





目录
5.1 平台与技术栈选型:云边协同、MLOps 与 AIOps
1 引言:智能制造与AI落地的窗口期
在经历了十多年“工业4.0”与“智能制造”的概念喧嚣之后,制造企业正在进入一个更务实的阶段:不再追逐炫目的样板工厂展示,而是开始追问“哪些AI项目真正带来了可量化的OEE提升、停机时间下降和库存周转改善”。从2024–2025年的多项研究和调研数据来看,人工智能在制造业的应用正在从局部试点走向系统化部署,但成熟度高度不均衡,预测维护和智能调度则是最先跑通业务闭环的两个典型场景。
Deloitte 在 2025 年发布的《Smart Manufacturing Survey》中指出,约 29% 的受访企业已经在工厂或网络层面部署了 AI/ML,24% 在同一尺度上部署了生成式 AI,同时还有 23% 和 38% 的企业正处于 AI/ML 与生成式 AI 的试点阶段,这意味着超过一半的制造企业已经在用或正试图用 AI 改造关键运营流程。(Deloitte)Auburn 大学 ICAMS 2024 年的智能制造采纳研究则进一步强调,企业对 AI 的兴趣迅速升温,但受限于业务案例不足和技能短缺,真正跑通生产场景的项目仍然是少数。(奥本大学工程学院)
在众多应用场景中,预测维护是最容易量化价值、也最适合从“点状试点”走向“面上复制”的入口。IoT Analytics 的预测维护市场报告显示,全球预测维护市场在 2022 年已达到约 55 亿美元,相比 2021 年增长 11%,并预计到 2028 年仍将保持约 17% 的复合年增长率;对于大型资产而言,典型的非计划停机成本中位数已经超过每小时 10 万美元。(IoT Analytics)在这样的经济驱动力下,围绕设备状态监测、故障预测和剩余寿命估计(RUL)的 AI 技术不断演进,从传统的统计方法和浅层机器学习,演进到融合深度学习、图模型与自监督学习的复杂技术栈。(MDPI)
另一方面,随着离散制造和流程工业对柔性、定制化和交付弹性的要求不断提高,静态的生产计划和“日计划+临时插单+人工调度”的模式越来越难以应对现实复杂性。近年来,基于深度强化学习、多智能体系统以及数字孪生的自适应生产调度研究迅速升温,从典型的 Job Shop / Flow Shop 调度问题,走向考虑机器故障、能耗、碳排、物料运输和在制品缓冲等约束的真实车间场景。(Taylor & Francis Online)
更重要的是,最新文献中已经出现“预测维护+自适应调度”一体化建模的趋势:通过将设备健康预测结果直接嵌入调度决策,使生产计划能够提前规避高风险设备、动态调整工序路由,从而在保障交期的同时降低故障停机的概率。(SpringerLink)这意味着,预测维护不再只是“维护部门的数据项目”,而是有机会成为生产系统自优化的一部分。
在这样的背景下,本文聚焦“AI在智能制造中的落地”,以“预测维护”和“自适应生产调度”两个场景为主线,从技术体系、开源生态、架构设计与工程落地四个维度展开分析,并尽可能引用 2022–2025 年的最新公开文献和开源实践,为希望在工厂中落地 AI 的工程师和技术管理者提供一套可参考的路线图。
表1 概览:AI 与预测维护在制造业中的市场与采纳情况
| 指标 | 年份 | 数值/描述 | 说明 | 数据来源 |
|---|---|---|---|---|
| 全球预测维护市场规模 | 2022 | 约 55 亿美元 | 相比 2021 年增长约 11% | IoT Analytics 预测维护市场报告(IoT Analytics) |
| 预测维护市场预期 CAGR | 2023–2028 | 约 17% | 预测维护将保持快速增长 | IoT Analytics(IoT Analytics) |
| 非计划停机成本中位数 | 近期 | 超过 10 万美元/小时 | 大型资产停机损失的典型量级 | IoT Analytics(IoT Analytics) |
| 在工厂/网络层面使用 AI/ML 的企业比例 | 2025 | 29% | 已在规模化使用传统 AI/ML 模型 | Deloitte 2025 调研(Deloitte) |
| 在工厂/网络层面使用生成式 AI 的企业比例 | 2025 | 24% | 已在规模化部署生成式 AI | Deloitte 2025 调研(Deloitte) |
| 正在试点 AI/ML 的企业比例 | 2025 | 23% | 尚处于 PoC/试点阶段 | Deloitte 2025 调研(Deloitte) |
| 正在试点生成式 AI 的企业比例 | 2025 | 38% | 探索文本/代码/知识类场景 | Deloitte 2025 调研(Deloitte) |
| 调研样本规模(制造企业) | 2023 | 350 家 | 来自北美和欧洲的中大型制造企业样本 | Rootstock AI in Manufacturing Survey(Rootstock Software) |
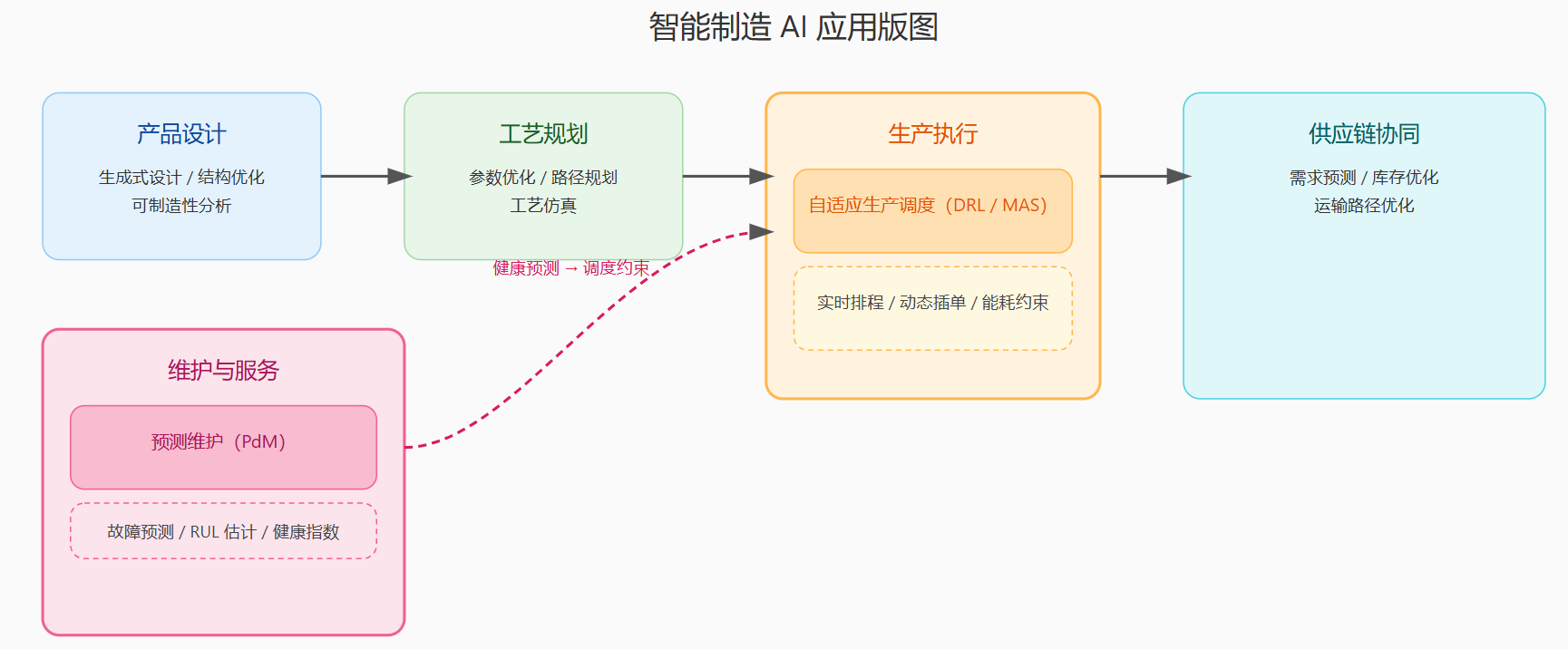
图1 :智能制造中 AI 应用版图与落地图谱示意图
2 预测维护:从概念到端到端落地
2.1 预测维护在智能制造中的价值与痛点
