





目录
2.2 预训练范式 (Pre-training Paradigm) 的兴起:自然语言与视觉模型的突破
2.4 统一表征 (Unified Representation) 的提出与未来趋势
3.1 基于上下文的方法(Context‑based Methods)
3.4 基于聚类的方法(Clustering‑based Methods)
3.5 基于图的方法(Graph‑based Methods)
4.2 统一表征 (Unified Representation) 的提出与意义
路径一:跨模态对比 (Cross‑Modal Contrastive) / 对齐 (Alignment)
路径二:统一 / 模态-无关 (Modality‑Agnostic) 模型 + 多模态预训练 (Multimodal Pre-training)
1. 引言
1.1 研究背景与动机
随着深度学习技术的飞速发展,以监督学习为代表的模型在众多领域取得了突破性进展,例如图像识别、自然语言处理等。然而,监督学习的成功在很大程度上依赖于大规模、高质量的人工标注数据集。获取这些数据集不仅成本高昂、耗时费力,而且在某些专业领域(如医疗影像分析、金融风控)中,标注工作甚至需要领域专家的深度参与,这极大地限制了监督学习技术的广泛应用和进一步发展。为了突破这一瓶颈,研究者们开始探索如何有效利用海量的未标注数据,自监督学习(Self-Supervised Learning, SSL)应运而生,并迅速成为机器学习领域的研究热点。自监督学习的核心思想是设计巧妙的预训练任务(Pretext Tasks),从未标注数据中自动生成监督信号(即“伪标签”),从而学习数据的有效表征。这种方法不仅极大地降低了数据标注的成本,还使得模型能够学习到比监督学习更泛化、更丰富的特征表示,为下游任务(Downstream Tasks)提供了强大的基础。近年来,以BERT、GPT系列为代表的自监督预训练模型在自然语言处理领域取得了巨大成功,而SimCLR等对比学习方法则在计算机视觉领域展现出强大的潜力,这些里程碑式的工作标志着自监督学习正引领着人工智能进入一个新的发展阶段。
1.2 自监督学习的定义与核心思想
自监督学习是一种介于监督学习和无监督学习之间的学习范式。与监督学习依赖人工标注的标签不同,自监督学习通过设计预训练任务,从数据本身挖掘监督信息。其核心思想可以概括为:通过解决一个由数据自身生成的“代理任务”(Pretext Task),来驱动模型学习到对下游任务有用的“通用表征”(Representation)。例如,在图像领域,可以通过随机遮盖图像的一部分,然后训练模型去预测被遮盖的内容;在自然语言处理领域,可以随机遮盖句子中的某些单词,让模型去预测这些被遮盖的词。这些预训练任务本身可能并不直接对应最终的下游任务,但通过解决这些任务,模型被迫学习到数据内部的结构、语义和关联性,从而获得强大的特征提取能力。这种学习方式的优势在于,它几乎可以利用任何来源的原始数据,无需昂贵的人工标注,使得模型能够从海量数据中汲取知识,学习到更加鲁棒和泛化的特征。预训练完成后,学习到的模型(通常是其编码器部分)可以作为下游任务的初始化权重,通过少量标注数据进行微调(Fine-tuning),从而在多种任务上取得优异的性能。
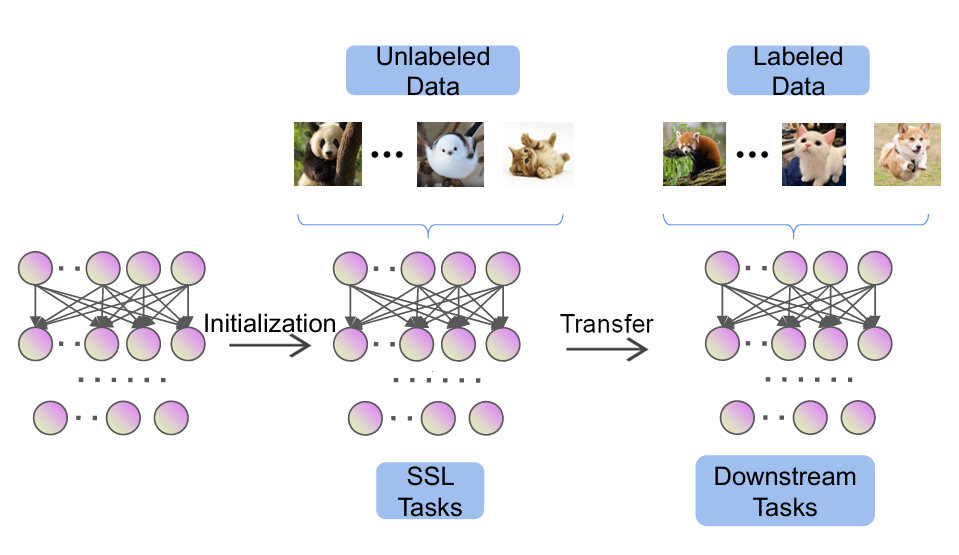
1.3 本文结构安排
本文旨在对自监督学习技术进行全面而深入的综述,系统性地梳理其发展历程、核心方法、模型架构、应用领域以及未来趋势。文章将从基础概念出发,逐步深入到前沿研究,力求为读者呈现一幅完整的自监督学习技术图景。
-
第二章将回顾自监督学习的发展历程,从早期的探索到预训练范式的兴起,重点介绍BERT、GPT、SimCLR等关键里程碑,并探讨统一表征的未来趋势。
-
第三章是本文的核心,将详细阐述自监督学习的主要技术方法。我们将按照基于上下文、生成式、对比式、基于聚类、基于图以及混合方法这六大类别,系统介绍各类方法的核心思想、代表性算法、模型架构及其实用考量。
-
第四章将聚焦于自监督学习的预训练范式与统一表征,探讨其演进路径、技术实现以及面临的挑战。
-
第五章将展示自监督学习在计算机视觉、自然语言处理等多个领域的具体应用,并结合实验数据对其性能进行分析与比较。
-
第六章将探讨自监督学习的未来发展趋势与当前面临的开放性问题,为未来的研究方向提供参考。
-
第七章对全文进行总结。
2. 自监督学习的发展历程与关键里程碑
自监督学习并非一个全新的概念,其思想根源可以追溯到早期的无监督学习和表示学习。然而,随着深度学习,特别是Transformer架构的兴起,自监督学习在近十年间取得了爆炸式的发展,并逐渐成为主流的研究范式。其发展历程大致可以划分为几个关键阶段,每个阶段都伴随着标志性技术的突破,推动了整个领域的进步。
2.1 早期探索:从传统无监督 / 表示学习到深度自监督
在深度学习兴起之前,自监督 (self‑supervised) 的理念其实已以多种方式隐含于传统的无监督表示学习 (representation learning) 中。典型代表是 Autoencoder (AE) 及其各种变种 (如去噪自编码器 Denoising Autoencoder, DAE/变分自编码器 VAE 等) —— 这些模型通过对输入数据进行编码 (encoding) 与解码 (decoding),并以重构 (reconstruction) 为目标,让网络学习一种低维隐空间 (latent space) 表示。AE 类模型不依赖人工标签 (label),而是从数据本身生成“监督信号 (supervisory signal)”,因此被视为自监督 / 表示学习 (representation learning) 的早期雏形。DAE 通过给输入加入噪声 (noise) 或遮挡 (masking) 部分维度,再训练模型恢复 (reconstruct) 原始数据,迫使编码器学习到鲁棒 (robust)、能捕捉输入数据结构与本质特征的隐表示,而不是简单复制输入。
