





目录
8 跨领域应用的任务建模共性:从“任务设置”反推“共享结构”
8.4 能源电力、金融、教育、机器人与科学计算相关多任务设置
本文讲解内容来源为文献Abdelsamie, M.M., Azab, S.S. & Hefny, H.A. Deep multi-task learning: a review of concepts, methods, and cross-domain applications. Int J Data Sci Anal 21, 77 (2026). https://doi.org/10.1007/s41060-025-00892-y
属于对这篇文献内容的总结与提炼,便于国内读者学习。
1 引言
把“一个模型只做一件事”的单任务范式(Single-Task Learning, STL)换成“一个模型同时学多件相关的事”,并不是为了追求更热闹的模型结构,而是为了把机器学习中长期存在的“数据稀缺、泛化不稳、特征学习不够鲁棒”这些问题,转化为一个更可控的归纳偏置问题:如果若干任务之间共享底层语义、结构或可迁移的中间表示,那么让它们共同训练的过程就相当于对共享参数施加了更强的约束,使网络更倾向于学习“跨任务可复用”的表征,而不是对单一任务的偶然相关性过拟合。深度多任务学习(Deep Multi-Task Learning, Deep MTL)之所以值得单独讨论,是因为深度网络提供了丰富的参数共享方式、模块化结构与端到端优化手段,使得“共享什么、在哪里共享、共享多少、怎么平衡各任务损失”变成了一个可设计、可学习的系统工程问题,而不仅仅是把多个输出头接在同一个 backbone 上那么简单。与此同时,多任务训练天然是多目标优化:每个任务都在“拉着参数往自己的方向走”,共享层在不同梯度信号的拉扯下很容易出现冲突,正迁移与负迁移的边界也随之变得非常微妙,因此要想真正把多任务学习用好,理论层面的统一建模视角、共享机制的抽象、以及训练动力学的解释就显得格外重要。
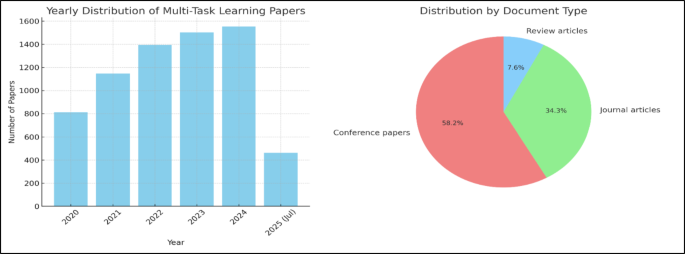
从文献计量角度也能看到,多任务学习在近几年呈现出明显增长,并且已经扩散到计算机科学、工程、数学、医学健康等多个学科方向:在一个面向 2020—2025(截至 2025 年中)的统计口径下,检索到的多任务学习相关记录规模达到 8,245 条,筛选去重后保留 6,872 条;其中计算机科学占比最显著(4,698 篇),工程(1,135 篇)、数学(498 篇)等方向紧随其后,医学健康相关也有一定规模。这样的分布暗示:深度多任务学习已经不是某个小圈子的技巧,而更像一种“跨任务共享表示”的通用建模范式,只要一个问题存在多个相关预测目标、多个相关数据源或多个相关训练信号,MTL 就有机会把这些信息组织成一个更稳定的学习过程。
2 理论知识与技术基础
2.1 “任务”的形式化定义:从映射到分布
在深度多任务学习语境里,“任务(task)”并不等价于某个行业应用,也不等价于某个数据集名字;更通用的理解是:任务是一类从输入空间到输出空间的映射问题,它对应一套数据分布、标签定义、评价指标与损失函数。把任务形式化有两个好处:第一,它让“任务相关性”不再停留在直觉层面,而可以通过输出语义、标注噪声、数据采样机制、甚至梯度相似性等角度去讨论;第二,它让多任务学习自然落到一个多分布、多损失的联合优化框架里,便于统一推导模型结构与训练策略。假设共有 T 个任务,每个任务 t 都有自己的数据集与经验分布:
![]()
其中 x 是输入样本(可以是图像、文本、时间序列、图结构等),y^(t) 是任务 t 的监督信号(可以是类别、回归值、分割掩码、序列标签或偏好排序等),n_t 是该任务可用样本量。多任务学习最关键的地方在于:不同任务的输入分布不一定完全一致,输出空间几乎肯定不一致,甚至任务的标注密度与噪声水平也会不同;因此,“把多任务看成把多个标签拼在一起的多标签学习”只是一种特殊情况。更一般的情形是:你需要设计某种共享表示或共享参数,使模型在面对不同任务的数据采样时,能够在共享子空间里积累可迁移知识,同时在任务私有分支里保留各自的差异性。
2.2 多任务学习的统一优化目标与参数分解
深度多任务学习通常把网络参数分成两类:一类是跨任务共享的参数(可以理解为共享编码器、共享特征提取器或共享主干),另一类是每个任务特有的参数(任务头、任务解码器、任务特定注意力模块等)。在最常见的“共享主干 + 多头输出”结构中,模型可以写成两段函数复合:共享部分把输入映射到某个中间表示 hs,然后任务头把 hs 映射到各自输出。用参数表示时,Ws 代表共享参数,Wt 代表任务 t 的私有参数。一个通用的多任务目标可以写为:
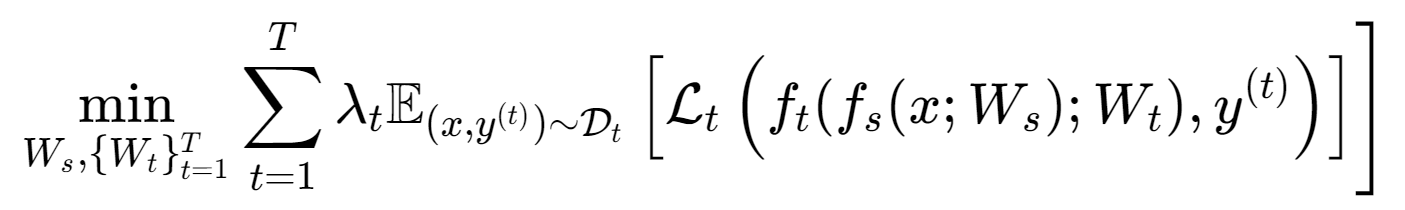
其中 fs 表示共享网络映射,ft 表示任务头映射,Lt 是任务 t 的损失函数,λt 是任务权重(控制各任务在联合目标中的相对重要性)。这一行公式在实践中看起来很朴素,但它把多任务学习的核心困难也全部暴露出来了:当 T 增大时,如何设定或学习 λt 才能避免某些任务“梯度更大、数据更多、目标更容易”而主导训练;当任务差异大时,共享参数 Ws 的梯度会来自多个损失的叠加,冲突会导致某些任务性能下降;当任务存在标签稀疏或部分标注时,期望项的采样方式也会影响训练稳定性。很多“看上去是结构创新”的 MTL 方法,实质上都在围绕这三个问题做不同层面的约束:要么改变共享的方式,要么改变损失的合成方式,要么改变梯度更新的方式。
2.3 共享表示的归纳偏置与正则化效应
为什么共享参数会带来泛化收益,一个常见解释是“正则化效应”:当多个任务共享同一套隐藏层时,这些共享层必须同时满足多个任务的预测需求,因此它更倾向于学习到稳定、普适的特征,而不是对单任务的偶然模式过拟合。这可以理解为一种结构化的归纳偏置:共享表示迫使网络在表示空间里找到跨任务的“交集部分”。当任务之间确实有共同的潜在因素(例如视觉场景理解中的边缘、纹理、几何;NLP 中的词法、句法、语义;医学数据中的生理指标共变结构),这种偏置会明显提高有效样本量与特征鲁棒性。反过来,如果任务之间缺乏共同因素,或者目标相互矛盾,那么共享就会把不相容的学习信号压到同一组参数里,导致性能下降,这就是多任务学习中特别强调的负迁移(negative transfer)。换句话说,MTL 的收益并不是“共享一定更好”,而是“共享是一把带方向性的正则化刀”,刀刃指向的方向由任务相关性决定。
