





目录
2 音乐生成任务的表示与问题设定:谱面世界与声学世界如何握手
4 从“生成音频”到“生成可压缩 token”:神经音频编解码器与离散化
表5 可控性“接口化”的常见手段:你能控制什么,取决于你把什么变成条件
7 评测基准与评估体系:为什么“听起来不错”无法成为科学指标
8 数据集与训练数据:从“公开基准”到“版权与溯源”成为第一等约束
9 统一化趋势:从单任务模型到“音频基础模型”与多模态创作链
10 结语:未来几年真正决定路线胜负的,可能是评测与合规而非模型规模
1 引言
“让机器写音乐”这件事,过去很长时间都像是在两种世界之间搭桥:一边是乐理、谱面、结构、动机与发展这些高度抽象的符号体系;另一边是声学、音色、混音、空间感与“像真的一样”的听感。直到近几年,随着神经音频编解码器(neural audio codec)、大规模自监督表示学习、扩散模型与大语言模型式的离散序列建模在音频领域逐渐打通,音乐生成开始出现一种新的统一视角:无论是“谱”还是“声”,都可以被编码成可学习、可生成、可对齐文本语义的表示,然后用规模化模型去做条件生成与编辑。以 Google 的 MusicLM 为代表的一条路线把音乐生成写成层级式序列到序列问题,并公开了 MusicCaps 数据集以推动后续研究 (arXiv);Meta 的 MusicGen 则强调单阶段的离散 token 语言模型,结合 EnCodec 等音频离散化技术,以更直接的生成链路换取效率与可控性 (arXiv);Stability AI 的 Stable Audio Open 则把文本到音频的大模型推进到“开放权重 + 可追溯 Creative Commons 训练数据”的叙事中,试图在可用性、可研究性与版权合规之间找到一个工程可落地的中点 (arXiv)。
但当模型走出论文、进入真实创作与商业分发语境,“评测”与“评估体系”就不再只是学术比赛的计分规则:它会直接影响产品体验、版权争议的可辩护性、平台治理与行业合作方式。2024 年起,围绕训练数据是否构成“合理使用”、输出是否“可替代”原创作品的法律争议被迅速推到台前:美国唱片业相关诉讼把 Suno、Udio 等生成式音乐平台推到聚光灯下,RIAA 与多家唱片公司提交的起诉文件与媒体报道不断更新细节 (Reuters);而 2025 年又出现了更“产业化”的信号:部分版权方与平台达成和解与合作框架,试图转向“授权模型”的路线 (Reuters)。在这种背景下,音乐生成模型的综述如果只停留在“模型结构像什么”就会失焦:我们必须把表示方式、训练数据、对齐方法、评测指标、人类听感实验、可控编辑能力、部署效率与合规治理放到同一个评估框架里谈,才能理解为什么某些路线能产品化、某些路线更适合学术开放、某些路线在法律与伦理压力下不得不改变技术选型。
本文尝试做一篇“超长但不清单化”的整合综述:用较长段落解释关键技术脉络,再用表格把横向对比压缩成可检索的结构化信息,并在必要处引入公开论文与官方资料中可核查的事实。由于音乐生成跨越符号域、音频域、多模态对齐与人类主观评测,本文也会把“评测基准”当作核心主线:什么才算“更好”的音乐?我们又如何在可重复的实验条件下衡量它?