然而,由于当时计算资源有限、神经网络普遍较浅 (shallow)、且硬件 / 优化技术对大规模训练并不成熟,这类基于重构 (reconstruction‑based) 的方法所能学习到的表示能力相对有限。其所得到的特征虽然能在某些简单任务 (如降维、聚类) 上产生一定价值,但在复杂的下游任务 (如高分辨率图像分类、语义理解或自然语言处理) 上难以带来突破。
随着深度学习 (deep learning) — 特别是深层卷积网络 (CNN)、循环神经网络 (RNN) 等结构的普及与发展,研究者开始尝试通过设计更复杂、更具语义 / 结构意义的“预训练 (pretext) 任务 (pretext tasks)”来推动无标签数据的有效利用。例如在 图像 / 视频 领域,通过让模型预测图像的旋转角度 (rotation)、还原被遮挡 / 被遮盖 (masked) 的区域 (inpainting)、重建图像色彩 (colorization)、或解决拼图 (jigsaw) 游戏、预测视频帧顺序 (frame order) 等任务,以期逼迫编码器 /特征提取网络 (feature extractor) 学习到比像素级重构更具语义性的表示 (semantic representation) —— 这些表示含有对物体、场景、运动等的语义/结构理解,而不仅仅是像素相关性。这样的实验奠定了后来自监督学习 (SSL) 更大规模发展与多样化预训练任务设计的基础。
总体而言,这一阶段 (传统 AE → 深度网络 + 重构 / 重建任务 → 基于结构 / 上下文 /任务设计的预训练) 展示了自监督 / 表示学习 (representation learning) 从浅层、局部、低语义表示,朝向深层、结构化、语义丰富表示方向演进的潜力。
2.2 预训练范式 (Pre-training Paradigm) 的兴起:自然语言与视觉模型的突破
近年来,自监督学习真正进入大众视野,关键在于“预训练 (pre‑training) + 下游迁移 (downstream fine‑tuning)”这一范式被广泛接受和证明有效。与传统监督学习依赖大量人工标注数据 (labeled data) 不同,SSL 的核心优势在于它可以利用海量未标注 (unlabeled) 数据,通过为模型设定恰当的预训练任务 (pretext tasks),使其学习到高质量、通用性强的表示 (representations)。这种 paradigm 的普及,使得表示学习从“专用任务 (task‑specific)”逐步走向“通用预训练 + 多任务迁移 (multi-task transfer)”的方向。正如近年多篇综述所强调的那样。arXiv+2MDPI+2
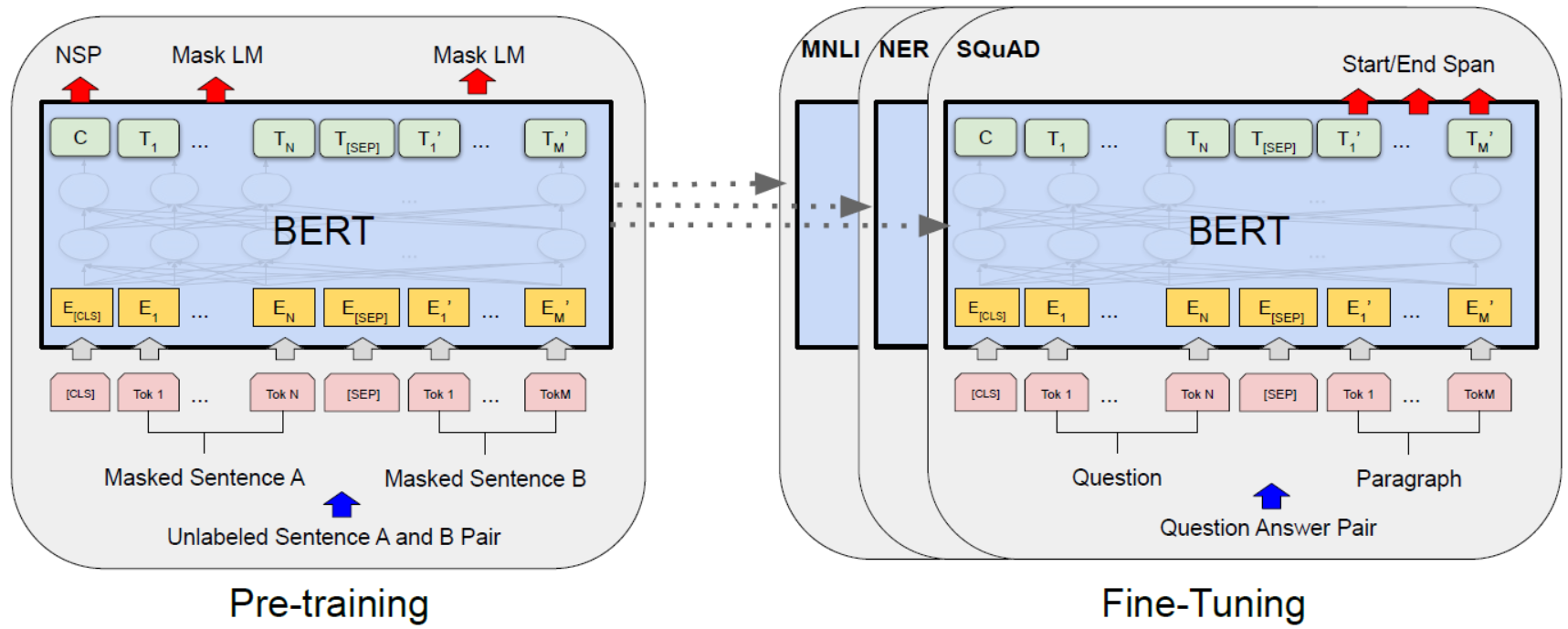
在自然语言处理 (NLP) 领域,这一变化尤为显著。以 BERT (Bidirectional Encoder Representations from Transformers) 为代表的预训练语言模型,通过“掩码语言模型 (Masked Language Modeling, MLM)”与“下一句预测 (Next Sentence Prediction, NSP)”两个任务 — 即在无标签文本数据中随机遮盖 (mask) 部分 token,然后让模型预测被遮盖的 token,同时让模型判断两句是否连贯 (next sentence) — 从而学习到深层、双向 (bidirectional)、上下文相关的语言表示 (contextual embeddings)。BERT 的成功不仅显著提升了下游 NLP 任务 (如文本分类、问答、自然语言推理等) 的性能,也证明了大规模自监督预训练 + Transformer 架构 + 通用表示 (universal representations) 的有效性。arXiv+2余志州的博客+2
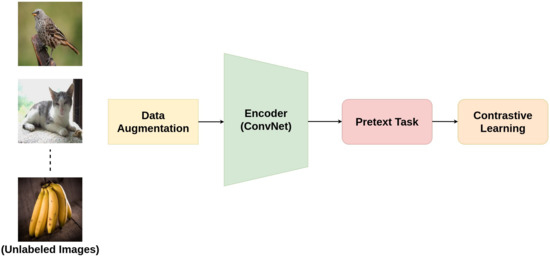
与此同时,在计算机视觉 (CV) 领域,虽然早期也有人基于生成式 (generative) / 重构 (reconstruction) 方法 (如 autoencoder、图像上色 (colorization)、补全 (inpainting) 等) 进行预训练,但这些方法在高分辨率图像表示、语义分类等任务上的效果往往不及后来的对比学习 (contrastive learning) 方法。随着对比学习 (contrastive learning) 的引入 — 它通过构造正样本 (positive pair) 与负样本 (negative samples),并设计对比损失 (contrastive loss),将同一输入 (经不同增强) 的表示拉近 (similar) ,同时将不同输入 (negative) 的表示推远 (dissimilar) — 视觉 SSL 开始取得突破性进展。多数综述认为,对比学习成为视觉 SSL 的主流方向。MDPI+2OpenReview+2
因此,自监督学习从生成 / 重构范式 (reconstruction / generative) → 预训练 + 表示学习 → 对比 / 预测 /掩码 + 迁移学习 (transfer learning) 的路线,标志着其从理论与实验探索,迈入实用化与产业化 (transfer to practice) 的关键转折。