为了把这种“共享即正则化”的直觉更工程化,一种常见做法是用显式正则项去鼓励任务参数之间相似,而不是强制它们完全相同;这就自然引出软参数共享(soft parameter sharing)。软共享本质上是把“共享表示”从结构层面挪到优化层面:结构上每个任务都有自己的参数,优化上用正则项让它们不要差得太远,只有当任务确实需要差异化时才允许偏离。这种思路非常适合“任务部分相关、但又不完全一致”的场景,因为它把共享程度变成了一个可调的连续量,而不是硬共享那种二值选择。
2.4 任务相关性、正迁移与负迁移:从梯度到表示空间
任务相关性常常被口头描述为“语义相近”“共享特征”“目标一致”,但在深度学习训练过程中,更直接的信号来自梯度:共享参数 Ws 的更新方向是各任务梯度的加权和,如果不同任务在共享参数上的梯度方向高度一致,那么它们会彼此促进,训练表现为正迁移;如果梯度方向经常相反或夹角很大,那么共享更新会互相抵消甚至拉扯,表现为负迁移。用余弦相似度描述这种关系很直观:
$$
\cos(g_i,g_j)=\frac{g_i^\top g_j}{|g_i|_2|g_j|_2}
$$
其中 gi 是任务 i 对共享参数的梯度,gj 是任务 j 对共享参数的梯度。cos 接近 1 表示两个任务在共享参数上的优化方向一致,接近 -1 则意味着强冲突。把任务关系放到梯度空间看,会带来一个重要启示:任务相关性并不是静态属性,它会随训练阶段变化。早期阶段共享层学习通用低级特征时,很多任务可能梯度一致;中后期任务开始追求各自指标时,冲突可能变强。于是,结构上“一刀切”的硬共享,很可能在后期出现过共享(oversharing)问题;而结构上太分离,又可能导致早期无法充分利用共享信号。深度多任务学习大量的结构创新(例如注意力型共享、门控共享、动态路由、跨层线性混合)从理论动机上都可以理解为:让共享程度随层级、随任务、随训练过程自适应,从而把负迁移压到可控范围内。
2.5 多目标优化视角:加权和只是起点
多任务学习是典型的多目标优化(multi-objective optimization):每个任务都有自己的损失函数,理想状态是找到一组参数使所有任务都尽可能好,但现实中经常存在不可兼得。最常用的做法是把多目标问题转成单目标,用加权和来优化:
$$
L(W)=\sum_{t=1}^{T}\lambda_t,L_t(W)
$$
其中 W 可以代表全部参数或仅共享参数。这个做法简单有效,但它把“任务权衡”完全塞进 λt 里,一旦权重设得不合适,就会出现任务失衡:有的任务因为数据量大或梯度大而主导更新,有的任务被压制而学不到。更进一步,当任务冲突很强时,任何固定权重都可能让某些任务陷入“被牺牲”的局面,这也解释了为什么在多任务学习里,权重学习、任务分组、梯度投影与结构自适应会被频繁讨论——它们本质上都在尝试回答一个问题:当目标不可兼得时,训练过程应当如何在参数空间里选择一个“更合理的折中点”,让模型既能共享带来的正则化收益,又不至于被冲突目标拖垮。
2.6 深度多任务学习的“结构—优化—数据”三要素
把深度多任务学习真正讲透,需要同时抓住结构、优化和数据这三条主线。结构决定了共享信息的通道与瓶颈:硬共享把共享变成结构事实,软共享把共享变成优化倾向,注意力/门控/路由结构把共享变成可学习的选择;优化决定了不同任务如何在共享参数上“谈判”:权重、调度、梯度冲突处理会改变每一步更新的方向与幅度;数据决定了谈判的筹码:任务样本量差异、标注密度差异、噪声差异会让某些任务在训练中天然更强势。很多多任务项目失败并不是“方法不够先进”,而是三要素之间存在隐含矛盾,比如用硬共享去训练差异很大的任务、用固定权重去面对极度不平衡的数据、用过度复杂的结构去处理小数据,从而把优化难度放大。把三要素放到一个框架里理解,才能在实践中做出更稳健的设计选择。
3 研究热度与跨学科分布:统计结果背后的方法含义
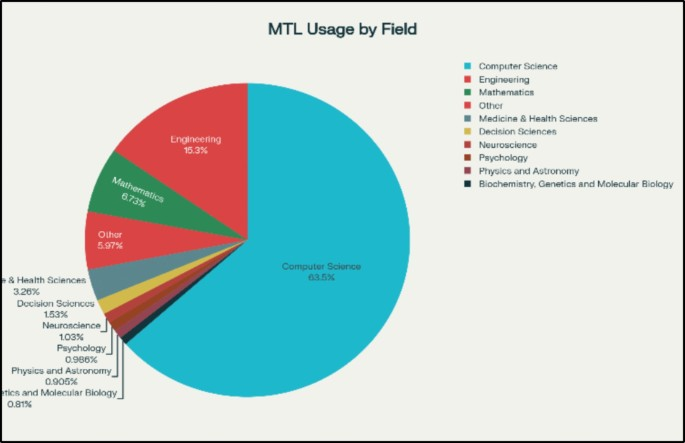
在 2020—2025(截至 2025 年中)的一个统计口径下,多任务学习相关研究呈现出明显的规模增长:检索阶段得到 8,245 条记录,经过筛选、限定文献类型并基于 DOI 与标题去重后保留 6,872 条用于分析。更值得注意的是学科分布:计算机科学 4,698 篇、工程 1,135 篇、数学 498 篇、医学健康 241 篇、决策科学 113 篇等,构成了多任务学习的主要“供给侧”。这些数字并不仅仅说明“大家都在发 MTL”,它更说明深度多任务学习的核心价值点更容易在技术密集型领域被兑现:这些领域往往天然存在多个相关预测目标、多个互补数据源、以及更强的计算基础设施,从而更容易探索复杂共享结构与多目标训练策略。反过来,MTL 在医学、健康、心理、教育等领域出现并扩展,也暗示“多源、多端点、多指标”正在成为数据驱动建模的常态,而多任务学习提供了一种把这种复杂性组织起来的方式。
4 MTL 常用共享策略:硬参数共享与软参数共享
4.1 硬参数共享:共享隐层、分离输出头
硬参数共享(hard parameter sharing)是最经典也最容易落地的一类深度多任务结构:多个任务共享同一组隐藏层参数(尤其是底层或主干网络),而在输出层使用各自独立的任务头。它的直观意义是:不同任务在前面几层“看到同样的世界”,在最后几层“说出不同的答案”。对很多任务高度相关的场景,这种结构既能显著减少参数量、降低训练成本,也能通过共享带来更强的正则化效应,从而缓解过拟合。结构上它非常像“一个 backbone + 多个 heads”,因此在工程上普及度极高。
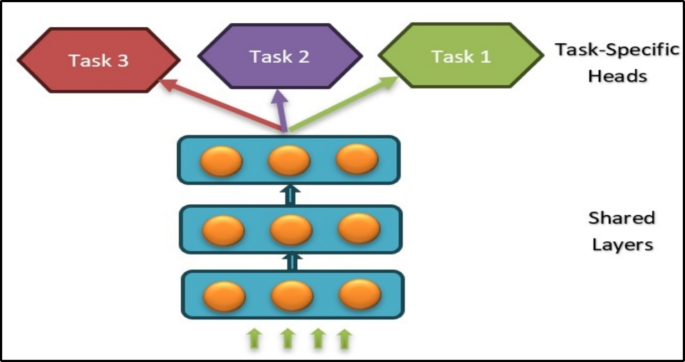
为了把硬共享写得更清楚,可以用共享表示 hs 与任务输出的函数复合表达:
$$
h_s = f_s(x; W_s)
$$
$$
\hat{y}_t = f_t(h_s; W_t),\quad t=1,\ldots,T
$$
$$
L(W_s,{W_t})=\sum_{t=1}^{T} L_t(\hat{y}_t, y^{(t)})
$$
其中 x 是输入,fs 是共享层映射,Ws 是共享参数,ft 是任务 t 的输出头映射,Wt 是任务参数,ŷt 是任务预测,Lt 是任务损失。硬共享的关键假设在于:存在一组共享参数 Ws,使得它学习到的 hs 对所有任务都有用。如果这个假设成立,那么共享层相当于把多个任务的数据联合起来训练同一套特征提取器,模型会更稳定;如果假设不成立,那么所有任务都被迫在同一个 hs 上竞争表达能力,负迁移就很难避免。
