




 本文详细探讨了随机数生成的原理、伪随机数生成器的安全性,包括PRNG的类型如线性同余生成器和Blum-Blum-ShubPRNG,以及如何确保熵的充足和PRNG的安全防御。此外,文章还涉及密码技术的正确应用,包括口令存储策略、身份认证、动态口令技术和软件保护技术,如代码混淆和分析方法如静态分析、污点分析和模糊测试。
本文详细探讨了随机数生成的原理、伪随机数生成器的安全性,包括PRNG的类型如线性同余生成器和Blum-Blum-ShubPRNG,以及如何确保熵的充足和PRNG的安全防御。此外,文章还涉及密码技术的正确应用,包括口令存储策略、身份认证、动态口令技术和软件保护技术,如代码混淆和分析方法如静态分析、污点分析和模糊测试。
将对授课剩下的部分的核心思想进行汇总,说明每一部分可能的攻击和防御,对核心知识进行梳理。
目录
随机数生成
PRNG
伪随机数生成器,所得的随机数是算法输出结果。如果seed确定输出也确定,并不是真正的随机数。后一个输出全由前一个决定(最后还是落脚到种子),如果知道了某个internal state,那么输出也就完全知道了。因为一般基于种子的保密而不是算法的保密。用时钟播种的伪随机数是可预测的。
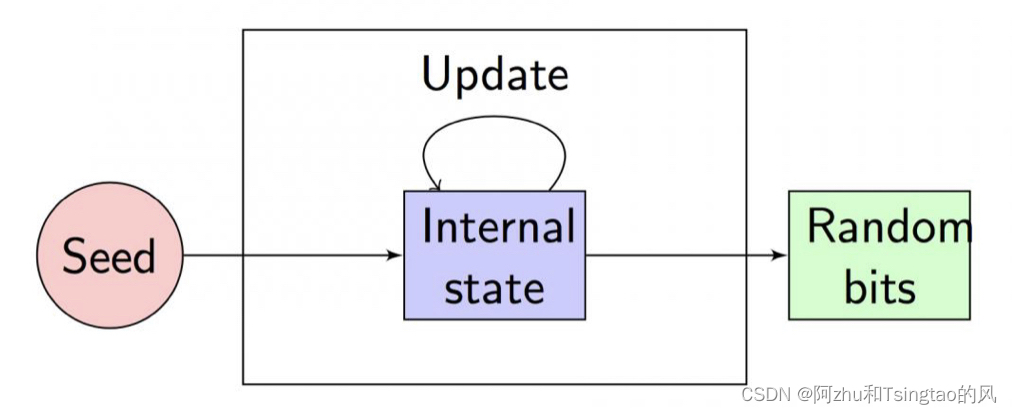
分类:
加密型PRNG:使用密码算法生成的随机数流。要保证足够的熵(无法获取种子),在算法已知的前提下也无法计算出随机数。
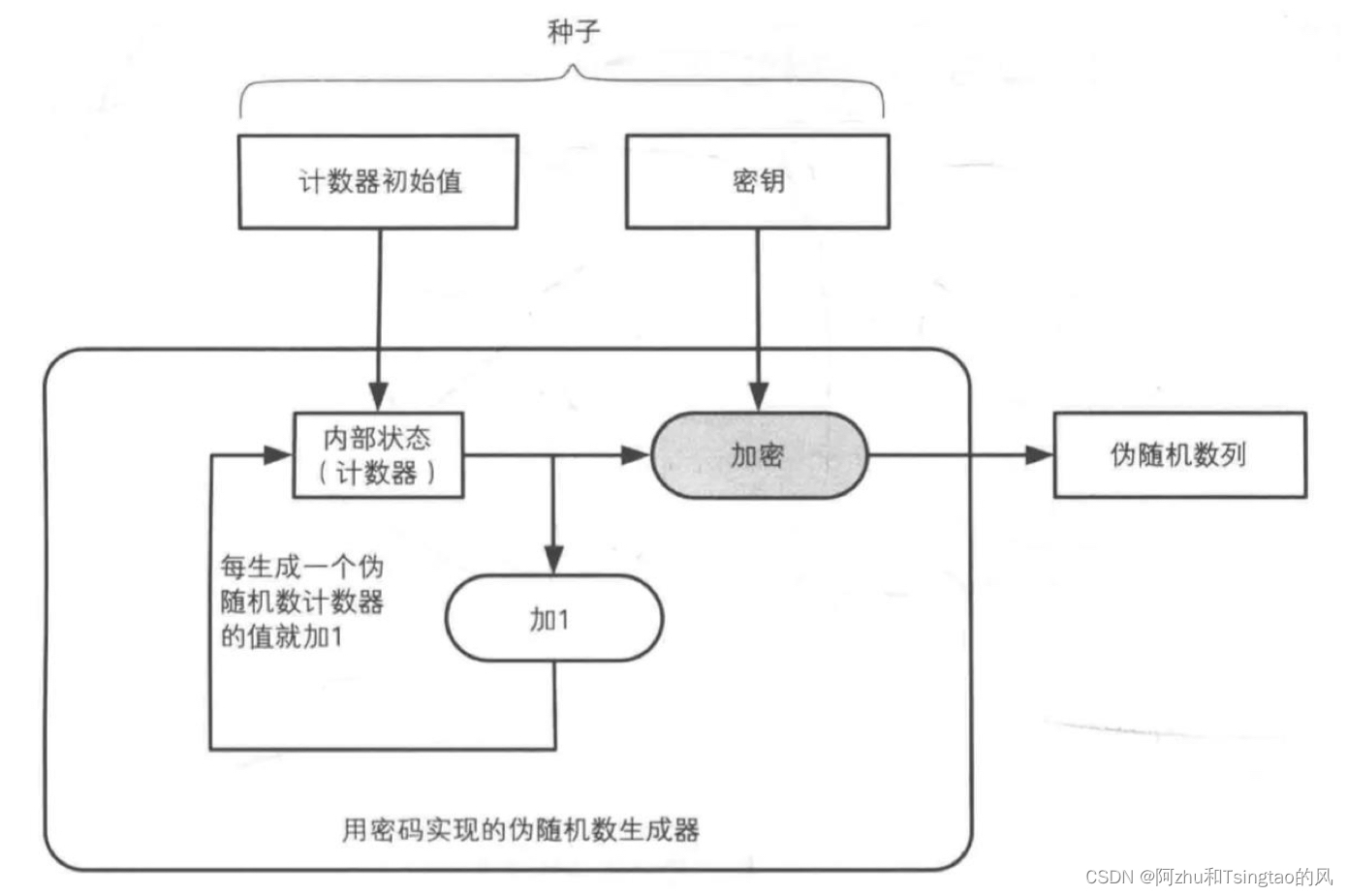
统计型PRNG:基于统计学原理生成的随机数流。产生的数据是均匀概率分布,但并不是几个不可预测的。rand() 和random()就是典型。
=>实例:
PRNG线性同余生成器:每一个输出都会泄露内部状态。所以就算是将seed位数提高到64bit或者128bit,也只是在计算上对攻击者造成难度,而不是原理上安全的。