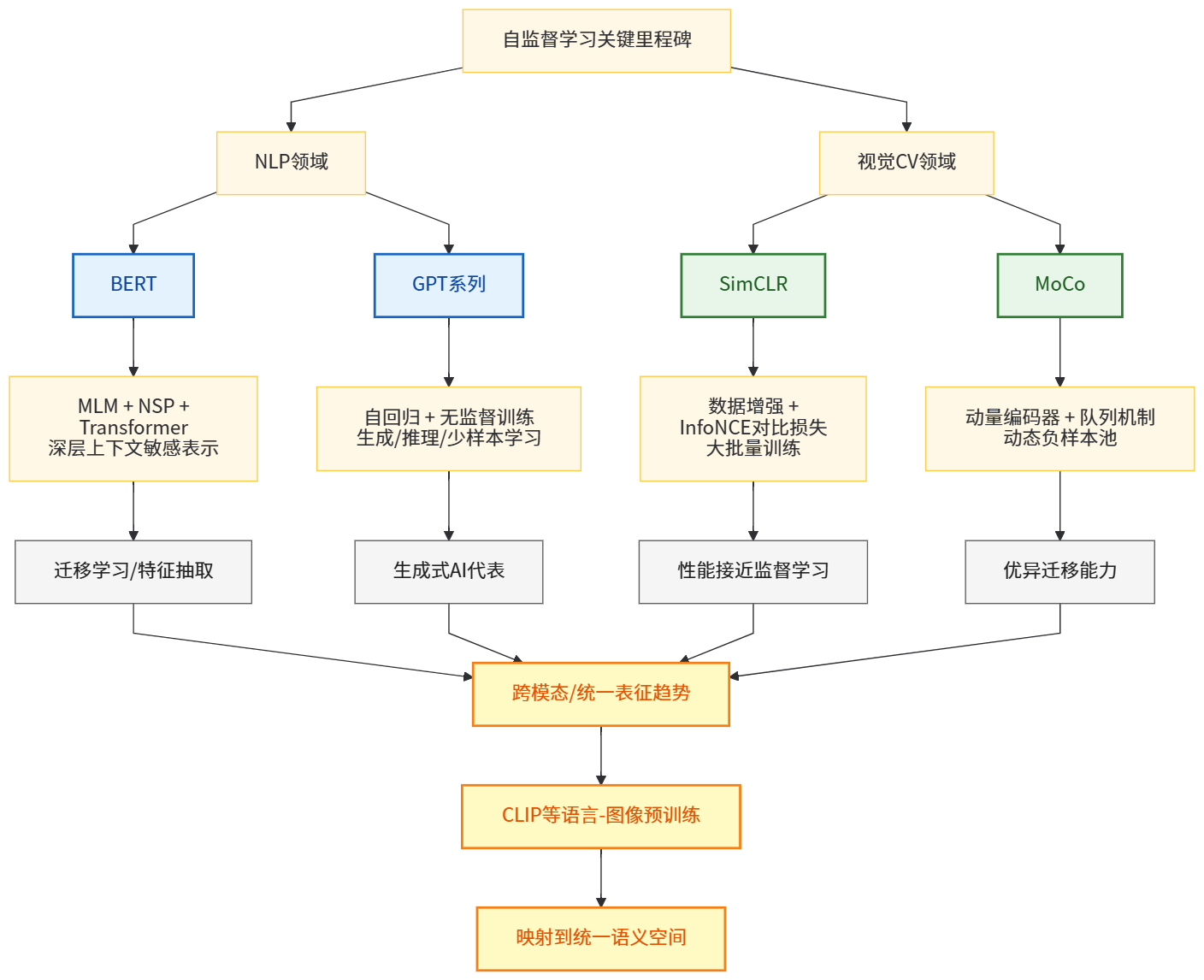
2.3 关键里程碑:NLP 与视觉领域的代表模型
在自监督 / 预训练 (pre‑training) 演化过程中,有若干模型 / 方法成为里程碑,它们分别在 NLP 与视觉 (CV) 领域设立了新的标准,并推动该领域快速发展。
在 NLP 领域,以 BERT 为代表的自监督预训练语言模型,通过 MLM + NSP + Transformer 架构,学习到通用、深层、上下文敏感 (contextual) 的语言表示。这种表示不仅可以被用作下游任务 (fine‑tune),也可以用于特征抽取 (feature extraction)、迁移学习 (transfer learning),极大地推动了 NLP 各类任务性能提升。
与此同时,生成式语言模型 (autoregressive language models) — 例如 GPT-3 / GPT 系列 等 — 则通过“自回归 (autoregressive) + 无监督 / 自监督训练 (使用海量文本)” 的方式,在生成 (generation)、推理 (reasoning)、少样本 / 零样本学习 (few-shot / zero-shot learning) 等方面展现惊人能力。这表明,自监督预训练不只是用于表示 (representation) —— 在生成、推理等复杂任务上也具有巨大潜力。许多评论把 GPT 系列 (以及后续更大规模模型) 视为生成式人工智能 (generative AI) 的代表,推动了生成式 AI 在工业界与学术界均取得重大影响。维基百科+2余志州的博客+2
在视觉 (CV) 领域,SimCLR (Simple Framework for Contrastive Learning of Visual Representations) 和 MoCo (Momentum Contrast) 等方法成为对比学习 (contrastive self-supervised learning) 的代表。SimCLR 提出一种非常简洁 (simple) 的对比学习框架:通过对同一张图像做两种不同的数据增强 (data augmentation),得到正样本 (positive pair),然后通过编码器 (encoder) + projection head + 对比损失 (contrastive loss, 如 InfoNCE) 将正样本的表示拉近,同时与其他图像 (negative samples) 推远。在大批量 (large batch size) + 长时间训练 (longer training) 下,SimCLR 在 ImageNet 等数据集上取得与监督训练 (supervised training) 接近 / 持平的分类性能。arXiv+1
MoCo 则通过引入动量编码器 (momentum encoder) + 队列机制 (queue / dictionary) 动态维护大规模负样本池 (negative sample bank),解决了 SimCLR 需要超大 batch size 的现实瓶颈,使对比学习在较小 batch size / 较常规训练条件下也能取得优异表现。MoCo 所学习到的表示在多个下游任务 (包括目标检测、语义分割等) 上表现出良好的迁移能力,有时甚至优于其监督预训练 (supervised pre-training) 对应版本。arXiv+1
更近几年,随着视觉预训练 (vision pretraining) 与语言 / 多模态 (multimodal) 预训练 (pre‑training) 思想的融合,学界和工业界开始探索跨模态 (cross‑modal) / 统一表征 (unified representation) —— 例如通过语言–图像对 (image–text pairs) 进行对比学习 (contrastive language–image pre‑training) 等方式,将不同模态 (modalities) 的数据映射到同一语义空间 (semantic space)。这预示着自监督 / 表示学习不再局限于单一模态 (单纯图像 / 文本),而是朝向更加通用、通模态 (universal & cross-modal) 的方向演进。许多近期综述与研究都强调这一趋势。OpenReview+2arXiv+2
因此,SimCLR 与 MoCo 等对比学习方法,以及 BERT / GPT 系列语言模型,构成了自监督 / 预训练 (SSL + pre‑training) 迭代过程中的关键里程碑,它们在各自领域推动了表征学习 (representation learning) 的质量与可迁移性 (transferability) 达到新的高度。
2.4 统一表征 (Unified Representation) 的提出与未来趋势
随着自监督学习在单模态 (unimodal) — 无论是文本 (NLP) 还是图像 (CV) — 上取得显著成果,研究者越来越关注如何扩展这种能力,使模型能够处理并统一多种模态 (multimodal, e.g. 文本、图像、视频、音频等) 的数据。也就是说:能否通过一个统一的预训练 / 表征机制 (representation mechanism),学习到跨模态 (cross‑modal) 的通用 / 共享语义空间 (semantic space),从而使模型能够理解和处理来自不同模态 (例如图像 + 文本) 的数据。
