






目录
文章内容基于文献《Revisiting U-Net: a foundational backbone for modern generative AI》并对其进行总结提炼,供读者学习。
1 引言
在过去十年里,生成式人工智能经历了从 GAN、VAE,到 Transformer、大规模扩散模型的快速演化。如今我们熟悉的文生图(text-to-image)、文生音频、视频生成、三维重建、姿态与动作生成等任务背后,往往隐藏着一个“看似传统”的卷积结构:U-Net。对于很多初学者来说,U-Net 似乎只是做医学图像分割的经典网络;但如果把视角从应用拉回到“架构”本身,就会发现:在大量扩散模型、条件 GAN、甚至部分自回归模型中,真正承担“生成器/去噪器”职责的,往往就是各种变体化的 U-Net。
因此,如果只把 U-Net 理解成“分割网络”,很容易低估它在生成式 AI 中的地位。更合理的看法是:U-Net 是一种通用的编码器–解码器(encoder–decoder)骨干结构,通过多尺度卷积特征、跳跃连接、归一化与残差单元等机制,为不同范式的生成模型提供了一个稳定、可扩展、细节友好的特征变换“母体”。无论是 Stable Diffusion 这样的潜空间扩散模型,还是图像到图像翻译的条件 GAN、音频语音的 U 形网络、基于 U-Net Encapsulated Transformer 的语言模型,核心思路都离不开这条“U 型路径”。
为了真正用好现代扩散/生成模型,理解 U-Net 的理论基础、架构变体与跨模态应用非常关键。本文将从基础理论与技术出发,系统梳理 U-Net 的编码–解码结构、跳跃连接、归一化与注意力等核心机制,随后以扩散模型、GAN、自回归模型三大生成范式为主线,结合图像、文本、音频、视频、三维和姿态/动作等多种数据模态,讨论 U-Net 作为“生成骨干”的角色与演化脉络。中后部分将重点分析其优势与局限,从架构角度理解为何在 Transformer 统治的时代,U-Net 依然是现代生成式 AI 无法绕开的基础组件。
2 理论知识与技术基础
在进入具体的 U-Net 结构之前,有必要先把几个底层理论讲清楚:多维数据表示形式、卷积与下采样/上采样的本质,编码器–解码器与跳跃连接的思想,以及归一化、注意力、残差连接等“现代深度网络三大件”。这些内容既是 U-Net 设计的理论基础,也是理解其在扩散、GAN、自回归等框架中扮演角色的关键。
2.1 多维数据与卷积算子的统一视角
在一个统一的记号体系中,可以把输入数据表示为 ,其中 D 表示“空间/时间/体素”维度,C 表示通道数。具体到不同模态:
-
一维数据:如语音波形、时间序列、token 嵌入,长度可以记为 L(空间)或 T(时间);
-
二维数据:最典型的是图像,尺寸为 H×W,三个颜色通道则体现在通道维 C 上;
-
三维数据:可以是视频(H×W×T),也可以是体数据(H×W×L用于 CT/MRI 等)。
卷积核本质上是局部线性变换,参数尺寸为,其中 K 在 1D 是长度,在 2D 是
,在 3D 则是
或
。卷积通过滑动窗口在局部感受野内对输入做加权求和,实现局部模式检测与平移不变性。
在 U-Net 中,下采样阶段通过卷积 + 池化逐步压缩空间/时间维度、扩展通道数,从而形成层次化表示;上采样阶段则通过转置卷积或插值 + 卷积将低分辨率特征还原成高分辨率输出。所有这些操作,本质上都是针对 在不同尺度上的线性与非线性变换。
2.2 编码器–解码器与跳跃连接的思想
编码器–解码器框架可看作一种“信息压缩–重建”机制:
-
编码器(contracting path)通过连续的卷积、归一化、非线性与池化,把输入转换为更抽象的表示;
-
解码器(expansive path)则逐步上采样,将高层语义重新映射回原输入分辨率空间。
如果只有这种“先压缩再重建”的结构,中途必然会丢失大量细节。这也是早期自编码器重建图像容易“糊”的根本原因。U-Net 的关键创新在于引入了跳跃连接(skip connections):在每个尺度上,把编码器对应层的特征直接“跨越”到解码器同尺度层,与上采样特征进行拼接或相加,然后再经过卷积 refinement,从而在重建时补回低层细节信息。形象地说,编码器负责“理解你在看什么”,跳跃连接负责“记得细节长什么样”。