4.2 软参数共享:正则化驱动的“相似而非相同”
软参数共享(soft parameter sharing)在结构上更“分离”:每个任务有自己的网络参数,但通过正则项让不同任务的参数保持相似,从而实现间接共享。它的思想是把共享程度做成连续可控:任务相关性强时,正则项会把参数拉得更近;任务需要差异化时,模型允许参数偏离。实践中,这种方式常用于任务间存在一定冲突或差异,硬共享容易过共享导致负迁移的场景。
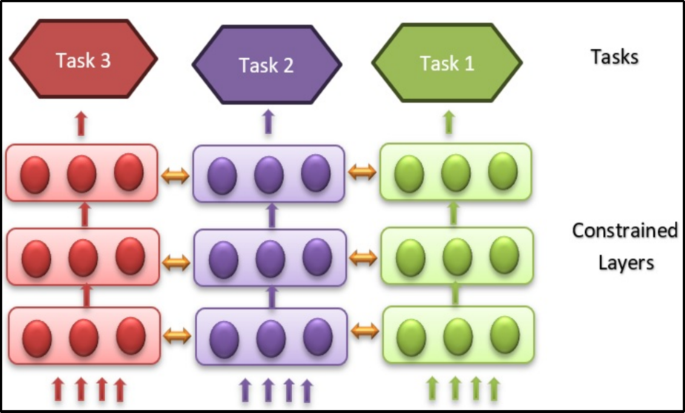
软共享常见的总损失形式可以写为:
$$
L = \sum_{t=1}^{T} L_t + \alpha,R(W_1, W_2, \ldots, W_T)
$$
其中 Lt 是各任务损失,R 是正则项,用来鼓励不同任务参数保持相似,α 控制正则强度。为了让正则项更直观,可以给出一种常见形式(并不限定必须如此):
$$
R(W_1,\ldots,W_T)=\sum_{i<j}|W_i-W_j|_F^2
$$
这里 Wi 表示任务 i 的参数集合,F 范数衡量参数差异。需要强调的是,“相似”并不意味着“完全相同”,而是一种受约束的偏离:当任务确实存在特定模式时,参数允许分化,以吸收任务特有的统计规律。软共享的优势是更灵活,缺点是参数量更大、训练更复杂,并且需要选择合适的正则形式与强度,否则可能出现“共享不足”导致无法发挥多任务收益。
4.3 硬共享与软共享对比:从结构约束到风险边界
在实际工程里,硬共享和软共享往往不是非此即彼,而是一个连续谱系的两端:硬共享把共享写死在结构里,软共享把共享交给损失函数与优化过程。更深入地看,它们对应两种不同的风险管理策略。硬共享通过减少参数自由度,天然降低过拟合风险和计算成本,但一旦任务冲突就容易出现负迁移;软共享通过保留任务私有参数,降低冲突风险并提高适配性,但会抬高计算与调参成本,并可能因自由度过大而在小数据上过拟合。把这种差异总结成表格会更清晰。
表1 硬参数共享与软参数共享对比
| 维度 | 硬参数共享(Hard parameter sharing) | 软参数共享(Soft parameter sharing) |
|---|---|---|
| 定义 | 所有任务共享一套共同参数 | 各任务拥有各自参数,但通过正则化等方式间接共享知识 |
| 任务相关性要求 | 需要任务高度相关 | 适用于任务部分相关或相关性较低的情形 |
| 灵活性 | 灵活性较低;难以学习强任务特有特征 | 灵活性更高;更容易学习任务特定特征 |
| 计算成本 | 较低(参数更少) | 较高(需要维护多套参数) |
| 过拟合风险 | 较低(模型复杂度被压缩) | 较高(每个任务自由度更大) |
| 适配性 | 对多样化任务需求适配有限 | 对不同任务的独特需求适配更好 |
| 实现难度 | 更简单、易实现 | 更复杂,需要额外机制支持任务特定学习 |
5 深度多任务学习架构谱系:单域、多模态、学习式与条件式
5.1 单域架构:共享主干、跨层信息流与预测蒸馏
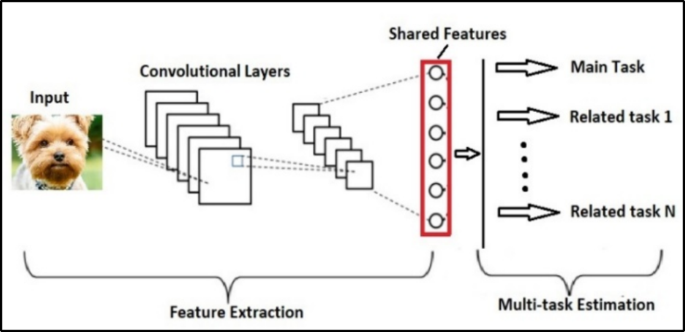
在单一领域(例如计算机视觉或 NLP)内,多任务架构的设计往往围绕“共享主干 + 任务头”的基本形态展开,但会在共享的颗粒度、共享位置以及任务间信息交互方式上做文章。最简单的形态就是共享主干(shared trunk):用一个共同的特征提取器抽取通用表示,然后每个任务用自己的输出头读取这份表示,完成检测、分割、分类、属性识别等不同目标。共享主干的优势在于可解释、可扩展、工程实现简单,尤其在视觉中不同任务往往共享底层纹理与形状特征时非常合适。为了避免共享主干在高层语义上过度耦合导致的冲突,很多结构会在主干之上加上任务特定注意力模块:共享层提供“全局特征集合”,每个任务用软注意力从中筛出更适配自己的子特征,从而实现“共享特征池 + 任务特定读取”。
当任务之间既相关又存在较强差异时,仅靠共享主干可能不够灵活,于是出现了另一类思路:每个任务保留一套网络,但允许它们在对应层之间交换信息。跨层信息流(cross-talk)或更典型的 cross-stitch 结构,就是把“共享”从“共享同一组参数”改成“共享同一层的表示并且共享比例可学习”。cross-stitch 的核心机制是对齐各任务网络的中间表示,然后用一个可学习的线性混合把不同任务的表示按比例融合到各自分支里,等价于让任务自己决定哪些层该共享、共享多少。这样做的理论含义非常明确:共享不是结构事实,而是一个在训练中被学习出来的门控矩阵,从而能在一定程度上缓解负迁移。
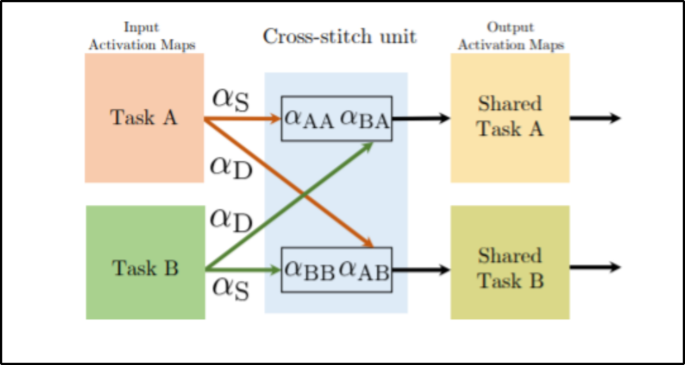
为了把 cross-stitch 的“可学习共享”写得更数学化,可以用两任务的某一层 l 表示举例(多任务可扩展为更高维的混合矩阵):
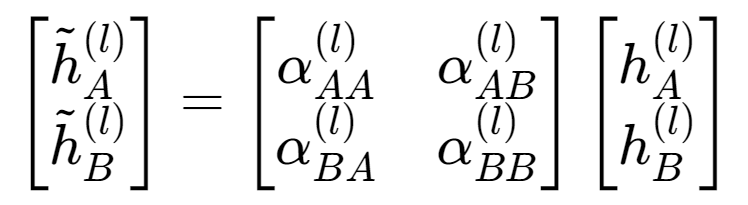
其中 hA^(l)、hB^(l) 是两任务在第 l 层各自分支产生的表示,混合矩阵的各元素 α 表示“本任务对自己表示的保留比例”和“从其他任务引入信息的比例”,带波浪线的表示是融合后的输入。这个公式的关键不在于线性代数,而在于它揭示了一个可控维度:共享程度从 0/1 变成了可学习的连续值,并且可以逐层变化。
除了在表示层面做混合,单域多任务还常见一种更“监督驱动”的信息流:预测蒸馏(prediction distillation)。它受到知识蒸馏思想启发:让某个任务的预测结果作为另一个任务的额外监督信号,从而把任务间关系编码到训练信号里,而不一定直接共享参数。直观上,这相当于把“任务 A 学到的中间结论”当成“任务 B 的软标签”或“辅助约束”,使得任务 B 在学习自身目标时,同时对齐任务 A 的预测结构。预测蒸馏的价值在于:即便任务的输出空间不同,只要它们之间存在可表达的关联(例如深度估计与语义分割在几何与语义层面互补),就能通过预测层面的互监督建立联系。
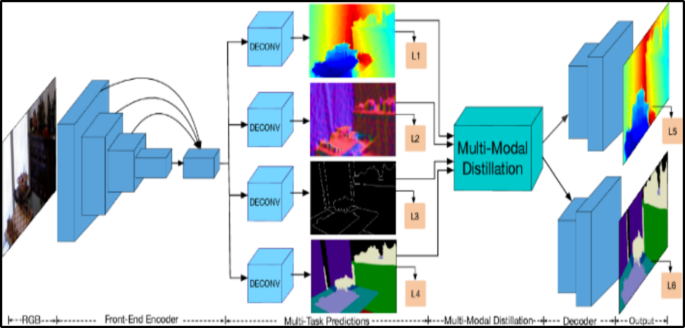
如果用一个抽象损失来表达预测蒸馏的思想,可以写成“每个任务既要对齐真实标签,也要对齐来自其他任务的教师信号”的形式:
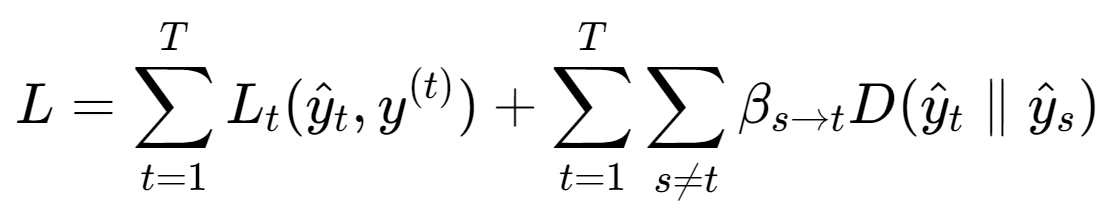
其中 D 是某种分布差异度量(例如 KL 散度或均方误差形式的对齐),β 控制蒸馏强度。这个公式并不要求所有任务输出同构,而强调“可比较的信号”可以通过中间表示、概率分布或某种映射后再对齐。实际设计时,最难的是找到合适的对齐空间与蒸馏方向,否则蒸馏可能把噪声与偏差也一起传递过去。