2 音乐生成任务的表示与问题设定:谱面世界与声学世界如何握手
音乐生成的难点,从来不只是“生成一段听起来不难听的音频”。音乐同时存在于三层结构里:最底层是波形与频谱决定的“物理可听性”;中间层是音色、和声、节奏、律动、混音空间构成的“风格与制作”;最高层则是主题动机、段落结构、张力推进、复现与变化这些“时间尺度很长的叙事”。如果直接在波形上建模,序列长度巨大、采样率高、长程依赖极难;如果只在符号上建模,虽然长程结构容易一些,却很难自然地呈现真实音色与演唱质感。于是研究路线不断在“更抽象”与“更具体”之间摆动:符号作曲模型把 MIDI/音符事件当语言;音频域模型把压缩后的离散码当语言;扩散模型则在连续潜空间里逐步采样,把生成过程变成“逐渐去噪”的物理过程类比。
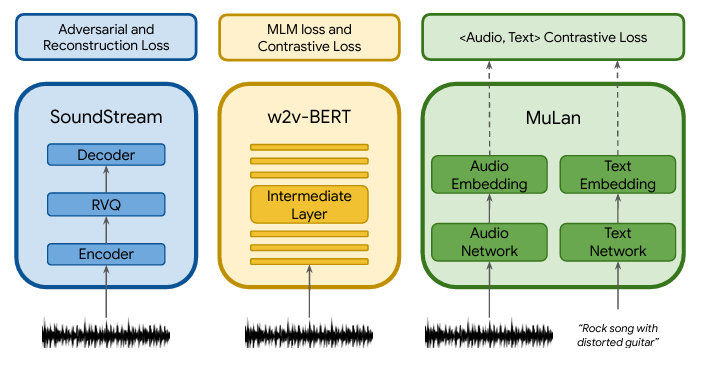
一个关键的“握手”技术,是神经音频编解码器:SoundStream 这样的工作证明了用残差向量量化(RVQ)等方法,可以把音频压缩成离散 token,在较低码率下仍保持主观质量,从而让“像语言一样的序列建模”在音频上成为可能 (arXiv)。AudioLM 进一步提出混合 token 化思路:用自监督音频表征捕捉长程一致性,用神经编解码 token 捕捉高保真细节,从而兼顾“结构”和“听感” (arXiv)。MusicLM 把这类框架扩展到文本条件音乐生成,并强调分钟级一致性与对文本的遵循度 (arXiv)。另一方面,Meta 的 MusicGen 则选择“更简单的链路”:直接在多个离散码流上训练单阶段 Transformer 语言模型,用高效 interleaving 模式生成多码本 token,减少级联模型的复杂性,换取推理更直接的工程优势 (arXiv)。
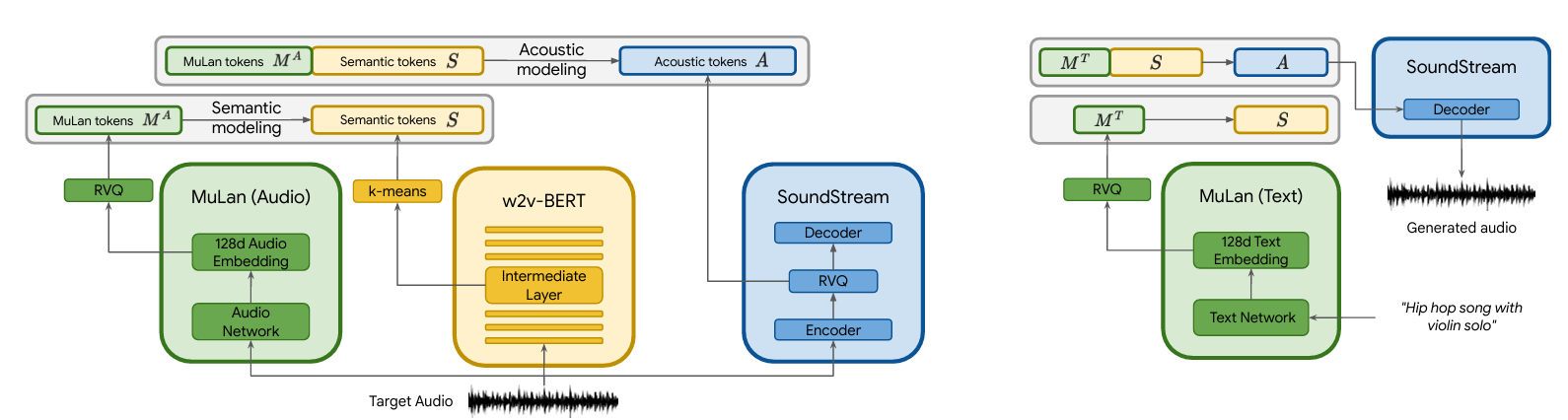
表1 生成任务的主流表征与适用场景
| 表征层级 | 典型形式 | 优势 | 典型短板 | 更适合的任务 |
|---|---|---|---|---|
| 符号域(Symbolic) | MIDI、piano-roll、事件序列(bar/beat/pitch/duration 等) | 结构可控、可插入乐理先验、长程依赖更“短” | 音色/演唱/混音缺失,落地到音频需再合成 | 作曲草稿、配器草案、和声/旋律续写、风格迁移(符号级) |
| 音频域(Waveform) | 原始波形 | 直接输出可听音乐,覆盖音色与制作 | 序列极长、训练与推理成本高、长程结构困难 | 高保真生成(但成本高)、端到端带人声生成(早期) |
| 离散音频 token | neural codec 的多码本 token(如 RVQ) | 可用“语言模型式”方法,质量与效率折中 | 仍需解决长程结构与语义对齐 | 文本到音乐/音效、音乐续写、条件编辑 |
| 连续潜空间(扩散) | VAE/autoencoder latent + diffusion/flow | 稳定训练、可做强条件控制与编辑 | 采样步数影响速度;长程结构仍是难点 | 文本到音频、风格/音色编辑、音频到音频变换 |
(本表概括了以 SoundStream、AudioLM、MusicLM、MusicGen、Stable Audio Open 等工作所体现的表征取舍与代价结构。 (arXiv))
3 符号音乐生成:把“乐谱当语言”的漫长道路
