







 本文详细介绍了SQLServer中的数据表操作,包括创建、插入、修改表结构和删除,以及视图的概念、优点、创建和操作,如通过视图插入、修改和删除数据。还提供了编程示例,展示了如何在实际项目中创建和管理学生表、课程表和成绩表及视图。
本文详细介绍了SQLServer中的数据表操作,包括创建、插入、修改表结构和删除,以及视图的概念、优点、创建和操作,如通过视图插入、修改和删除数据。还提供了编程示例,展示了如何在实际项目中创建和管理学生表、课程表和成绩表及视图。
数据库实验(一)SQL Server触发器
触发器的定义
触发器是建立在触发事件上的。例如,对表执行 INSERT 、 UPDATE 或 DELETE 等操作时, SQL Server 就会自动执行建立在这些操作上的触发器。在触发器中,包含了一系列用于定义业务规则的 SQL 语句,用来强制用户实现这些规则,从而确保数据的完整性。
触发器和存储过程的区别
触发器与存储过程的区别是运行方式的不同,触发器不能用 EXECUTE 语句调用,而是在用户执行 SQL 语句时,自动触发执行。而存储过程需要用户、应用程序或者触发器来显示地调用并执行。
触发器的优点
-
触发器是自动的。当对表中的数据做了任何修改之后,立即被激活;
-
触发器可以通过数据库中的相关表,进行层叠修改;
-
触发器可以强制限制。这些限制比用 CHECK 约束所定义的更复杂,与 CHECK 约束不同的是,触发器可以引用其他表中的列。
触发器的作用
触发器的主要作用就是,其能够实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性,它能够对数据库中的相关表进行级联修改,提供比 CHECK 约束更复杂的数据完整性,并自定义错误消息。触发器的主要作用主要有以下几个方面:
-
强制数据库间的引用完整性;
-
级联修改数据库中所有相关的表,自动触发其它与之相关的操作;
-
跟踪变化,撤销或回滚违法操作,防止非法修改数据;
-
返回自定义的错误消息,约束无法返回信息,而触发器可以;
-
触发器可以调用更多的存储过程。
触发器的分类
SQL Server 包括三种常规类型的触发器: DML 触发器、 DDL 触发器和登录触发器。
DML触发器
DML 触发器是一些附加在特定表或视图上的操作代码。当数据库服务器中,发生数据操作语言事件时,执行这些操作。 SQL Server 中的 DML 触发器有三种:
INSERT 触发器:向表中插入数据时被触发;
DELETE 触发器:从表中删除数据时被触发;
UPDATE 触发器:修改表中数据时被触发。
当遇到下列情形时,应考虑使用 DML 触发器:
-
通过数据库中的相关表实现级联更改;
-
防止恶意或者错误的 INSERT 、 DELETE 和 UPDATE 操作,并强制执行 CHECK 约束定义的限制更为复杂的其他限制;
-
评估数据修改前后表的状态,并根据该差异采取措施。
DDL触发器
DDL 触发器是当服务器或者数据库中发生数据定义语言(主要是以 CREATE , DROP , ALTER 开头的语句)事件时,被激活使用。使用 DDL 触发器,可以防止对数据架构进行的某些更改,还可以防止对记录数据中的更改或事件操作。
登录触发器
登录触发器会为响应 LOGIN 事件而激发存储过程,与 SQL Server 实例建立用户会话时,将引发此事件。
登录触发器将在登录的身份验证阶段完成之后,且用户会话实际建立之前激发。因此,来自触发器内部,且通常将到达用户的所有消息(例如错误消息和来自 PRINT 语句的消息)传送到 SQL Server 错误日志。如果身份验证失败,将不激发登录触发器。
触发器的工作原理
触发器触发时:
-
系统自动在内存中创建 deleted 表或 inserted 表;
-
只读,不允许修改,触发器执行完成后,自动删除。
inserted表
-
临时保存插入或更新后的记录行;
-
可以从 inserted 表中,检查插入的数据是否满足业务需求;
-
如果不满足,则向用户报告错误消息,并回滚插入操作。
deleted表
-
临时保存删除或更新前的记录行;
-
可以从 deleted 表中,检查被删除的数据是否满足业务需求;
-
如果不满足,则向用户报告错误消息,并回滚插入操作。
inserted 表和 deleted 表对照:


创建触发器
创建触发器语法示例如下:
CREATE TRIGGER trigger_name
ON table_name
[WITH ENCRYPTION]
FOR | AFTER | INSTEAD OF [DELETE, INSERT, UPDATE]
AS
BEGIN
SQL语句
END我们以 INSERT 触发器的创建为例,讲解触发器的创建和使用。首先创建测试数据表:
--创建学生表
create table student(
stu_id int identity(1,1) primary key,
stu_name varchar(10),
stu_gender char(2),
stu_age int
)为 student 表创建 INSERT 触发器:
--创建insert触发器
create trigger trig_insert
on student
after insert
as
begin
if object_id(N'student_sum',N'U') is null--判断student_sum表是否存在
create table student_sum(stuCount int default(0));--创建存储学生人数的student_sum表
declare @stuNumber int;
select @stuNumber = count(*)from student;
if not exists (select * from student_sum)--判断表中是否有记录
insert into student_sum values(0);
update student_sum set stuCount =@stuNumber; --把更新后总的学生数插入到student_sum表中
end测试触发器:
--测试触发器trig_insert-->功能是向student插入数据的同时级联插入到
--student_sum表中,更新stuCount
--因为是后触发器,所以先插入数据后,才触发触发器trig_insert;
insert into student(stu_name,stu_gender,stu_age)values('吕布','男',30);
select stuCount 学生总人数 from student_sum;
insert into student(stu_name,stu_gender,stu_age)values('貂蝉','女',30);
select stuCount 学生总人数 from student_sum;
insert into student(stu_name,stu_gender,stu_age)values('曹阿瞒','男',40);
select stuCount 学生总人数 from student_sum;另外,因为定义学生总数表 student_sum ,是向 student 表中插入数据后,才计算的学生总数。所以,学生总数表应该禁止用户,向其中插入数据。
--创建insert_forbidden,禁止用户向student_sum表中插入数据
create trigger insert_forbidden
on student_sum
after insert
as
begin
RAISERROR('禁止直接向该表中插入记录,操作被禁止',1,1)--raiserror 是用于抛出一个错误
rollback transaction
end编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。 你只需:
-
补全右侧代码片段中 create trigger_insert_score 下的 Begin-End 区域间的代码,向 score 表建立一个插入触发器。保证向 score 表中插入的学生信息的学号,必须在 student 表中存在;
-
补全右侧代码片段 create trigger_delete_student 下的 Begin-End 区域间的代码,向 student 表插入删除触发器,实现 student 表和 score 表的级联删除;
-
补全右侧代码片段 create trigger_protect_grade 下的 Begin-End 区域间的代码,向 score 表建立触发器,使 grade 列不能手工修改。
表 student 如下所示,其中 birthday 是 date 类型,其余字段均为 varchar 类型。
| sno | sname | sex | birthday | discipline | school |
|---|---|---|---|---|---|
| 1001 | Tom | male | 2019-06-01 | computer | information |
| 1002 | Bob | male | 2019-06-01 | software | information |
| 1003 | Alice | female | 2019-05-02 | computer | information |
表 score 如下所示,字段 grade 为 float 类型,其余均为 varchar 类型。
| sno | cno | grade |
|---|---|---|
| 1001 | 101 | 89 |
| 1001 | 102 | 78 |
| 1002 | 101 | 88 |
| 1002 | 102 | 80 |
测试要求:

实验代码
USE studentdb
go
SET NOCOUNT ON
go
--********** create trigger_insert_score **********--
--********** Begin **********--
create trigger trigger_insert_score
on score
after insert
as
begin
if not exists
(select*
from student
where sno in(
select sno
from inserted))
begin
rollback transaction
begin transaction
end
end
--********** End **********--
go
delete from score
go
insert into score values('1001','2001','89.5')
go
insert into score values('1002','2001','95')
go
insert into score values('1011','2001','88')
go
select * from score
go
--********** create trigger_delete_student **********--
--********** Begin **********--
create trigger trigger_delete_student
on student
for delete
as
begin
delete from score
where sno in(
select sno
from deleted)
end
--********** End **********--
go
delete from student
where sno='1001'
go
select *
from student
go
--********** create trigger_protect_grade **********--
--********** Begin **********--
create trigger trigger_protect_grade
on score
for update
as
begin
rollback transaction
begin transaction
end
--********** End **********--
go
delete from score where sno='1001'
go
select * from score
go
select * from student
goSQL Server 实验二:数据库视图的创建和使用
第一关
相关知识
什么是表
如果说数据库是一个仓库,那么表就是存放物品的架子。
数据表是数据库中最基本的操作对象,通常把数据存放在数据库中,其实就是将数据存放在数据库中的一张表中,且一个数据库可以包含一个或多个表。
数据表中的数据,按照行和列的规则,来进行数据存储。每一行,为一条数据记录,一条数据记录是由多个字段的描述信息组成的,每一列就是一个字段。
例如:有一个记录了员工信息的 employee 表,每一列就是用来描述员工特定信息的字段,比如工号、姓名等等;每一行则用于描述某一员工的所有字段信息:工号、姓名、性别和学历等,这些信息的集合称之为一条记录,如下图所示。
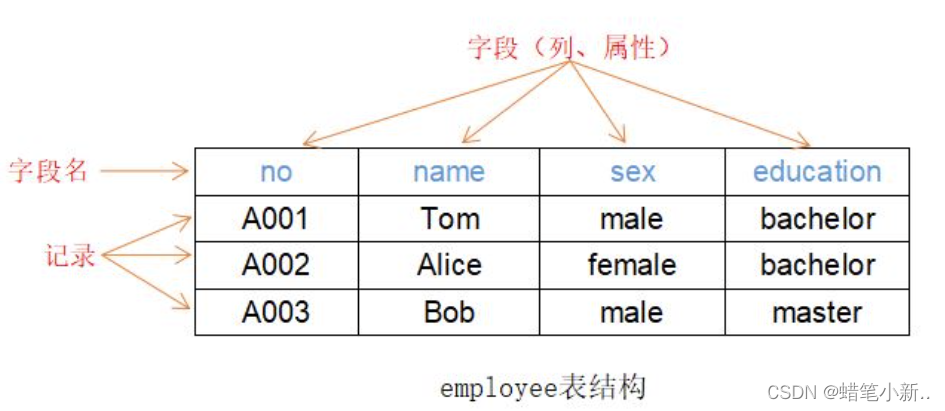
操作数据表
SQL Server 提供了非常丰富的数据表操作方法,用户可以通过企业管理器和 T-SQL 语言进行操作。使用 T-SQL 操作数据表,具有灵活、快捷等特点,也是数据库管理人员使用最多的一种方式。
对于数据表的操作主要分为:
-
CREATE TABLE 创建数据表
-
ALTER TABLE 修改数据表结构
-
DROP TABLE 删除数据表
创建数据表
数据表的创建主要是对基本结构的构建。例如,列属性的设定,数据完整性的约束。创建数据表使用 CREATE TABLE 语句,基本语法格式如下:
CREATE TABLE table_name
(
column_name1 data_type(size),
column_name2 data_type(size),
column_name3 data_type(size),
....
);column_name :列名;
data_type :列的数据类型(例如 varchar 、 integer 、 decimal 、 date 等等);
size :列的最大长度。
例如,使用下面的 CREATE TABLE 语句,创建一个名为 Persons 的表,包含五列 PersonID 、 LastName 、 FirstName 、 Address 和 City :
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);利用 select name, length, COLLATION from syscolumns where id=object_Id('Persons') 查看创建的 Persons 表结构:

插入数据
创建完表后,可用 INSERT INTO 语句向表中插入数据。其语法如下:
INSERT INTO 表名称 VALUES (值1, 值2,....)我们也可以指定所要插入数据的列,如下:
INSERT INTO 表名称 (列1, 列2,...) VALUES (值1, 值2,....)例如,向 Persons 表中,插入 Tom 的个人信息,可以使用下列的语句完成。
INSERT INTO Persons VALUES('1001','Tom','Green','West Road','New York')使用select * from Persons语句查看插入结果。

修改表结构
在表已经创建好的前提下,可以使用 ALTER TABLE 语句,对表中的列进行增加、删除或修改数据类型等操作。
- 新增列
ALTER TABLE table_name
ADD column_name datatype使用如下语句,可以为数据表 Persons 添加一列 AddedCol :
ALTER TABLE Persons
ADD AddedCol varchar(50)新增列后的表结构如下图:
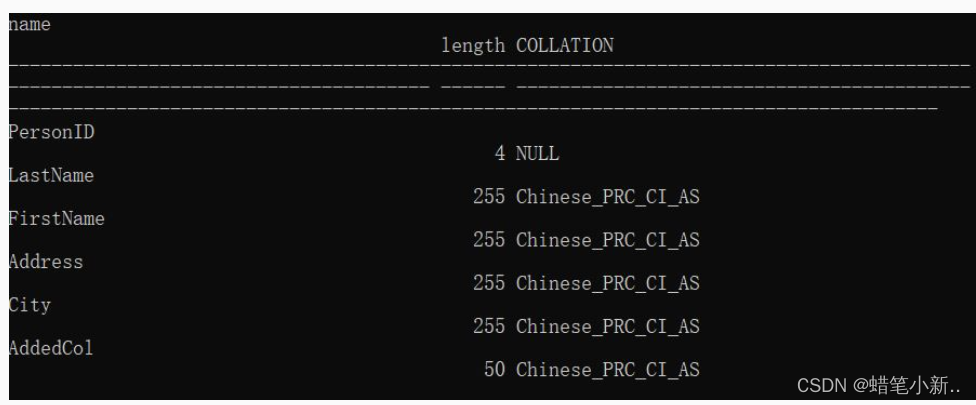
- 删除列
ALTER TABLE table_name
DROP COLUMN column_name例如,使用下列语句,可以删除数据表 Persons 中的列 City :
ALTER TABLE Persons
DROP COLUMN City删除 City 列后,表 Persons 的结构如下图:

- 修改列的数据类型
ALTER TABLE table_name
ALTER COLUMN column_name datatype下列语句把数据表 Persons 中 AddedCol 列的数据类型改为 int 类型:
ALTER TABLE persons
ALTER COLUMN addedCol int修改数据类型后的表结构如下:
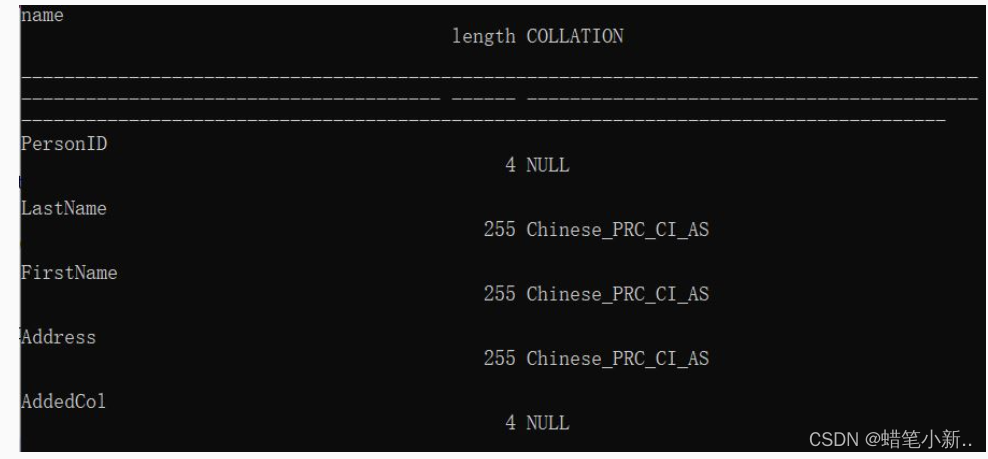
删除数据表
删除数据表是对数据库中已建立的表进行删除,在删除表的同时,会对表中定义的数据、索引和视图进行清除。在做任何删除操作前,应做好备份工作。我们使用 DROP TABLE 语句,对数据库中的数据表进行删除,语法格式如下:
DROP TABLE table_name编程要求
本次编程任务是:
在右侧编辑区 create table 下的 Begin-End 区域补全代码,创建 Student 、 Course 和 Score 三个表;
在右侧编辑区 insert 下的 Begin-End 区域补全代码,向 Score 表中插入下面给出的数据;
在右侧编辑区 alt student table 下的 Begin-End 区域补全代码,修改 Student 表结构,新增一列 addr 用于描述地址信息,并设置数据类型以及长度为 varchar(256),;
在右侧编辑区 del score table 下的 Begin-End 区域补全代码,删除 Score 表。
Student 表结构如下:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| sno | varchar(50) | 学号 |
| name | varchar(50) | 姓名 |
| sex | varchar(10) | 性别 |
| birthday | Date | 出生日期 |
| discipline | varchar(50) | 专业 |
| school | varchar(100) | 学院 |
Course 表结构如下:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| cno | varchar(50) | 课程号 |
| cname | varchar(50) | 课程名称 |
| description | varchar(256) | 课程说明 |
| credit | float | 学分 |
| cinstitution | varchar(128) | 开课单位 |
Score 表结构如下:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| sno | varchar(50) | 学号 |
| cno | varchar(50) | 课程号 |
| grade | float | 成绩 |
Score 表待插入的数据:
| 学号 | 课程号 | 成绩 |
|---|---|---|
| 09011101 | 101 | 89 |
| 09011101 | 102 | 78 |
第一关实验代码
USE studentdb
go
SET NOCOUNT ON
go
--********** create table **********--
--********** Begin **********--
create table student(
sno varchar(50),
name varchar(50),
sex varchar(10),
birthday Date,
discipline varchar(50),
school varchar(100)
);
create table course(
cno varchar(50),
cname varchar(50),
description varchar(256),
credit float,
cinstitution varchar(128)
);
create table score(
sno varchar(50),
cno varchar(50),
grade float
);
--********** End **********--
go
select name, length, COLLATION from syscolumns where id=object_Id('student')
go
select name, length, COLLATION from syscolumns where id=object_Id('course')
go
select name, length, COLLATION from syscolumns where id=object_Id('score')
go
--********** insert **********--
--********** Begin **********--
insert into score values('09011101','101',89);
insert into score values('09011101','102',78);
--********** End **********--
select * from score
go
--********** alt student table **********--
--********** Begin **********--
ALTER TABLE Student
ADD addr VARCHAR(256);
--********** End **********--
go
select name, length, COLLATION from syscolumns where id=object_Id('student')
go
--********** del score table **********--
--********** Begin **********--
drop table score;
--********** End **********--
go
GO
IF NOT EXISTS(Select 1 From Sysobjects Where Name='score') --查询表是否存在
BEGIN
PRINT 'NOT EXISTS TABLE score'
END
GO
第二关
相关知识
视图是什么
视图是一个虚拟表,其结构和内容是通过 SQL 查询获得的。用户可以通过 SQL 查询语句,像其他普通关系表一样,对视图中的数据进行查询。视图同样支持表的相关操作,并可以直接修改、添加、删除数据库中的真实数据。
视图通常用来集中、简化和自定义不同用户对数据库的不同认识,如视图可用作安全机制。方法是只允许用户由视图访问数据,而不授予用户直接访问数据表的权限。视图还可以用于提供向后兼容接口,来模拟曾经存在,但其架构已更改的表。
视图的优缺点
视图的优点
-
安全保密。通过视图,用户只能查询和修改他们所能见到的数据,对于数据库中的其他数据,则既看不见也取不到。通过视图,用户可以被限制在数据的不同子集上。
-
查询简单。视图能够从几个不同的关系表中提取数据,并且用一个单表,表示出来。利用视图,将多表查询转换成视图的单表查询。
-
结构简单。视图能够给用户一个“个性化”的数据库结构外观,用一组用户感兴趣的可见表,来代表这个数据库的内容。
-
隔离变化。视图能够代表一个一致的、非变化的数据。即使是在作为视图基础的数据表(基表),被分割、重新构造或者重命名的情况下,也是如此。
-
逻辑数据独立。视图可以使应用程序和数据库表在一定程度上独立。如果没有视图,应用一定是建立在表上。有了视图之后,程序可以建立在视图上,从而使程序独立于数据表。
视图的缺点
虽然视图存在上述优点,但在定义数据库对象时,不能不加选择地来定义视图,因为视图也存在一些缺点:
-
性能。 SQL Server 必须把视图查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询, SQL Server 也要把它变成一个复杂的结合体,需要花费一定的时间。
-
修改限制。当用户试图修改视图的某些信息时,数据库必须把它转化为对基本表的某些信息的修改,对于简单的视图来说,这是很方便的,但对于比较复杂的视图,可能是不可修改的。
操作视图
创建视图
使用 T-SQL 命令,创建视图的基本语法如下:
--语法
CREATE VIEW view_name
AS
SELECT column_name(s) FROM table_name
WHERE conditionview_name :指定创建视图的名称; column_name :指定视图中列名称; table_name :视图的基础表名称; condition : select 的限定条件。
下面是一个创建视图的实例:
--准备表和数据
create table studentTable(
id int identity(1,1) primary key,
name varchar(20),
gender char(2),
age int,
)
insert into studentTable (name,gender,age)
values
('刘备','男',28),
('张飞','男',24),
('关羽','男',26);
--删除已存在的视图student_view
if (exists (select * from sys.objects where name = 'student_view'))
drop view student_view
go
--创建视图student_view
create view student_view
as
select name,age from studentTable where age>24;
--查询视图
select * from student_view;通过创建的视图查询的结果:

通过视图向基本表中插入数据
--通过视图向基本表中插入数据
create view stu_insert_view(编号,姓名,性别,年龄)
as
select id,name,gender,age from studentTable;
go
select * from studentTable;
---插入一条数据
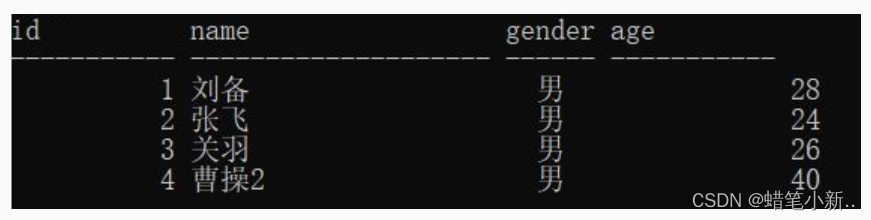
insert into stu_insert_view values('曹操2','男',40);
----查看插入记录之后表中的内容。
select * from studentTable;插入数据之前表中的数据如下:
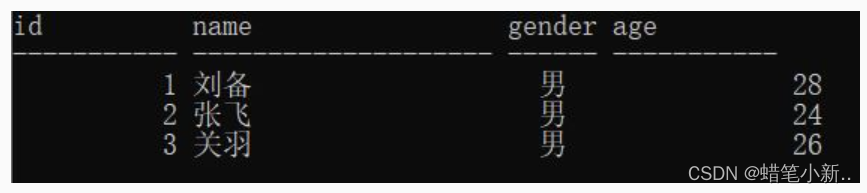
通过视图插入数据后,表中的数据如下:
通过视图修改基本表的数据
--查看修改之前的数据
select * from studentTable;
--修改数据
update student_view set age=30 where name='刘备';
--查看修改后的数据
select * from studentTable;修改视图之前表 studentTable 中的数据如下:

通过视图修改表 studentTable 中的数据后如下:

通过视图删除基本表的数据
通过视图删除基本表数据的语法如下:
delete view_name where condition;
--查看表中源数据
select * from studentTable;
--删除记录
delete student_view where name ='关羽';
--通过视图删除之后的数据
select * from studentTable;删除之前的数据:

删除之后的数据:

修改视图
可以使用 ALTER VIEW 语句来对已有的视图进行修改。
ALTER VIEW view_name AS select_statement语法说明如下:
view_name :指定视图的名称。该名称在数据库中必须是唯一的,不能与其他表或视图同名。
select_statement :指定创建视图的 SELECT 语句,可用于查询多个基表或源视图。
例如:
--修改视图
alter view student_view
as
select name,age from studentTable where age>30;此时再执行select * from student_view会得到如下年龄大于 30 的记录:

删除视图
可以使用 drop view 语句删除视图:
drop view view_name1,view_name2,......,view_nameN;
--该语句可以同时删除多个视图,只要在删除各视图名称之间用逗号分隔即可。例如
drop view student_view;编程要求
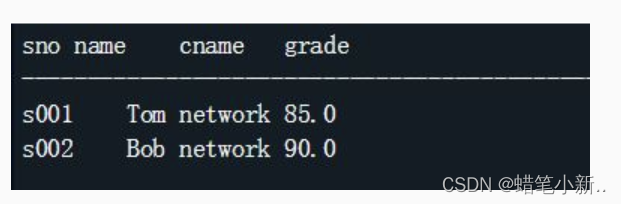
本次编程任务是,在右侧编辑区 create score_view_cdept 下的 Begin-End 区域补全代码,创建学生的成绩单视图,包括学号 sno 、姓名 name 、课程名 cname 和成绩 grade 字段。
涉及到的数据库和表都已经建立好了,并插入了相应的数据,具体如下: Student 表结构如下:
| sno | name | sex | birthday | discipline | school |
|---|---|---|---|---|---|
| s001 | Tom | male | 2019-06-01 | computer | information |
| s002 | Bob | male | 2019-06-01 | software | information |
| s003 | Alice | female | 2019-05-02 | computer | information |
| Course 表结构如下: |
| cno | cname | description | credit | cinstitution |
|---|---|---|---|---|
| c001 | network | computer network description | 2 | College Of Information Engineering |
| c002 | Java | java description | 2 | College Of Information Engineering |
Score 表结构如下:
| sno | cno | grade |
|---|---|---|
| s001 | c001 | 85 |
| s002 | c001 | 90 |
测试说明
平台将对你补充的代码进行评测,输出结果正确才可通关。
预期输出:
第二关实验代码
USE studentdb
go
SET NOCOUNT ON
go
--********** create score_view_cdept **********--
--********** Begin **********--
create view score_view_cdept
as
select student.sno,student.name,cname,grade
from student,course,score
where student.sno=score.sno and score.cno=course.cno
--********** End **********--
go
SQL-CRUD-1
第一关任务描述
本关任务:
- 用insert给数据库添加数据
相关知识
有关系student(sno,sname,ssex,sage,sdept),属性对应含义:学号,姓名,性别,所在系。现有的部分元组如下所示

insert 向数据库表插入数据的基本格式有三种:R,S是关系名
- 1.insert into R(属性列表) values (对应属性的值列表)
- 2.insert into R values(对应关系默认属性的值列表)
- 3.insert into R(属性列表) select 属性列表 from S R, S 可以是同一关系
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。 你只需根据右侧提示,完成以下任务:
- 1.补全右侧代码片段中 第一题 下 Begin-End 区间的代码,实现功能:MA系新来一名学生,学号07002,姓名 lucy, 性别 F,年龄21,请用insert语句将该学生信息加入student。
-
2.补全右侧代码片段中 第二题下 Begin-End 区间的代码,实现功能:新来一名学生,学号07003,姓名 Andy ,性别 F, 但尚未知道年龄, 也未确定分配到哪个系, 请插入已知信息到student。 。
-
3.补全右侧代码片段中 第三题 下 Begin-End 区间的代码,实现功能:有一名学生学号是04005,其余信息与学号04003相同,请将学生信息插入表student。
注意:sql语句不区分大小写,但是元组的数据是区分大小写的。另外在Mysql中,字符串用""括起来。
测试说明
测试过程:
-
本关涉及到的测试文件是 step1_test.sh ,平台将运行用户补全的 step1.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
第一关实验代码
USE test_wyy_db_guet
GO
SET NOCOUNT ON
-- ********** Begin ********** --
-- ********** 此处写第一题的SQL语句 ********** --
insert into student values('07002','lucy','F',21,'MA');
-- ********** End ********** --
GO
-- ********** Begin ********** --
-- ********** 此处写第二题的SQL语句 ********** --
insert into student(sno,sname,ssex) values('07003','Andy','F');
-- ********** End ********** --
GO
-- ********** Begin ********** --
-- ********** 此处写第三题的SQL语句 ********** --
insert into student(sno,sname,ssex,sage,sdept)
select '04005',sname,ssex,sage,sdept from student
where sno='04003';
-- ********** End ********** --
GO
--此处请不要随意修改
select * from student
GO第二关任务描述
- 使用update 修改关系中元组的值。
- 基本格式: update R set 属性名A=属性值B where 条件C 将关系R中满足条件C的元组中的属性A的值修改为B
编程要求
- 1.补全右侧代码片段中 第一题 下 Begin-End 区间的代码,将所有学生的年龄增加1岁;
- 2.补全右侧代码片段中 第二题 下 Begin-End 区间的代码,IS系改名为TS了,请修改相应学生的信息。
- 3.补全右侧代码片段中 第三题 下 Begin-End 区间的代码,MA系学生的学号前两位修改为08,其他不变. 学号长度为5,你们可以查阅right或substring函数,并用连接的方式得到新的学号。
使用的表结构: Student(Sno, Sname, Ssex, Sage, Sdept)
测试说明
测试过程:
-
本关涉及到的测试文件是 step2_test.sh ,平台将运行用户补全的 step2.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
第二关实验代码(right or substring)
USE test_wyy_db_guet
Go
SET NOCOUNT ON
-- ********** Begin ********** --
---------- 第一题----------
update student set sage=sage+1;
-- ********** End ********** --
GO
-- ********** Begin ********** --
---------- 第二题----------
update student set sdept='TS' where sdept='IS';
-- ********** End ********** --
GO
-- ********** Begin ********** --
---------- 第三题写法right----------
update student
set sno = '08' + right(sno,len(sno)-len('08'))
where sdept like 'MA%';
---------- 第三题写法substring----------
update student
set sno = '08' + substring(sno,3,5)
where sdept like 'MA%';
-- ********** End ********** --
GO
-- **********下面的语句请不要修改 ********** --
select * from student
GO
第三关任务描述
本关任务:使用 delete 删除符合条件的元组
相关知识
- delete语句格式 delete from R where 条件C
编程要求
我们已经为你建好了数据库与数据表R,S,并添加了相应的数据内容。 R代表本科生导师, S代表研究生导师,属性列一样,如下:
id varchar(20) not null,name varchar(30) not null,sex varchar(2) not null
-
1.补全右侧代码片段中 第一题 下 Begin-End 区间的代码,删除id是1002 的本科生导师元组
-
2.补全右侧代码片段中 第二题 下 Begin-End 区间的代码,删除研究生导师关系中,同时也是本科生导师,且性别为M的元组
-
3.补全右侧代码片段中 第三题 下 Begin-End 区间的代码,删除姓名是A开头的本科生导师元组
测试说明
测试过程:
-
本关涉及到的测试文件是 step3_test.sh ,平台将运行用户补全的 step3.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
第三关实验代码
USE test_wyy_db_guet
Go
SET NOCOUNT ON
---------- 第一题 ----------
-- ********** Begin ********** --
delete from R where id='1002';
-- ********** End ********** --
GO
---------- 第二题 ----------
-- ********** Begin ********** --
delete
from
S
where id in
(select id from R where sex = 'M');
-- ********** End ********** --
GO
---------- 第三题 ----------
-- ********** Begin ********** --
delete
from R
where name like 'A%';
-- ********** End ********** --
GO
--********** 下面的语句请不要删除 ********** --
select id,name,sex from R
union all
select id,name,sex from S
GOPS:
第三关的第二题查找id是因为其他属性均有可能重复(名字、性别);所以这里使用id而不用姓名。
SQL-CRUD-2数据库实验
第一关任务描述
在 sqlserver 中有三个高频使用的数据操作语句 (DML,Data Manipulation Language) ,熟练掌握这三个语句的使用方法,能让大家快速入门 sqlserver 。本关就先为大家重点介绍数据的插入( INSERT )。
相关知识
INSERT 顾名思义,就是向表(table)中插入行。
插入完整内容的行
向表中插入数据最简单的方法,就是使用 INSERT 语句。 INSERT 语句需要你声明要插入内容的表名和内容。举个“栗子”!
假设我们现在要建立一张名为 Customers 的空表,建立过程如下:
USE TestDb
CREATE TABLE Customers
(
cust_id int not null,
cust_name varchar(32) not null,
cust_city varchar(32) not null,
cust_email varchar(32) null
)
--查看表内容
SELECT * FROM Customers得到的空表是这样的:

接下来,我们要往空表中插入一条内容, 插入 (INSERT) 语句如下:
INSERT INTO Customers
VALUES (
'1000000006',
'Toy Land',
'New York',
NULL
)如图所示,是我们得到的结果,一条完整的内容已经被填入了空表中。
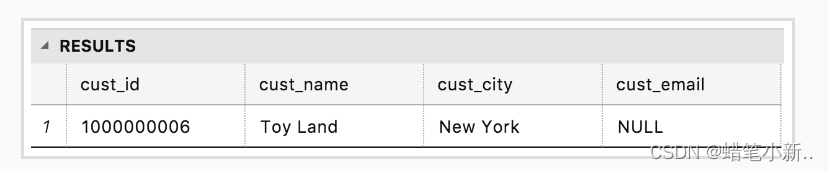
分析: 在这个例子中,我们把消费者的信息 (values) 依序插入了 Customers 表中。可能有人已经注意到, INSERT INTO 后面只跟了一个表名,这就意味着,我们插入内容的时候必须是依序全内容插入,即使内容为空,也必须用空值 NULL 来填补。

这样的插入虽然简单,但是很危险。一旦表的结构变了,你就会插错内容。下述的方法虽然相对繁琐,其最大的优点就是安全。它列出了你想要插入内容所对应的字段(column),一一对应就不容易出错。 比如:我们换下字段(column) 的顺序,看看会不会成功。
INSERT INTO Customers(
cust_id,
cust_email,
cust_name,
cust_city
)
VALUES (
'1000000006',
NULL,
'Toy Land',
'New York'
)从结果可以看出,即使打乱了顺序,这种方法也能将内容安全地插入。所以我们推荐写插入语句时,把字段(column)名也一并写进去。
插入选定内容的行
就像我刚才说的,把字段(column)名写入插入语句是个好办法!用这个方法,我们还能忽略某些字段,只插入我们最关心的数据。
比如,我们忽略 cust_email ,为表 Customers 插入内容。
INSERT INTO Customers(
cust_id,
cust_name,
cust_city
)
VALUES (
'1000000006',
'Toy Land',
'New York'
)从结果可以看出,我们成功地进行了有选择的插入。
综上所述,本关主要为大家讲解了数据的插入,祝大家顺利通过本关评测。
编程要求
在右侧根据提示补全语句,具体编程任务是:
-
补全右侧代码片段中 create database 下 Begin-End 区间的代码,用来建立数据库 school ;
-
补全右侧代码片段中 create table 下 Begin-End 区间的代码,用来建立空表 teacher ,其中表结构如下图所示;

- 补全右侧代码片段中 insert 下 Begin-End 区间的代码,用来将 Lucy 插入表中,其中数据内容如下图所示:

测试说明
测试过程:
-
本关涉及到的测试文件是 test1.shell ,平台将运行用户补全的 step1.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

第一关代码
-- ********** create database ********** --
-- ********** Begin ********** --
create database school;
-- ********** End ********** --
go
use school
go
-- ********** create table ********** --
-- ********** Begin ********** --
create table teacher(
ID int not null,
Name varchar(20) not null,
sex char(2) not null,
Phone varchar(20) default null
);
-- ********** End ********** --
go
SET NOCOUNT ON
-- ********** insert ********** --
-- ********** Begin ********** --
insert into teacher (ID,Name,sex)values(1,'Lucy','F');
-- ********** End ********** --
go
第二关任务描述
喂一句心灵鸡汤:人生,从来都没有 delete 键,你能做的,只有负重前行,心向阳光。
真的是这样吗?至少在虚拟世界,后悔药是有的卖的,你是可以重新来过的。
本关就为各位提供上帝视角般的 delete 键,接下来我们会重点介绍数据的删除(DELETE)。
相关知识
使用 DELETE 语句可以从表中删除数据。 DELETE 的两种用法如下所示:
-
删除表中的指定行;
-
删除表中的所有行。
删除表中的指定行
DELETE FROM 后面需要你指定删除内容所在的表, WHERE 语句是过滤语句,它用来帮你寻找哪条内容是你想要删除的。在下面的例子中,只有消费者 1000000006 的内容才会被删除。
DELETE FROM Customers WHERE cust_id=1000000006目前原始表有两条内容:

运行后我们成功地删除了 Toy Land 的数据。
删除表中的所有行
DELETE FROM Customers如果需要删除表中所有的行,只需要省略 WHERE 语句即可。
数据的删除就介绍到这里了,是不是跃跃欲试呢?
编程要求
根据右侧提示补全语句,具体编程任务是:
-
补全右侧代码片段中 create database 下 Begin-End 区间的代码,用来建立数据库 website ;
-
补全右侧代码片段中 create table 下 Begin-End 区间的代码,用来建立空表 shopping ,其中表结构如下图所示:

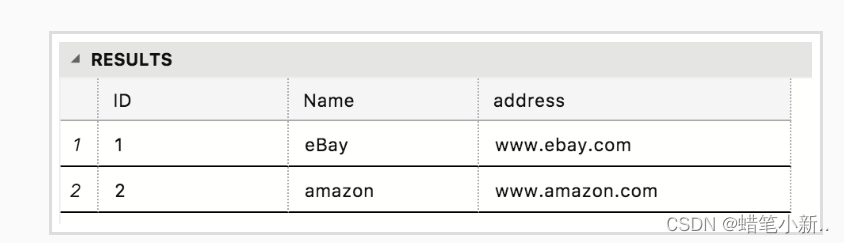
- 补全右侧代码片段中 insert 下 Begin-End 区间的代码,用来插入内容 amazon ,具体内容如下表所示: (我们已经事先帮你插入了内容 eBay ,所以你只要关注 amazon 的插入即可)
- 补全右侧代码片段中 delete 下 Begin-End 区间的代码,用来删除内容 eBay 。
如果我们使用语句:
create TABLE shopping
(
ID int IDENTITY(1,1) not null
)会使字段 ID 的数字自增。本关要求同学们使用该语句,但同学们插入内容的时候,请不要给字段 ID 赋值,因为它自己会自增!
测试说明
测试过程:
-
本关涉及到的测试文件是 test2.shell ,平台将运行用户补全的 step2.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:
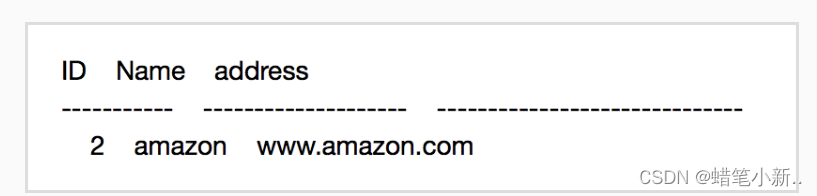
第二关代码
-- ********** create database ********** --
-- ********** Begin ********** --
create database website;
-- ********** End ********** --
go
use website
go
-- ********** create table ********** --
-- ********** Begin ********** --
create table shopping (
ID int IDENTITY(1,1) not null,
Name varchar(20) not null,
address varchar(30) not null
);
-- ********** End ********** --
go
SET NOCOUNT ON
insert into shopping (Name, address) values ('eBay', 'www.ebay.com')
go
SET NOCOUNT ON
-- ********** insert ********** --
-- ********** Begin ********** --
insert into shopping (Name, address)
values
('amazon', 'www.amazon.com')
-- ********** End ********** --
go
SET NOCOUNT ON
-- ********** delete ********** --
-- ********** Begin ********** --
delete from shopping
where Name='eBay';
-- ********** End ********** --
go第三关任务描述
中国有句俗语:人生在世熟能无过,过而能改,善莫大焉!
错了并不可怕,改了还是一条好汉!本关就为各位着重介绍数据的更新 (UPDATE)。学习完后,你也有机会亲手试试,如何来修改数据库中的数据。
相关知识
通过上一关的学习,我们已经掌握了 DELETE 操作,相信很多人都躺着过关了!同样,UPDATE 也非常的简单,只要记住 UPDATE 语句三要素,就能轻松掌握。它们分别是:
需要更新的表(table)名;
需要更新的字段(column)名和它的新内容(row);
决定更新哪一条内容(row)的过滤条件。
让我们来看看,它是怎么更新表里的内容的吧。
更新表中的指定行
消费者 1000000005 之前没有在记录里留下他的 email ,如下图所示:
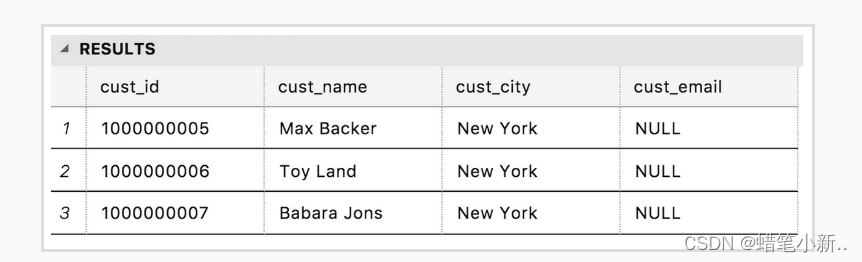
但是,现在他有了一个新邮箱,所以需要更新数据库里的数据,更新代码如下所示:
UPDATE Customers
SET cust_email = 'max@yahoo.com'
WHERE cust_id = '1000000005'看上去不难吧,来练练手吧!
编程要求
在右侧补全语句,具体编程任务是:
-
补全右侧代码片段中 create database 下 Begin-End 区间的代码,用来建立数据库 Books ;
-
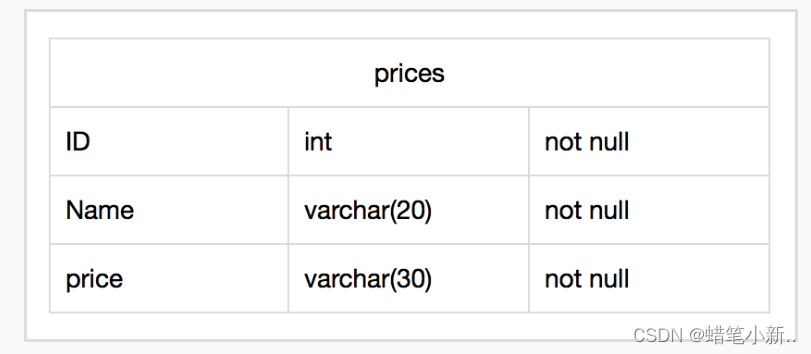
补全右侧代码片段中 create table 下 Begin-End 区间的代码,用来建立空表 prices ,其中表结构如下图所示:
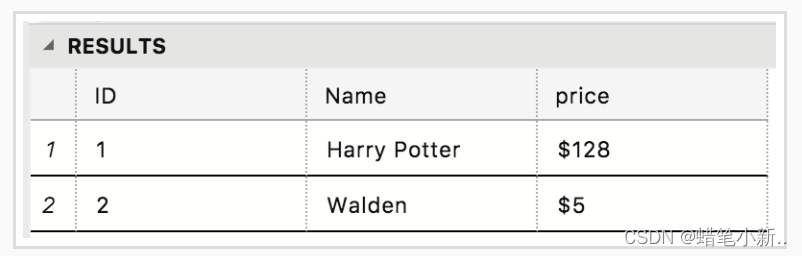
- 补全右侧代码片段中 insert 下 Begin-End 区间的代码,用来插入内容 Harry Potter ,具体内容如下表所示: (我们已经事先帮你插入了内容 Walden ,所以你只要关注 Harry Potter 的插入即可)
- 补全右侧代码片段中 update 下 Begin-End 区间的代码,用来将 Walden 的价格更新为 $6 。
| 小提示 |
如果我们使用语句:
create TABLE prices
(
ID int IDENTITY(1,1) not null
)会使字段 ID 的数字自增。本关要求同学们使用该语句,但同学们插入内容的时候请不要给字段 ID 赋值,因为它自己会自增!
测试说明
测试过程:
-
本关涉及到的测试文件是 test3.shell ,平台将运行用户补全的 step3.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

第三关代码
-- ********** create database ********** --
-- ********** Begin ********** --
create database Books;
-- ********** End ********** --
go
use Books
go
-- ********** create table ********** --
-- ********** Begin ********** --
create table prices
(
ID int IDENTITY(1,1) not null,
Name varchar(20) not null,
price varchar(30) not null
);
-- ********** End ********** --
go
SET NOCOUNT ON
-- ********** insert ********** --
-- ********** Begin ********** --
insert into prices (Name,price)values('Harry Potter','$128')
-- ********** End ********** --
go
SET NOCOUNT ON
insert into prices (Name,price)values ('Walden', '$5')
go
SET NOCOUNT ON
-- ********** update ********** --
-- ********** Begin ********** --
update prices
set price='$6'
where ID=2;
-- ********** End ********** --
goSQL简单查询-2
第一关任务描述
本关任务:
-
用 SELECT 语句检索数据表中指定字段的数据;
-
用 SELECT 语句检索数据表中所有字段的数据。
相关知识
为了完成本关任务,你需要掌握:1.如何获取数据表中指定字段的数据,2.如何获取数据表中的所有数据。
若想使用 SELECT 语句来检索数据表中的数据,你至少得弄清楚两个重要的信息:(1) 你想检索的是什么?(2) 你想检索的内容它在什么地方?
检索数据表中一个字段的内容
我们将从最简单的 SELECT 语句开始学习。
语法规则为: SELECT 字段名 FROM 表名
举个例子 我们想从表 Customers 中得到 cust_name 字段所有的内容,即所有人的姓名。表 Customers 的内容如下图所示:
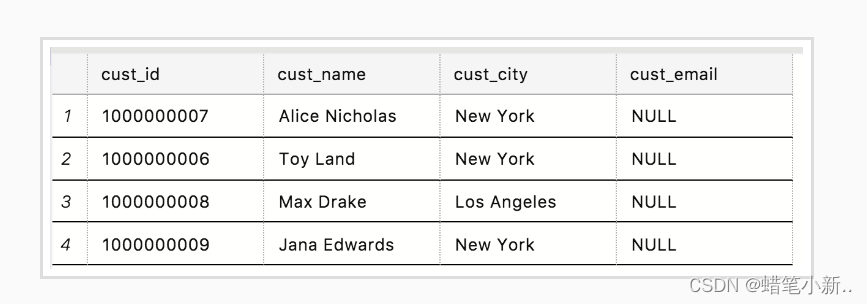
输入:
SELECT cust_name
FROM Customers输出:

我们成功从表 Customers 中检索到了字段 cust_name 的内容。
检索数据表中多个字段的内容
如果我想检索更多的字段呢?当然可以做到,而且语法结构与检索单个字段的内容类似,只需要你把想要检索的字段,统统放到 SELECT 后面就可以了,记得要加逗号隔开。
语法规则为: SELECT 字段名1, 字段名2, 字段名3 FROM 表名
举个例子 我们想从表 Customers 中得到 cust_id 和 cust_name 字段所有的内容。
输入:
SELECT cust_id, cust_name
FROM Customers输出:
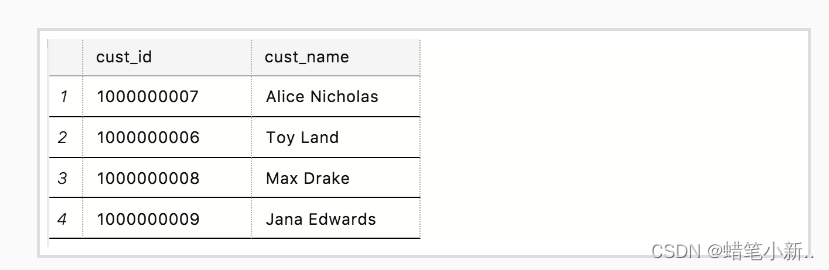
可以看到,我们成功从表 Customers 中检索到了字段 cust_id 和 cust_name 的内容。
检索数据表中所有字段的内容
如果我想检索一张表内的所有字段呢?是不是需要我把字段一个一个列出来呀?如果我不记得字段都有哪些了怎么办呢?当然有解决办法! 我们可以通过在 SELECT 语句后使用 * 来返回表内所有字段的内容。
语法规则为: SELECT * FROM 表名
举个例子 我们想从表 Customers 中得到所有字段的内容。
输入:
SELECT *
FROM Customers输出:

我们成功输出了表 Customers 中所有字段的所有内容。很简单对不对?
下面轮到你们来试一试了。
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。 你只需根据右侧提示,完成以下任务:
-
补全右侧代码片段中 retrieving multiple column 下 Begin-End 区间的代码,检索表 Products 中字段 prod_name 和 prod_price 的所有内容;
-
补全右侧代码片段中 retrieving all column 下 Begin-End 区间的代码,检索表 Products 中所有字段的内容。
其中表 Products 的结构如下图所示;
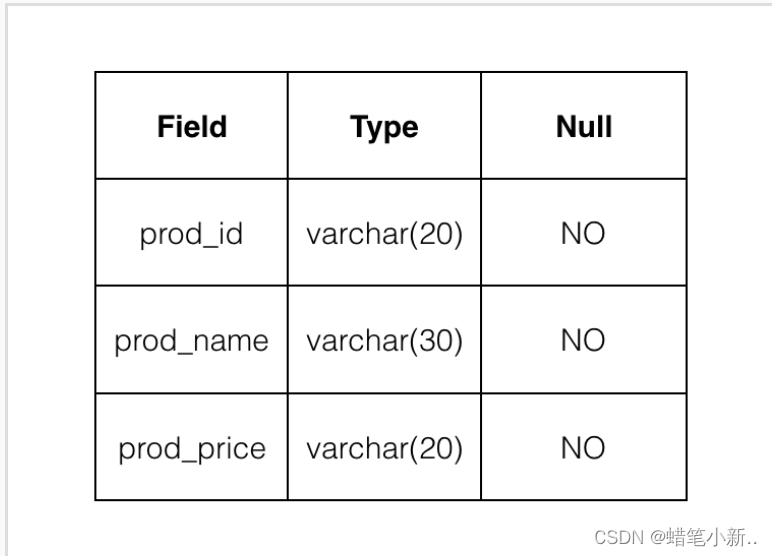
测试说明
测试过程:
-
本关涉及到的测试文件是 step1_test.sh ,平台将运行用户补全的 step1.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:
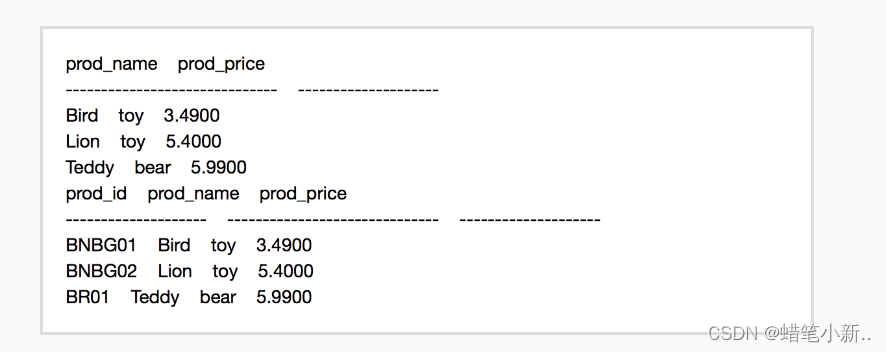
第一关实验代码
USE Mall
GO
SET NOCOUNT ON
---------- retrieving multiple column ----------
-- ********** Begin ********** --
select prod_name,prod_price from Products;
-- ********** End ********** --
GO
---------- retrieving all column ----------
-- ********** Begin ********** --
select * from Products;
-- ********** End ********** --
GO第二关任务描述
本关任务:
-
查询数据表中的指定字段的数据;
-
查询数据表中指定字段运算后的数据。
相关知识
为了完成本关任务,你需要掌握:1.使用限制关键字查询数据表中的指定字段的内容,2.使用运算符查询数据表中指定字段运算后的内容。
带限制条件的查询
SELECT 语句可以帮你返回所有匹配的内容,甚至整张表的内容。但是如果你仅仅是想要第一行的数据或者前几行的数据怎么办呢?好消息是我们可以通过限制条件来查询,不过限制条件的语法在各个数据库中的语法是不同的。在 SQL Server 中:
语法规则为: SELECT TOP 行数 字段名 FROM 表名
举个例子 我们想从表 Customers 中得到 cust_name 字段的前 3 行内容。表 Customers 的内容如下图所示:
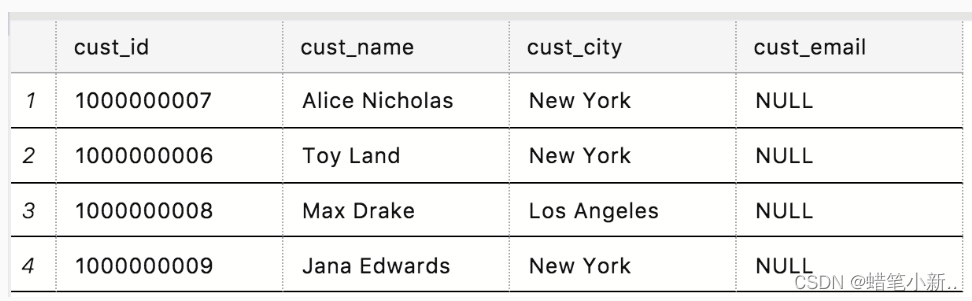
输入:
SELECT TOP 3 cust_name
FROM Customers输出:

当然,如果你使用的是 MYSQL 或者其他数据库,语法可不一样啊,你得去问 google 咯^-^。
表达式查询
有时候,你并不想知道某个字段的内容,而是想知道经过处理后的内容。这种情况有很多。比如,你想知道这一批的书打6折后都是多少钱?你想知道字段 A 和字段 B 加起来是多少?这是可以做到的,我们可以使用表达式查询来达到此目的。
语法规则为: SELECT 包含字段名的表达式 AS 新字段名 FROM 表名
其中,表达式计算的结果会放在新字段名下面,但是新字段名并没有存储在表中,而是暂时把结果返回给你,供你参考。
举个例子 我们想从把表 Customers 中每位消费者的 cust_id 都 +1 。表 Customers 的内容与上例的相同。
输入:
SELECT cust_id, cust_id+1 as new_cust_id
FROM Customers输出:

编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。 你只需:
- 补全右侧代码片段中 retrieving with limited 下 Begin-End 区间的代码,检索表 Products 中字段 prod_name 的前两项内容;
- 补全右侧代码片段中 retrieving with expression 下 Begin-End 区间的代码,检索表 Products 中字段 prod_price 的内容,并检索到字段 prod_price 打8折后的价钱,命名该打折后的价格为 discount_price 。
其中表 Products 的结构如下图所示:

测试说明
测试过程:
-
本关涉及到的测试文件是 step2_test.sh ,平台将运行用户补全的 step2.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

第二关实验代码
USE Mall
Go
SET NOCOUNT ON
---------- retrieving with limited ----------
-- ********** Begin ********** --
select top 2 prod_name
from Products;
-- ********** End ********** --
GO
---------- retrieving with expression ----------
-- ********** Begin ********** --
select prod_price,(prod_price*0.8) as discount_price
from Products
-- ********** End ********** --
GO第三关任务描述
本关任务:使用 WHERE 语句和逻辑表达式,检索数据表中指定字段的符合条件的数据。
相关知识
为了完成本关任务,你需要掌握:如何使用 WHERE 语句和操作符来选择符合条件的数据。
在实际情况中,我们不仅需要对某字段的全部数据进行检索,更多的是需要对符合我们需求的数据进行检索。SQL 语言的发明者当然想到了这些,为我们提供了更多的方法来检索你想要的数据。
WHERE 语句就是这样一种存在,只要把你的需求正确地放在 WHERE 后边,它就能帮你检索到你想要的内容。
下表为与 WHERE 语句搭配的操作符列表:

使用WHERE语句检索单范围数据
如果你想在房屋中介数据库中,寻找小于100万的房子,你应该怎么做?你是不是很自然的就想到了要用操作符 < 的。
让我们举个例子来看看,检索单范围数据是怎么实现的:
我们想从表 Customers 中找到消费大于 1000 的人。表 Customers 的内容如下图所示:
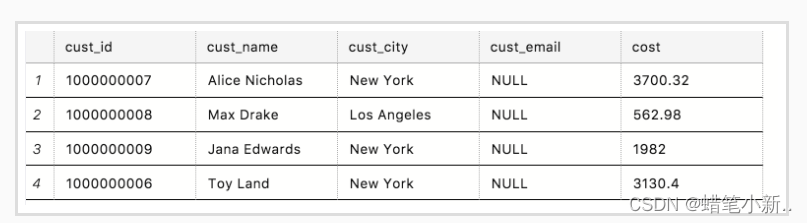
输入:
SELECT cust_name, cost
FROM Customers
WHERE cost > 1000输出:

不仅是 > ,其他操作符 < , <= , >= , !< , !> 的使用方法也是一样的。
使用WHERE语句检索双范围数据
还有一种情况,就是你心目中有一个理想的区间范围。比如你想买房,不能太便宜,因为便宜的有可能又小又偏僻,也不能太贵,因为。。。呵呵大家懂的。这时候,你就需要划定一个范围,SQL 很贴心的为大家提供了自然语言关键字,用来划定数字的范围。
语法规则为: WHERE 字段名 BETWEEN 数字1 AND 数字2
举个例子 我们想从表 Customers 中找到消费在 1000~3000 之间的人。表 Customers 的内容和上例相同。
输入:
SELECT cust_name, cost
FROM Customers
WHERE cost BETWEEN 1000 AND 3000输出:

Tips: 注意,使用 BETWEEN...AND... 时一定要记住较小的数在前边,较大的数在后边!
使用WHERE语句检索不匹配某条件的语句
有很多人可能有过这样的感觉,问你想要什么样的男/女朋友,你可能说想要这样的,那样的,好像都不错,看感觉吧。虽然你可能不知道你最想要什么,但是你一定知道你不想要什么。
SQL 语句也一样,它为你提供了选择不想要什么的机会。
举个例子 我们想从表 Customers 中找到消费者不在 New York 的人。表 Customers 的内容和上例相同。
输入:
SELECT cust_name, cust_city
FROM Customers
WHERE cust_city <> 'New York'
Tips: 注意,在 SQL Server 中,不等于只能用 <> 符号,不能使用 != 符号。
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。 你只需:
-
补全右侧代码片段中 retrieving with range 下 Begin-End 区间的代码,检索表 Products 中字段 prod_price 价钱介于 3 和 5 的内容,要求显示出商品名称和价钱;
-
补全右侧代码片段中 retrieving with nomatches 下 Begin-End 区间的代码,检索表 Products 中除了 Lion toy 的商品名称和价钱。
其中表 Products 的内容如下图所示:
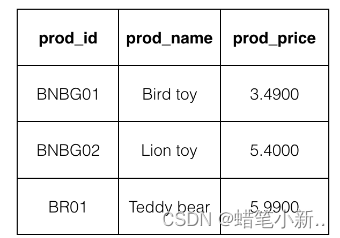
测试说明
测试过程:
-
本关涉及到的测试文件是 step3_test.sh ,平台将运行用户补全的 step3.sql 文件,得到数据;
-
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

