




 本文介绍了如何在茴香豆Web版中创建自定义领域的知识问答助手,包括在HuixiangdouWeb应用中设置知识库、在InternLMStudio上部署技术助手,以及详细步骤如下载模型、安装依赖、配置文件和创建向量数据库。作者还演示了如何使用茴香豆搭建RAG助手,以及知识库的构建和运行过程。
本文介绍了如何在茴香豆Web版中创建自定义领域的知识问答助手,包括在HuixiangdouWeb应用中设置知识库、在InternLMStudio上部署技术助手,以及详细步骤如下载模型、安装依赖、配置文件和创建向量数据库。作者还演示了如何使用茴香豆搭建RAG助手,以及知识库的构建和运行过程。
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

文章目录
🍀在茴香豆 Web 版中创建自己领域的知识问答助手
我使用的文档正是https://arxiv.org/pdf/2312.10997.pdf
下面是我问的几个问题


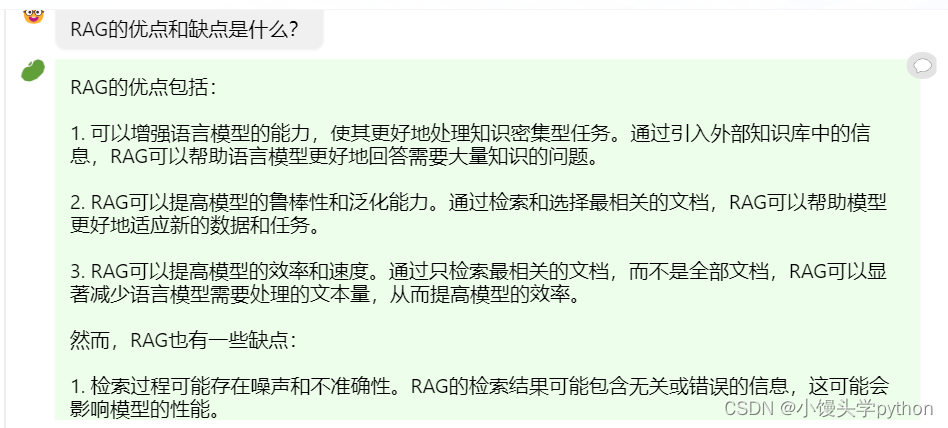


从某种意义上讲,可以帮助我们进行快速的查缺补漏哈
下面是具体的操作流程
首先我们打开网站
https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
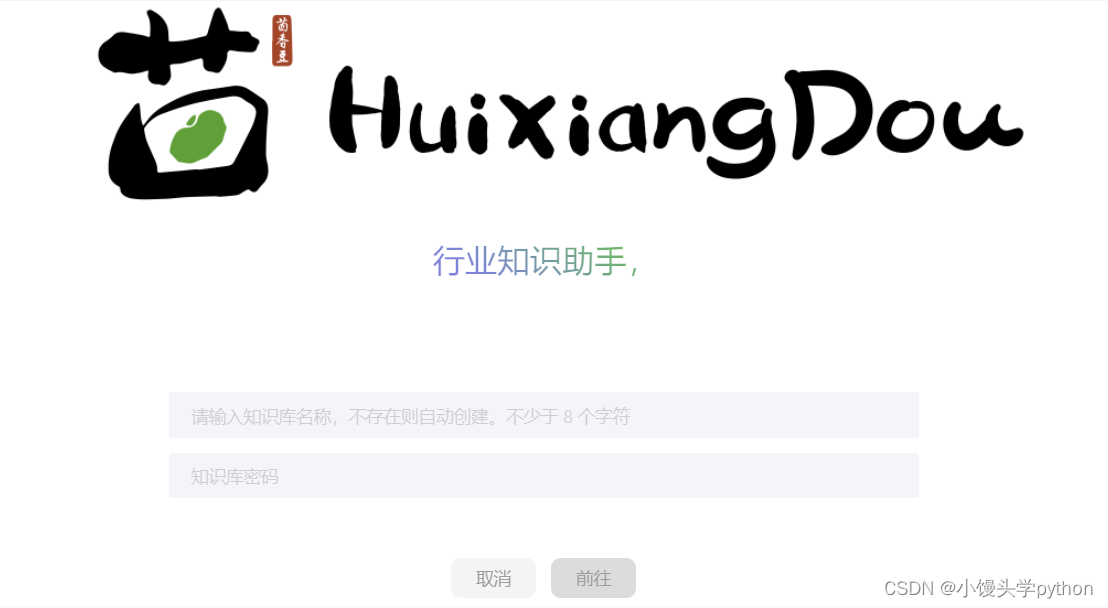
接下来输入知识库名称和密码即可,输入完成后就行下面的界面
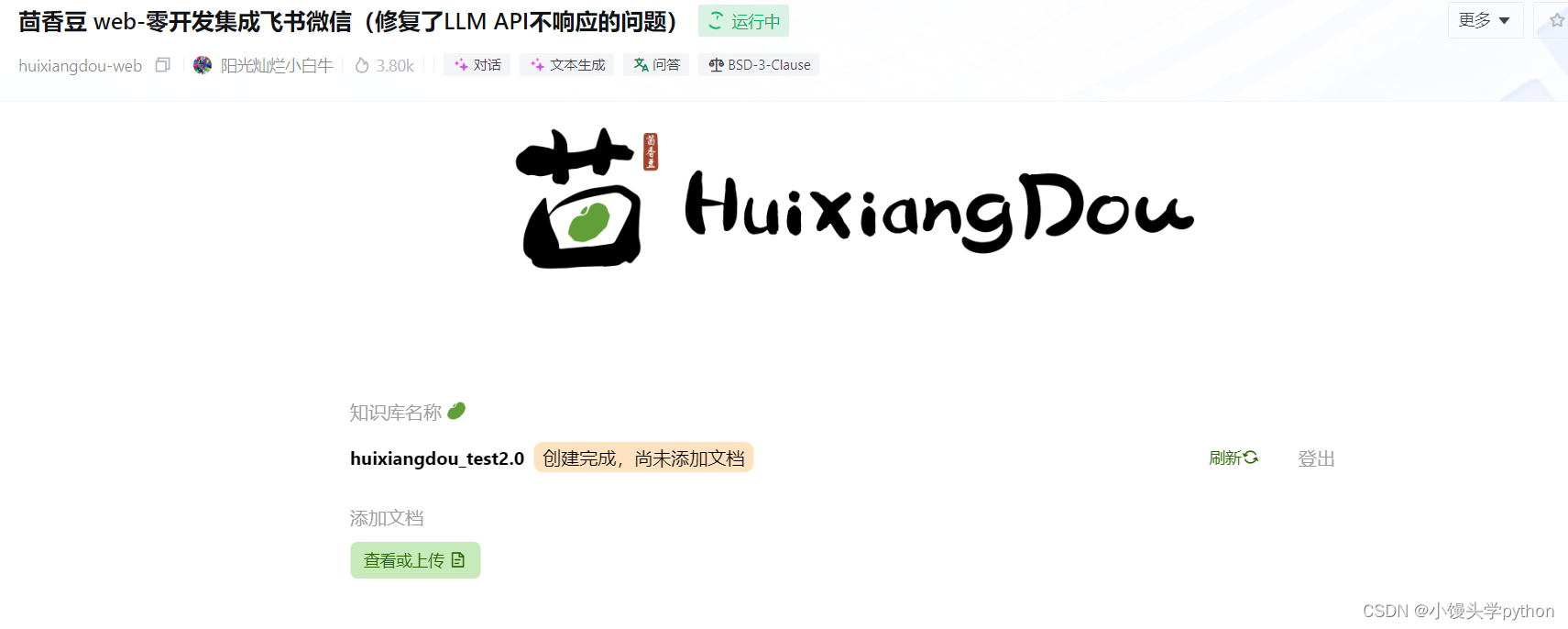
之后我们只需要点击查看或上传文档即可,这就相当于我们获得了一个外部的知识库,接下来我们就可以对我们简易的小助手进行提问了,如最上面几张图所示,当然我们也可以简单的测试一下玩一玩
当我们问你是谁的时候,这时候应该是固定回复了