5.2 多模态架构:把“跨任务共享”扩展到“跨媒介共享”
当输入不仅仅来自单一模态(例如同时有图像与文本、结构化表格与时间序列、传感器与语言指令),多任务学习会自然升级为“多模态多任务”问题:不同模态之间存在互补信息,但对齐与融合并不容易。多模态架构的关键在于:共享表示不再是单一特征空间,而是需要在多模态编码器之间建立共享通道与对齐机制,典型做法包括层级注意力、联合注意力、共享记忆模块等。多模态 MTL 的理论难点是“共享什么”:共享底层编码器参数往往不合理,因为不同模态统计结构差异巨大;更常见的做法是在较高层引入共享记忆或共享语义空间,让不同模态先各自编码,再在共享空间里交互,最后由任务头读取融合后的表征。这样既保留了模态特性,又能让任务利用跨模态信息。
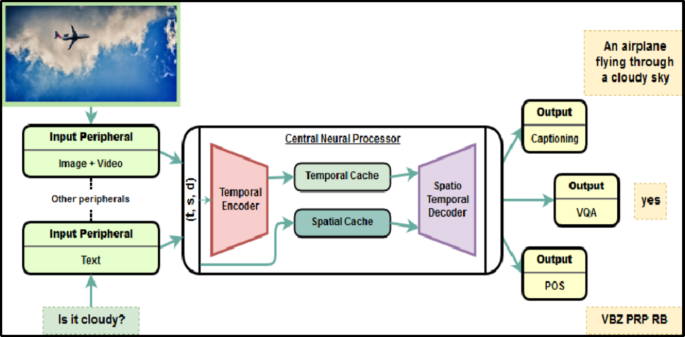
5.3 学习式架构:让“共享结构”也成为可学习对象
手工设计共享结构往往依赖经验:哪些层共享、哪些层分离、共享比例如何设定,都需要大量试验。当任务数量多、关系复杂、且任务间相关性并不均匀时,固定结构很难同时照顾所有任务,于是出现学习式架构(learned architectures):不仅学习权重参数,还学习网络结构本身或共享模式。一个直观的理解是:共享不是先验假设,而是需要从数据中学出来的隐变量;模型通过结构搜索、分支搜索、模块重组、细粒度掩码等方式,自动找到更适合当前任务集合的共享图。理论上,这类方法试图把“任务关系建模”与“结构设计”合二为一,让模型在训练中发现哪些任务应该共享哪些子网络,从而在提升正迁移的同时减少负迁移风险。
5.4 条件式架构:按输入与任务动态调整计算路径
条件式架构(conditional architectures)进一步把共享策略做成动态:网络会根据输入样本、任务类型或上下文,选择不同的计算路径或共享模块,从而提高计算效率与任务适配性。它的理论动机可以理解为“共享不应对所有样本一视同仁”:即便同一个任务内部,不同样本也可能需要不同特征;不同任务之间的共享也可能随输入而变化。条件式结构通常会引入门控、路由、任务路由(task routing)等机制,让网络在前向传播时就决定“用哪些共享模块、用多少共享模块”。这类方法的挑战在于训练稳定性:路由决策可能引入非平滑优化,且容易出现某些模块被过度使用、某些模块被闲置的现象,因此往往需要额外的均衡约束。
表2 深度多任务学习架构四类划分
| 架构类别 | 核心思想 | 共享方式的典型形态 | 适配的任务/数据特征 |
|---|---|---|---|
| 单域架构 | 在同一领域内设计共享与分支 | 共享主干、多头;跨层信息流;预测蒸馏 | 任务输入同构、特征可复用、任务间存在可表达互补 |
| 多模态架构 | 融合不同模态并跨任务共享 | 共享语义空间、共享记忆/注意力、跨模态对齐 | 多源输入、多模态互补,标注稀缺或任务组合复杂 |
| 学习式架构 | 结构与共享模式由训练学习 | 结构搜索、模块重组、细粒度掩码/剪枝 | 任务数量多、关系未知或非均匀,需要自动发现共享图 |
| 条件式架构 | 按输入/任务动态选择共享路径 | 动态路由、门控共享、任务路由 | 任务差异较大或样本异质性强,需要按需计算与共享 |
6 训练与优化:任务损失、权重学习与梯度冲突
多任务学习在训练层面的困难,常常比结构设计更“隐蔽”也更致命,因为很多失败案例表面看是“结构不行”,本质却是“优化谈判失败”。联合训练时,任务损失的数值尺度可能不同,梯度范数可能不同,数据量更可能极不平衡:某些任务每个 batch 都有标注,某些任务是稀疏标注或仅部分样本标注;某些任务容易收敛,某些任务收敛慢。这样一来,如果简单把所有任务损失直接相加,训练会自然偏向梯度更大或数据更多的任务,导致低资源任务长期学不到有效表征,进而形成“越学越偏”的马太效应。对这个问题的一个核心抽象是:权重 λt 不应仅仅是人为常数,而应该表达“任务在当前阶段对共享表示学习的贡献”与“任务当前的学习难度/不确定性”。因此,围绕权重学习的思路会出现很多变体,包括基于不确定性估计、基于梯度大小/收敛速度、基于元学习(metaweighting)等方向。
如果用一个更“训练动力学”的角度看问题,权重学习可以理解为给每个任务的梯度打折扣或放大。把各任务梯度记为 gt,则更新方向往往形如:
$$
g=\sum_{t=1}^{T}\lambda_t,g_t,\quad g_t=\nabla_W L_t(W)
$$
这里 W 可以是共享参数或全部参数。困难在于:当某些任务梯度方向冲突时,简单加权并不能消除冲突,甚至会让冲突在共享层累积成噪声,导致训练震荡、收敛变慢、或者出现某些任务性能持续退化。于是另一类优化思路是显式处理梯度冲突,例如通过梯度投影把更新方向限制在“不伤害其他任务”的可行域附近,或者通过任务分组把强冲突任务拆开共享,减少共享参数被拉扯的程度。理论上,这些方法都在试图让多目标优化更接近一个“帕累托意义上的合理折中”:不是让某一个任务独大,而是让更新方向尽量不让其他任务损失上升太多。
多任务训练还面临一个实践中非常常见却容易被忽视的问题:超参数敏感性。单任务模型往往只需要调学习率、权重衰减、batch size 等少量参数,而多任务系统除了这些,还要调任务权重、任务采样策略、共享层深度、分支位置、正则强度、甚至任务调度(先学什么、后学什么、每个任务更新频率多少)。当任务数量增长时,超参数空间呈指数式膨胀,导致“能跑起来不难、跑得好很难”。因此,深度多任务学习的工程化落地,往往不是靠更复杂的模型,而是靠更系统的训练策略与更稳健的默认设置,例如对权重引入自适应机制、对任务分组引入自动发现、对共享结构引入可学习门控,从而把调参负担从人为经验转移到模型学习过程本身。
表3 多任务训练常见困难与结构/优化层面的对应关系
| 困难类型 | 典型表现 | 更偏结构的处理思路 | 更偏优化的处理思路 |
|---|---|---|---|
| 负迁移/任务冲突 | 某些任务联合训练后反而变差 | 减少共享层(软共享/分支更早);引入门控/路由;学习式结构 | 梯度冲突处理;自适应权重;任务分组与调度 |
| 任务不平衡 | 数据多的任务主导训练,稀缺任务学不到 | 为稀缺任务保留更强的私有分支;多模态任务用共享空间对齐 | 权重学习(如元学习/自适应权重);重采样/调度 |