预测维护(Predictive Maintenance, PdM)本质上是一种利用传感器数据和数据分析技术,对设备未来状态进行预判,从而在故障发生之前安排维护活动的策略。与传统的“事后维修”(Run-to-Failure)和“预防性维护”(基于时间或使用次数的周期保养)相比,预测维护使维护计划从“基于经验”转向“基于数据和模型”。系统性综述表明,机器学习和深度学习方法在预测维护中已经被广泛用于自动故障检测、故障诊断以及剩余寿命预测,目标都是在降低非计划停机的前提下减少过度维护。(纯粹)
近年来的多篇综述工作显示,工业 4.0 语境下的预测维护普遍采用物联网(IoT)感知层 + 边缘/云计算 + AI/ML 模型 + 运维决策引擎的层级架构,逐渐从以人工经验为主导的模型向以数据驱动为核心的“智能维护系统”演化。(PMC)在传感器类型方面,振动、温度、电流、电压、声学信号、油液分析和工艺参数是应用最广泛的几类数据源;在建模目标方面,则主要包括故障二分类、多类故障识别、RUL 连续回归以及健康指数构建等。(MDPI)
然而,大量实践也表明,预测维护项目要真正落地到工厂一线并非易事。近年的系统综述总结了数十个工业用例中的共通挑战,包括数据质量差(缺失、噪声、标签稀缺)、场景高度不平衡(真实故障样本极少)、模型泛化能力不足(跨设备、跨工况迁移困难)、与现有 CMMS / ERP / MES 系统集成复杂等问题。(科学直接)
值得注意的是,中小制造企业(SMEs)在预测维护上的需求尤为迫切:设备老旧、停机成本高,却又难以承担昂贵的商业软件和大型数据团队成本。针对这一痛点,Pejić Bach 等在 2023 年构建了一个完全基于开源 R 生态的预测维护决策支持系统(DSS),通过物联网采集工业冷却系统数据,利用多个 R 包设计并验证了预测模型和维护策略,证明中小企业可以基于开源技术构建可用的预测维护系统。(MDPI)
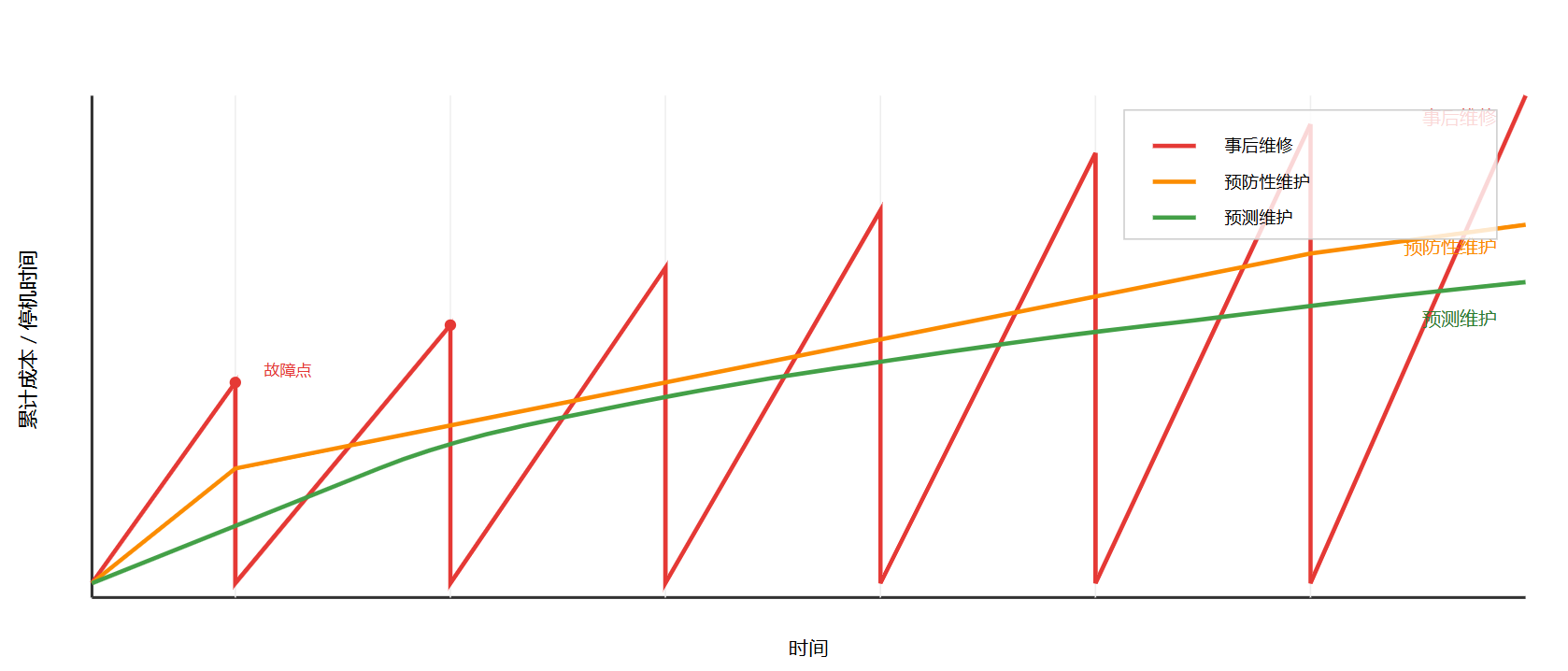
图2 :不同维护策略(事后维修、预防性维护、预测维护)在成本和停机时间上的对比曲线
2.2 数据驱动的预测维护技术体系:从特征工程到深度学习
从技术视角看,现代预测维护体系大致可以分为数据采集与集成、数据理解与特征工程、建模与训练、推理与决策以及闭环优化五个阶段。近年来的系统综述对这些阶段进行了系统梳理,并将预测维护模型划分为基于规则/阈值、传统机器学习和深度学习三大类。(MDPI)
在机器学习层面,常见的模型包括逻辑回归、随机森林、梯度提升树、支持向量机以及各种集成学习方法。它们在特征维度有限、样本量中等的场景下依然具有良好的基准性能,特别适合早期试点阶段或对可解释性要求较高的中小项目。(纯粹)与此同时,深度学习方法在处理高维时序数据和多模态数据(如振动 + 图像 + 工艺参数)方面展现了明显优势,典型模型包括一维卷积神经网络(1D-CNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)以及 CNN-LSTM 等混合结构。(MDPI)
Li 等在 2025 年发表在 Scientific Reports 的研究中,系统比较了多种深度学习架构在预测制造系统设备故障与 RUL 上的表现,提出了从数据采集、预处理到模型构建的完整框架,并表明在多组工业数据集上,深度学习模型整体上优于传统机器学习基线。(Nature)Mateus 等在 2025 年的工作则进一步通过混合 LSTM–CNN 结构,提高了对复杂工业时序数据的预测能力,强调了结合卷积(局部模式捕捉)与循环网络(长序列依赖建模)的优势。(MDPI)
在这一技术体系中,特征工程与数据预处理仍然是决定项目成败的关键环节。对原始传感器数据进行插值、滤波、去噪、归一化,以及构造时域、频域和时频域特征(如 RMS、峰值因子、谱能量、小波系数等),能够显著提升模型的可学习性和鲁棒性。(MDPI)同时,针对极度不平衡的故障数据,研究者提出了多种策略,包括代价敏感学习、异常检测方法、自监督预训练和数据增强技术,以缓解正负样本不平衡带来的影响。(PMC)
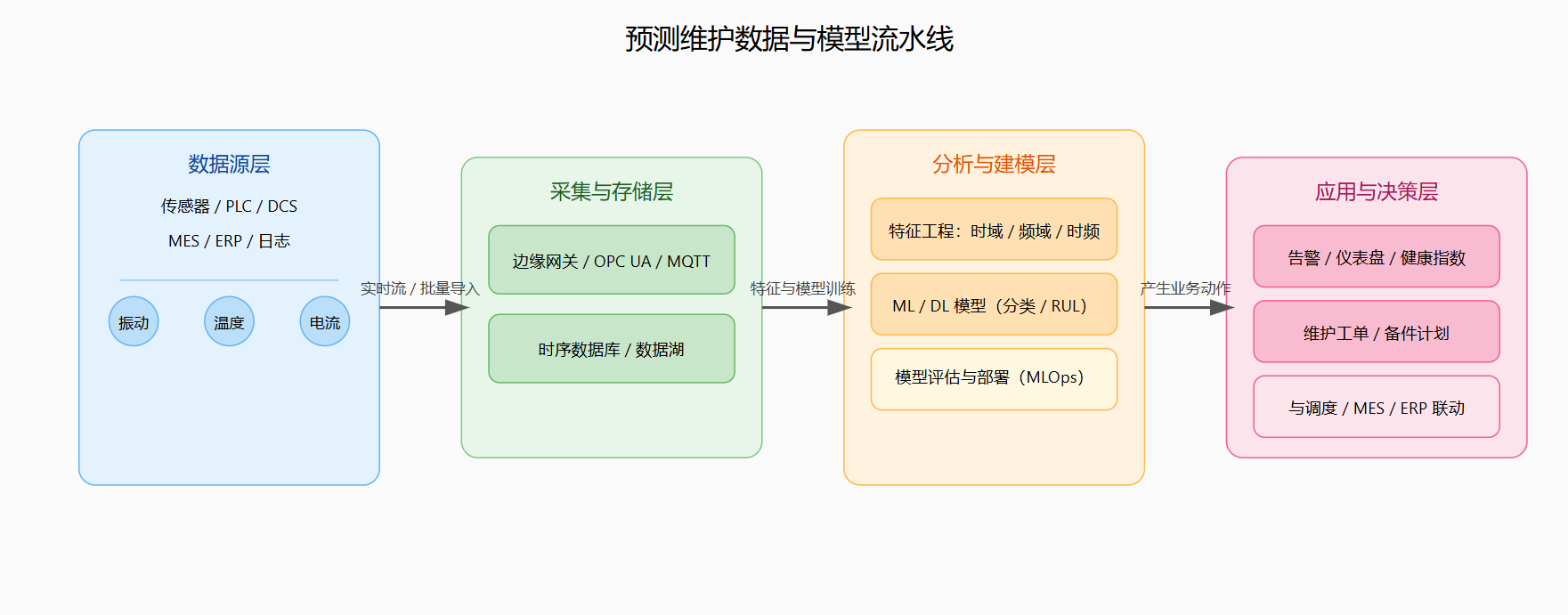
图3 :典型预测维护数据与模型流水线架构图
2.3 开源预测维护实践:架构、工具与案例
近年来,围绕预测维护的开源生态逐渐成熟,既包括通用机器学习和时序建模框架,也包括专门面向工业预测维护的数据集、参考架构和可直接部署的示例项目。
在学术领域,Pejić Bach 等基于 R 语言构建的预测维护 DSS 为中小企业提供了一套完全依赖开源软件的解决方案,涵盖数据采集、模型训练和维护策略推荐。(MDPI)Su 等在 2024 年提出的统一预测维护平台则进一步将数据仓库能力与 Apache Spark 的分布式计算能力结合,通过端到端平台支持大规模工业预测维护部署。(PMC)在 GitHub 上,面向预测维护的数据集与代码示例也不断涌现,例如针对涡轮风扇发动机、工业电机等设备的故障预测项目,以及聚合多种公开预测维护数据集并提供快速上手脚本的 pmx_data 元数据仓库。(GitHub)
表2 代表性开源预测维护方案与资源对比
| 名称/工作 | 技术栈与框架 | 主要对象/场景 | 特点与启示 | 参考来源 |
|---|---|---|---|---|
| Predictive Maintenance DSS for SMEs | R 语言,多个开源 R 包(机器学习、可视化等) | 中小型制造企业的工业冷却系统 | 完全基于开源构建 DSS,强调低成本与可定制性 | Pejić Bach 等(MDPI) |