那如果我们问了一个和文档不相关的问题的时候,模型会怎么回复呢
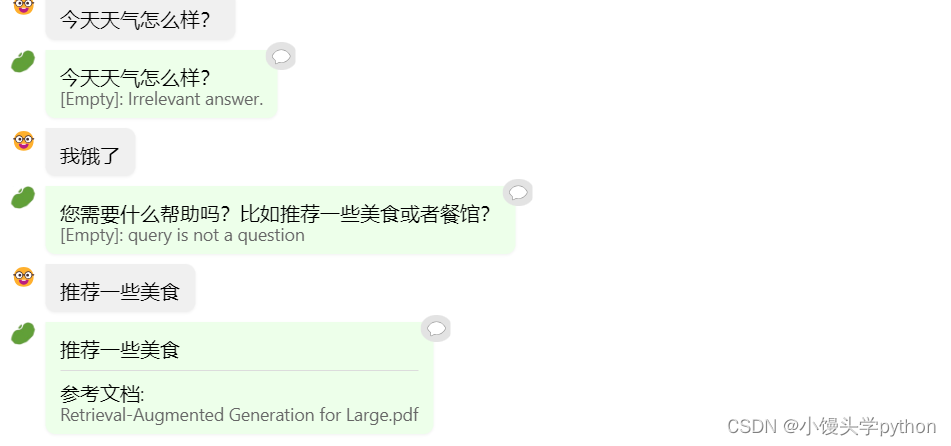
这时候就看起来很傻了哈哈哈~
🍀在 InternLM Studio 上部署茴香豆技术助手
首先还是进入到开发机
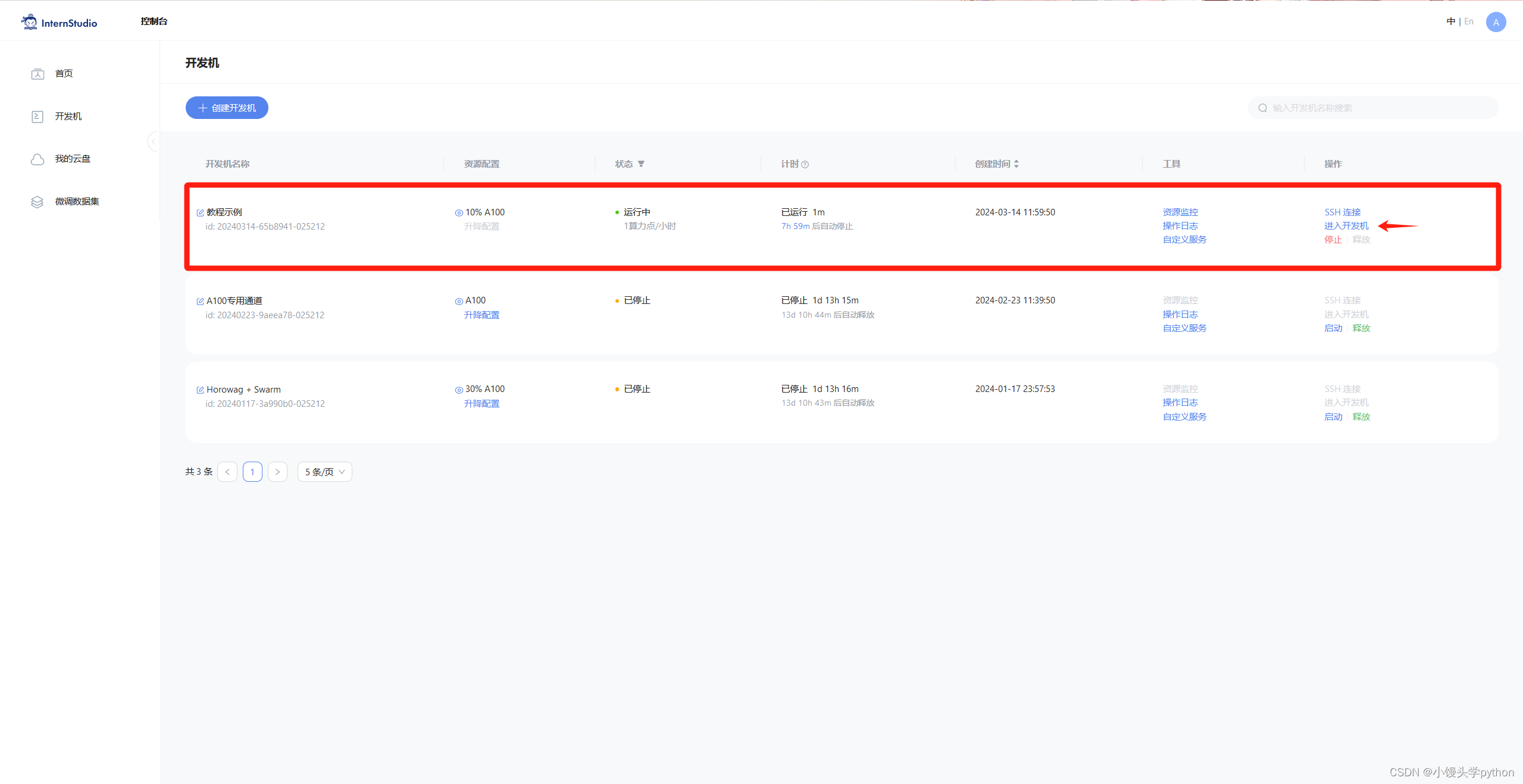
进入开发机后,从官方环境复制运行 InternLM 的基础环境,命名为 InternLM2_Huixiangdou,在命令行模式下运行:
studio-conda -o internlm-base -t InternLM2_Huixiangdou
复制完成后,在本地查看环境。
conda env list
运行 conda 命令,激活 InternLM2_Huixiangdou python 虚拟环境:
conda activate InternLM2_Huixiangdou
下载基础文件
复制茴香豆所需模型文件,为了减少下载和避免 HuggingFace 登录问题,所有作业和教程涉及的模型都已经存放在 Intern Studio 开发机共享文件中。本教程选用 InternLM2-Chat-7B 作为基础模型。
# 创建模型文件夹
cd /root && mkdir models
# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maida 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2238
2238


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