| 结构复杂度高 | 难以手工确定共享位置与共享比例 | 学习式架构搜索;细粒度掩码共享 | 以稳定性为目标的超参自动化与约束 |
| 超参数敏感 | 权重、学习率、采样频率难调 | 用结构把可调维度“固化”为可学习门控 | 用自适应策略替代固定常数,减少人工调参 |
7 多任务学习与迁移学习:范式差异与边界
多任务学习与迁移学习经常被放在一起讨论,因为两者都强调“利用共享知识提升学习效果”,但它们的核心范式差异非常明显:多任务学习是在同一训练过程中同时学习多个任务,知识在任务之间是双向流动的;迁移学习通常是先在源任务上训练,再把知识迁移到目标任务上,知识流动是从源到目标的单向过程。多任务学习要求训练时同时拥有多个任务的数据与监督信号,并且模型结构往往需要显式支持多输出;迁移学习则更强调预训练—微调或域适配,新增任务时可以在不完全重训的情况下适配目标任务。
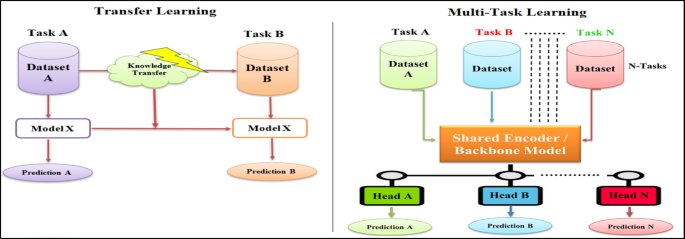
把差异总结成表格,会更利于在工程决策时快速判断该用哪种范式:当你手头只有目标任务少量数据、但有大规模相关预训练数据时,迁移学习往往更自然;当你需要同时优化多个相关指标,且希望通过共享表示降低整体系统成本时,多任务学习更合适。更微妙的是,两者并不冲突:多任务学习可以用预训练模型作为共享主干,也可以把迁移学习视为任务数为 2 且训练阶段分离的一种特殊情形;关键在于理解它们的训练模式与知识流方向,从而合理组合。
表4 迁移学习与多任务学习的关键结构差异(翻译整理)
| 维度 | 迁移学习(Transfer learning) | 多任务学习(Multi-Task learning) |
|---|---|---|
| 训练方式 | 顺序式:先源任务,再目标任务 | 同步式:多个任务同时训练 |
| 知识流向 | 仅从源到目标 | 任务之间双向流动 |
| 目标 | 用源知识提升目标任务 | 通过共享表示同时提升多个任务 |
| 模型结构 | 常复用/微调已有模型来适配新任务 | 共享主干 + 任务特定输出头/分支 |
| 典型使用场景 | 目标数据稀缺;域适配 | 任务相关、特征共享、多标签/多目标联合建模 |
8 跨领域应用的任务建模共性:从“任务设置”反推“共享结构”
跨领域应用并不是为了展示“MTL 能用在多少地方”,而是为了观察一个更本质的问题:不同领域的多任务设置,往往呈现出相似的结构模式。比如在医疗影像与计算机视觉中,常见的任务组合是“分割 + 分类 + 严重程度预测/回归”,因为它们共享同一套视觉表征但对输出粒度要求不同;在推荐与医疗 NLP 中,常见组合是“表示学习/图嵌入 + 预测/推荐”,因为共享图结构或文本编码能同时支撑多个下游目标;在能源与电力系统中,常见组合是“分类 + 回归 + 异常检测”,因为同一套传感器时间序列同时包含状态识别与数值预测信息;在教育与心理中,常见组合是“主任务预测 + 辅助任务刻画潜变量”,利用辅助任务逼迫模型学习更稳定的学生状态或心理状态表示。换句话说,跨领域的差异更多体现在数据形态与标签定义上,而多任务学习的共性体现在“共享一个中间表示去服务多个输出”的组织方式上。
为了便于直接复用,这里把跨领域的多任务应用按领域拆成多张表格(内容逐条翻译整理自对应汇总表),每行都保留了方法名、共享方式、结构要点、任务设置与主要局限。这样做的目的不是让你照着抄某个系统,而是让你在设计自己的多任务系统时,能快速对照“我现在的任务组合更像哪一类”“我该优先考虑硬共享还是软共享”“我的风险点更可能在结构还是在优化”。
8.1 文本与自然语言处理相关多任务设置
表5 文本/NLP 领域多任务应用汇总
| 引用 | 年份 | 领域 | 方法/思路 | 参数共享 | 架构要点 | 任务设置 | 主要局限 |
|---|---|---|---|---|---|---|---|
| [84] | 2025 | NLP | 面向方言的仇恨言论多任务学习 | 硬✓ 软– | Transformer 共享编码器 + 方言/任务特定输出头(如方言分类器或二分类仇恨检测头) | 仇恨言论检测(按方言分任务) | 方言数据不平衡与词表外(OOV)问题 |
| [88] | 2024 | NLP | 基于 LLM 的自动权重学习多任务框架 | 硬– 软✓ | 基于 LLM 的多任务学习,构造辅助任务并进行权重学习 | 隐式情感分析 | 数据层不确定性来自 LLM 幻觉;任务层不确定性来自不同模型容量;性能依赖权重估计准确性 |
| [34] | 2021 | NLP | 以情感分析辅助仇恨言论检测的多任务方法 | 硬✓ 软– | Transformer 结构 | 仇恨言论检测;情感分析 | 对隐式仇恨敏感;对细微极性/情绪线索把握困难;训练数据误标影响学习;未在西班牙语以外数据验证 |
| [34] | 2021 | NLP | 基于 BETO 的多任务学习 | 硬✓ 软✓ | 基于 Transformer 的 BETO | 仇恨言论检测;极性分类;情绪分类 | 非仇恨类样本略有性能下降;辅助任务误差传播;数据集标签噪声 |
| [35] | 2023 | NLP | 深度多任务学习(Bi-LSTM + 感知机头) | 硬✓ 软– | Bi-LSTM + 任务特定感知机 | 情感分析;讽刺检测 | 中性类易误判;对讽刺上下文敏感;对数据与预处理依赖较强 |
| [36] | 2022 | NLP/文本分类 | 子词-短语抽取辅助的多任务学习 | 硬✓ 软– | 预训练 NLM + 任务特定全连接层 | 文本分类;子词-短语识别 | 依赖无监督子词/短语抽取质量;未实现任务加权方案 |
| [42] | 2020 | NLP/多语机器翻译 | 任务与数据调度的多任务学习 | 硬✓ 软– | Transformer 多语 NMT | 翻译(双语 bitext);MLM;DAE | 需要谨慎调度;语言间数据不平衡;高资源语言可能性能下降 |
| [26] | 2019 | 生物医学 NLP/化学 | 多任务学习(NER + 释义生成) | 硬– 软✓ | 共享 Bi-LSTM + ANMT | 命名实体识别(NER);释义生成 | 依赖释义质量;局限于化学领域;需要大量释义数据 |
8.2 计算机视觉、医疗影像与智能驾驶相关多任务设置
表6 视觉/影像/驾驶领域多任务应用汇总
| 引用 | 年份 | 领域 | 方法/思路 | 参数共享 | 架构要点 | 任务设置 | 主要局限 |
|---|---|---|---|---|---|---|---|