符号音乐生成是深度学习音乐生成最早成熟的一支,因为它天然把音乐变成离散序列:音符事件像 token,拍号小节像分隔符,和弦与调式像高层语义标签。问题在于,“把 MIDI 当文本”并不等同于“音乐像语言”。音乐的并行结构(和弦纵向堆叠)与层级结构(小节—乐句—段落)更强,节奏栅格与速度变化也比自然语言更具刚性约束。于是,研究者不断发明更贴近音乐结构的表示与训练策略:Pop Music Transformer 提出的 REMI(Revamped MIDI)以“bar/position”显式标注节拍推进,并把 tempo、chord 等控制事件纳入序列,使模型更容易学到节奏与和声的可控结构 (arXiv)。MusicBERT 则把“理解音乐”的预训练引入符号域,强调 bar-level masking 等策略以减少信息泄漏,说明音乐 token 的相关性结构与文本不同,照搬 NLP 的 mask 方式会损害学习效果 (arXiv)。
符号生成在今天仍然重要,原因并不只是“学术传统”。恰恰相反,当音频域模型越来越能“一键生成听起来像歌的作品”,符号域反而在更专业的工作流里凸显价值:它适合做结构草图、旋律动机、和弦走向、段落安排,适合与 DAW/MIDI 工具链协作,也更容易做“可解释、可编辑、可版权溯源”的控制(至少在乐谱层面)。从产业角度看,很多“可控性需求”最终会回到符号层:用户想要的是“把副歌升高一个全音、保持节奏与配器不变”,而不是“再随机采样一次”。
表2 符号域代表性工作与关键思想
| 工作 | 年份 | 关键创新点 | 与评测/可控性相关的启示 |
|---|---|---|---|
| Pop Music Transformer / REMI | 2020 | 以 bar/position/tempo/chord 等事件构造更适配 Transformer 的音乐序列表示 | 可控 token 的设计本身就是“评测维度”:没有可控接口就难以评“可控性” (arXiv) |
| MusicBERT | 2021 | 符号音乐的大规模预训练;针对音乐结构设计 masking 策略 | 预训练让下游任务与生成可共享表征,但也要求更严格的数据与任务划分 (arXiv) |
| Theme Transformer(主题条件) | 2022/2023 | 更显式的主题/动机条件化训练(示例) | 把“动机复现/发展”变成可评测的条件任务,有助于客观指标设计 (ACM Digital Library) |
4 从“生成音频”到“生成可压缩 token”:神经音频编解码器与离散化
如果说符号域把音乐生成简化为“像写字一样写谱”,那么音频域要解决的第一性问题是:如何把 44.1kHz 或 48kHz 的高采样率信号变成模型可处理的序列长度?早期像 OpenAI Jukebox 这样的大规模系统使用多尺度 VQ-VAE 把音频压缩成离散 code,再用自回归 Transformer 在 code 序列上建模,展示了分钟级连贯与带人声生成的可能性,但代价是推理极慢,工程门槛极高 (arXiv)。之后,SoundStream 等神经编解码器路线把“高保真压缩”推进到可实时或接近实时的方向:用 RVQ 与端到端训练在较低码率下取得可观主观质量,且能覆盖语音与音乐等多类音频 (arXiv)。在这一基础上,AudioLM 的“语义 token + 声学 token”混合方案把长期结构与细节质量分担给不同 token 空间,使“既像真的、又有结构”的生成更可行 (arXiv)。
这段演进的意义在于:音乐生成开始拥有类似 NLP 的“token 工程学”。一旦音频被稳定离散化,很多在语言模型里成熟的训练技巧(条件建模、引导、对齐、偏好优化、并行解码)就能迁移;同时,评测也开始能借用“embedding 分布距离”这类更可重复的指标(例如 FAD),因为我们终于可以用统一的表征空间去比较生成音频与真实音频在统计意义上的距离 (Google Research)。
表3 音频离散化/表示学习的关键支撑工作
| 工作 | 核心贡献 | 为什么对音乐生成重要 |
|---|---|---|