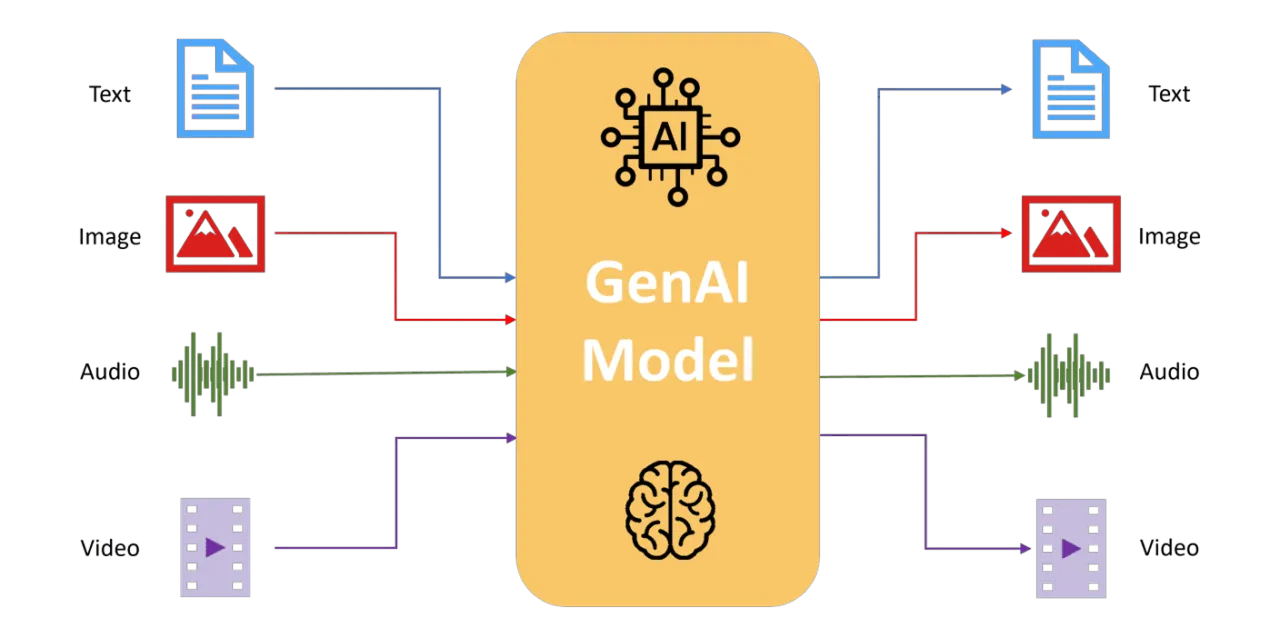
这一趋势催生了诸多跨模态预训练 (multimodal pre‑training) 和统一表征 (unified representation) 的尝试。以语言–图像对对比学习 (contrastive language–image pre-training) 为例,通过同时训练图像编码器 (image encoder) 与文本编码器 (text encoder),并最小化 / 最大化它们在同一语义空间 (semantic space) 中的距离 (或相似性),使得图像与其对应文本 (image–text pair) 的表示 (embedding) 靠近,而与不相关 (negative) 的样本远离。这样,当模型训练完成后,它便拥有跨模态 (cross‑modal) 的理解与检索能力:例如根据文本检索图像 (text → image),或根据图像生成 /检索文本 (image → text),或将两种模态联合用于下游任务 (如图文检索、视觉问答 multi-modal tasks) 。
更进一步,为了兼容更多模态 (例如音频、视频、3D 点云、图结构、时间序列等) 的数据,一些研究开始探索统一架构 (unified architecture)、统一 representational space,以及更加通用 (universal) 的预训练方法。这不仅对理论研究具有挑战性 (如何设计跨模态对齐 / 对比 /生成机制),也在实践中有广泛应用前景 (跨模态检索、跨模态生成、多模态理解、多任务迁移等)。近年来已有多篇综述与实际研究认为,多模态 / 统一表征 (multimodal / unified representation learning) 是自监督 / 表征学习 (SSL / representation learning) 未来的重要方向,也是向通用 /基础 (foundation) 模型迈进的关键路径。OpenReview+2 Towards AI+2
综上,自监督学习 (SSL) 从最初的重构 / 表示学习 (autoencoder),经过深度网络 + 预训练任务 (pretext tasks) 的探索,到对比学习 (contrastive learning)、遮掩 / 掩码建模 (masked modeling) 等范式的出现,再到今天朝向多模态 / 统一 /基础 (foundation) 表征 (unified & universal representation) 的发展,体现了该领域在理论、方法与应用上的不断演进 — 从“单一模态 + 专用任务”到“多模态 + 通用预训练 + 强迁移能力”的转变。
3. 自监督学习的主要技术方法与模型架构
自监督学习 (Self‑Supervised Learning, SSL) 的核心在于 —— 设计合理的预训练任务 (pretext tasks),以从未标注 (unlabeled) 的数据中提取有意义、可迁移 (transferable) 的表征 (representation)。按照这些预训练任务 (pretext) 的设计思路与实现机制,目前文献中常见的方法可大致分为 基于上下文 (Context-based)、生成式 (Generative)、对比 (Contrastive)、基于聚类 (Clustering-based)、基于图 (Graph-based),以及 混合 (Hybrid) 等几类。下文对前五类进行详细阐述:包括其核心思想 (intuition)、代表性算法与模型架构 (architecture)、适用范围与优缺点。
3.1 基于上下文的方法(Context‑based Methods)
3.1.1 核心思想与直观解释
基于上下文的方法 (context-based methods) 的基本假设是:数据的语义结构与内在规律隐藏在其上下文 (context)/邻域 (neighborhood) 信息中。通过“破坏 — 重建 (corrupt–reconstruct)”或“屏蔽 (mask) — 预测 (predict)”等预训练任务 (pretext tasks),模型被迫利用可见部分的信息去恢复 / 预测被破坏 /被遮挡 (masked) 的内容,从而学习到数据中对语义、结构、统计分布等关键特征的隐空间 (latent representation)。这种方式不依赖人工标签 (labels),更贴近人类通过上下文理解世界的方式,是 SSL 中最直观、最早被采用的策略之一。 arXiv+1

3.1.2 代表性算法与模型架构
-
语言领域 (NLP): 以 BERT (Bidirectional Encoder Representations from Transformers) 为典型。BERT 通过随机遮盖 (mask) 输入序列 (如遮盖 ~15% 的 token)、然后利用其双向 Transformer 编码器 (encoder) 基于上下文 (上下文中前后 token) 预测被遮盖 token (Masked Language Modeling, MLM);同时引入 “下一句预测 (Next Sentence Prediction, NSP)” 任务,让模型理解句子间关系 (sentence-to-sentence coherence),从而获得语义丰富、上下文敏感 (contextualized) 的语言表示。BERT 的成功证明了上下文预测任务能够让模型从大规模无标签文本中学到通用的深层语义结构。
-