| [89] | 2022 | 计算机视觉/安全 | 恶意软件图像分类的深度多任务学习 | 硬✓ 软– | 11 层 CNN,PReLU 激活 | PE、APK、ELF、Mach-O 等多格式恶意软件图像分类 | 仅使用图像特征;尚未融合代码/API 等语义特征 |
| [90] | 2024 | 计算机视觉/皮肤影像 | 注意力引导的多任务学习(含不确定性) | 硬✓ 软✓ | CNN + 多任务 + 注意力 + 不确定性模块 | 皮肤病灶分割;皮肤病灶分类 | 对其他数据集泛化有限;缺少域适配;任务扩展仍需工作 |
| [23] | 2023 | 医疗影像 | 跨任务注意力网络(CTAN) | 硬– 软✓ | 注意力型多任务框架 | 分割;诊断;严重程度预测;剂量规划(跨 Prostate、OpenKBP、HAM10000、STOIC 等 4 个数据集) | 分割任务提升有限;复杂任务(如 COVID 严重程度分类)可能出现性能下降 |
| [43] | 2021 | 医疗影像/MRI 分割 | 加权损失的深度多任务学习 | 硬✓ 软✓ | 改造 V-Net:双解码器 + 多深度融合模块 | 肿瘤掩码分割;距离变换估计 | 权重系数经验设定;未必最优;融合模块适用性未与其他注意力形式充分对比 |
| [37] | 2014 | 计算机视觉 | 面部关键点的任务约束学习(TCDCN) | 硬✓ 软– | 任务约束深度 CNN | 主任务:关键点检测;辅任务:头姿、面部属性、表情、性别、年龄估计 | 各任务收敛速度不同;跨任务平衡学习较难 |
| [38] | 2024 | 智能驾驶/视觉 | YOLOPv3 多任务视觉感知 | 硬✓ 软✓ | 基于 YOLOv7 的 YOLOPv3,encoder–decoder + 任务头 | 目标检测;可行驶区域分割;车道线检测 | 高分辨率特征与上下文依赖利用不足;实时约束;缺少实例分割与边缘压缩 |
| [39] | 2023 | 计算机视觉 | 结合知识蒸馏的多任务学习 | 硬✓ 软✓ | 共享编码器 + 任务头 | 目标检测;语义分割 | 受限于部分标注;若无蒸馏难以同时优化两任务 |
| [62] | 2023 | 自动驾驶 | 决策与优化(MDO)驱动的多任务学习 | 硬✓ 软✓ | 共享骨干 + 任务子网(UNet、FPN、Transformer) | 目标检测;车道线检测;可行驶区域分割;深度估计 | 深度估计任务与其他任务相关性低,影响联合性能;配置优化复杂 |
8.3 医疗健康、推荐、生物信息与化学相关多任务设置
表7 医疗/生物信息/化学领域多任务应用汇总
| 引用 | 年份 | 领域 | 方法/思路 | 参数共享 | 架构要点 | 任务设置 | 主要局限 |
|---|---|---|---|---|---|---|---|
| [28] | 2024 | 医疗健康 | M3H:多模态多任务学习 | 硬✓ 软✓ | 注意力模型 | 40 种诊断;3 类手术预测;1 个表型刻画(含分类/回归/聚类) | 任务/模式覆盖有限(例如缺少图像分割等);对扰动鲁棒性;缺少组学/可穿戴融合;任务集设计受维度灾难影响;数值不稳定 |
| [91] | 2023 | 医疗健康 | GenHPF:多任务多源学习 | 硬– 软✓ | 分层文本编码 | 12 个临床预测任务,跨 3 个 EHR 数据集 | 限于表格/同语言 EHR;部分事件类型因内存限制被排除 |
| [24] | 2018 | 医学/健康(EHR) | 表型刻画的多任务神经网络 + 辅助任务 | 硬– 软✓ | 多任务神经网络 + 辅助任务 | 表型刻画(phenotyping)及辅助任务 | 随机选择辅助任务未必最优;规则式真值可能引入伪影;特征表示缺少时间建模;表型范围有限 |
| [25] | 2022 | 医疗(NLP/推荐) | MedRec 药物推荐系统 | 硬– 软✓ | GCN + 注意力 + 属性融合 | 图嵌入;药物推荐 | 依赖图质量;缺少时间建模;外部验证有限 |
| [30] | 2023 | 生物信息 | UnitedNet:可解释多任务深度网络 | 硬– 软✓ | 编码器–解码器–判别器联合 | 联合分组识别;跨模态预测 | 需要细致调参/结构;训练随机性;更多任务可扩展性仍在探索 |
| [93] | 2024 | 生物信息/生物医药 | HBNMM:异构生物网络多任务模型 | 硬– 软✓ | 图注意力 + MTL | ncRNA-疾病;ncRNA-药物;药物-疾病关联预测 | 关联稀疏;药物-疾病链接不平衡;标注有限 |
| [71] | 2022 | 生物信息/药物发现 | 多任务 + 自监督预训练(蛋白+药物)与双适配 | 硬✓ 软✓ | 蛋白编码器(Transformer);药物编码器(GCN);DTA 预测器;双适配机制 | DTA(药物-靶标亲和力)预测;蛋白/药物预训练 | 小标注数据易过拟合;替换预训练模型收益有限 |
| [41] | 2022 | 药物发现/生化 | SGNN-EBM:结构 GNN + 能量模型 | 硬– 软✓ | 结构化 GNN 与 EBM 的软共享 | 分子性质预测(382 个任务) | 计算复杂;对 NCE 训练噪声分布敏感 |
| [73] | 2023 | 医疗/推荐 | 贝叶斯多任务学习 + LASSO(序数回归) | 硬✓ 软✓ | 多元贝叶斯模型(共享先验);Gibbs 采样;潜变量序数 probit | 多维满意度评分预测;药物推荐 | 缺少总体评分监督;缺少个性化效用建模;患者信息有限;偏临床使用 |
| [27] | 2021 | 化学 | 可燃性性质预测的多任务深度网络(MDNN) | 硬– 软✓ | Tree-LSTM 编码器 + 多个 FNN 解码器 | LFL、UFL、闪点、AIT 预测 | 需要大规模高质量数据;对简单小分子可能欠佳;可解释性有限 |
8.4 能源电力、金融、教育、机器人与科学计算相关多任务设置
表8 工程/社会/科学计算领域多任务应用汇总
| 引用 | 年份 | 领域 | 方法/思路 | 参数共享 | 架构要点 | 任务设置 | 主要局限 |
|---|---|---|---|---|---|---|---|
| [94] | 2025 | 电力系统 | 基于 SRIN 的多任务学习(时空循环插补网络) | 硬– 软✓ | SRIN(RNN) | 缺失数据插补;电压稳定性评估 | 需要在更复杂/更多电网测试;依赖 RNN 可解释性 |