| SoundStream | 端到端神经音频编解码器,RVQ,多码率 | 把“音频→token→语言模型”的路线变得可规模化 (arXiv) |
| AudioLM | 混合语义/声学 token 的层级生成框架 | 解释了“结构一致性”和“高保真”可以由不同 token 子空间协同实现 (arXiv) |
| MuLan | 音乐音频与自然语言的联合嵌入 | 为文本条件音乐生成提供语义对齐支点,也反过来用于评测(相似度分数) (arXiv) |
5 音频域大模型:自回归、掩码并行、扩散/流匹配三大范式
当我们能把音乐压缩为 token 或潜变量后,生成模型大致分成三类范式,它们的分歧本质上是:你愿意用多少推理时间换取多强的条件一致性与音质,以及你把“结构”交给模型还是交给后处理与工作流。
自回归(AR)范式把生成当作逐 token 预测:优点是训练目标简单、可自然地做长上下文续写与条件插入;缺点是推理速度常常被序列长度锁死。MusicGen 是这一范式在音乐生成上的代表:它用单阶段 Transformer 直接生成多码本 token,强调无需多级级联模型即可得到高质量样本,并支持文本与旋律特征条件 (arXiv)。AudioGen 则把相似框架用于更广义的文本到音频(含环境声、音效等),并使用数据混合增强与 classifier-free guidance 等技术提升文本遵循与多源分离能力 (arXiv)。从评测角度看,AR 模型往往在“可续写性、可条件插入性”上更自然:你可以给一个短前缀让它续写,也可以在 token 层做受控采样;但当用户想要“快速出多个候选、反复迭代”,AR 的延迟会成为体验瓶颈。
掩码并行(masked / non-AR)范式试图用并行解码加速生成:MAGNeT(Masked Audio Generation using a Single Non-Autoregressive Transformer)通过预测被遮蔽的 token span 并迭代填充,强调在保持质量竞争力的同时大幅加速推理,并讨论了与 AR、扩散之间的速度—质量折中 (arXiv)。这种路线对“产品化”尤其诱人:音乐生成产品最怕用户等待,等待会让“创作流”断裂;但如果并行解码导致结构一致性或细节质量下降,又会放大用户对“塑料感”“拼贴感”的厌恶。
扩散(diffusion)及其变体把生成当作逐步去噪:在音频领域,常见做法是在 autoencoder latent 空间做扩散,既降低维度,又保留可编辑性。AudioLDM 把 CLAP 等语言-音频对比表征作为条件,构建 latent diffusion 的文本到音频系统 (arXiv);Stable Audio Open 则采用 autoencoder + T5 文本嵌入 + latent-space DiT 扩散结构,公开权重并强调训练数据基于 Creative Commons,使研究者能在可复现实验与合规叙事中继续迭代 (arXiv)。扩散模型往往在“音色质感、局部细节、编辑能力”上表现突出,但推理速度与采样步数绑定,必须靠蒸馏、流匹配、少步采样或更强硬件来解决延迟问题。近期也出现用偏好优化、DPO 类方法对齐扩散音频生成的工作(例如 Tango 2 讨论通过偏好数据提升概念覆盖与顺序一致性),反映出“扩散也需要对齐”正在成为共识 (arXiv)。
表4 音频域生成范式对比:速度、质量、可控性的代价结构
| 范式 | 代表工作 | 典型优势 | 典型挑战 | 评测侧重点更敏感于… |
|---|---|---|---|---|
| 自回归(AR)token LM | MusicGen、AudioGen、AudioLM、MusicLM | 训练直接、可续写、条件插入自然 | 推理慢、长音频成本高 | 长程一致性、条件遵循度、续写连贯 (arXiv) |