| 统一预测维护平台(Unified PdM Platform) | 数据仓库 + Apache Spark + 分布式 ML 框架 | 多行业设备资产管理与预测维护 | 提供端到端平台,从数据汇聚到模型部署一体化 | Su 等(PMC) |
| pmx_data 元数据仓库 | Python,提供数据下载脚本与数据说明 | 多行业预测维护公开数据集 | 汇总多种 PdM 数据集,简化数据准备步骤 | Autonlab pmx_data(GitHub) |
| kokikwbt/predictive-maintenance | GitHub 仓库,聚合多种 PdM 数据集 | 航空、工业设备等多种场景 | 通过统一索引快速定位合适数据集 | GitHub 仓库与评述(GitHub) |
| real-time PdM showcase | Python + 深度学习自编码器 + Kafka/Streams + Grafana | 实时异常检测与维护告警 | 提供从流数据到可视化的完整实时 PdM 样例 | GitHub showcase(GitHub) |
| IoT-based PdM 仿真项目 | 边缘设备 + 传感器仿真 + ML 模型 | IoT 场景下的设备在线监测与故障预测 | 模拟真实 IoT 流水线,适合作为教学与快速 PoC | IoT PdM 仓库(GitHub) |
这些开源项目为工业工程师提供了非常实用的参考:一方面,可以直接复用其中的模型结构、数据处理脚本和可视化仪表盘,加速 PoC 阶段的验证;另一方面,它们也展示了在真实工业场景中如何用容器化、流式处理框架和可观测性工具将预测维护模型“产品化”。
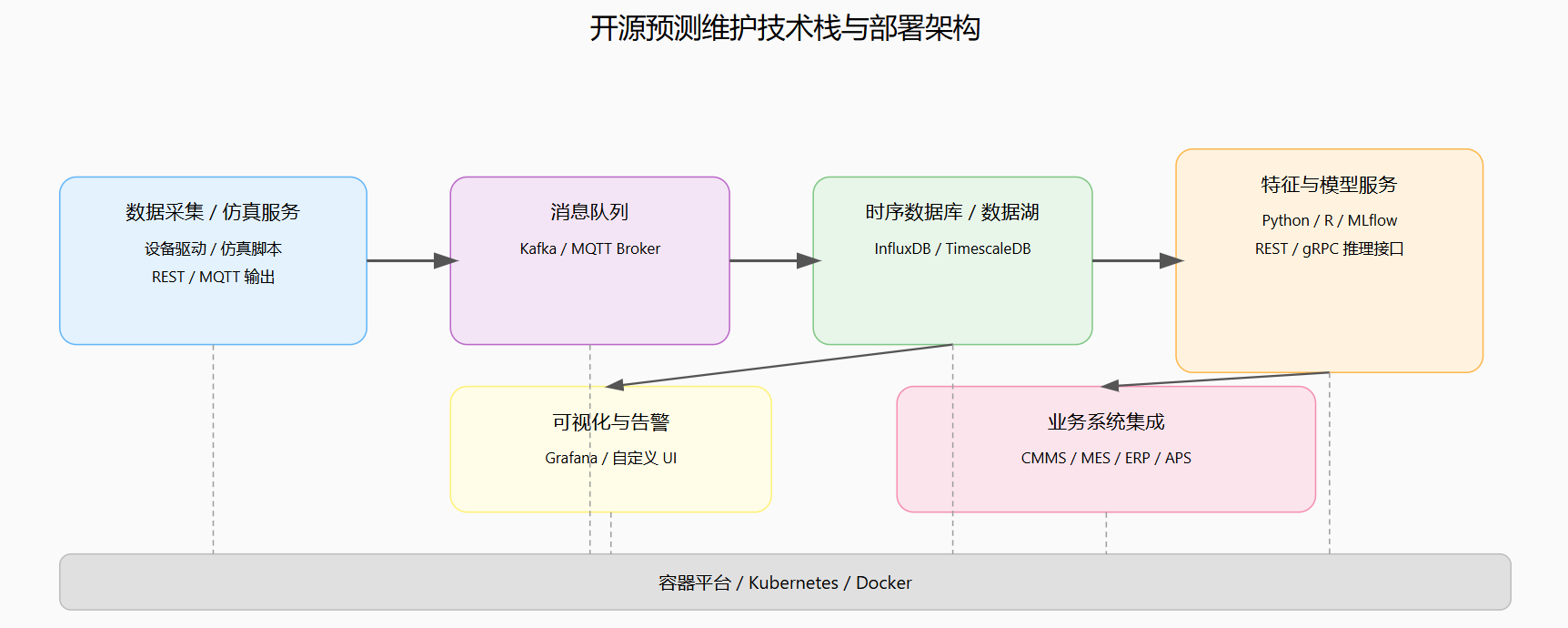
图4:典型开源预测维护技术栈与部署架构图
2.4 预测维护落地实施路径:从试点到规模化
从大量实践和文献案例来看,预测维护项目往往经历从“单机 PoC”到“生产线/车间级推广”,再到“多工厂协同”的演进路径。2024 年发布的一系列综述工作强调,成功的预测维护部署通常具备三大特征:以业务价值驱动(从高停机成本的关键资产切入)、以平台化架构支撑(数据与模型能力复用)、以组织能力建设为保障(维护与 IT/数据团队协同)。(科学直接)
在 PoC 阶段,企业通常选择一台或少量关键设备(如瓶颈机床、压缩机、炉窑、关键传输设备),收集一定周期的高频传感器数据与维护历史,通过开源数据集和模型作为对照,快速构建基线模型并验证预测能力。在这个阶段,模型的精度固然重要,但更关键的是证明“可以基于实时数据合理预测故障或健康趋势”,并为后续流程再造提供依据。(MDCplus)
当进入车间级推广时,挑战会迅速从“模型性能”转向“系统工程”:如何与现有的 CMMS、MES 和 ERP 系统打通,实现从“预测”到“工单”和“排程”的闭环;如何保证模型在不同设备、不同工况和不同工厂之间的迁移能力;如何管理模型版本与数据漂移。而统一预测维护平台、MLOps/AIOps 实践和数据仓库 + 流式处理架构,正是为这些问题提供基础的技术答案。(PMC)
在更成熟的阶段,预测维护还会与生产调度、质量管理和供应链协同进一步融合。例如,将 RUL 预测结果作为调度模型的输入特征,由调度算法主动避开“高风险设备”;或者将预测到的停机窗口与备件供应、人员排班、订单交付窗口进行共同优化,从而真正实现跨职能的决策协同。近期有研究工作提出了“在调度模型中嵌入设备健康预测”的联合优化框架,展示了预测维护与调度联动能够在保障交期的同时显著降低停机风险。(SpringerLink)
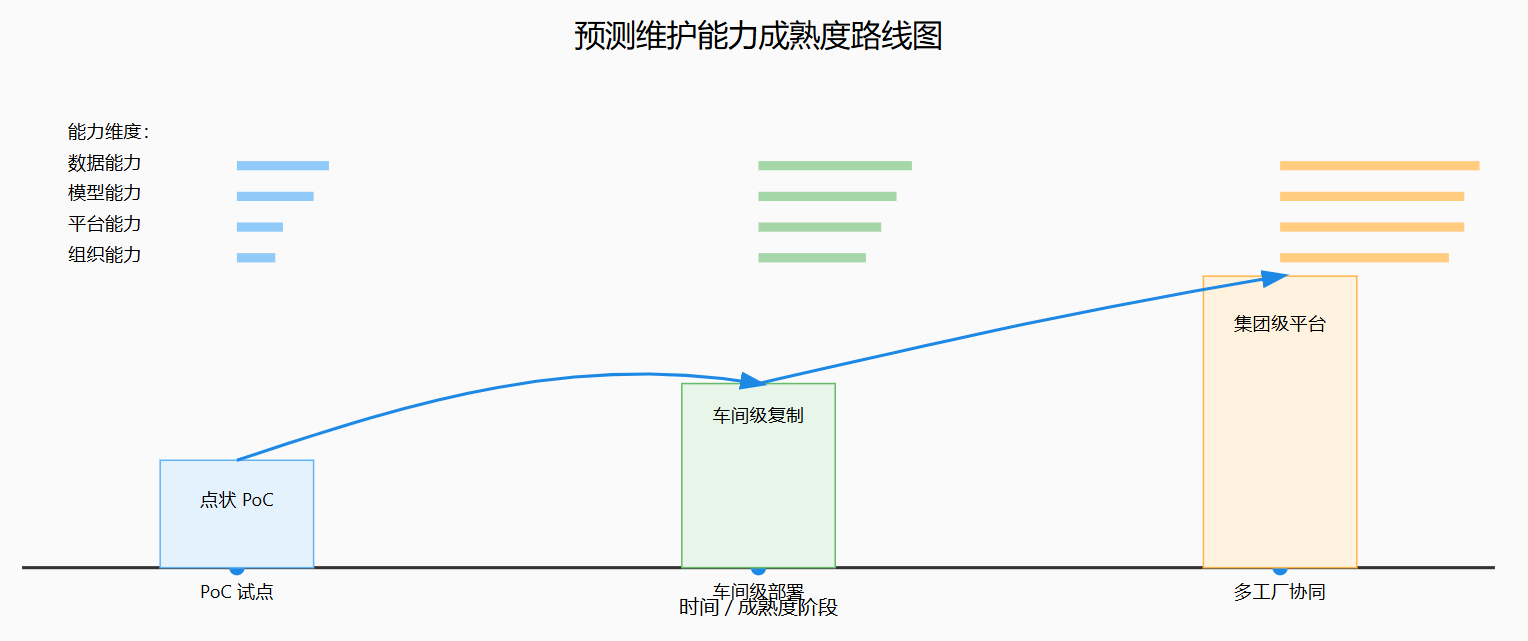
图5:预测维护从 PoC 到规模化的能力成熟度演进路线图
3 自适应生产调度:用强化学习和多智能体重构车间大脑
3.1 生产调度的复杂性与传统方法局限
相比预测维护,生产调度问题在工业工程领域的研究历史更长,经典的 Job Shop Scheduling(车间作业调度)、Flow Shop(流水车间)、Flexible Job Shop(柔性车间)等问题已经被研究几十年。然而,现实车间往往远比标准调度问题复杂:订单到达具有随机性,工艺路线可能因设备故障或工装短缺而临时变化,生产过程中存在返修、插单、优先级改变等频繁扰动,同时还需要考虑能耗、碳排、库存和供应链波动等多重目标。(Taylor & Francis Online)
传统调度方法包括规则驱动(如最短加工时间优先、最早交期优先)、数学规划(如混合整数规划)以及各种启发式与元启发式算法(如遗传算法、粒子群、禁忌搜索等)。这些方法在静态、小规模或约束简单的场景下表现良好,但在面对高度动态和不确定的车间环境时,它们往往需要频繁重算,且难以在合理时间内给出高质量解。(MDPI)
近年来,强化学习(Reinforcement Learning, RL)被越来越多地引入生产调度领域。Esteso 等在 2023 年发表的综述文章系统梳理了 RL 在生产计划与控制中的应用,指出 RL 特别适合处理具有长期回报、复杂状态空间和不完全信息的调度问题,能够通过与仿真环境交互学习近似最优或高质量的调度策略。(Taylor & Francis Online)2024 年的系统综述进一步通过文献计量分析展示了 RL 在调度领域的爆发式增长,并总结了 Q-learning、Deep Q Network(DQN)、Actor–Critic、近端策略优化(PPO)等算法在不同调度问题上的应用模式。(MDPI)