正是这种多尺度、层次化的信息融合,使 U-Net 在分割、重建、生成任务中都能兼顾整体结构与局部细节。
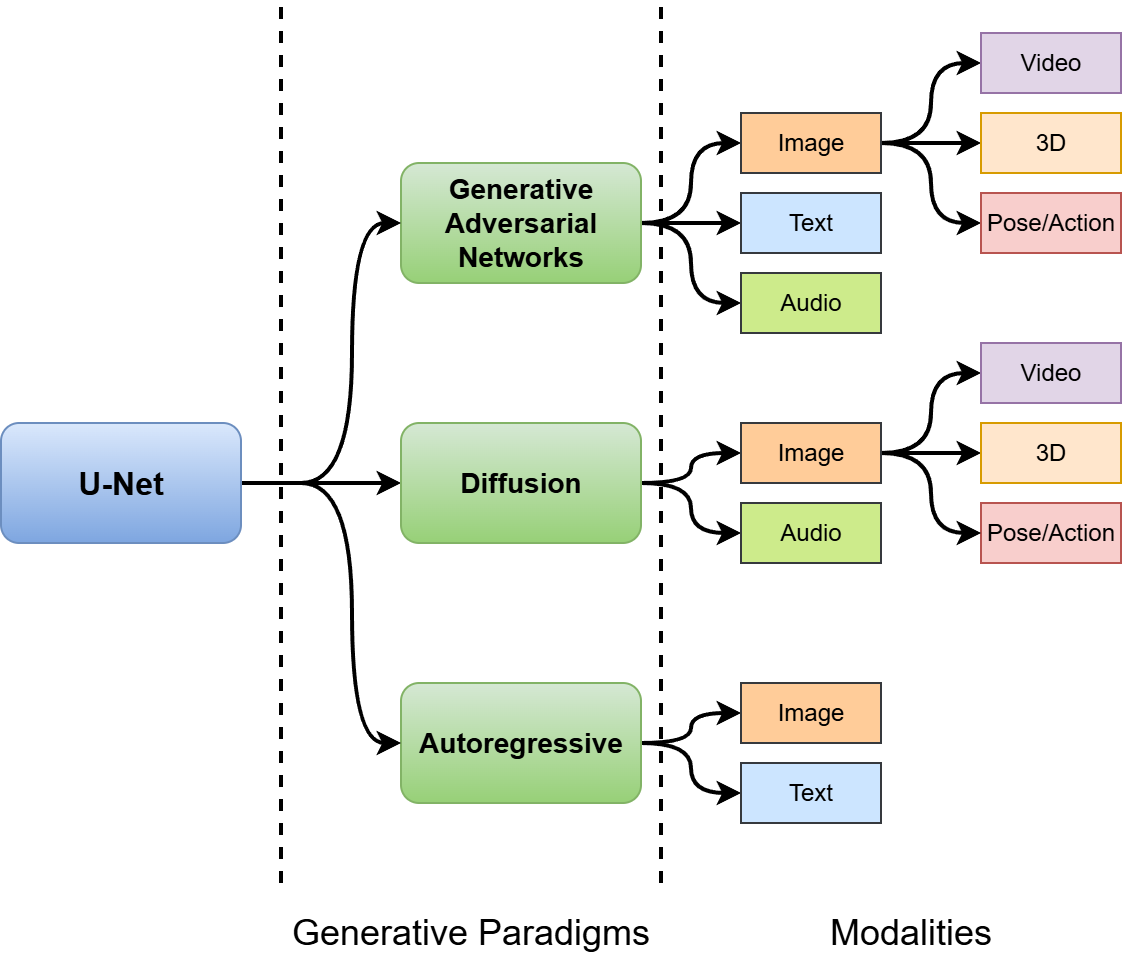
图1 U-Net 在生成式 AI 中的范式–模态分类示意
图1从“生成范式”(GAN / Diffusion / Autoregressive)和“数据模态”(图像、文本、音频、视频、3D、姿态/动作)两个轴出发,整理了 U-Net 在不同组合中的角色,凸显出其作为“统一骨干”的地位。
2.3 归一化、注意力与残差连接基础
现代深度网络要训练得稳,往往少不了三类技术:
-
归一化(Normalization):BatchNorm、LayerNorm、InstanceNorm、GroupNorm 等,核心作用是稳定激活分布、缓解梯度爆炸/消失。U-Net 最早广泛使用 BatchNorm,但在小 batch 或扩散模型中,则更常见 LayerNorm、GroupNorm、InstanceNorm。
-
注意力机制(Attention):卷积的感受野有限,而自注意力可以在全局范围内建模长程依赖。自注意力(self-attention)主要用于单模态内部建模,交叉注意力(cross-attention)则用于跨模态对齐(如文本–图像、文本–音频)。
-
残差连接(Residual Connection):通过“身份映射 + 残差变换”形式,使网络学习到的是“增量变化”,缓解深层网络的退化与梯度问题,代表作是 ResNet 以及大量 ResUNet 变体。
在后续章节我们会看到,几乎所有现代 U-Net 变体都会在卷积块中融合归一化、注意力、残差这三类机制,从而在不同生成范式中取得良好的训练稳定性与表达能力。
3 U-Net 经典结构与通用形式
3.1 标准 U-Net 的整体结构
经典 U-Net 可以抽象为一个对称的 U 形结构:左边是编码器,右边是解码器,中间是瓶颈层,两侧每一层之间通过跳跃连接相连。结构上通常包含 4~5 个尺度,每个尺度的处理流程基本一致:
-
若干个 3×3卷积 + 归一化 + ReLU;
-
编码端使用 2×2最大池化进行下采样,通道数翻倍;
-
解码端使用转置卷积或上采样恢复分辨率,并与对应尺度编码特征拼接;
-
最后一层用 1×1 卷积将通道映射到输出通道数,并根据任务选择 softmax / sigmoid / tanh 等输出激活。
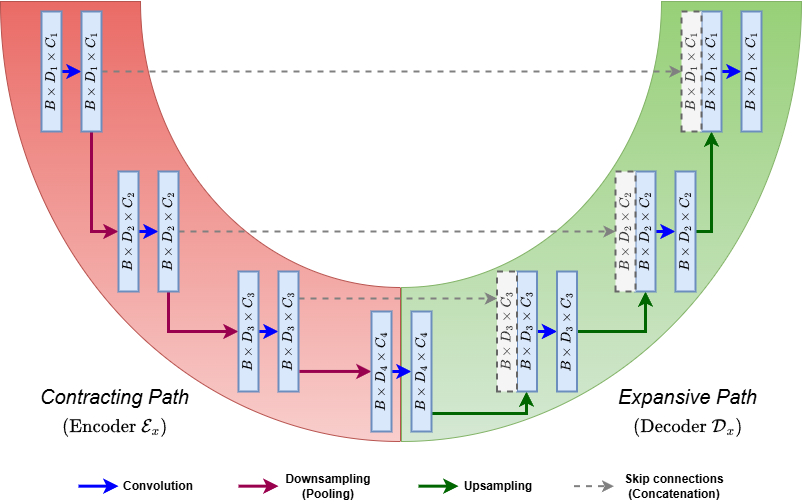
图2 标准 U-Net 编解码结构示意
图2直观展示了“收缩路径 + 扩展路径 + 跳跃连接”的整体结构:左侧特征与右侧对应尺度相连,构成 U 形路径,这也是“U-Net”命名的来源。
3.2 编码器:层次特征提取与下采样
在编码器部分,每一层可以形式化为:给定输入特征,先后经历两次卷积 + 归一化 + ReLU:
$$F_i = \mathrm{ReLU}(\mathrm{Norm}(\mathrm{Conv}_{3\times3}(F_{i-1}))) \\ F_i = \mathrm{ReLU}(\mathrm{Norm}(\mathrm{Conv}_{3\times3}(F_i)))$$
然后使用最大池化进行空间/时间降采样:
$$F_i^{\text{down}} = \mathrm{MaxPool}_{2\times2}(F_i)$$
最大池化的数学形式可以理解为:在 kernel 覆盖的局部区域 内取最大值,既缩小分辨率,又保留最强响应,从而使高级层能够看到更大的感受野。
编码器每一层的输出会被缓存,用于后续解码阶段的跳跃连接。
3.3 解码器:上采样与重建
解码器的目标是将瓶颈特征逐步“放大”回输入尺度,同时恢复清晰边界与细节。典型流程为:
-
利用转置卷积或上采样 + 卷积,把特征图上采样一倍;
-
与编码器对应层特征
在通道维拼接;
-
再经过两次卷积 + 归一化 + ReLU 进行特征融合与细化。
转置卷积可以被理解为普通卷积的“逆向操作”:通过在输出上扩展位置、再用卷积核加权求和来实现可学习的上采样。形式上可以写成:
$$F' = W^\top * F$$
其中 表示卷积核的“转置”,∗为卷积运算。
3.4 跳跃连接的作用
