{page_number + 1}_index{image_index + 1}.{image_ext}"
image_path = os.path.join(output_folder, image_filename)
with open(image_path, "wb") as image_file:
image_file.write(image_bytes)
image_count += 1
return image_count
except Exception as e:
raise e
- 做个简单GUI
def browse_files():
"""
open GUI
"""
file_paths = filedialog.askopenfilenames(
title="select PDF", filetypes=[("PDF File", "*.pdf")]
)
file_paths = root.tk.splitlist(file_paths)
file_listbox.delete(0, tk.END)
for file_path in file_paths:
file_listbox.insert(tk.END, file_path)
- 选择output文件夹
def browse_folder():
"""
select output folder
"""
folder_path = filedialog.askdirectory(title="select output folder")
output_folder_entry.delete(0, tk.END)
output_folder_entry.insert(tk.END, folder_path)
- 提取图片函数
def extract_images():
"""
the main function to extract
"""
# get the pdf and folder selected
pdf_files = file_listbox.get(0, tk.END)
output_folder = output_folder_entry.get()
if not pdf_files:
messagebox.showwarning("warning", "please select PDF file!")
return
if not output_folder:
messagebox.showwarning("warning", "the output folder is null!")
return
# for each pdf to get the pictures
total_images = 0
for pdf_file in pdf_files:
try:
image_count = extract_images_from_pdf(pdf_file, output_folder)
total_images += image_count
messagebox.showinfo(
"Success", f"{image_count} images extracted from file {pdf_file}!"
)
except Exception as e:
messagebox.showerror("Fail", f"Error processing file {pdf_file}: {str(e)}")
return
messagebox.showinfo("Finish", f"A total of {total_images} images were extracted!")
- 主窗口
# create main window
root = tk.Tk()
root.title("Image extraction tool")
# select files
file_frame = tk.Frame(root)
file_frame.pack(pady=10)
file_label = tk.Label(file_frame, text="select PDF file:")
file_label.pack(side=tk.LEFT)
browse_button = tk.Button(file_frame, text="Select", command=browse_files)
browse_button.pack(side=tk.LEFT, padx=10)
file_listbox = tk.Listbox(root, width=50, height=10)
file_listbox.pack(pady=10)
# Output folder selection
output_frame = tk.Frame(root)
output_frame.pack(pady=10)
output_label = tk.Label(output_frame, text="select output folder:")
output_label.pack(side=tk.LEFT)
output_folder_entry = tk.Entry(output_frame, width=30)
output_folder_entry.pack(side=tk.LEFT, padx=10)
folder_browse_button = tk.Button(output_frame, text="Select", command=browse_folder)
folder_browse_button.pack(side=tk.LEFT)
# Extract the picture
extract_button = tk.Button(root, text="Extract the picture", command=extract_images)
extract_button.pack(pady=10)
# run the main
root.mainloop()


















 2526
2526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