| 掩码并行/非自回归 | MAGNeT | 推理更快、适合多候选探索 | 迭代策略复杂、质量/结构折中 | 速度—质量曲线、结构稳定性 (arXiv) |
| 扩散/流匹配(latent) | AudioLDM、Stable Audio Open | 细节质感强、编辑友好、训练稳定 | 采样慢、长程结构仍难 | 真实感(embedding 距离)、人类偏好、编辑一致性 (arXiv) |
6 可控生成与对齐:从“能生成”到“能听懂你的话”
音乐生成的“可控性”比文生文更难,因为用户需求往往同时作用于多个时间尺度:你既想要整体风格(“90 年代英伦摇滚质感”),又想要和声走向(“副歌转到大调并抬高张力”),还想要制作细节(“鼓要干一点、混响短一点”),甚至想要具体结构(“前奏 8 小节—主歌—副歌—间奏—再副歌”)。在学术论文中,可控性常被简化为“文本遵循度”,或额外加入“旋律条件”“和弦条件”“节奏模板条件”。MusicLM 展示了文本与旋律双条件的风格化转换能力,强调在分钟级生成中保持一致性 (arXiv);MusicGen 也支持以旋律特征进行条件控制,试图把“哼唱/哨音 → 风格化成某种编曲”做成标准接口 (arXiv);符号域里,REMI 的 chord/tempo 事件就是把控制显式编码进序列,使控制成为“语言的一部分” (arXiv)。
对齐(alignment)则更像是“把模型从统计拟合推到用户意图”。在文本领域,这对应 RLHF 或偏好优化;在音频领域,偏好数据更贵、更难标注,也更难获得“客观正确答案”。因此,一条常见路径是用预训练的跨模态相似度模型做代理:例如 CLAP 作为语言-音频对齐表征,经常被用作条件编码或排序信号 (arXiv);MuLan 相似度也在 MusicLM 相关工作里被用作评测与对齐参考 (arXiv)。另一条路径是直接构造偏好数据:Tango 2 通过合成偏好对来优化扩散模型的概念覆盖与顺序一致性,体现了“音频对齐也在向 DPO 化”发展 (arXiv)。
当我们把“可控性”视为评测维度,就会发现:评测体系需要同时覆盖“语义正确”“结构正确”“音质正确”“制作正确”。这也是为什么工业界产品更新时常常强调“结构更好、key 控制、stem 下载、音频到音频 remix”等功能点——因为这些点本质上是在补齐“可控性维度”的用户可感知接口。Udio 的官方更新中就明确提到 v1.5 带来 key control 等能力 (Udio);Suno 的模型时间线说明了不同版本在生成时长与结构质量上的迭代方向 (Suno帮助中心)。
表5 可控性“接口化”的常见手段:你能控制什么,取决于你把什么变成条件
| 控制目标 | 常见实现方式 | 适用域 | 难点 |
|---|---|---|---|
| 风格/情绪/流派 | 文本条件 + 引导(CFG/偏好排序);或跨模态嵌入条件(CLAP/MuLan) | 音频域为主 | 文本词汇与音乐风格映射含糊;主观差异大 (arXiv) |
| 旋律约束(哼唱/旋律引导) | 旋律特征条件(pitch contour/embedding);或提供短音频 prompt 做续写 | 音频域/符号域 | “保形”与“变风格”矛盾:既要像原旋律,又要像目标风格 (arXiv) |
| 和弦/调式/速度 | 在符号表示中显式加入 chord/tempo token(REMI);或在音频域用结构条件 | 符号域更直接 | 音频域的和声可解释性弱;需要可靠的自动标注或条件提取 (arXiv) |
| 结构(段落/时长) | 分段生成 + 级联/编辑;或模型支持 variable length | 音频域 | 长程一致性、段落边界过渡、主题复现难 (arXiv) |