在第 l 个尺度,跳跃连接的融合过程可以写为:
$$F_x^{(l)} = \mathrm{Concat}(E_x^{(l)}, D_x^{(l)})$$
其中是编码器第 l 层特征,
是解码器上采样后的特征。拼接后的特征再通过卷积块进行重建。这一操作带来三方面好处:
-
保留低层空间细节,避免因多次下采样造成边界模糊、纹理缺失;
-
提供多尺度上下文,使网络同时感知局部与全局;
-
在反向传播中提供“捷径”,改善梯度流动,缓解深层网络难以训练的问题。
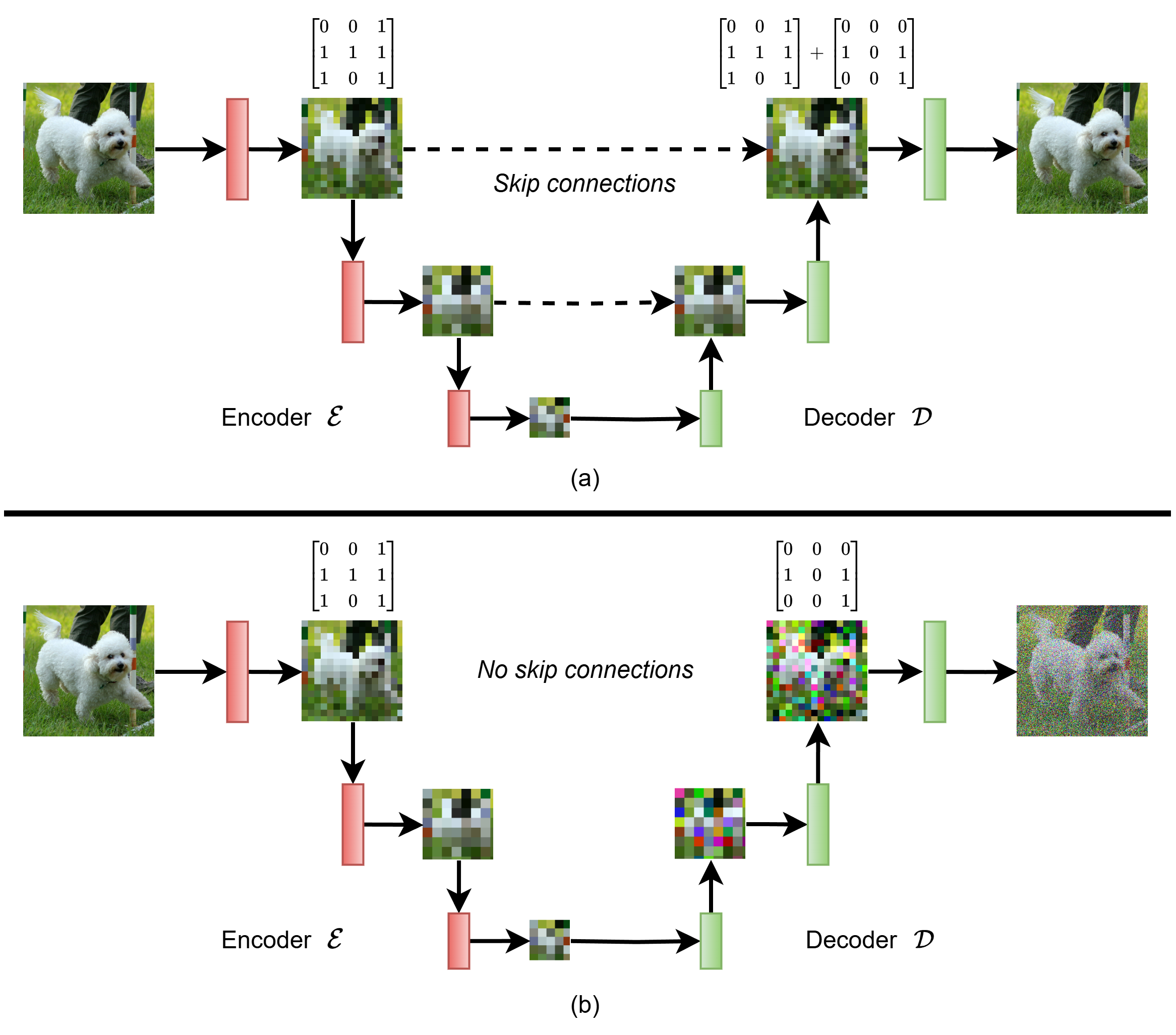
图3 跳跃连接对细节恢复的影响示意
3.5 标准 U-Net 前向过程梳理
可以将 U-Net 的前向过程抽象为一个伪代码算法:

图4 标准 U-Net 前向计算流程示意
在概念上,它包含三段:
-
向下:多层卷积 + 池化,保存每层特征;
-
瓶颈:若干卷积块进行深层语义抽象;
-
向上:上采样 + 与对应编码层拼接 + 卷积细化,最终输出特定任务的结果。
这种结构在分割中输出的是类别概率图,在扩散模型中输出的是“噪声预测”或“残差”,在某些自回归变体中则输出下一 token 的条件分布。
4 U-Net 的架构增强
随着任务从单一的医学分割拓展到多模态生成,原始 U-Net 结构在稳定性、表达能力和跨模态对齐方面暴露出一些不足,促使研究者不断引入归一化变体、注意力机制和残差块,从而形成一整套“现代 U-Net 家族”。
4.1 归一化层的演化
早期 U-Net 大多采用 BatchNorm,这是卷积网络的标准配置。然而在很多生成式任务中,特别是:
-
batch 很小(医疗、3D、视频);
-
使用扩散模型、先验模型时需要精确控制统计;
BatchNorm 对 batch 统计量的依赖开始成为瓶颈。于是出现了更适合小 batch、可变 batch、跨模态的归一化形式:
-
LayerNorm:对单个样本的所有特征维度做归一化,与 batch 大小无关,在扩散、Transformer 融合的 U-Net 中非常常见,如 Stable Diffusion、Imagen 等文生图模型的 U-Net 均采用 LayerNorm。
-
InstanceNorm:对每个样本的每个通道独立归一化,常用于风格迁移、音频/语音任务中;
-
GroupNorm:把通道划分为若干组,在组内归一化,兼顾 BatchNorm 的效果和小 batch 的鲁棒性。
在生成任务中,不同模态、不同范式的 U-Net 会根据任务特性选用不同归一化组合,这一点在后文总结的模态–模型表格中可以看到。
表1 生成式 AI 与 U-Net 相关综述工作概览
| 标题 | 主要关注点 | 简要说明 |
|---|---|---|
| 生成式 AI 应用综述 | 应用层面 | 从跨领域应用角度统计数百种生成式 AI 用法,强调应用场景与趋势 |
| 面向元宇宙的生成式 AI | 元宇宙 | 讨论生成式 AI 如何支撑虚拟世界构建与交互,给出未来研究路线 |
| AIGC 发展历程综述 | 模型与内容 | 从 GAN 到 ChatGPT 的内容生成技术演进,覆盖单模态与多模态 |
| 视频领域的生成式 AI 与 LLM | 视频 | 关注视频生成、理解与流媒体传输中的生成式技术 |
| 视觉生成模型综述 | 视觉扩散 | 对视觉扩散模型在图像、文本、音频等任务中的方法与评测做系统梳理 |
| U-Net 在显微/医学图像中的应用 | U-Net 传统任务 | 聚焦 U-Net 在显微图像与多模态医学分割中的演化 |
| U-Net 在音频增强中的应用 | U-Net 音频 | 总结基于谱图的 U-Net 在语音/音乐/环境音等增强任务中的应用 |
| U-Net 在生成式 AI 中的角色 | 架构视角 | 以 U-Net 为主角,从多模态、多范式角度分析其在现代生成模型中的骨干作用 |
该表格的意义在于:绝大多数已有综述要么围绕“生成模型类型”(扩散、LLM),要么围绕“应用领域”(视频、医学、音频),而架构层面专门从 U-Net 出发的系统性整理相对较少,这也说明从“骨干网络”视角审视生成式 AI 的价值。
4.2 注意力机制与 Transformer 融合