| [31] | 2024 | 电网/智能电网 | CNN 共享编码器、多头多任务 | 硬✓ 软– | Conv1D+BN+tanh 的 CNN blocks;共享编码器;两头:softmax(分类)与线性(回归) | 故障类型分类(多类);故障定位(回归) | 作为电网故障方向较早的多任务尝试;对噪声鲁棒到 40dB;推理快且参数更少(该行更多是现象描述与优点) |
| [32] | 2024 | 智能建筑/能源 | Mixture-of-Experts + 稀疏 Transformer + 多门融合 | 硬✓ 软✓ | 多门专家混合(MoE)+ 稀疏约束 Transformer;任务头分离;注意力融合;任务间加权策略 | 负荷预测;室温预测;能耗异常检测;能耗异常预测 | 训练难度与资源消耗随任务变化;模型越大准确率越高;Transformer 模型内存约为 CNN 的 5 倍 |
| [63] | 2022 | 金融 | CWGAN-GP + 多任务学习 | 硬✓ 软– | CWGAN-GP 生成器 + 共享 MLP 层的 MTL | 处理不平衡信用评分;合成数据生成 | 计算成本高、训练调参耗时;合成样本过大可能过拟合;生成数据质量与多样性仍需提升 |
| [64] | 2021 | 气候科学 | 多任务学习 + 二维 RNN | 硬✓ 软– | CNN 特征抽取 + 2D-RNN 时间建模 | 温度预测;湿度估计;能见度估计;风速估计 | 可解释性有限;无注意力机制;需要识别空间关键区域;时间建模带来计算复杂度 |
| [65] | 2019 | 教育数据挖掘 | 多层 LSTM + 注意力的多任务学习 | 硬– 软✓ | 共享参数多层 LSTM + 注意力 | 学生表现预测(主);知识点掌握预测(辅) | 只关注作业相关特征;未考虑内容理解与外部因素;任务扩展会增加复杂度 |
| [67] | 2020 | 教育数据挖掘 | 多任务 MIML(MIML-Circle) | 硬✓ 软✓ | 多实例多标签学习(MIML)+ 迭代式软特征融合 | 课程表现预测;学业预警 | 忽略心理/家庭因素;假设先修课程足够;数据集有限;跨机构泛化未验证 |
| [66] | 2022 | 机器人/操作 | 多任务 Transformer(PERACT) | 硬✓ 软✓ | Perceiver Transformer | 6-DoF 多任务操控;语言条件行为克隆(多任务/多数据集) | 限于离散动作;依赖采样式运动规划;难泛化到更精细的连续控制 |
| [40] | 2023 | 交通预测/物理 | 用多任务优化训练 PINNs | 硬✓ 软✓ | 多个 PINN 共享结构 + 自适应参数迁移 | 交通密度预测(主);交通速度预测(辅) | 损失分量平衡复杂;向更多任务扩展的可伸缩性问题 |
| [70] | 2024 | 物理 | 多任务 PINNs 求解多孔介质流固耦合 | 硬– 软✓ | 软共享 MTL-PINN | 流场与结构场耦合预测 | 场景聚焦于恒压生产设定(适用范围有限) |
| [33] | 2024 | 心理健康 | 可穿戴相关心理状态多任务预测 | 硬– 软✓ | 共享编码器 + 任务头 | 抑郁、焦虑、压力预测 | 仅穿戴特征贡献有限;是否能泛化到非大学生群体未探索 |
8.5 农业与时空数据相关多任务设置
表9 农业领域多任务应用汇总
| 引用 | 年份 | 领域 | 方法/思路 | 参数共享 | 架构要点 | 任务设置 | 主要局限 |
|---|---|---|---|---|---|---|---|
| [29] | 2024 | 农业 | 混合深度学习多任务模型 | 硬– 软✓ | MKCNN + Bi-LSTM(共享层) | 产量回归;高/低产量分类 | 数据可用性有限;依赖特征工程;对时间动态的深层建模不足 |
| [72] | 2023 | 智慧农业 | 张量多任务学习 | 硬– 软✓ | 时空张量 + CP 分解 | 跨农场与月份预测施肥量与施肥时间 | 数据采集困难;时空建模假设复杂 |
9 优势、局限与评估要点:把理论落到可验证的结论
多任务学习常被概括为“能提升泛化、能节省数据、能省训练时间”,这些结论并不是口号,而是可以被结构与优化机制解释清楚的。共享表示带来的正则化效应使模型更不容易记住单任务噪声,从而在测试分布上更稳;多个任务共同训练相当于让共享层在更多监督信号下更新,尤其在某些任务标注稀缺时,其他任务提供的梯度能起到数据增强式的补充;把多个任务合并到一个模型,往往能减少重复训练与重复部署成本,并且在某些情况下比训练多个独立模型更快更省资源。更关键的是,当任务之间存在可迁移结构时,多任务学习能实现正向知识迁移,使某些难任务从易任务中获得“学习支架”。
但多任务学习的局限同样具有结构根源与优化根源。负迁移是最核心的风险:任务差异过大或目标冲突时,共享层被迫折中,导致某些任务性能下降;任务不平衡会让数据多、梯度强或目标更容易的任务主导训练,使弱任务学不到;结构复杂度高导致很难设计一个兼顾共享与私有的网络,尤其当任务跨模态、跨尺度、跨结构时;超参数敏感性使得多任务系统调参成本显著上升,任务权重、学习率、优化策略都需要更精细的协调;任务选择与分组也非常关键,把不该放在一起的任务硬凑在一起,收益会被抵消甚至变成伤害;最后,当任务数量增加到几十甚至上百时,训练的计算与内存需求会快速上升,更新调度与稳定性都会变得困难。
因此,一个更“工程可验证”的评估要点是:不要只看平均指标提升,而要看任务间的收益分布与稳定性,特别要检查是否出现了某些任务明显下降;不要只看最终指标,还要看训练过程是否稳定、是否对权重与调度高度敏感;不要只看模型结构的复杂度,还要评估它在不同任务组合、不同数据噪声与不同标注缺失模式下的鲁棒性。多任务学习的目标不是“让所有任务都小幅提升”,而是在可接受的训练成本与复杂度下,让共享带来的正则化收益真正落到核心任务上,同时把负迁移风险控制在可解释、可调节的范围内。
表10 多任务学习的优势与局限:机制化解释
| 方面 | 更偏“机制”的解释 |
|---|---|
| 泛化更好 | 共享参数形成结构化归纳偏置,起到正则化效应,降低过拟合风险 |
| 数据更省 | 多任务共享表示相当于提高共享层的有效样本量,弱监督任务可借助强监督任务梯度 |
| 训练更高效 | 一次训练服务多个目标,减少重复 backbone 的训练与部署 |