7 评测基准与评估体系:为什么“听起来不错”无法成为科学指标
音乐生成评测的核心矛盾是:我们想要可重复、可量化、可对比的指标,但音乐好坏高度主观且依赖文化语境。于是评测体系几乎必然是“自动指标 + 人类主观实验 + 任务化可控评测”的混合体。自动指标方面,文本到音频/音乐生成常用 embedding 距离或相似度:FAD(Fréchet Audio Distance)用音频编码器嵌入分布之间的 Fréchet 距离衡量生成音频与真实音频的统计差异,是被频繁引用的“音质/真实感”代理指标之一 (arXiv);而文本遵循度常用 CLAPScore 或 MuLan 相似度一类跨模态相似度作为代理,尽管这类指标会被“投机取巧”的模型优化而失真,因此更适合作为开发过程中的诊断工具,而非唯一排名依据 (arXiv)。
人类主观评测方面,音乐生成常借用音频领域传统的 MOS、MUSHRA 或成对偏好测试:让听众在同一任务条件下比较多个样本,评“更像音乐”“更符合提示词”“更少伪影”“更有结构”。这里的挑战不仅是成本,更是实验设计:听众是否专业、播放设备是否一致、样本时长是否公平、提示词是否覆盖多风格、是否存在“新奇偏置”(第一次听 AI 觉得惊艳,听多了觉得空洞)都会影响结果。因而,一个严肃的评测体系往往要同时报告:自动指标、主观偏好、以及一组可复现的任务化设置(例如固定提示词集、固定时长、固定采样策略、固定后处理)。
特别值得强调的是,MusicLM 在发布同时公开 MusicCaps 数据集,本质上是把评测基准“数据化”:用 5.5k 高质量音乐-文本对为“文本到音乐”提供标准测试床,从而让不同模型能在相近条件下对比文本遵循与音质 (arXiv)。而 Stable Audio Open 强调训练数据的许可来源,也是在评测体系里引入一个新的维度:不仅要评生成质量,还要评“可公开、可复现、可合法使用的训练数据”是否会显著限制上限,以及在这种限制下如何设计更公平的对比 (arXiv)。
表6 常见评测指标/方法与它们的“盲点”
| 评测手段 | 典型代表 | 能回答的问题 | 常见盲点 |
|---|---|---|---|
| 真实感/分布距离(embedding-based) | FAD | 生成音频整体上有多“像真实数据分布” | 可能忽略音乐结构;对编码器选择敏感 (arXiv) |
| 文本-音频对齐分数 | CLAPScore、MuLan 相似度 | 模型是否“听懂提示词” | 易被对齐模型偏置影响;可能奖励“标签化音效”而非音乐性 (arXiv) |
| 人类偏好(成对比较/打分) | A/B preference、MOS、MUSHRA(常见范式) | 综合质量、音乐性、可用性 | 成本高、可重复性差;实验设计细节决定可信度(播放设备/受试者/样本长度) |
| 任务化可控评测 | 固定提示词集、固定结构控制任务 | 可控接口是否真的可控 | 任务设计困难;容易“教模型做题”而非泛化能力 |
8 数据集与训练数据:从“公开基准”到“版权与溯源”成为第一等约束
音乐生成模型的训练数据,一直处于“需求巨大—可公开数据有限—版权风险极高”的张力中。学术界可公开的音乐数据往往规模有限或许可复杂:MusicCaps 作为 MusicLM 工作中公开的数据集,规模约 5.5k,对研究推动很大,但对训练一个“商业级全风格”音乐模型显然远远不够 (arXiv)。更大规模的音频事件数据集如 AudioSet 与衍生的 AudioCaps 提供了丰富的音频-标签/字幕资源,为“文本到音频”与音频理解提供基础,但其“音乐性”与“完整歌曲结构”并非设计重点 (Google Research)。在符号域,Lakh MIDI Dataset 之类的大规模 MIDI 资源为结构学习提供沃土,但 MIDI 来自网络抓取与社区制作,质量与版权状态更复杂,研究中常以清洗子集或衍生数据形式使用(这也意味着评测与复现必须谨慎对齐数据版本) (kaggle.com)。