卷积在局部模式建模上很强,但难以高效覆盖长程依赖。将注意力机制嵌入 U-Net 可以让网络在保持多尺度卷积结构的同时拥有全局建模能力。
-
自注意力(Self-Attention):在图像、语音、文本单模态任务中,常被放入 U-Net 的中高层卷积块中,用于整合全局上下文,如 U-Net Transformer、Attention Wave-U-Net、Attention ResCUNet-GAN 等。
-
交叉注意力(Cross-Attention):在条件生成任务中尤为关键,例如文本–图像、文本–音频等。Stable Diffusion、Imagen、AudioLDM 等模型都使用跨注意力,让 U-Net 在去噪时能够“有条件地”选择与文本描述匹配的特征。
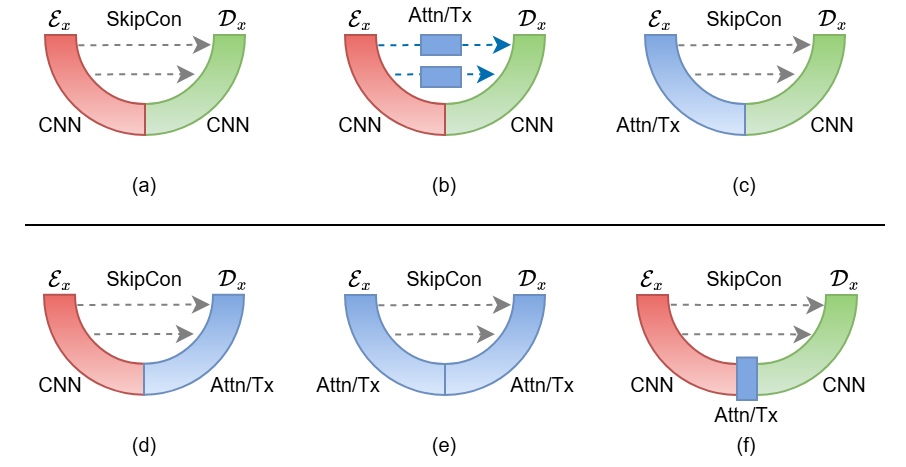
图5 将 Transformer 模块嵌入 U-Net 的多种方式
图中展示了若干典型结构:仅在 skip 连接处加入注意力;在编码器或解码器内部使用 Transformer;在瓶颈层插入完整的 Transformer 模块;乃至编码解码两侧全部替换为 Transformer,从而形成完全 Transformer 化的 U 形结构。
一个重要分支是 U-Net Encapsulated Transformer(UET):先用一维卷积式 U-Net 在 token 序列上做“降维编码”,在压缩后的表示上运行较小的 Transformer,然后再通过对称的 U-Net 解码恢复序列长度。这样既保留了 Transformer 的全局建模能力,又显著降低了维度与计算量,非常适合在资源有限的场景下扩展语言模型深度。
4.3 残差块与 ResUNet
Residual connection 是现代 U-Net 变体的“标配”。在很多模型中,卷积块不再是简单的“Conv–Norm–ReLU–Conv–Norm–ReLU”,而是用 ResBlock 替代:
$$F_{\text{out}} = F_{\text{in}} + \mathcal{F}(F_{\text{in}})$$
其中 F是若干卷积 + 归一化 + 非线性组成的残差分支。这种设计使网络更容易学习“对当前特征的微调”,而不是重新从零拟合整个映射。ResUNet、MultiResUNet、3D dResU-Net、扩散模型中的 U-Net 均大量采用这种残差设计。
在生成任务中,残差块与扩散过程天然契合:扩散模型要求在每一步预测“噪声”或“残差”,残差块正好在结构上表达“输入 + 校正”的思想,有助于稳定训练和提升细节质量。
表2 不同模态下 U-Net 变体的架构特性
| 模态 | 模型/类型 | 归一化 | 注意力 | 残差连接 |
|---|---|---|---|---|
| 图像 | ResUNet(标准) | BatchNorm | 无 | 有 |
| 图像 | MultiResUNet(标准) | BatchNorm | 无 | 有 |
| 图像 | PixelCNN++(自回归) | — | 无 | 有 |
| 图像 | Pix2Pix / PatchGAN(GAN) | BatchNorm | 无 | 无 |
| 图像 | Stable Diffusion(扩散) | LayerNorm | 交叉注意力 | 有 |
| 图像 | ControlNet(扩散) | LayerNorm | 交叉注意力 | 有 |
| 文本 | U-Net Transformer(自回归) | LayerNorm | 自注意力 | 无 |
| 文本 | UET(自回归) | LayerNorm | 自注意力 | 无 |
| 音频 | Deep-U-Net(标准) | BatchNorm | 无 | 无 |
| 音频 | Attention Wave-U-Net(标准) | — | 自注意力 | 无 |
| 音频 | AudioLDM(扩散) | LayerNorm | 交叉注意力 | 有 |
| 视频 | MagicVideo(扩散) | LayerNorm | 时序/交叉注意力 | 有 |
| 视频 | Lumiere(扩散) | — | 自注意力 | 有 |
| 三维 | 3D U-Net(标准) | BatchNorm | 无 | 无 |