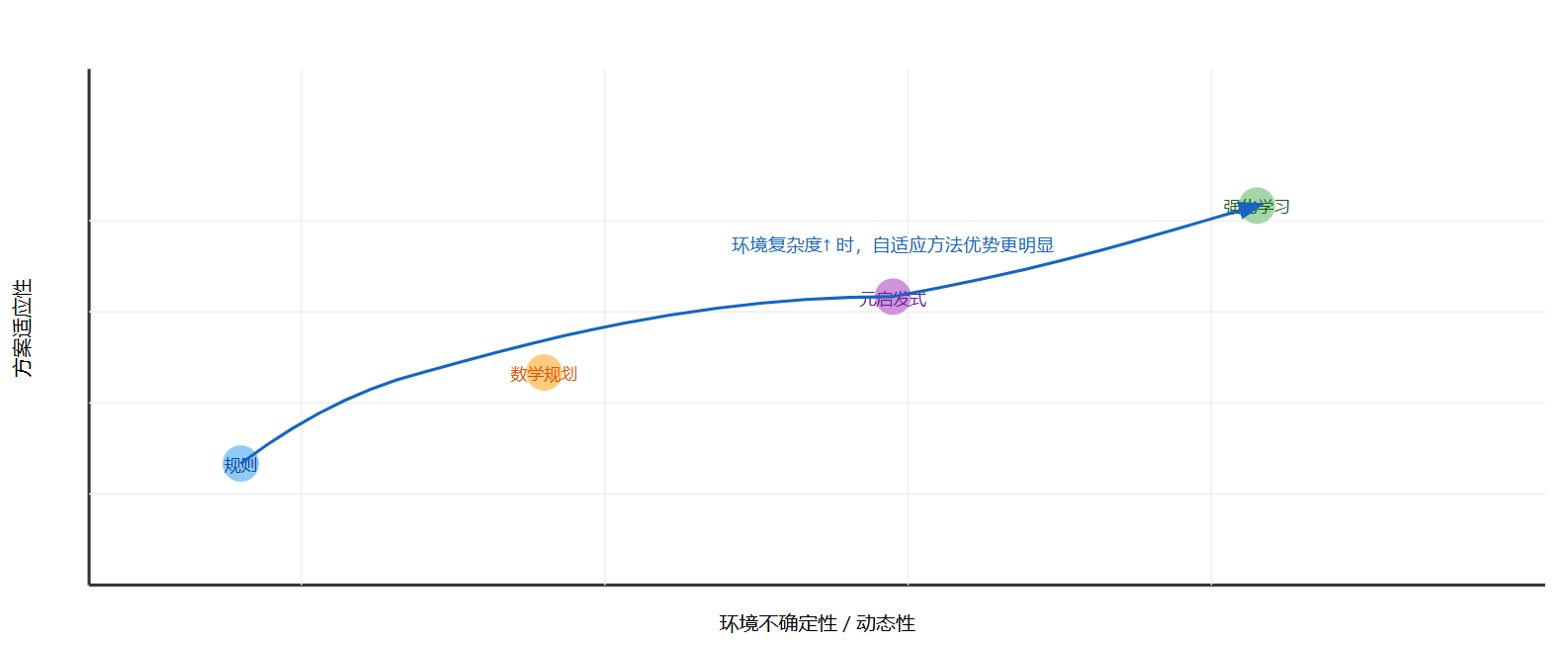
图6:传统规则调度、数学规划和强化学习调度在复杂性与适应性上的对比示意图
3.2 深度强化学习与多智能体调度架构
在具体方法上,最新的调度研究逐渐从单智能体强化学习发展到多智能体系统,并与数字孪生和工业互联网紧密结合。Chang 等在 2023 年的工作中,将数字孪生与深度强化学习结合,实现了实时生产调度:通过数字孪生仿真车间状态,RL 智能体不断与仿真环境交互,学习在动态事件(如新订单、机器故障)下调整排程的策略,从而实现对复杂制造系统的实时调度优化。(SAGE Journals)
Chen 等在 2025 年提出了一种基于多智能体网络化 CPS(Cyber-Physical System)架构的自适应调度系统,针对离散制造车间,将机器、缓冲区、运输设备等建模为协同的智能体,通过多智能体强化学习和协调机制,实现对动态扰动下车间调度的自适应调整。(ACM Digital Library)Du 等在 2025 年的研究中进一步利用合作式多智能体 RL,在个性化生产场景下实现了能够实时响应需求变动的调度策略,强调了个性化、短交期与柔性生产背景下自适应调度的重要性。(Taylor & Francis Online)
在调度环境建模上,Lang 等提出了将生产调度问题系统性建模为强化学习环境的方法,利用离散事件仿真构建状态转移,实现了可重复、可扩展的 RL 训练环境。(科学直接)围绕这一思想,一系列开源调度环境和框架相继出现,例如 JSSEnv(Job Shop Scheduling Environment)、RL-Job-Shop-Scheduling、graph-jsp-env、jsspetri 以及 gym-flp 等,它们大多基于 OpenAI Gym 或 Gymnasium 接口,为研究者和工程师提供了可直接使用的训练环境。(GitHub)
表3 典型自适应生产调度开源环境与框架概览
| 环境/框架 | 技术基础与接口 | 支持的问题类型 | 主要特性与适用场景 | 参考来源 |
|---|---|---|---|---|
| JSSEnv | Python + OpenAI Gym | Job Shop Scheduling | 针对 JSSP 的优化环境,实现高效仿真与状态表示 | GitHub JSSEnv(GitHub) |
| RL-Job-Shop-Scheduling | Python + DRL + Gym | Job Shop Scheduling | 提供 JSSP 强化学习实现,可复现相关论文的实验 | GitHub 项目(GitHub) |
| graph-jsp-env | Python + Gymnasium + 图建模 | Job Shop Scheduling(图表示) | 使用离散图结构表示调度问题,支持更复杂的状态编码 | GitHub graph-jsp-env(GitHub) |
| jsspetri | Python + Petri 网 + Gym 接口 | Job Shop Scheduling | 通过 Petri 网建模车间,适合分析并发与同步行为 | JSSPetri 项目(PyPI) |
| gym-flp | Python + OpenAI Gym | 设施布局与相关生产问题 | 为设施布局问题设计的 RL 环境,可扩展到调度研究 | Heinbach 等(EconStor) |
| schlably | Python DRL 框架 | 多种调度与优化问题 | 面向生产调度的 DRL 开发框架,便于构建和比较算法 | de Puiseau 等(科学直接) |
在算法层面,针对生产调度的强化学习研究已经从早期的基于表格 Q-learning 和 DQN,发展为融合注意力机制、图神经网络和层次化 RL 的复杂结构。例如,近期关于生产工期预测与动态关键路径方法(EMA-DCPM)的研究通过引入注意力机制提升了作业时间预测的准确性,为调度算法提供更加可靠的输入。(Nature)又如,对低碳柔性作业车间调度(LC-FJSP)的研究将碳排放与完工时间同时纳入优化目标,在数学模型基础上结合智能优化算法以兼顾效率与可持续性。(MDPI)
更进一步,Stöckermann 等在 2025 年的工作中,将深度强化学习应用于多个公开基准工厂和一个大型工业半导体制造场景的批次派工问题,系统评估了不同 DRL 方法在真实工业级场景中的可扩展性,表明 RL 在复杂制造系统调度上具备现实应用潜力。(SpringerLink)
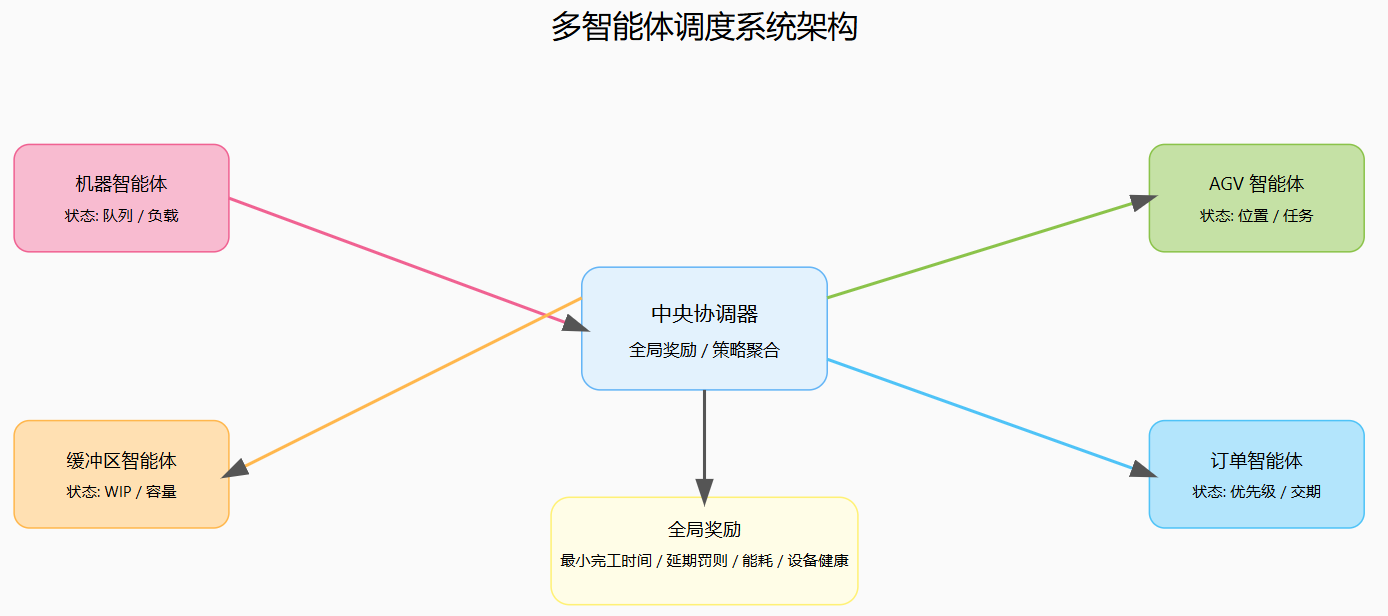
图7:多智能体调度系统架构示意图
3.3 面向低碳与弹性供应链的调度优化新目标
随着“双碳”目标和可持续发展要求的提出,生产调度正在从“单一追求交期与产能”转向多目标优化,包括能耗、碳排、设备健康、库存与供应链韧性等。Tang 等在 2024 年提出的低碳柔性作业车间调度模型(LC-FJSP),在经典柔性作业车间调度的基础上,将设备的运行能耗与空闲能耗纳入机器参数,通过构建多目标数学模型,将总完工时间和碳排放的加权和作为优化目标。(MDPI)这类工作表明,生产调度可以从源头上纳入能源消耗与环境影响,而不仅仅在设备层面做能耗优化。