这也是为什么 Stable Audio Open 选择强调“Creative Commons 数据训练并公开权重”——它把“数据许可”作为研究叙事的一部分,使后续工作能在更低法律风险下复现实验与做二次开发 (arXiv)。与之并行的是产业界的另一条路:不回避版权库,而是通过授权与合作把数据合法化。2024 年唱片业对 Suno、Udio 的诉讼文件与新闻报道,清晰展示了版权方对“未经许可训练”的强硬态度 (Reuters);而 2025 年出现的和解/合作报道则表明行业可能在向“授权 AI 模型”过渡,只是代价是更强的平台限制、下载限制与更复杂的商业条款 (Reuters)。这会反过来影响评测体系:未来的“最好模型”可能不是纯技术意义上的最好,而是在“质量—成本—延迟—合规—可分发”多目标下的最优折中。
9 统一化趋势:从单任务模型到“音频基础模型”与多模态创作链
近两年一个明显趋势,是把音乐生成纳入“更广义的音频生成/编辑”框架:同一个模型既做文本到音效,也做文本到音乐,甚至做歌声、配音、音频修复与编辑。UniAudio 把多类音频生成任务统一为 token 序列建模,并用多尺度 Transformer 处理过长序列,强调“音频基础模型”的潜力 (arXiv)。Google DeepMind 的 Lyria 与相关工具(Music AI Sandbox、MusicFX 等)则体现了另一种统一:把音乐生成当作创作工具链的一环,与实时交互、DJ 混合、短视频创作场景结合,并在官方信息中明确这些工具由 Lyria/Lyria RealTime 驱动 (Google DeepMind)。当生成不再只是“一次性采样”,而是“可交互、可编辑、可实时 jam”,评测体系也必然要扩展:延迟、交互稳定性、可撤销编辑、一致性保持、局部替换不破坏全局结构等,都将变成新的可量化指标。
与此同时,模型的“部署形态”正在分叉:一端是开放权重、研究可复现(如 Stable Audio Open);另一端是封闭 API、产品化与版权合作(如部分商业平台),还有一端是“实验性实时 API”与创作工具(如 Lyria RealTime 的实验接口叙事)。不同形态会塑造不同的评估习惯:开放权重社区更偏好可复现基准与公开数据;商业平台更在意用户留存、创作效率与版权风险;实时交互则要求以系统工程指标(延迟、抖动、稳定性)重塑“好模型”的定义。
10 结语:未来几年真正决定路线胜负的,可能是评测与合规而非模型规模
回看音乐生成的技术史,会发现每一次“质变”几乎都来自表征与评测的共同演进:有了更合适的表示(REMI、neural codec token、latent diffusion),模型才学得动;有了更可复现的基准(MusicCaps)与更工程化的指标(FAD、对齐分数、人类偏好实验范式),社区才知道该往哪儿优化 (arXiv)。而当音乐生成走向产业化,训练数据许可、版权合作与平台限制会把评测体系从“学术比较”推向“治理工具”:你不仅要证明模型更好听,还要证明它更可控、更可解释、更可追溯、更合规、更可部署。2024—2025 年围绕 Suno、Udio 的诉讼与和解新闻已经把这种趋势写在明面上:行业在探索一条既能用 AI 扩大创作可能、又能让权利人参与分配的路径 (Reuters)。
因此,未来“最强的音乐生成模型”很可能不是单纯参数最大、数据最多的模型,而是在可控接口、对齐策略、评测体系与合规框架上最成熟的系统。技术路线会继续百花齐放:AR、并行掩码、扩散/流匹配、符号—音频混合、以及统一音频基础模型都会并行存在;真正的分水岭会出现在“谁能把评估变成可产品化的工程闭环,谁能把合规变成可扩展的数据策略”。