| 三维 | DreamFusion(扩散) | LayerNorm | 交叉注意力 | 有 |
| 姿态/动作 | Variational U-Net(标准) | — | 无 | 有 |
| 姿态/动作 | Attn ResCUNet-GAN(GAN) | BatchNorm | 自注意力 | 有 |
| 姿态/动作 | DreamPose(扩散) | LayerNorm | 交叉注意力 | 有 |
该表格清楚地展现了一个趋势:越往现代、越往多模态靠近,U-Net 内部越倾向于使用 LayerNorm + 注意力 + 残差块,这可以视为“扩散时代的标准 U-Net 套餐”。
5 U-Net 与三大生成范式的结合
5.1 扩散模型中的去噪骨干
扩散模型的基本思想是:
-
正向过程逐步向数据中注入噪声,使其最终接近各向同性高斯分布;
-
反向过程学习一个“去噪网络”,从纯噪声逐步恢复出真实样本。
在绝大部分扩散模型中,这个“去噪网络”就是一个带注意力、带残差、带归一化的 U-Net。以 Stable Diffusion 为例,输入并非原始图像,而是由 VAE 编码得到的潜空间特征;U-Net 在潜空间上做多步去噪,最后再通过 VAE 解码回像素空间,从而大幅节省计算。Imagen、DreamBooth、ControlNet、SmartBrush 等模型都遵循类似范式,只是在条件信息(文本、边缘、深度、姿态等)的接入方式、注意力设计和训练目标上各有差异。
在视频扩散中,U-Net 被扩展为 3D 卷积或“2D + 时间维注意力”的形式,用来同时处理空间与时间。MagicVideo、Lumiere、Latent-Shift、Upscale-A-Video 等模型都在 U 形结构上加入了时间维卷积/注意力或无参数的 temporal shift 模块,以确保生成序列在时间上的连贯性与稳定性。三维生成(如 DreamFusion、Efficient-3DiM、Video3D)则利用 U-Net 对 2D 渲染视图或中间体表示进行去噪,再结合体渲染或 NeRF 进行 3D 形状重建。
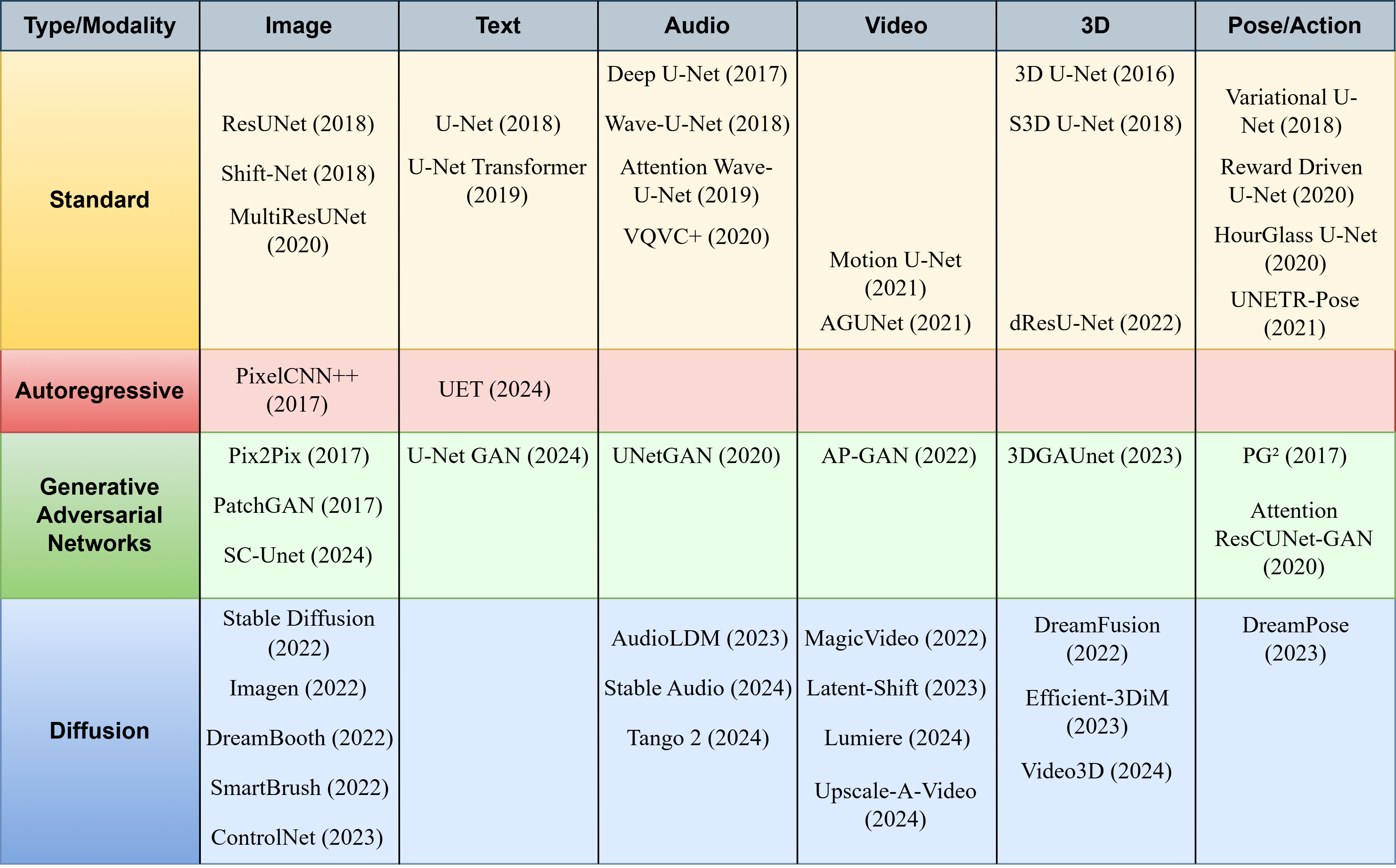
图6 扩散模型中 U-Net 去噪器的迭代过程示意
5.2 GAN 框架中的生成器与判别器
在条件 GAN 中,U-Net 主要扮演两类角色:
-
生成器(Generator):典型如 Pix2Pix 中的图像到图像翻译,输入是源域图像,输出是目标域图像,U 形结构兼顾全局语义与局部纹理;
-
判别器(Discriminator):PatchGAN 等结构会采用 U-Net-like 的多尺度感受野,使判别器能对局部 patch 的真伪给出细粒度判断,提供更加丰富的对抗梯度。
有的工作甚至在生成器与判别器两个角色上都使用 U-Net。例如对图像修补的 SC-Unet + WGAN 方案:生成器使用对称连接的 U-Net,内部融合膨胀卷积与多头自注意力,判别器在像素/区域级别对修补区域做细粒度判别,为生成器提供更加“局部敏感”的损失信号,从而在 CelebA-HQ、ImageNet 等数据集上获得更好的 PSNR/SSIM 指标。
5.3 自回归模型与 UET
传统自回归模型(RNN、Transformer、PixelCNN)强调“逐步生成”:文本按 token,图像按像素或 patch,一个一个往后推,这与 U-Net 的“并行整图变换”形成天然对比。因此,U-Net 直接用于自回归生成并不常见。但通过结构融合,可以得到兼具两者优点的混合架构。
PixelCNN++ 在结构上引入了下采样与 shortcut,有点类似“纵向展开的 U 形网络”,通过多尺度特征提升生成质量与效率。更具有代表性的是 U-Net Encapsulated Transformer(UET):
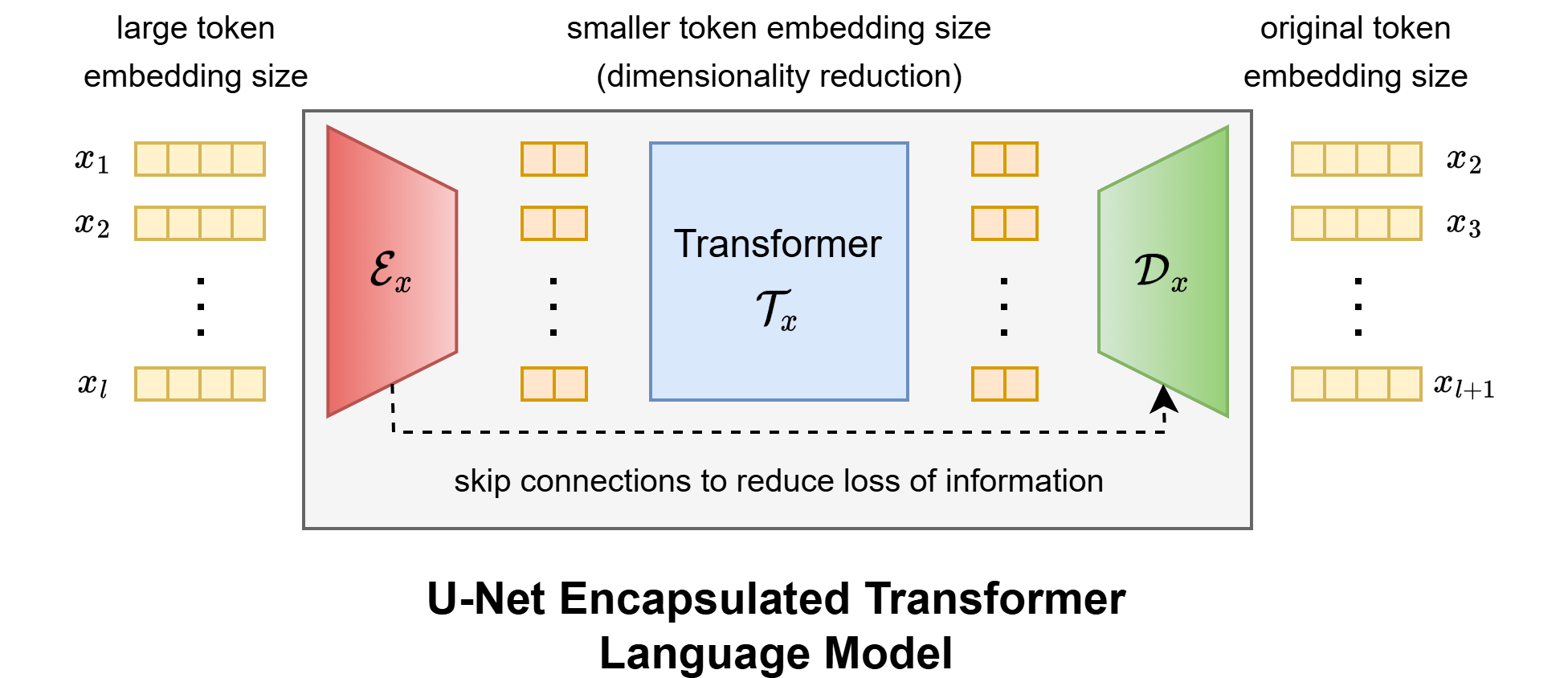
图7 UET 语言建模结构示意(此处可粘贴原文 Fig.5)
UET 先用一维卷积分支在序列上做“编码”,把高维 token 嵌入压缩到较低维特征,再在压缩空间上运行轻量级 Transformer 学习全局上下文,最后用对称的一维 U-Net 解码回原维度,实现“U-Net 负责降维与局部建模,Transformer 负责长程依赖与语义”的分工。实验证明,在相近资源约束下,UET 能在分类、推荐与语言建模中取得与更大 Transformer 接近甚至更优的表现。