Blum-Blum-Shub PRNG:加密型,基于因子分解,安全性可证明但速度很慢。
Tiny PRNG:基于AES可抵御所有已知密码攻击。
PRNG安全
攻击思想:本质是是否可以观察到规律,不是说保密/随机的种子一定安全,只要是可以被观察出规律/可以从上一个推出下一个,那么就是不安全的。
安全:要抵抗密码分析的攻击,使其难以从真正的随机数中区分出生成的伪随机数。要防御对内部状态的攻击,尽可能的保护内部状态。
防御:在保密种子的前提下,我们要进行深度防御。
熵
对数据随机性的度量,我们要做的是用收集好的熵作为PRNG的种子。并没有一个通用的度量指标。
来源:熵的来源可以是硬件设备的自然的随机的过程,比如噪声脉冲衰变等。也可以是软件源的随机性,比如无法预测的输入(键盘鼠标动作网络流量等)。当然由于计算机是完全确定的机器,所有在攻击者收集到一定信息的时候,纯软件方法收集的熵总是会被攻破。=>深度防御
来源问题:鼠标事件经常是可以监控到的,并且可能会有某些无意的重复性的动作发生,所以在保证没有恶意监听的情况下避免重复取样,并确保在生成随机数时有足够的熵。Linux中的/dev/random是真随机数发生器,在熵不足时会被阻塞,/dev/urandom会重复利用熵池中的数据生成随机数不会有阻塞。
安全问题:假设的攻击模型是攻击者无法生成相关数据或只能对时间戳进行猜测,但是攻击者同样可以通过复制完全相同的设备与动作进行信息的收集。
密码技术应用
常见的密码技术误用:伪随机数发生器的弱种子(时间硬编码的密钥)、弱加密算法及哈希(凯撒DESRC4)、密钥长度不足(可被穷举攻击)、分组密码ECB(难以隐藏明文结构)、分组密码CBC的弱IV(选择明文攻击)(并且在损坏时影响到2个分组,丢失时影响所有后续分组)
