




1 由来
在投入产出的关系中,越来越多的学者发现产出不仅仅只有期望产出,还有非期望产出,例如当在有GDP产出时候,在工业领域必然会产生二氧化碳、废水等非期望产出。那么原本CCR(规模报酬不变,即投入产出同比例增加)、BCC模型(规模报酬可变)考虑的投入越少导致产出越多就不能说明一个DMU是有效率的,如何将非期望产出考虑进去就成了问题。因此在此之后发展出SBM、DDF模型。
2. DDF模型(方向距离函数模型)
3.SBM模型
Tone 于2001年提出SBM模型(Slack Based Measure),优点在于成功解决了经向模型在效率评价中对于松弛变量的忽视问题。
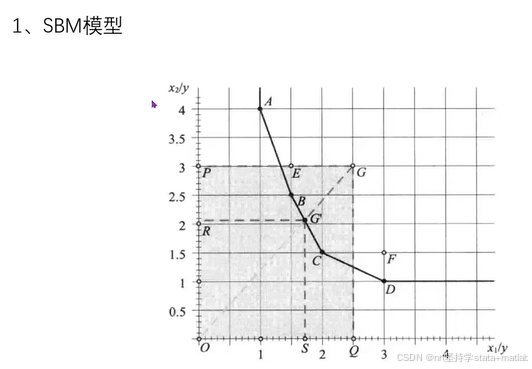
横轴:单位产出的投入1;
纵轴:单位产出的投入2;
投入越少越好,即前沿面越靠近原点对应的效率越高
GG‘:表示无效的程度
OG':表示有效的程度
1-GG'/OG':表示有效程度的衡量换句话说,就是径向效率值
| 小贴士:径向改进VS松弛改进
径向改进:投入同比例减少,例如EE'; 松弛改进:投入不同比例减少,例如E'B |
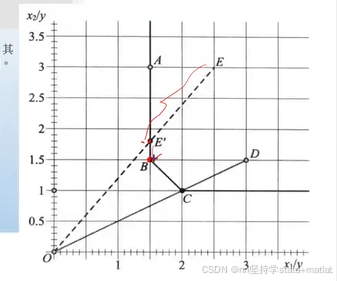
| 投入角度 | 在衡量效率的时候没有考虑生产的松弛 | 假定生产已经到前沿面了,那么投入要减少多少才能到标杆 |
| 产出角度 | 在衡量效率的时候没有考虑投入的松弛 | 假定投入已经到前沿面了,那么产出要增加多少才能到前沿面 |
| 非角度 | 同时考虑投入和产出 | 即考虑了投入减少的部分,也考虑了产出增加的部分 |





4.EBM模型(混合距离函数)
5.Malmquist指数、ML指数
补充请看:一文详细说明SBM、SBM-DDF、DDF、NDDF、ML指数是什么(学习笔记)_sbm-ddf模型-优快云博客
6.计算方法

| 分类 | 方法 | 优缺点 | ||
| 参数法 | 随机前沿分析法(SFA) | 需要准确预测生产函数的特定形状,然后利用SFA计算出生产过程的效率值 | ||
| 非参数法 | 数据包络分析法(DEA) | DEA-SBM超效率模型 | 包含非期望产出 | 无需提前设定投入和产出 直接按的生产函数关系 |
| Global-Malmquist-Luenberger(GML)指数 | 对数据量纲没有要求,信息反映充分,规避线性无解的问题 | |||
GML指数:前为止有三种方法可以实现。
第一种是早期用的比较多的基于Kaoru Tone(2001)的SBM模型(SBM-GML),
第二种是Fukuyama&Weber(2009)提出的方向SBM距离函数模型(GML-DDF)。
最后一种方法是Rolf Fare&Grosskopf(2010)基于方向距离函数的SBM模型(SBM-DDF模型),
三种方法的优劣及合理性评价,目前暂无定论。
| GM(Global Malmquist)指数 | 是通过全局DEA模型计算的M指数 | |
| ML(Malmquist_Luenberger)指数 | 考虑非期望产出DEA模型计算的M指数 | |
| GML(Global Malmquist_Luenberger)指数 | 考虑非期望产出的全局DEA模型计算的M指数 |
| M指数 | FGNZ分解 |
| RD分解 | |
| Zofio分解 |
参考文献:
贸易综合竞争力对绿色全要素生产率的影响研究——王双 西南财经大学硕士论文

















 3442
3442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