参考文献与资料(精选)
-
Dhariwal, P. et al. Jukebox: A Generative Model for Music. arXiv:2005.00341 (arXiv)
-
Zeghidour, N. et al. SoundStream: An End-to-End Neural Audio Codec. arXiv:2107.03312 (arXiv)
-
Borsos, Z. et al. AudioLM: a Language Modeling Approach to Audio Generation. arXiv:2209.03143 (arXiv)
-
Agostinelli, A. et al. MusicLM: Generating Music From Text. arXiv:2301.11325(并发布 MusicCaps) (arXiv)
-
Copet, J. et al. Simple and Controllable Music Generation(MusicGen) arXiv:2306.05284 (arXiv)
-
Kreuk, F. et al. AudioGen: Textually Guided Audio Generation. arXiv:2209.15352 (arXiv)
-
Evans, Z. et al. Stable Audio Open. arXiv:2407.14358 (arXiv)
-
Liu, H. et al. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. arXiv:2301.12503 (arXiv)
-
Huang, Y.-S., Yang, Y.-H. Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions(含 REMI) arXiv:2002.00212 (arXiv)
-
Zeng, M. et al. MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training. Findings of ACL 2021 (ACL Anthology)
-
Kilgour, K. et al. Fréchet Audio Distance(FAD)相关引用信息(在后续工作中广泛使用) (arXiv)
-
Wu, Y. et al. Contrastive Language-Audio Pretraining (CLAP). arXiv:2206.04769 (arXiv)
-
Yang, D. et al. UniAudio: An Audio Foundation Model Toward Universal Audio Generation. arXiv:2310.00704 (arXiv)
-
Google DeepMind:音乐生成工具与 Lyria/Lyria RealTime 相关官方页面与公告 (Google DeepMind)
-
Udio 官方:v1.5 更新说明(含 key control 等) (Udio)
-
Suno 官方:模型时间线与版本信息 (Suno帮助中心)
-
RIAA/唱片公司诉讼文件(Suno、Udio 起诉状 PDF) (RIAA)
-
Reuters / AP:关于 AI 音乐平台诉讼与和解合作的新闻报道 (Reuters)


















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