视觉 (Vision) 领域: 随着 Vision Transformer (ViT) 等 Transformer 架构被引入图像分析,类似 NLP 中的 mask/predict 思想也被应用于图像。典型的是 Masked Autoencoder (MAE):MAE 随机遮盖图像的若干 patch (图像块),仅对未遮盖部分进行编码 (encoder),然后通过 decoder 对被遮盖部分重建 (reconstruction);这种不对称 encoder–decoder 架构极大提升了预训练效率,同时能够学习到高质量的视觉特征表示 (visual representation)。
-
图像修复 (Image Inpainting) 等任务:这是另一种 context-based 的视觉 SSL 任务,模型需要根据图像的可见区域,恢复被遮挡 / 缺失区域的像素 — 这要求模型理解图像的局部纹理、全局结构与语义内容。
3.1.3 实用考量与应用场景
基于上下文的方法因其任务简单、直观且通用性强,在 NLP、视觉 (图像/视频)、语音、时间序列等多个领域都有广泛应用。其成功的关键在于:合适的遮挡 / 掩码 (mask) 策略 (masking strategy)、对编码器/解码器架构 (encoder‑decoder) 的合理设计、以及选择恰当的重建 / 预测目标 (pixel / token / feature-level)。例如,在视觉任务中,可选择重建像素 (pixel‑level)、预测离散 token (如将 image‑patch 转为视觉 token) 或者重建高层 feature。不同的选择决定了模型所学表示的抽象程度和通用性。
总体而言,context-based 方法最适合那些数据本身具有丰富结构 / 上下文 / 连续性 (spatial/temporal) 的领域 (如语言、图像、视频、时间序列、语音)。这种方法帮助模型捕获局部与全局结构、上下文依赖与语义规律,为下游分类、检测、生成、恢复等任务奠定基础。
3.2 生成式方法(Generative Methods)
3.2.1 核心思想与直观解释
生成式方法 (generative methods) 是另一类重要的 SSL 技术路径。其目标不仅仅是恢复或预测被遮挡 / 被破坏的部分,而是尝试 生成 (generate) 与真实数据分布 (data distribution) 高度相似的新数据样本 —— 即模型学习一个潜在空间 (latent space),从中能够采样 (sample) 出新的数据。这要求模型理解数据的底层结构、统计分布和语义规律。通过生成任务 (generation tasks),模型被迫学习数据的全局结构和复杂特征。与 context-based 方法相比,生成式方法更强调对数据分布 (distribution) 的建模和隐空间 (latent space) 的结构化表达。
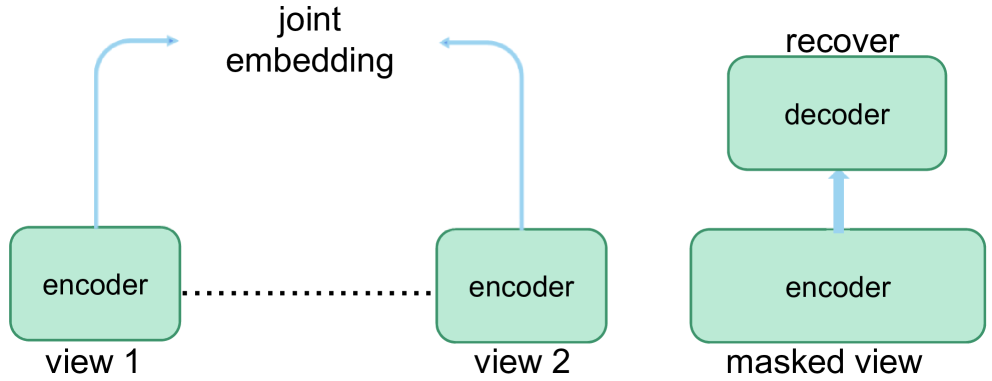
这种方式一方面能够得到具有良好结构性和语义性的表示 (representation),另一方面也可以直接用于生成、数据增强 (data augmentation)、图像 / 文本 /音频 /视频 的合成 (synthesis)、编辑 (editing) 和创作 (creation) 等任务,是生成式 AI (generative AI) 的重要组成部分。
3.2.2 代表性算法与模型架构
经典生成式模型包括:
-
Variational Autoencoder (VAE):由 encoder 与 decoder 构成,encoder 将输入映射到潜在空间 (latent distribution, 通常为高斯分布),decoder 从 latent 分布中采样 (sampling) 并尝试重建 (reconstruct) 输入。训练时优化重建损失 (reconstruction loss) 和 KL 散度 (KL divergence),使 latent 空间结构有意义。VAE 的潜在空间通常较为平滑 (smooth) 且结构良好,适合进行插值 (interpolation)、属性操作 (attribute manipulation) 和生成新样本。
-
Generative Adversarial Network (GAN):GAN 由 generator 与 discriminator 组成。generator 从随机噪声生成假样本 (fake sample),discriminator 尝试区分真假 (real vs fake),两者通过对抗训练 (adversarial training) 共同进化。GAN 在图像、视频、音频等领域生成高质量、高分辨率、语义一致性强的样本,广泛应用于图像生成、图像编辑、风格迁移 (style transfer)、数据增强 (data augmentation) 等任务。
-
扩散模型 (Diffusion Models):近年来成为生成式 AI 新兴主流。其基本思想是:定义一个“前向 (forward) 过程 (diffusion)”,将真实数据逐步加噪 (noise),最终变成纯噪声;然后训练一个“反向 (reverse) 过程 (denoising) 网络 (通常是 U-Net、Transformer、或其他架构),从噪声逐步恢复 / 生成新的数据样本。扩散模型在图像 (DALL‑E 2、Imagen 等)、文本到图像 (text-to-image)、图像编辑 (inpainting, super‑resolution) 等任务上表现出色。
3.2.3 实用考量与应用场景
生成式方法虽然功能强大,但也存在若干挑战:
-