流密码:避免使用相同的密钥(随机数种子),可以通过收集足量的:来破解明文。
CBC的弱IV:可以通过构造明文来对比密文得到某些信息,因为IV被预测到了。=>使IV不可预测来防御。
避免设计自己的密码算法和安全协议。
PBE算法:用口令生成密钥并用密钥来加密,并将加密后的会话密钥加盐后通过物理方式保存。加盐的作用是防止KEK的安全强度不够。=>当然也要保证盐时不可以被预测的。
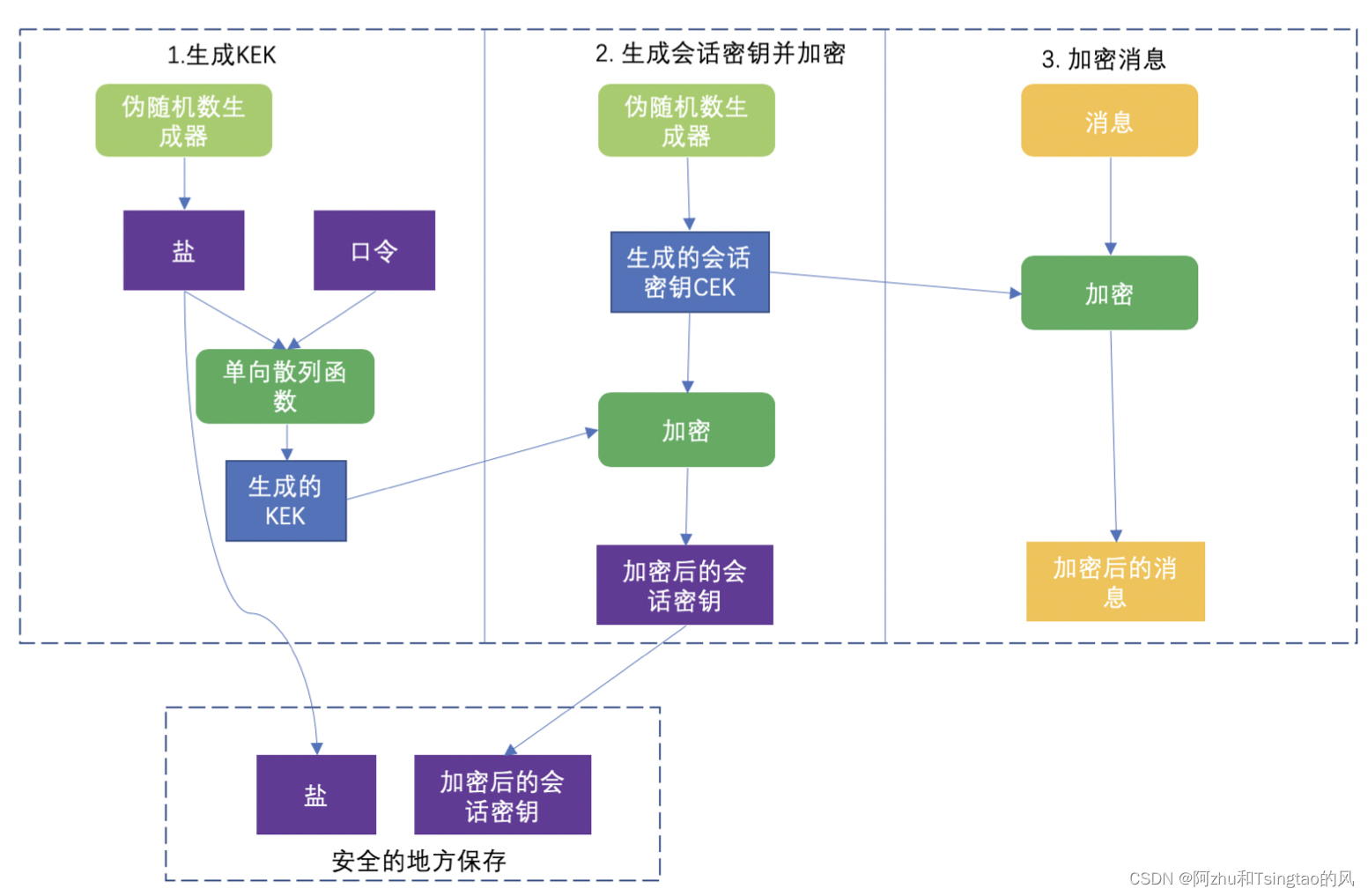
更改后的PBE:多次迭代KEK阶段的单向散列函数。增加破解的复杂度。
哈希作用:还可以运用在资源计量上。在服务之前客户需要计算一个运算复杂但验证容易的挑战(Hash cache:找到多少位的碰撞),这样可以环节拒绝服务攻击。
一次一密:很完美的加密方案,但是存在很多现实问题。比如说:密钥生成与分发,不能重复使用,可能难解码等。
身份认证
这里的重点在盐的应用,由于时间原因认证技术就不再赘述了,记住就行了没什么好分析的。
口令储存
口令不能以明文储存。于是衍生出了加密和散列的方式。
加密口令:将问题又变成了密钥的保护。
散列储存:彩虹表攻击(预计算口令散列表之后对比)=>通过加盐来解决。
加盐:明文加盐后hash储存。这样可以使同样的口令得到不同的Hash结果,并且增大了破解的难度同时使攻击者难以发现用户是不是在不同系统中使用相同口令。要注意的是:加盐并不能对某一特定口令提供保护,因为仍然可以针对性的暴力破解,只是将整体爆库的难度增加。同样的,盐值要不可预测。
动态口令
RSA SecurID:双口令=PIN+令牌码。令牌码是1min改变一次,通过128bit的唯一种子和RSA时间同步算法生成。种子是安全性基础,如果泄露就不应该再使用同一服务器提供的任何U盾服务。