6 基于模态的 U-Net 生成应用
这一节从“模态”而非“算法”出发,讨论 U-Net 在图像、文本、音频、视频、三维、姿态/动作等任务中的典型用法与理论特点。
6.1 图像生成与编辑
图像是 U-Net 最早的舞台,也依旧是其应用最为成熟的模态。按照生成任务可以大致分为:
-
图像生成与文生图:Stable Diffusion、Imagen、DreamBooth、ControlNet 等,将 U-Net 作为潜空间去噪器,通过多步扩散反演,从噪声中重构出高保真图像。
-
图像到图像翻译与修补:Pix2Pix、Shift-Net、SC-Unet 等,把源图当成条件输入,用 U 形结构实现高质量转换与修复。
-
高分辨率重建与超分:多尺度 U-Net、ResUNet 等结构用于恢复清晰纹理和边界。
表3 视觉模态下典型 U-Net 生成模型的定量比较
| 模态 | 模型 | 类型 | 参数规模 | 典型数据集 | 指标示例 |
|---|---|---|---|---|---|
| 图像 | ResUNet | 标准 U-Net | ≈7.8M | Massachusetts roads | 用于道路分割,强调结构细节 |
| 图像 | MultiResUNet | 标准 U-Net | ≈18.6M | 多种医学数据 | 在小样本分割中表现优异 |
| 图像 | SC-Unet | GAN | ≈2.1e8 | ImageNet, CelebA-HQ | FID 可达 1.x–8.x |
| 图像 | Stable Diffusion | 扩散 | ≈4e8 | ImageNet, LAION 等 | FID ≈3–5,高分辨率文生图 |
| 图像 | Imagen | 扩散 | ≈6e8 | MS-COCO | MS-COCO FID ≈7.x |
| 图像 | ControlNet | 扩散 | — | ADE20K 等 | 在边缘/深度/姿态控制下生成稳定 |
可以看到,随着从“标准 U-Net”向“GAN U-Net”再到“扩散 U-Net”的演进,参数规模从几千万级增加到数亿级,但结构骨干仍然是多尺度卷积 + 跳跃连接,只是不断加入注意力、条件分支和更复杂的归一化策略。
图像编辑方面,U-Net 通过 mask、条件编码等方式实现局部修补(inpainting)、外延生成(outpainting)和风格迁移。Shift-Net 通过在特征空间做“特征平移”,把已知区域的 encoder 特征作用到未知区域,结合 U 形解码实现视觉上连贯的补齐;SmartBrush 则在文生图扩散骨干上叠加目标掩膜预测与多任务训练,使得局部编辑更加可控。
6.2 文本与语言建模
在文本模态中,U-Net 不再处理像素,而是处理 token 嵌入序列。几个典型方向包括:
-
机器阅读理解:针对可回答/不可回答问题,将问题与篇章拼接后送入 U 形结构,通过“答案指针 + 无答案指针 + 验证器”的设计实现端到端预测;
-
对话生成:U-Net Transformer 在标准 Transformer 的基础上引入类似 U 形的层次跳跃连接,使得模型在不同层级的语义表示之间可以做更丰富的信息交互,从而提高对话多样性与流畅性;
-
语言建模与降维:UET 通过一维卷积式 U-Net 对 token 序列降维,再让较小的 Transformer 建模上下文,最后用解码 U-Net 还原,达到用更少资源构建较深语义模型的目的。
在评测上,这类模型通常使用 Perplexity、BLEU、ROUGE 等指标。U-Net 引入的主要价值在于:以较低的计算成本提供层次结构与多尺度上下文,在某些场景下可以替代部分大型 Transformer 层,从而达到“以 U 形结构换算力”的效果。
6.3 音频与语音生成
音频是另一个非常适合 U 形结构的模态,因为语音/音乐本身就是时间序列上的局部–长程混合结构。