另一方面,时间预测能力的增强也使得调度模型能够更好地应对供应链波动和订单不确定性。Wang 等在 2024 年提出的 EMA-DCPM 模型中,通过引入注意力机制的机器学习方法预测产品作业时间,并结合改进的动态关键路径方法优化项目和生产任务的时间安排,从而提升了调度方案对不确定工期的鲁棒性。(Nature)结合这类时间预测模型与强化学习或智能优化算法,可以实现对“交期风险”的主动控制。
更进一步的研究开始尝试将预测维护与调度联合建模,如通过生成式深度学习模型对工序级健康状态进行预测,并将其转化为操作级别的健康指数,再由调度算法利用这些指数进行资源分配和顺序安排,以避免在健康状态较差的设备上安排关键路径工序。(SpringerLink)这类联合优化框架为未来“自感知、自决策”的工厂提供了可行的技术路径。
表4 调度优化目标与典型指标映射
| 优化维度 | 调度目标示例 | 典型指标与度量方式 | 相关研究参考 |
|---|---|---|---|
| 交期与产能 | 最小化总完工时间、延迟订单数、延期罚则 | 总完工时间、平均延迟、按期交付率 | 综述与基准研究(Taylor & Francis Online) |
| 能耗与碳排 | 最小化能耗与碳排 | 单件能耗、单位产值碳排、峰谷电价加权能耗 | LC-FJSP 模型(MDPI) |
| 设备健康与可靠性 | 避免在高风险设备上安排关键任务 | 健康指数分布、健康约束违反次数、预测停机窗口利用率 | 健康驱动调度框架(SpringerLink) |
| 供应链与库存 | 兼顾库存周转与交期 | 在制品(WIP)水平、缺料次数、安全库存占用 | AI in Manufacturing 综述(科学直接) |
3.4 自适应调度落地实践与开源方案
与预测维护类似,自适应调度的落地也离不开可复用的仿真环境和开源框架。基于 OpenAI Gym/Gymnasium 接口的调度环境(如 JSSEnv、graph-jsp-env、jsspetri 和 gym-flp 等)为算法开发与对比提供了统一接口,而 schlably 等面向生产调度的 DRL 框架则进一步封装了网络结构、训练循环与评估流程,使工程团队能够更专注于业务建模与奖励函数设计。(GitHub)
从工程视角看,一个可落地的自适应调度系统通常包含以下几个关键组成部分:第一,可信的仿真或数字孪生环境,用于在安全环境中训练和评估调度策略;第二,可在线更新的调度策略部署机制,使 RL 策略或智能启发式能够在真实车间中以“建议+人工确认”或“半自动执行”的方式运行;第三,与 MES、APS 和 ERP 的数据接口,使调度系统能够实时获取订单、库存、设备状态和工艺参数,并将调度结果推送到执行系统。Chang、Chen、Du 等人的研究工作表明,通过网络化 CPS、多智能体系统与数字孪生的结合,可以在保证安全和可控的前提下,在真实车间环境中逐步引入自适应调度。(SAGE Journals)
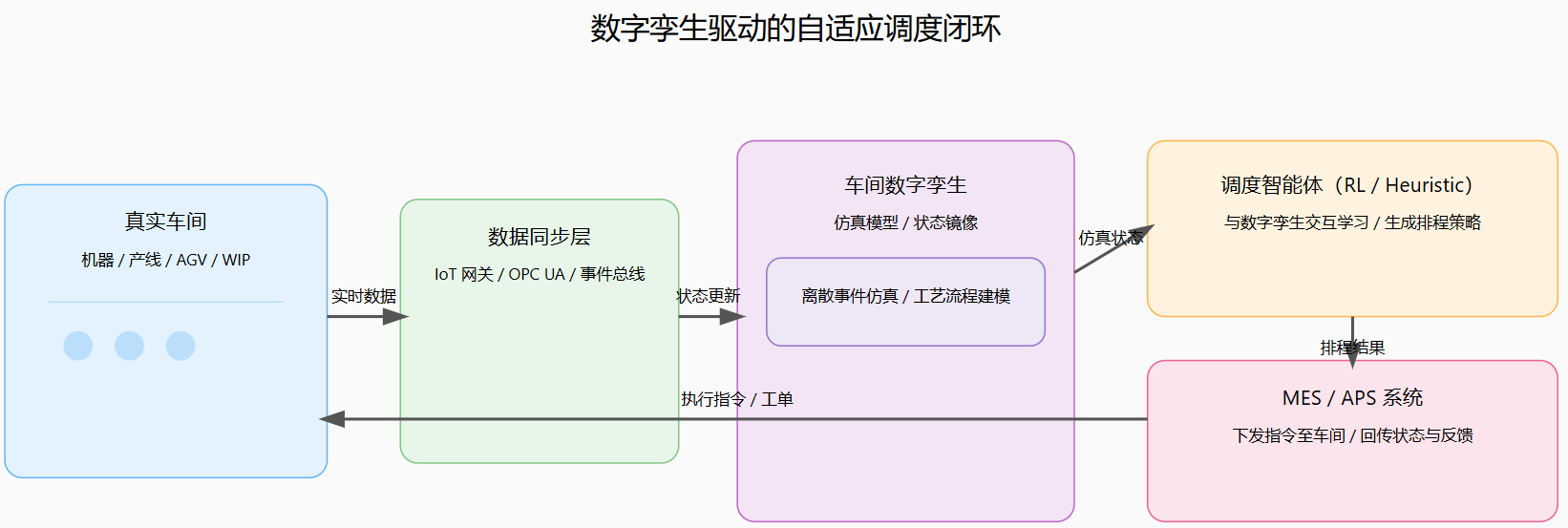
图8:基于数字孪生的自适应调度系统端到端结构图
4 从预测维护到自适应调度:一体化智能制造架构设计
4.1 数据与模型的统一视角:设备健康—订单—资源三位一体
在传统工厂里,维护系统和生产调度系统往往彼此割裂:维护部门关心设备是否会坏、何时停机,而计划/调度部门关心订单能否按时交付、产能是否足够。AI 落地为打通这两套系统提供了技术基础:如果可以在统一的数据平台中同时获取设备健康状态、订单优先级和资源约束信息,就可以通过联合建模实现更高层次的全局优化。
近期针对预测维护与调度一体化的研究强调,关键在于建立统一的状态表示:将设备健康指数(或 RUL 预测)、订单紧急程度、工序加工时间预测和资源占用等信息,在同一状态空间中表示出来,使调度智能体能够同时感知“设备风险”和“订单压力”。(SpringerLink)同时,通过统一的数据仓库和流式数据总线(如基于 Apache Kafka 或工业消息总线的架构),可以让预测维护模型与调度模型共享实时数据源,而不必各自建设重复的采集和清洗链路。(PMC)
在这种统一视角下,预测维护输出的不再只是单一的告警或工单,而是面向上层决策的“约束与偏好”:例如,在未来若干时间窗口内,某台设备具有较高故障风险,那么调度模型在同一时间窗口内应当降低在该设备上的负荷,或者安排非关键路径任务;一旦预测到某个停机窗口,则可以将其视为“硬约束”嵌入调度问题。
4.2 数字孪生与工业互联网平台:闭环的关键基础设施
实现预测维护与自适应调度的闭环,很难仅靠单点系统,需要数字孪生和工业互联网平台作为基础设施。Barua 等在 2025 年的研究中,从战略视角讨论了 AI 在智能生产管理中的实施路径,强调预测维护、实时调度、视觉质检与供应链优化等 AI 应用需要在统一的“智能生产管理平台”上协同运行,而不仅仅是多个孤立系统。(Nature)Gao 等 2024 年对制造业 AI 应用的综合综述也指出,从生产系统设计与规划到过程建模与优化,AI 应用都受益于统一的数据基础设施与模型管理能力。(科学直接)
数字孪生在这一架构中承担着“试验场”和“影子工厂”的角色:预测维护模型可以在数字孪生中评估不同维护策略的长期影响,而调度智能体则可以在数字孪生中安全地试验新的排程策略和参数,避免对真实生产造成风险。Chang 等关于数字孪生驱动实时调度的工作表明,这种“仿真+RL”的模式能够有效提升调度策略应对动态事件的能力。(SAGE Journals)