哈希链:存用户的口令Hash1000次得到的结果,需要用户提供口令的Hash999次的结果,服务器对其计算一次Hash进行比对。成功后更新储存为口令Hash999次的结果。这样就算999次的结果泄露也没关系,因为现在服务器需要的是998次。
软件保护技术
同样,在本节仅整理了代码混淆部分。
代码混淆:是将代码转换成功能上等价但是难以阅读和理解的形式,增加反汇编的困难程度,但是不影响计算机执行。难以维护,所以保留原代码的程序树来维护。
基本技术:增加不执行的无用代码;更改变量名为无意义字符或重复字符;独特的数据编码;程序控制流的展开等。
评价标准:效能(人类能读懂代码有多困难)、抗逆(抵抗自动化分析混淆的工具)和花销。
没有百分之百安全的方式,但是可以让让黑客破解的难度远超他们预期。
程序分析
在本节中着重梳理软件的分析技术。
静态分析
分析程序而不运行。代码风格很影响静态分析,人难以理解的有时机器也难以理解。(个人认为这就是代码混淆可以防止静态分析的原因:破坏了结构)
污点分析
将输入的信息当作污点,追踪程序路径上的数据流动和可能的取值。
untainted<=tainted才是合法的。
分析途径:假设符号,对x=y生成约束qx>=qy(为了方便记忆:y赋值给x,y先于x,后的一定大于先的),之后解限定符的不等式,看是否在untainted<=tainted的合法范围内解出。如果无解,那么说明可能出现了非法流。
流敏感:处理多次赋值的情况,对同一变量的不同情况设定不同的限定符。在传统的分析中,同一个变量的限定符是相同的,这就会导致多次赋值的时候不考虑执行顺序引起误解的误报。
路径敏感:处理有分支的情况,分别记录每个路径的不同状态。流敏感在遇到分支路径时会出现误报,因为他会将分支里同一个变量的限定符还设定为同一个。
上下文敏感:处理多次调用函数的情况,对于每一次的调用都设置新的限定符。
为什么不用路径和流敏感分析?