训练不稳定性:以 GAN 为例,其训练往往面临模式崩溃 (mode collapse)、训练震荡 (instability)、生成样本多样性 / 质量不稳定等问题。
-
计算与资源开销大:要生成高分辨率、语义丰富的样本(尤其是图像/视频),通常需要较大的模型与计算资源 (GPU/TPU)、长时间训练。
-
评估困难:如何客观、系统地评价生成模型 (generated samples) 的质量与多样性仍然是一个开放性问题 (e.g., 图像生成的质量 /多样性 /真实性 /语义一致性等指标);此外,仅靠生成质量并不必然保证所学表示对下游任务有用。
尽管如此,生成式方法在以下场景具有独特优势:
-
数据增强 (Data Augmentation):在下游任务标注数据稀缺时,可以通过生成样本扩充数据集,提高模型泛化能力。
-
内容创作 / 编辑 /生成:如艺术创作、游戏 /影视中的场景 /角色生成、图像 /视频编辑 (如去噪、修复、风格迁移)、文本 /图像 /音频 /视频合成等。
-
潜在空间操作 (Latent Space Manipulation):借助平滑 /结构化的 latent 空间 (如 VAE latent),可对数据进行插值、属性编辑 (修改特定语义结构,如人脸属性、风格、颜色、姿态等)。
因此,生成式 SSL / 表示学习是通向生成式 AI、内容生成/编辑以及数据增强的一条重要路线。
3.3 对比方法(Contrastive Methods)
3.3.1 核心思想与直观解释
对比学习 (contrastive learning) 是近几年在自监督学习中 — 尤其是视觉 (computer vision, CV) — 得到广泛成功和关注的技术路线。其核心思想为 “将相似 (positive) 的样本表示拉近 (pull together),将不相似 (negative) 的样本表示推远 (push apart)” —— 即在 embedding / 表征空间 (embedding space) 中,通过构造正 / 负样本对 (positive / negative pairs),并优化对比损失 (contrastive loss),使模型区分不同实例 (instance discrimination)。
具体来说,对同一数据 (如一张图像) 通过不同数据增强 (data augmentation) 生成多个视图 (views),将这些视图作为正样本 (positive),而其他不同样本 (通过增强生成的) 作为负样本 (negative);编码后计算相似度 (similarity,比方说余弦相似度) 并用损失 (如 InfoNCE / NT-Xent) 强化正样本之间的相似性、削弱负样本之间的相似性。这样,编码器 (encoder) 被迫学习对数据增强 (augmentation) 不敏感 (invariant)、对语义 / 实例差异敏感 (discriminative) 的表征。 维基百科+2arXiv+2
对比学习通过“实例判别 (instance discrimination)”思想,鼓励模型关注数据中能够区分不同实例 /语义类别的关键特征,而忽略仅仅与像素 /原始输入 idiosyncrasy 有关的细节,从而获得更有意义、更通用、更具有判别力 (discriminative) 的表示 (representation)。
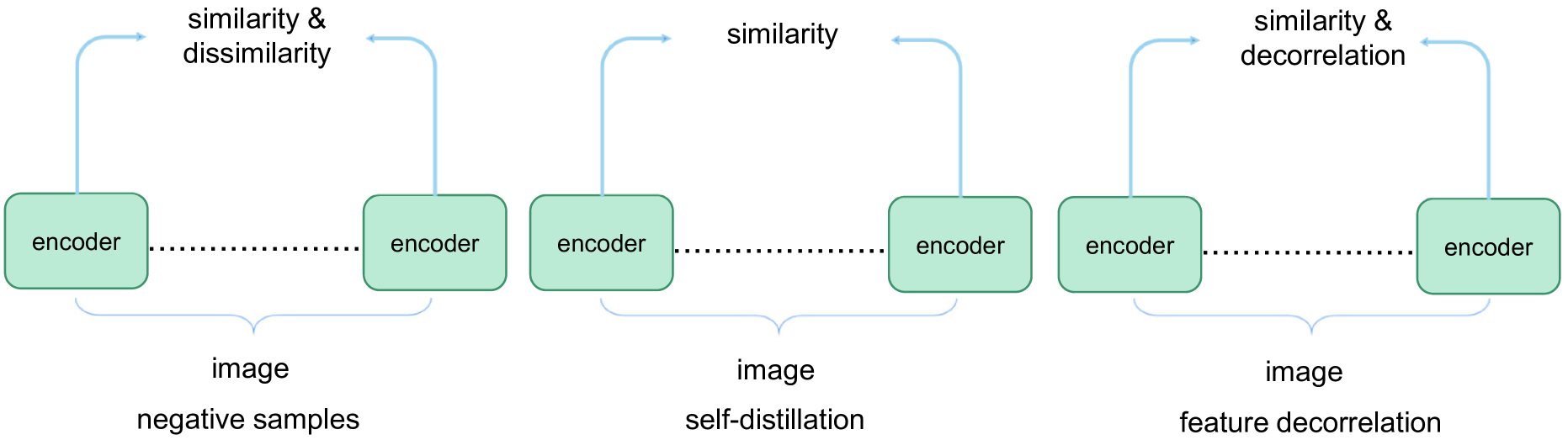
3.3.2 代表性算法与模型架构
-
SimCLR (Simple Framework for Contrastive Learning of Representations):这是一个简洁但非常有效的对比学习框架。SimCLR 的典型结构包括:(1) 数据增强模块 (data augmentation) — 为每张图像生成两个不同增强视图;(2) 编码器 (encoder),例如 ResNet;(3) 一个投影头 (projection head),将 encoder 的特征映射到用于对比学习 (contrastive) 的空间;(4) 使用 NT‑Xent / InfoNCE 对比损失 (contrastive loss) 优化模型。SimCLR 的成功关键在于大规模数据增强 + 足够大的批次 (batch size) + 长时间训练。 arXiv+1
-
MoCo (Momentum Contrast):MoCo 提出了解决 SimCLR 对超大 batch size 依赖的问题。其通过引入 “动量编码器 (momentum encoder)” + 一个 “队列 (queue / memory bank)” 来动态维护大规模的负样本池 (negative sample pool):每个 mini-batch 编码的新样本入队 (enqueue),最旧样本出队 (dequeue),形成一个不断更新的 negative sample 字典 (dictionary),从而在较小 batch size 下也能获得足够多样 / 足够数量的负样本用于 contrastive learning。MoCo 的设计使对比学习更加高效、可扩展。 Medium+1
-
非对比 / 无负样本对 (non-contrastive / negative‑free) 方法:近年来,研究者发现去掉负样本 (negative samples) 也可能获得有用表示。典型代表包括 BYOL (Bootstrap Your Own Latent) —— 它不使用任何负样本,而是通过在线 (online) 网络 + 目标 (target) 网络 + 预测头 (predictor) 构造一种“自预测 (self-prediction)”机制:对同一图像的两个增强视图,一视图通过在线网络编码并经过 predictor,另一视图通过目标网络编码 (target network 的参数为 online 网络参数的指数滑动平均);在线网络学习去预测目标网络对另一个视图的输出。尽管没有负样本,也没有 explicit collapse 防护 (如对比损失),BYOL 在图像表征学习 (如 ImageNet 预训练 + 下游任务) 中仍表现出与对比学习方法可比甚至更好的效果。 HMOO 读书笔记+1