在时域增强方面,Wave-U-Net 直接在波形上做一维 U 形卷积,下采样阶段用长跨度覆盖大时间上下文,上采样阶段恢复局部波形细节,实现端到端噪声抑制与语音分离。Attention Wave-U-Net 则在跳跃连接中增加自注意力,使网络在还原过程中能够更有选择地关注语音主成分。Deep-U-Net 等结构则多在频谱域(如 STFT、mel-spectrogram)上工作。
在生成方面,AudioLDM、Stable Audio、Tango 2 等文生音频扩散模型采用与 Stable Diffusion 类似的潜空间 U-Net 结构:文本通过 CLAP 或其他语音–文本对比编码器映射到条件嵌入,U-Net 在潜空间上对音频进行多轮去噪,再解码为 44.1kHz 立体声波形。Tango 2 进一步利用“偏好对比(DPO)”进行微调,使生成音频在主观感受上更符合人类偏好。
表4 U-Net 语音增强与文生音频模型性能概览
| 任务 | 模型 | 参数规模 | 数据集 | 指标示例 |
|---|---|---|---|---|
| 语音增强 | Wave-U-Net | — | VCTK, SEGAN | PESQ≈2.4,SSNR≈10dB |
| 语音增强 | Attention Wave-U-Net | — | VCTK | PESQ≈2.6,COVL≈3.3 |
| 文生音频 | AudioLDM | ≈7.4e8 | 多源音频 | KL≈1.7,CLAP≈0.43 |
| 文生音频 | Stable Audio | ≈1e9 | AudioSparx | KL≈0.8,CLAP≈0.46 |
| 文生音频 | Tango 2 | ≈8.7e8 | Audio-alpaca | KL≈1.1,CLAP≈0.57 |
可以看到,增强类 U-Net 规模较小,偏重细节恢复;生成类 U-Net 则规模巨大,偏重多模态条件与长时间结构建模。
6.4 视频生成
视频生成相当于在图像生成基础上再加一个时间维。U-Net 在这里通常有两种扩展方式:
-
使用 3D 卷积,将时间视作第三个空间维度一次性处理;
-
使用 2D + 时间注意力/shift 模块,在空间维做卷积,在时间维通过注意力或无参数 shift 建模。
Motion U-Net、AGUNet 等侧重视频分割与目标跟踪;AP-GAN 将 U-Net 作为生成器,在视频换脸、属性编辑中保持身份一致与表情/姿势变化。扩散方向上,MagicVideo 利用 VAE 将视频编码到紧凑潜空间,在那里运行 3D U-Net 扩散;Lumiere 提出 Space-Time U-Net,一次性生成完整视频序列而非先生成关键帧再做时间超分,从而提升全局时间一致性;Latent-Shift 则通过参数为零的 temporal shift 模块在时间维上实现特征交换,使原本为图像设计的 U-Net 能以较小代价扩展到视频。
6.5 三维体数据与 3D 生成
在三维场景下,U-Net 需要处理体素网格或多视角图像/视频渲染。3D U-Net 通过 3D 卷积与 3D 池化实现对体数据的分割与生成,是医学影像任务的主力架构之一。dResU-Net 通过更深的残差路径增强表示能力,S3D-UNet 通过可分离 3D 卷积降低计算量。
在生成式任务中,DreamFusion 等方法利用预训练的 2D 文生图扩散模型作为“先验”,通过反向传播优化 NeRF,使其渲染的 2D 视图在扩散模型看来是“高分辨率、符合文本语义”的图像。这一过程中,U-Net 仍然是扩散模型内部的核心骨干。Efficient-3DiM 通过改进时间步采样与特征提取策略,将训练时间从十天级缩短到一日以内,Video3D 则利用视频扩散 + 体渲染生成一致的多视角 3D 场景。
6.6 姿态与动作生成
在人体姿态和动作生成方面,U-Net 的优势在于对空间结构一致性的维护。PG 等姿态引导人像生成模型采用两阶段 U 形网络:第一阶段生成粗糙、姿态正确的图像,第二阶段通过残差 U-Net + GAN 微调纹理与细节。Variational U-Net 把“形状”与“外观”拆开建模,用变分编码器处理外观,用条件 U-Net 控制形状,实现换装、姿态修改等任务。
UNETR-Pose 将 Transformer 编码器与 U-Net 解码器结合,用于多视角 3D 姿态估计;Attention ResCUNet-GAN 利用双 U-Net 结构补全 UV 空间的人脸纹理,实现大姿态下的鲁棒人脸识别。DreamPose 则在 Stable Diffusion 基础上增加姿态与图像条件,将静态时尚图片“动画化”为随时间变化的走秀视频。