第三关实验代码
USE Mall
Go
SET NOCOUNT ON
---------- retrieving with range ----------
-- ********** Begin ********** --
select prod_name,prod_price
from Products
where prod_price between 3 and 5
-- ********** End ********** --
GO
---------- retrieving with nomatches ----------
-- ********** Begin ********** --
select prod_name,prod_price
from Products
where prod_name <> 'Lion toy'
-- ********** End ********** --
GOJDBC基础编程练习
目录
第1关:JDBC更新员工密码
任务描述
本关任务:借助JDBC在库名tsgc中完成对数据表employee中性别为“女”的员工密码修改为“hello”;
表结构如图:
编程要求
根据提示,在右侧编辑器编写代码,在updateDB方法中完成"性别女"的员工密码修改
测试说明
平台会对你的代码进行运行测试,如果实际输出结果与预期结果相同,则通关;反之,则 GameOver。
实验一代码
package step1;
import java.sql.*;
public class UpdatePass {
// 修改数据
public static void updateDB() {
/********* Begin *********/
// 第一步:加载驱动
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
}
// 第二步:建立连接, "root"和"123123"是针对MySQL设置了用户名(root)和密码(123123)的情况
// 127.0.0.1:3306是mysql服务器地址及端口 数据库编码格式设置为utf-8
Connection conn = null;
PreparedStatement ps = null;
try {
String url = "jdbc:mysql://127.0.0.1:3306/tsgc?useUnicode=true&characterEncoding=utf8";
String user = "root";
String password = "123123";
conn = DriverManager.getConnection(url, user, password);
// 第三步:建立statement对象
String sql = "update employee set password='hello' where sex='女'";
ps = conn.prepareStatement(sql);
// 第四步:修改数据
ps.execute();
// 第五步:关闭statement对象和连接对象
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
ps.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/********* End *********/
}
}第2关:JDBC查询员工信息
任务描述
本关任务:借助JDBC在库名tsgc中完成对数据表employee数据的查询,并将查询结果在控制台打印输出;
表结构如图:
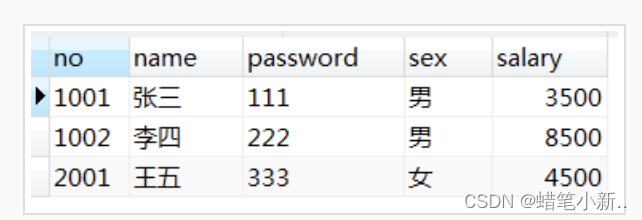
编程要求
根据提示,在右侧编辑器编写代码,在queryDB方法中完成表employee数据的查询,并按照输出格式进行输出(冒号为英文格式,每部分之间的分隔符是“/t”)。
测试说明
测试输入:无;
预期输出:
no:1001 name:张三 password:111 sex:男 salary:3500.0
no:1002 name:李四 password:222 sex:男 salary:8500.0
no:2001 name:王五 password:333 sex:女 salary:4500.0
开始你的任务吧,祝你成功!
实验二代码
package step1;
import java.sql.*;
public class QueryPass {
// 查询数据代码不用上实验报告
public static void queryDB() {
/********* Begin *********/
// 第一步:加载驱动
Connection conn = null;
PreparedStatement pst=null;
try{
Class.forName("com.mysql.jdbc.Driver");
// 第二步:建立连接, "root"和"123123"是针对MySQL设置了用户名(root)和密码(123123)的情况
// 127.0.0.1:3306是mysql服务器地址及端口 数据库编码格式设置为utf-8
String URL="jdbc:mysql://127.0.0.1:3306/tsgc?useUnicode=true&characterEncoding=utf8";
String user="root";
String psw="123123";
conn=DriverManager.getConnection(URL,user,psw);
// 第三步:建立statement对象
String sql="select * from employee";
pst=conn.prepareStatement(sql);
ResultSet rs = pst.executeQuery();
// 第四步:查询数据
while (rs.next()) {
String no = rs.getString(1);
String name = rs.getString(2);
Object psw1 = rs.getString(3);
Object sex = rs.getString(4);
double salary = rs.getDouble(5);
System.out.println("no:" + no + "\tname:" + name + "\tpassword:"+ psw1 + "\tsex:" + sex + "\tsalary:" + salary);
}
}catch(Exception ex){
ex.printStackTrace();
}
// 第五步:关闭statement对象和连接对象
finally {
// 第五步:关闭statement对象和连接对象
try {
pst.close();
conn.close();
} catch (SQLException ex) {
ex.printStackTrace();
}
}
/********* End *********/
}
}
SQL Server 存储过程——SQL Server 储存过程的创建与使用
任务描述
本关任务:学习 SQL Server 中存储过程的创建和使用。
相关知识
存储过程提供了很多 T-SQL 语言没有的高级特性,其传递参数和执行逻辑的能力,为处理各种复杂任务提供了支持。并且,由于存储过程是经过编译后,存储在服务器上的,这减少了执行过程中的传输带宽和执行时间。相反,如果使用 T-SQL ,则每次需要经过传输,再编译和执行。

什么是存储过程
存储过程是 SQL Server 中一个非常重要的数据库对象,它实际是一组为了完成特定功能的 T-SQL 语句集合。存储过程经编译后,存储在数据库中,用户通过指定存储过程的名称,并给出相应的参数,就可以对其进行执行。
SQL Server 中的存储过程具有如下特点:
- 能够包含执行各种数据库操作的语句,并且可以调用其他的存储过程;
- 能够接收输入参数,并以输出参数的形式,将多个数据值返回给调用程序或批处理;
- 向调用程序或批处理,返回一个表明成功或失败(及失败原因)的状态;
- 存储过程经过编译后,存储在数据库中,用户通过使用存储过程的名字,并指定参数来执行它。
存储过程不同于函数,存储过程不返回取代其名称的值,也不能直接在表达式中使用。
存储过程的类型
SQL Server 包含多种可用的存储过程,主要包括用户定义存储过程、扩展存储过程和系统存储过程。 ######用户定义存储过程 存储过程是指封装了可重用代码的模块或者例程。存储过程可以接收输入参数、向客户端返回表格或者标量结果和消息、调用数据定义语言( DDL )和数据操作语言( DML ),然后返回输入参数。 在 SQL Server 中,用户定义的存储过程有两种类型,即 T-SQL 和 CLR 。
- T-SQL 存储过程是指保存的 T-SQL 语句集合,可以接收和返回用户提供的参数。存储过程也可能从数据库向客户端应用程序返回数据。
- CLR 存储过程是指针对 .NET Framework 公共语言运行时方法的引用,可以接收和返回用户提供的参数。它们在 .NET Framework 程序集中,是作为类的公共静态方法来实现的。
扩展存储过程
扩展存储过程以在 SQL Server 环境外执行的动态链接库( DLL )来实现。扩展存储过程通过前缀 xp_ 来标识,它们以与系统存储过程相似的方式来执行。
系统存储过程
系统存储过程主要存储在 master 数据库中,并以 sp_ 为前缀,并且系统存储过程主要是从系统表中获取信息,从而为系统管理员 SQL Server 提供支持。通过系统存储过程, SQL Server 中的许多管理性或者信息性的活动,都可以被顺利有效地完成。
创建存储过程
在 SQL Server 中,使用 CREATE PROCEDURE 语句创建存储过程,具体的语法格式如下所示。
CREATE { PROC | PROCEDURE } procedure_name [ ; number ]
[ { @parameter data_type }
[ VARYING ] [ = default ] [ OUT | OUTPUT ] [READONLY]
[ WITH {RECOMPILE|ENCRYPTION|RECOMPILE,ENCRYPTION}]
[ FOR REPLICATION ]
AS { [ BEGIN ] sql_statement [;] [ ...n ] [ END ] }简单介绍个参数的含义。
- procedure_name 用于指定存储过程的名称;
- number 用于指定对同名的过程分组;
- @parameter 用于指定存储过程中的参数;
- data_type 用于指定参数的数据类型;
- VARYING 用于指定作为输出参数支持的结果集,仅适用于游标参数;
- default 用于指定参数的默认值;
- OUTPUT 用于指定参数是输出参数;
- RECOMPILE 用于指定数据库引擎不缓存该过程的计划,该过程在运行时编译;
- ENCRYPTION 用于指定 SQL Server 加密 syscomments 表中包含 CREATE PROCEDURE 语句文本的条目;
- FOR REPLICATION 用于指定不能在订阅服务器上执行为复制创建的存储过程;
- sql_statement 要包含在过程中的一个或多个 T-SQL 语句。
在命名自定义存储过程时,尽量不要使用 sp_ 作为名称前缀,避免与系统存储过程冲突。如果指定的名称与系统存储过程相同,由于系统存储过程优先级高,那么自定义的存储过程永远也不会执行。 ######创建简单存储过程 从 studentdb 数据库中获取学生学号、姓名和性别的存储过程。语句如下所示:
CREATE PROCEDURE proc_getInfos
AS
BEGIN
SELECT sno '学号', sname '姓名', sex '性别' from student
END创建带计算函数的存储过程
统计 studentdb 数据库中,男同学个数的存储过程。语句如下:
CREATE PROCEDURE proc_count_male
AS
BEGIN
SELECT COUNT(*) AS '男同学' frome student where sex='男'
END创建带输入参数的存储过程
根据用户输入的姓名,得到相应的信息的存储过程。语句如下:
CREATE PROCEDURE proc_select_where
@name varchar(50)
AS
BEGIN
SELECT * from student where sname=@name
END创建带输出参数的存储过程
创建一个存储过程,根据用户输入的年龄,返回大于输入年龄的学生有多少。语句如下:
CREATE PROCEDURE proc_select_ret
@age int,
@age_count int output
AS
BEGIN
SELECT @age_count=COUNT(*) from student where age>@age
END执行存储过程
在 SQL Server 中,可以使用 EXEC 或 EXECUTE 语句执行存储过程。 ######执行不带参数的存储过程
EXEC proc_getInfos执行带参数的存储过程
EXEC proc_select_where '张三'执行带输入输出参数的存储过程
DECLARE @age_ int=19;
DECLARE @count int;
EXEC proc_select_ret @age_, @count output
select '该班一共有'+LTRIM(STR(@count))+'人年龄大于'+LTRIM(STR(@age_));编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。 你只需:
- 补全右侧代码片段中 create proc_student_info 下的 Begin-End 区域间的代码,实现从表中查询所有学生基本信息的存储过程(存储过程名称一定要为 proc_student_info ,测试代码将调用 proc_student_info 存储过程,下面类似);
- 补全右侧代码片段中 create proc_sno 下的 Begin-End 区域间的代码,创建一个带参数的存储过程,输出指定学号的学生信息;
- 补全右侧代码片段中 create proc_add 下的 Begin-End 区域间的代码,创建一个带参数的存储过程,根据指定参数增加学生信息,如果学生编号已经存在则不能增加(调用此存储过程时,会依次填充各个字段值,请注意 insert 时,参数顺序与表字段的顺序一致);
- 补全右侧代码片段中 create student_del 下的 Begin-End 区域间的代码,创建一个带参数的存储过程,删除指定学号的学生信息。若成功,则输出 successfully deleted ;若没有该学号,则输出 No such student 。
表 student 的字段类型除了 birthday 是 date 类型,其余均为 varchar 类型,表内容如下:

测试说明
本关涉及到的测试文件是 step1.sh ,平台将运行用户补全的 step1.sql 文件,得到数据,然后执行以下操作:
-
将得到的数据与答案比较,判断程序是否正确;
-
如果操作正确,你将得到如下的结果:

实验代码
USE studentdb
go
SET NOCOUNT ON
go
--********** create proc_student_info **********--
--********** Begin **********--
create proc proc_student_info
as
Begin
select* from student
End
--********** End **********--
go
exec proc_student_info
go
--********** create proc_sno **********--
--********** Begin **********--
create proc proc_sno
@sno varchar(50)
as
Begin
select * from student where sno = @sno
End
--********** End **********--
go
exec proc_sno '1001'
go
--********** create proc_add **********--
--********** Begin **********--
create proc proc_add
@sno varchar(50),
@sname varchar(50),
@sex varchar(10),
@date date,
@dis varchar(50),
@school varchar(50)
as
Begin
if EXISTS(SELECT * FROM student WHERE sno=@sno)
print 'Already have a primary key '+@sno
else
insert into student values(@sno,@sname,@sex,@date,@dis,@school)
End
--********** End **********--
go
exec proc_add '1004','HMM','female','2019-6-2','English','national school'
go
exec proc_student_info
go
--********** create student_del **********--
--********** Begin **********--
create proc student_del
@sno varchar(50)
as
Begin
if EXISTS(select * from student where sno=@sno)
Begin
delete from student where sno = @sno
print'successfully deleted'
End
else
print'No such student'
End
--********** End **********--
go
exec student_del '1001'
go
exec proc_student_info
go
MySQL数据库 - 数据库创建及常用约束定义
第一题任务描述
本关任务:创建数据库。
相关知识
安装MySQL数据库是学习MySQL的第一步,为了完成本关任务,你需要掌握: 1.如何连接数据库; 2.如何创建数据库。
连接数据库
在操作数据库之前,需要连接它,输入命令:mysql -u用户名 -p密码。 在Educoder平台上连接数据库还需要加上一句-h127.0.0.1。
如下:

创建数据库
连接上MySQL之后就可以进行数据库的操作了。创建完数据库之后我们可以通过show databases;命令查看MySQL中已存在的数据库。
编程要求
在右侧命令行中连接MySQL,并创建一个名为MyDb的数据库。
连接数据库的用户名为:root,密码为:123123。
请注意:数据库名区分大小写。
完成数据库创建后,点评测按钮。
开始你的任务吧,祝你成功!
第一关答案

第二关任务描述
本关任务:在数据库中创建一个表。
要完成本关任务,你需要掌握:如何在指定数据库中创建表。
如何在指定数据库中创建表
我们先来了解一下在数据库中创建表的规则:
CREATE TABLE 表名(字段名,数据类型,字段名,数据类型,.....)
例如:

在数据库创建表,首先需要创建数据库(在MySQL数据库中是不区分大小写的不过数据库的名字是区分大小写的),如下:
CREATE DATABASE MyDb;
然后选择数据库:
USE MyDb;
最后创建t_user表:
CREATE TABLE t_user(id INT,username VARCHAR(32),password VARCHAR(32),phone VARCHAR(11));
如图:

表创建好之后可以验证是否创建成功。
语法如下:
DESCRIBE 表名;简写:
DESC 表名;例如:

编程要求
在右侧命令行中操作,创建数据库TestDb,在TestDb下创建表t_student,表结构如下:
| 字段名称 | 数据类型 | 备注 |
|---|---|---|
| sno | varchar(20) | 学号 不能为空 |
| sname | VARCHAR(32) | 姓名 不能为空 |
| dptno | INT | 所在学院编号 |
| ssex | varchar(2) | 性别 |
测试说明
操作完之后点击评测,如果数据库和表都创建成功,则闯关成功。
提示:如果右侧命令行无响应,是因为云端三十分钟会自动关闭容器,重新刷新页面即可解决问题,刷新之后环境会重置,所以需要重新创建数据库和表。
开始你的任务吧,祝你成功!
第二关答案

第三关任务描述
本关任务:创建表并且添加主键约束。
相关知识
主键,是表中一列或者多列的组合,主键约束(Primary Key Constraint)要求主键列的数据唯一,并且不允许为空,主键能够唯一的标识表中的每一条记录,可以结合外键来定义与不同数据表之间的关系。
为了完成本关任务,你需要掌握:怎么给表中的字段添加主键约束。
添加主键约束
有两种方式可以添加主键约束: 1.在定义列的同时指定主键; 2.在定义完字段之后再指定主键。
(1) 在定义列的同时指定主键:

(2) 在定义完所有列之后指定主键。

多字段联合主键
在开发中还有一种情况很常见,就是将几个字段联合在一起作为主键,那这个在代码中怎么实现呢? 举个例子,我们将员工的名字和部门ID联合起来作为主键:
CREATE TABLE t_emp2(name VARCHAR(32),deptId INT,salary FLOAT,PRIMARY KEY(name,deptId))
语句执行后,会将name和deptId字段组合成为表t_emp2的多字段组合主键。
编程要求
在数据库TestDb(若无,则新建该数据库),中,创建两张表t_user1,t_user2,表结构如下,请为两张表分别创建主键约束,t_user1的主键为userId,t_user2的主键为联合主键,将字段name和phone作为t_user2的联合主键。
表t_user1
| 字段名 | 数据类型 | 备注 |
|---|---|---|
| useid | INT | 用户ID |
| name | VARCHAR(32) | 用户名 |
| password | VARCHAR(11) | 密码 |
| phone | VARCHAR(11) | 电话号码 |
| VARCHAR(32) | 邮箱 |
表t_user2
| 字段名 | 数据类型 | 备注 |
|---|---|---|
| name | VARCHAR(32) | 用户名 |
| phone | VARCHAR(11) | 电话号码 |
| VARCHAR(32) | 邮箱 |
测试说明
测评通过即为闯关通过!
提示:输入 drop table 表名可以删除表。
开始你的任务吧,祝你成功!
第三关答案


第四关任务描述
本关任务:给表添加外码。
相关知识
为了完成本关任务,你需要掌握: 1.什么是外码; 2.怎么给表添加外码。
外部关键字
外码是另一张表中的主码。**外码的主要作用是保持数据的一致性,完整性。

如图有两张表,classId 是T_Student的外码,是T_class 表的主键, 如果我们要删除T_class 表中classId为1的字段,会报错的,因为t_student表中有数据和classId为1的字段关联,是不能删除的,这样就保证了数据的一致性和完整性。 **需要先删除T__student表中classId为1的两个字段。
如何给表添加外码
在MySQL中给表中字段添加外键约束的语法规则如下:
CONSTRAINT 外键名 FOREIGN KEY (字段名) REFERENCES 主表名(主键名)
编程要求
创建两张表如下,给t_student表添加外码约束,外键为dptno,外键名称为fk_stu_depart。 表t_depart
| 字段名称 | 数据类型 | 备注 |
|---|---|---|
| dptno | INT | 专业号,主码 |
| dptname | VARCHAR(22) | 专业名称 |
表t_student
| 字段名称 | 数据类型 | 备注 |
|---|---|---|
| stid | varchar(12) | 学号,主码 |
| name | VARCHAR(22) | 学生姓名 |
| dptno | INT | 所在专业,外码 |
在创建表之前你需要先创建数据库:TestDb,并且将两张表创建在TestDb数据库中。
完成创建后,可以使用前面关卡使用过的命令查看表、表结构等,点测评通过即通过闯关。
第四关答案

第五关任务描述
本关任务:给表添加常用的约束。
相关知识
在数据库的使用过程中我们经常要限制属性的取值,比如有些属性不能为空,就需要添加非空约束,本关要求完成常用约束的添加和定义。
为了完成本关任务,需要掌握: 1.添加唯一约束; 2.添加非空约束; 3.添加默认约束; 4.设置属性的值自动增加。
唯一约束
唯一约束(Unique Constraint)要求该列唯一,允许为空,但是只能有一个空值。唯一约束可以确保一列或者几列不出现重复值。
定义部门表的部门名称唯一,SQL语句如下:关键词 UNIQUE。
CREATE TABLE t_dept(id INT PRIMARY KEY,name VARCHAR(22) UNIQUE,location VARCHAR(50))
添加非空约束
关键词:NOT NULL;
例如:
CREATE TABLE t_dept(id INT PRIMARY KEY,name VARCHAR(22) NOT NULL,location VARCHAR(50))
使用默认约束
默认约束:即给字段一个默认值。 关键词:DEFAULT;
例如:
CREATE TABLE t_emp(id INT PRIMARY KEY,name VARCHAR(22),sex VARCHAR(2) DEFAULT '男') DEFAULT CHARSET=utf8;
注意:
- 如果是添加字符串型默认值要使用单引号,如果是整型则不需要加任何符号;
- 如果要添加的是中文默认值,则需要加上
DEFAULT CHARSET=utf8;使用英文字符则不需要。
设置表的属性值自动增加
| id | name |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| ID每次自动加一 | 姓名 |
| ... | XXX |
| 10 | XXX |
关键词:AUTO_INCREMENT,默认情况下初始值和增量都为1。
例如:
CREATE TABLE t_tmp(id int PRIMARY KEY AUTO_INCREMENT,name VARCHAR(32))
编程要求
在数据库TestDb中创建表t_user,表结构如下:
| 字段名称 | 数据类型 | 备注 |
|---|---|---|
| id | INT | 用户ID,主键,自动增长 |
| username | varchar(32) | 用户名,非空,唯一 |
| sex | varchar(4) | 性别,默认“m” |
提示:若要给字段添加两个或者两个以上的约束,约束之间以空格隔开即可。
提示:可使用如下语句删除表。
DROP TABLE 表名;
第五关答案




















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