此外还有方法如 SwAV (Swapping Assignments between Views) —— 它融合了聚类 (clustering) 与对比 / 表示一致性 (representation consistency) 的思想:通过对同一图像的不同增强视图进行聚类 (cluster assignments),并要求不同视图的聚类分配 (cluster assignment) 一致 (assignment consistency),从而在不显式构造大量正 / 负样本对 (或 memory bank / queue) 的条件下,也能学到有判别力 (discriminative) 的特征。SwAV 的这种 “聚类 + 表示一致性 (cluster assignment consistency)” 机制,使其在内存 /计算效率与表示质量之间取得较好平衡。 优快云 博客+1
3.3.3 优缺点与适用场景
-
优点:
-
对比学习 (尤其是 SimCLR、MoCo) 能学到对数据增强 (augmentations) 不敏感、对语义 / 实例差异敏感的判别性表示 (discriminative representation),在视觉分类、目标检测、语义分割等下游任务中表现强劲。
-
非对比 / 无负样本方法 (如 BYOL、SwAV) 简化训练流程 (不需要构造 / 存储 /管理大量负样本 / memory bank / queue),易于扩展,可在资源有限环境下使用。
-
对比 / non‑contrastive 方法可以与不同 backbone 架构 (CNN / Transformer) / 不同数据 (图像 /音频 /文本 /图) 结合,适用性广。
-
-
缺点 / 局限:
-
对比学习 (contrastive) 通常依赖较大 batch size 或大量负样本 (memory bank / queue),对计算资源要求较高;训练成本、显存 / 内存消耗较大。
-
对比学习对数据增强 (augmentation) 的选择非常敏感 —— 不合适的增强策略可能导致学习到无意义或退化的表示 (representation collapse / trivial solutions)。
-
非对比方法 (如 BYOL) 虽然不依赖负样本,但其训练机理目前仍缺乏完全被理解/理论保证 (为何不会 collapse)。
-
对比 / non‑contrastive 方法主要擅长学习判别性 /区分性 (discriminative) 表示,对于需要生成 (generation)、像素级重建 (pixel-level reconstruction) 或语义细节 (semantic nuance) 的任务,可能不如生成式方法。
-
因此,对比 (contrastive) 与其变种 /优化 (如非对比) 方法非常适合需要判别性 / 区分类别 /实例、对 augmentation 不敏感性要求高、资源允许的大规模视觉 / 表示学习任务 (例如图像分类、对象检测、特征迁移 / fine‑tune 等)。
3.4 基于聚类的方法(Clustering‑based Methods)
3.4.1 核心思想与直观解释
聚类 (clustering) 是一种在无标签数据上发现数据结构 (data structure) 和潜在类别 (latent clusters) 的经典无监督方法。在自监督学习中,聚类方法被用来为无标签数据生成 “伪标签 (pseudo‑labels)” —— 即假设同一簇 (cluster) 的样本属于同一语义 / 类别。然后,利用这些伪标签作为监督信号 (supervisory signal),用来训练模型 (例如分类器) 或设计预训练任务,使模型输出对簇结构敏感 / 能保持簇一致性。这种方法的直观思路是:数据本身 (在特征空间) 可能蕴含类别或语义上的簇结构 (cluster structure),通过聚类可以挖掘这些结构,从而创建一种弱监督 (weak supervision) 或伪监督 (pseudo supervision) 的环境。
通过聚类 + 伪标签 + 模型训练 (或迭代 clustering ↔ training) 的方式,模型学习到对簇结构 (cluster structure) 的敏感表征,这种表征往往对数据的全局 /类别结构 (global / class-level structure) 更加适合,而不仅限于实例级 (instance-level) 区分。
3.4.2 代表性算法与模型架构
-
DeepCluster:DeepCluster 是聚类 + 自监督结合 (clustering + SSL) 的经典方法。其流程为:
这种 “迭代聚类 ↔ 特征学习 (feature learning)” 的机制,使模型不断改进其嵌入 (embedding) 空间,使簇结构与类别 / 语义结构更加对齐。
-
使用当前模型 (通常是 CNN) 对所有 (或大量) 样本提取特征 (feature)。
-
对这些特征进行聚类 (如 K‑means),为每个样本分配一个伪标签 (cluster assignment)。