此外,轻量级 U-Net 还被用于无人机导航中,生成语义分割图以指导强化学习策略,实现仅依赖单目 RGB 的避障飞行。可以看出,只要任务需要“结构一致 + 局部细节”两者兼顾,U-Net 总能找到发挥空间。
7 U-Net 在生成式 AI 中的优势与局限
7.1 核心优势
从理论和实践两方面看,U-Net 在生成式 AI 中的优势可以概括为三点:
第一,多尺度层次特征提取能力强。编码–解码结构天然适合从局部到全局构建金字塔表示,无论是边界敏感的分割,还是纹理丰富的生成,都能在不同尺度上找到对应的表示层。
第二,细节保留能力突出。跳跃连接让低层特征绕过瓶颈直接参与重建,避免了单纯压缩–解压导致的细节损失,对扩散模型中多轮去噪尤为关键。图像、视频、音频中大量实验表明,相同参数量下,带 skip 的结构在 SSIM、PSNR、感知指标上往往更优。
第三,计算高效且易于并行。卷积 U-Net 在空间/时间维度上的计算复杂度基本随输入大小线性扩展,不像自注意力那样是二次复杂度;同时可以对整张图/整段序列并行处理,相比逐像素/逐 token 的自回归生成速度更快。这也是为什么扩散模型大多选择 U-Net 而非纯 Transformer 作为去噪器。
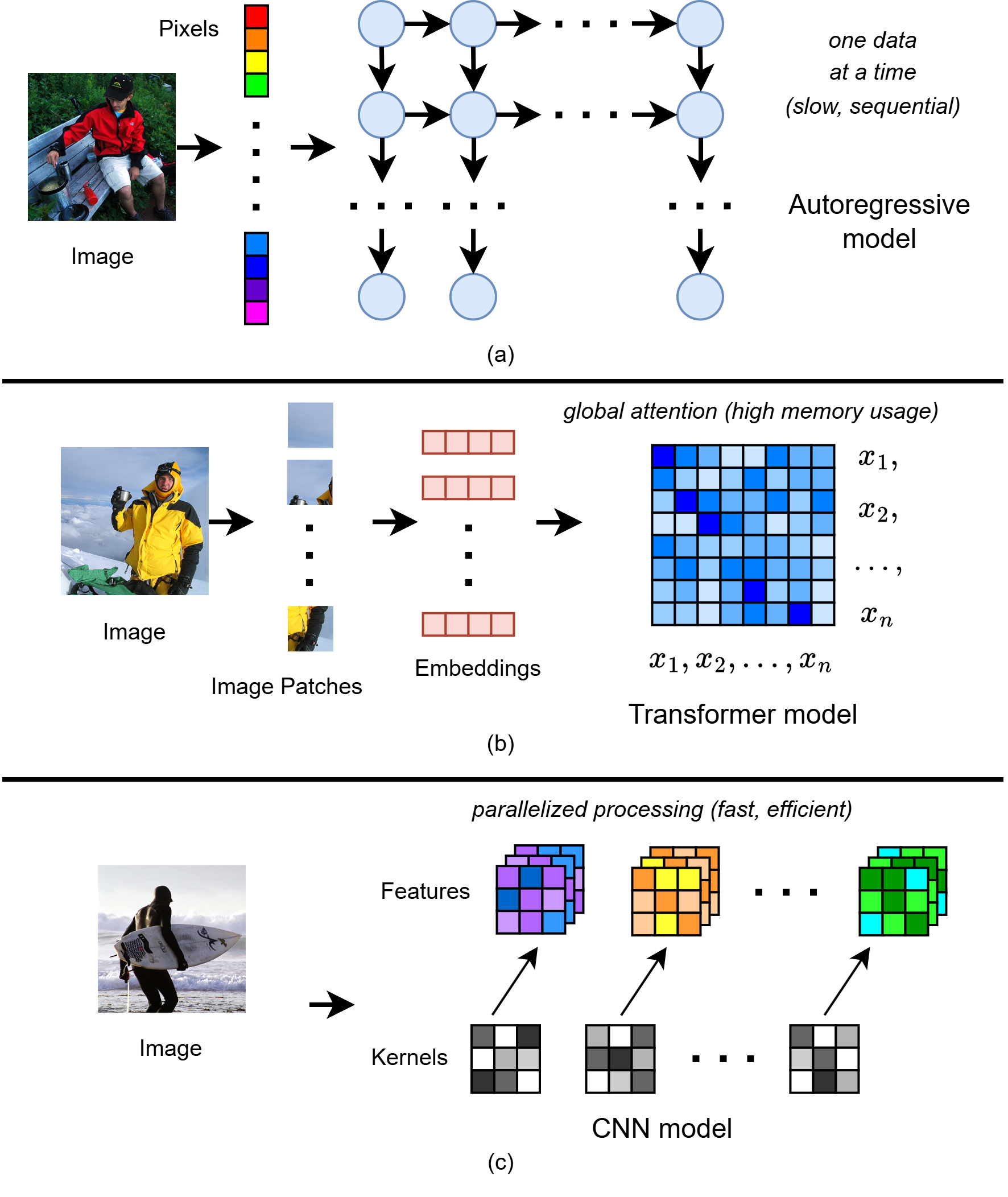
图9 自回归、Transformer、U-Net 三种生成方式在复杂度与并行性上的对比
7.2 主要局限
当然,U-Net 也并非“万能骨干”,其局限同样明显:
-
长程依赖建模能力有限。卷积感受野再大,本质上依旧是局部核叠加,要全面覆盖整张图像或长文本,往往需要很深的层数,而注意力可以一次性全局建模;
-
在超高分辨率任务中扩展性受限。分辨率成倍增加时,卷积计算量与显存需求同样成倍上升,而有效感受野相对变小,导致网络需要更深或更宽才能捕捉到全局结构;
-
在跨模态、语义抽象任务中需要额外模块配合。单纯卷积很难理解复杂语言、符号或高层语义关系,必须结合 Transformer、对比学习、交叉注意力等机制;
-
对序列与符号推理任务(例如纯文本长序列建模、强化学习策略生成)并非天然适配,往往需要以 UET 等混合结构的形式与自回归框架结合。

图10 随着输入分辨率增大,U-Net 在感受野、显存与计算上的三方权衡示意
在安全敏感领域,如医疗影像、自动驾驶,U-Net 与其他深度模型一样缺乏“可解释性”,只能借助可视化、热力图、影响力追踪等 XAI 技术去事后分析其行为,这也是未来必须重视的方向。
8 结语
从最初面向医学图像分割的卷积 U 形网络,到今天支撑 Stable Diffusion、AudioLDM、MagicVideo、DreamFusion、DreamPose 等多模态生成系统的核心骨干,U-Net 已经从一个“应用模型”转变为一个通用生成基础架构。编码–解码结构、跳跃连接、归一化、注意力与残差块的有机组合,使它既能在图像/视频/音频等连续模态中提供细节友好的多尺度表示,又能在与 Transformer、扩散、GAN、自回归等范式的融合中保持良好的计算效率与训练稳定性。
从架构视角来看,可以将当代大量生成式系统理解为:在不同模态、不同范式上,对“U 形结构 + 条件编码 + 注意力/残差”的不断重塑与扩展。Transformer 确实在长程依赖、序列建模方面占据主导,但在需要像素级/体素级、时间连续且细节丰富的生成任务中,U-Net 仍然是难以替代的基础组件。
未来,针对高分辨率、多模态与实时场景的需求,轻量化 U-Net、卷积–注意力混合骨干、与状态空间模型(如 Mamba)结合的结构,都有可能成为新的研究重点;同时,与可解释性、安全性、鲁棒性相关的工作也会越来越重要。无论生成式 AI 如何继续演化,只要任务仍然需要兼顾全局结构与局部细节,一种“有记忆的多尺度 U 形网络”就仍然会存在,而当前最成熟、被广泛验证的实现形式,就是 U-Net 及其丰富的变体。


















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