工业互联网平台则提供了连接真实设备、信息系统与云/边计算资源的“操作系统”。Su 等提出的统一预测维护平台以及多项智能制造平台化研究展示了通过云原生技术与边缘节点的协同,可以在保证实时性和可靠性的前提下,将预测维护与调度优化等计算任务灵活部署在边缘或云端。(PMC)

图9:预测维护 + 自适应调度一体化数字孪生与工业互联网平台架构图
4.3 典型落地蓝图:面向离散制造工厂的整体方案
以一家典型的离散制造工厂为例(例如汽车零部件加工或电子装配工厂),一体化“预测维护 + 自适应调度”落地蓝图可以概括为以下几个关键构件的组合。首先,在设备层通过加装或启用现有传感器采集关键状态数据,例如主轴振动、电流、电压、工件温度等,并通过边缘网关将数据实时上传到数据平台。其次,在平台侧构建用于预测维护的特征工程和建模流水线,利用历史故障与维护记录训练故障预测和 RUL 模型,并为每台关键设备持续生成健康指数和风险评估。
在此基础上,构建车间级数字孪生模型,将工序路线、设备能力、缓冲区、AGV 路径等要素建模为仿真环境,并利用 RL 或智能启发式训练自适应调度策略。调度策略在每个决策步中,不仅观察订单队列和设备可用性,还会接收来自预测维护模块的“设备健康状态向量”,从而自动避免将关键路径任务安排到预测风险较高的设备上。
在运行阶段,预测维护模型与调度智能体分别以服务形式部署,通过工业消息总线与 MES/APS 系统互联。当预测到某设备在未来一段时间内存在高概率故障时,维护系统会生成建议维护窗口,并将这一约束发送给调度系统;调度系统则会重算未来排程,在满足交期的前提下最大化利用其他设备,避免在潜在故障窗口内安排关键任务。
这种蓝图的价值在于,它不再把维护视为“生产之外的支撑函数”,而是将设备健康作为生产计划的输入之一,从而在全局层面优化“交期–成本–风险”的多目标平衡。结合最新的市场预测和案例研究,这样的一体化架构已经从实验室走向部分先锋工厂,未来几年有望在更多智能制造项目中出现。(Nature)
5 工程实践要点:平台、算法与组织变革
5.1 平台与技术栈选型:云边协同、MLOps 与 AIOps
从工程实现角度,预测维护与自适应调度并不是两个孤立的“模型项目”,而是需要长期运营的“AI 产品”。这意味着平台与技术栈的选型应优先考虑可运维性、可扩展性和与现有 IT/OT 系统的兼容性。近年来,大量关于边缘侧预测维护和 MLOps 实践的文章强调,通过在边缘设备上运行轻量级模型,可以显著降低延迟、节省带宽,并提升对网络中断的鲁棒性,而云端则适合承担模型训练、批量推理和跨工厂数据融合的任务。(Mouser Electronics)
在技术栈层面,通用的时序数据管理和流处理框架(如 Apache Kafka、Flink、Spark Streaming 等)已经成为连接 OT 与 AI 的事实标准;在模型部分,主流的深度学习框架(如 PyTorch、TensorFlow)与时间序列建模库(如 Prophet、sktime 等)为预测维护提供了丰富的工具选择,而针对调度领域的 DRL 框架和环境(如前文提到的 JSSEnv、schlably、gym-flp 等)则为自适应调度提供了算法实验与工程落地的基座。(科学直接)
5.2 模型治理与可解释性:从黑盒到灰盒
在设备维护和生产调度这两个高度工程化的领域,模型的可解释性与可控性具有特殊重要性。维护工程师和计划员通常不会盲目相信一个“黑盒模型”的输出,而是需要理解模型在做出预测和决策时关注了哪些变量,以及这些决策在不同场景下的稳定性如何。
最新的研究在可解释预测维护方面做了大量工作,例如针对 PdM 决策的情境化解释(contextual explanations),通过结合模型本身的特征重要性和设备运行上下文,为工程师提供更可读的解释报告,帮助他们理解为何某台设备在当前工况下被判定为“高风险”。(SpringerLink)在调度领域,图神经网络与注意力机制的引入同样为解释“智能体为何选择某个工件/机器组合”提供了可能,通过可视化注意力权重和状态嵌入,可以让工程师逐步建立对 RL 调度策略的信任。(Nature)
此外,模型治理还包括版本管理、数据漂移监测、性能退化告警和再训练策略等内容。统一的 MLOps/AIOps 平台可以记录每个模型版本的训练数据、特征工程流程、超参数和评估指标,并在部署后持续收集在线推理的表现,一旦发现模型性能显著下降或数据分布发生明显偏移,就触发再训练或回滚机制。(PMC)在多工厂场景下,还需要考虑联邦学习或跨工厂迁移学习等机制,以在保护数据隐私和降低数据汇聚成本的前提下共享模型经验。
5.3 组织与能力建设:从试点团队到全员协同
大量调研显示,阻碍智能制造和 AI 项目落地的,并不只是技术和数据问题,更多是组织和能力建设问题。Rootstock 与 Researchscape 在 2023 年对 350 家制造企业的调研表明,尽管多数企业认可 AI 的潜在价值,但在实际应用中,缺乏跨部门协同、业务场景定义不清和技能不足是最突出的挑战。(Rootstock Software)Deloitte 2025 年的调查也指出,虽然约三成企业已经在工厂层面部署 AI/ML,但多数还停留在试点阶段,亟需将 AI 能力嵌入日常运营流程。(Deloitte)