| 可能负迁移 | 任务冲突导致共享层梯度拉扯,折中更新损害部分任务 |
| 容易失衡 | 数据量/梯度范数/目标难度差异导致某些任务主导训练 |
| 调参更难 | 任务权重、共享深度、调度策略等超参维度显著增加 |
| 可扩展性挑战 | 任务数增加导致计算与内存开销上升,训练调度与稳定性变难 |
10 结语
深度多任务学习的核心并不是“把多个头接在一个网络上”,而是围绕共享表示建立一套可控的结构与优化机制:当任务相关性足够强时,硬共享用最小成本带来最强的正则化收益;当任务相关性部分成立或存在冲突时,软共享、门控共享、跨层信息流与预测蒸馏把共享变成连续可调的变量;当任务数量增长、关系复杂时,学习式与条件式架构尝试让共享模式由数据与训练过程自己决定;而在训练层面,多目标优化的权重、调度与梯度冲突处理决定了“共享到底是在帮助模型学通用表示,还是在让共享层被冲突信号撕裂”。如果你把 MTL 当成一套“结构—优化—数据”的联合设计问题,而不是一个固定模板,很多看似玄学的效果差异就会变得可解释,也更容易找到正确的调试方向。
参考文献
[1] Caruana, R.: Multitask learning. Machine Learning 28, 41–75 (1997).
[2] Sener, O., Koltun, V.: Multi-task learning as multi-objective optimization. NeurIPS (2018).
[3] Misra, I., Shrivastava, A., Gupta, A., Hebert, M.: Cross-stitch networks for multi-task learning. CVPR (2016).
[4] Xu, D., Ouyang, W., Wang, X., Sebe, N.: PAD-Net: multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. arXiv:1805.04409 (2018).
[5] Subhojeet, P., Priyanka, A., Aman, H.: OmniNet: A unified architecture for multi-modal multi-task learning. arXiv:1907.07804 (2019).
[6] Crawshaw, M.: Multi-task learning with deep neural networks: a survey. arXiv:2009.09796 (2020).
[7] Chen, S., Zhang, Y., Yang, Q.: Multi-task learning in natural language processing: an overview. arXiv:2109.09138 (2021).
[8] Fifty, C., Amid, E., Zhao, Z., Yu, T., Anil, R., Finn, C.: Efficiently identifying task groupings for multi-task learning. arXiv:2109.04617 (2021).
[9] Mao, Y., Wang, Z., Liu, W., Lin, X., Xie, P.: Metaweighting: learning to weight tasks in multi-task learning. Findings of ACL (2022).
[10] Xin, D., Ghorbani, B., Garg, A., Firat, O., Gilmer, J.: Do current multi-task optimization methods in deep learning even help? arXiv:2209.11379 (2022).
[11] Lindsey, J.W., Lippl, S.: Implicit regularization of multi-task learning and finetuning in overparameterized neural networks. arXiv:2310.02396 (2023).
[12] Sherif, A., Abid, A., Elattar, M., ElHelw, M.: STG-MTL: scalable task grouping for multi-task learning using data maps. Machine Learning: Science and Technology 5(2) (2024).
[13] Bohn, C., Freeman, I., Tercan, H., Meisen, T.: Task weighting through gradient projection for multitask learning. arXiv:2409.01793 (2024).
[14] Lai, W., Xie, H., Xu, G., Li, Q.: Multi-task learning with LLMs for implicit sentiment analysis: data-level and task-level automatic weight learning. arXiv:2412.09046 (2024).
[15] Roy, A., Koutlis, C., Papadopoulos, S., Ntoutsi, E.: FairBranch: mitigating bias transfer in fair multi-task learning. IJCNN (2024).
[16] Abdelsamie, M.M., Azab, S.S., Hefny, H.A.: The dialects gap: a multi-task learning approach for enhancing hate speech detection in Arabic dialects. Expert Systems with Applications (2025).


















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