因为他们都增加了很多的精度,而这些精度的负面影响是会降低可扩展性,最终降低我们可分析的程序规模。流敏感增加约束图中的节点数,路径敏感可能会出现路径爆炸的问题。
对于上下文敏感性也需要进行权衡精度和可扩展性的关系。
其他技术
符号执行技术:可以通过分析程序得到使特定区域代码执行的输入。输入符号而非具体值,在到达目标代码时得到相应的路径约束,然后通过约束求解出触发目标代码的具体值。每个符号的执行路径是满足具体路径条件的运行集,相比于普通测试,可以覆盖更多的执行空间。计算密集:由于路径是指数级增长的,仍会出现路径爆炸的情况。但是通用化了测试。
线性执行:按照一种代数的方式执行,得到一个可就能越界/不越界的范围,更好的覆盖执行空间。
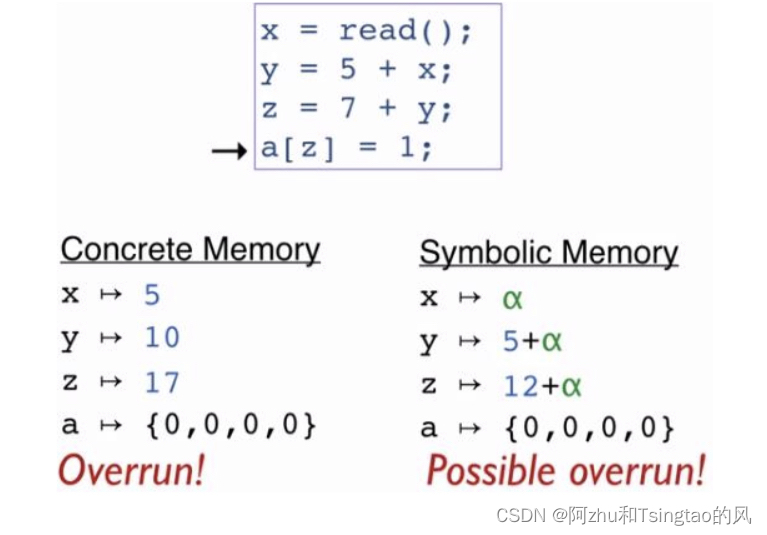
路径条件:路径是否可行通过路径条件Π是否满足来判断。路径约束的解可以用作执行该路径测试用例的输入。

路径和断言:类似于引入了额外的语句产生了新的路径条件,更精准的得到测试用例。仍然是上面的例子,现在引入额外的对Z的检查,而不是上面的z=1的检查。这样如果5/7行可以到达,那么说明产生了访问越界的问题。

动态分析
动态分析是在分析代码的时候执行代码
模糊测试
将生成的随机数输入程序中,检测程序是否出现异常,以发现漏洞和可能出现的程序错误。
分类:黑盒(只能看得到输入输出),基于语法的,白盒(可以知道内部执行逻辑)
测试数据:不能太随机,不然可能会出现浪费。Mutation(从已知合法的变换出新的),Generational(已知合法语法时),Combination结合前两种。
渗透测试:积极尝试查找可利用的漏洞来评估安全性,模拟黑客进行攻击。发掘的通常时真实漏洞没有误报,但是没有被渗透成功并不是安全的证据。要点是:熟悉目标领域的运作机制,在领域中构建系统(协议语言框架),软件/系统中常见弱点(Bug/配置错误设置错误)


















 505
505




 到【灌水乐园】发言
到【灌水乐园】发言