在“预测维护 + 自适应调度”这样的复合场景中,组织协同尤为重要:维护团队需要与生产计划、质量和 IT 团队共同定义目标和约束;数据科学家和自动化工程师需要共同设计可部署的模型与系统;工厂管理层则要在战略上支持从“经验驱动”向“数据与模型驱动”的文化转型。越来越多的成功案例表明,将 AI 团队嵌入到业务线中,与维护与生产团队组成长期稳定的跨职能小组,比建立“集中式 AI 中心”更有利于持续的场景孵化与落地。(Nature)
从能力建设角度,企业可以通过内部培训与外部合作的方式,逐步建立预测维护工程师、数据工程师、MLOps 工程师和调度优化专家等复合型人才队伍,并为他们提供充足的实验空间和真实数据,同时建立清晰的价值衡量指标,如停机时间减少、维护成本下降、交期稳定性提升等,以确保 AI 项目与业务目标持续对齐。
6 结语:迈向自优化、自演化的未来工厂
从最新的研究与实践来看,“预测维护”和“自适应生产调度”正在成为智能制造中最先跑通闭环的两个核心场景:前者通过对设备健康的前瞻性预测,帮助企业减少非计划停机、优化备件与维护资源;后者通过对复杂生产系统的实时决策优化,使工厂能够更好地应对订单波动、设备故障和多目标约束。更重要的是,越来越多的研究与项目不再将二者视为孤立模块,而是尝试构建“设备健康—生产调度—供应链”三者联动的一体化架构。(Nature)
在技术层面,深度学习、强化学习、多智能体系统、图神经网络和注意力机制等方法,为建模复杂工业系统提供了强大工具;数字孪生和工业互联网平台则为大规模部署与在线决策提供了基础设施;开源生态的发展使得中小企业也有可能基于开源框架构建自己的预测维护与调度系统。(科学直接)
在工程和组织层面,真正的挑战在于如何把这些技术长期运营起来:建立统一的数据与模型平台、设计可迭代的落地路线、构建跨部门协同的团队和机制,并在每一个阶段持续衡量和复盘价值。对于愿意在这一方向上投入的制造企业来说,当预测维护与自适应调度逐步成为“工厂操作系统”的一部分时,工厂将从被动响应走向主动优化,最终迈向“自感知、自决策、自演化”的未来形态。
在这个过程中,开放的学术研究与开源社区将持续扮演关键角色:它们不仅提供可复用的算法与工具,更重要的是共享经验和最佳实践,让不同规模和行业的制造企业都能够参与到这场智能制造的深度变革之中。
参考文献(节选)
[1] Achouch M., et al. “On Predictive Maintenance in Industry 4.0: Overview, Trends and Challenges.” Applied Sciences, 2022.(MDPI)
[2] Çinar Z. M., et al. “Machine Learning in Predictive Maintenance towards Sustainable Smart Manufacturing.” Sustainability, 2020.(纯粹)
[3] Hector I., et al. “Predictive Maintenance in Industry 4.0: A Survey of Technologies, Use Cases and Challenges.” 2024.(PMC)
[4] Benhanifia A., et al. “Systematic Review of Predictive Maintenance Practices in Manufacturing Industry.” 2025.(科学直接)
[5] Pejić Bach M., et al. “Predictive Maintenance in Industry 4.0 for the SMEs: A Decision Support System Case Study Using Open-Source Software.” Designs, 2023.(MDPI)
[6] Mateus B. C., et al. “Hybrid Deep Learning for Predictive Maintenance.” Energies, 2025.(MDPI)
[7] Li W., et al. “Comparison of Deep Learning Models for Predictive Maintenance in Industrial Manufacturing Systems.” Scientific Reports, 2025.(Nature)
[8] Su N., et al. “Elevating Smart Manufacturing with a Unified Predictive Maintenance Platform.” 2024.(PMC)
[9] IoT Analytics. “Predictive Maintenance Market: 5 Highlights for 2024 and beyond.” 2023.(IoT Analytics)
[10] Auburn University ICAMS. “Smart Manufacturing Adoption Study 2024.”(奥本大学工程学院)
[11] Deloitte. “2025 Smart Manufacturing and Operations Survey.” 2025.(Deloitte)
[12] Rootstock Software. “State of AI in Manufacturing Survey.” 2023.(Rootstock Software)
[13] Gao R. X., et al. “Artificial Intelligence in Manufacturing: State of the Art, Challenges, and Emerging Trends.” 2024.(科学直接)
[14] Bandhana A., et al. “AI-Driven Manufacturing: Surveying for Industry 4.0 and 5.0.” 2025.(SpringerLink)
[15] Barua D. A., et al. “Leveraging Artificial Intelligence for Smart Production Management.” Scientific Reports, 2025.(Nature)
[16] Chang X., et al. “Digital Twin and Deep Reinforcement Learning Enabled Real-time Production Scheduling.” 2023.(SAGE Journals)
[17] Chen J., et al. “Self-adaptive Production Scheduling for Discrete Manufacturing Based on CPS-MAS.” 2025.(ACM Digital Library)
[18] Du B., et al. “Cooperative-based Multi-agent Reinforcement Learning for Adaptive Production Scheduling.” 2025.(Taylor & Francis Online)
[19] Esteso A., et al. “Reinforcement Learning Applied to Production Planning and Control.” International Journal of Production Research, 2023.(Taylor & Francis Online)
[20] Modrak V., et al. “A Review on Reinforcement Learning in Production Scheduling.” Algorithms, 2024.(MDPI)
[21] Xu M., et al. “Learn to Optimise for Job Shop Scheduling: A Survey with Taxonomy.” 2025.(SpringerLink)
[22] Tang Y., et al. “Low-Carbon Flexible Job Shop Scheduling Problem Based on Energy Consumption and Carbon Emissions.” Sustainability, 2024.(MDPI)
[23] Wang L., et al. “EMA-DCPM: A Machine Learning Based Dynamic Critical Path Method with Attention Mechanism.” Scientific Reports, 2024.(Nature)
[24] Heinbach B., et al. “gym-flp: A Python Package for Training Reinforcement Learning Agents on Facility Layout Problems.” 2024.(EconStor)
[25] de Puiseau C. W., et al. “schlably: A Python Framework for Deep Reinforcement Learning in Production Scheduling.” 2023.(科学直接)
[26] GitHub Repositories: JSSEnv, RL-Job-Shop-Scheduling, graph-jsp-env, jsspetri, pmx_data, kokikwbt/predictive-maintenance, predictive-maintenance-showcase, iot-predictive-maintenance, etc.(GitHub)
[27] Islam M. R., et al. “Artificial Intelligence in Predictive Maintenance: A Systematic Literature Review on Review Papers.” 2024.(SpringerLink)
(以上参考文献仅列出本文引用的部分核心文献,读者可根据 DOI 或标题进一步检索完整内容。)


















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