-
使用这些伪标签对模型进行 (类) 有监督训练 (supervised training, e.g., 交叉熵分类 loss),使模型输出符合 cluster assignment。
-
用更新后的模型重新提取特征,再次聚类 / 分配标签,如此往复 (iterative clustering ↔ training),直到收敛。
-
-
SeLa (Self‑Labelling):为了解决 DeepCluster 的离线聚类 (offline clustering) 需要全部 /大批量数据的问题,以及 K‑means 对初始化 /簇数 (cluster number) 敏感的问题,SeLa 将聚类转化为一个最优传输 (optimal transport) 问题,用 Sinkhorn–Knopp 算法快速进行软分配 (soft clustering),从而实现一种端到端 (end‑to‑end)、在线 (online) 的聚类 + 表征学习方法。SeLa 的效率和稳定性优于传统离线聚类 + 训练的循环。
-
结合聚类 + 表示一致性 + 对比 / 非对比方法:例如本文前述的 SwAV,就将聚类 (cluster assignments) 与对比 / 表示一致性 (representation consistency) 结合起来。SwAV 对图像的不同增强视图进行聚类 (assignment),并鼓励不同视图在 cluster assignment 上保持一致 (assignment consistency) —— 从而不需要显式的大量负样本 (negative samples) / memory bank / queue,也不需要典型对比损失 (contrastive loss),便能得到鲁棒、判别性良好 (discriminative) 的表征。 优快云 博客+1
3.4.3 优缺点与适用场景
-
优点:
-
聚类 + 伪标签方式 (pseudo-label) 可以揭示数据的全局 / 类别结构 (global / class-level structure),更适合类别 / 聚类相关任务 (如半监督分类、聚类、检索等)。
-
与对比学习相比,聚类方法不一定依赖大 batch /大量 negative samples / memory bank / queue,可对资源有限 / batch size 较小的环境更友好 (尤其是使用在线 / 增量 clustering 方法时,例如 SeLa / SwAV)。
-
聚类 + 表示学习 (embedding learning) 的组合,使得表示空间自然具备簇 / 类别结构 (cluster / class structure),利于后续分类、聚类、检索等下游任务。
-
-
缺点 / 局限:
-
聚类本身对初始化 (initialization)、簇数 (number of clusters) 选择十分敏感,不当选择可能导致伪标签质量差 (poor pseudo-labels),从而影响表征质量。
-
离线聚类 + 训练 (如 DeepCluster) 的计算开销大、耗时长、不适合大规模 / 流数据 (streaming data) 环境。即便是在线 / 增量 clustering,也可能面临聚类稳定性、收敛性与复杂度问题。
-
聚类假设 (cluster assumption) — 即 “同簇 (cluster) 样本属于同一语义类别 /意义” — 在真实世界中不总是成立。因此,伪标签可能包含噪声 (label noise),对 downstream 有潜在负面影响。
-
聚类方法更偏重类别 / 类别结构 (class / cluster structure),对于 instance-level 判别 (instance discrimination)、对数据增强 (augmentation) 的不变性 (invariance) 的学习可能不如对比 / non-contrastive 方法。
-
因此,基于聚类的方法较适合那些目标是类别 / 聚类 /检索 (clustering / retrieval / classification) 的任务,尤其在资源有限、 batch size 较小、或者不方便构造 / 管理大量 negative samples / memory bank 的情形下表现优越。
3.5 基于图的方法(Graph‑based Methods)
3.5.1 核心思想与直观解释
对于图 (graph) 数据 (如社交网络、分子结构、生物网络、知识图谱、推荐系统网络等),其基本结构既包括节点 (nodes) 的属性 (features),也包括节点之间复杂的关系 (edges)/拓扑结构 (topology)。因此,将自监督学习思想扩展到图结构 (graph) 数据时,自然需要设计预训练任务 (pretext tasks) 来让模型 (通常是图神经网络, Graph Neural Network, GNN) 学习节点及图的结构信息、属性信息与拓扑规律 (topological patterns) —— 而非传统在图像 /文本 /序列上的对比 /重建。
Graph‑based SSL 方法试图通过构造适合图数据的预训练任务 (如预测节点之间是否存在边 / link, 预测节点属性 /类别, 最大化局部 /全局信息之间的互信息 (mutual information), 对子图 /子结构 (subgraph / motif) 进行区分 /一致性学习等) —— 从而让 GNN 学到对图结构 /关系 /属性敏感、有泛化能力 (generalizable) 的节点 /图表示 (embeddings)。
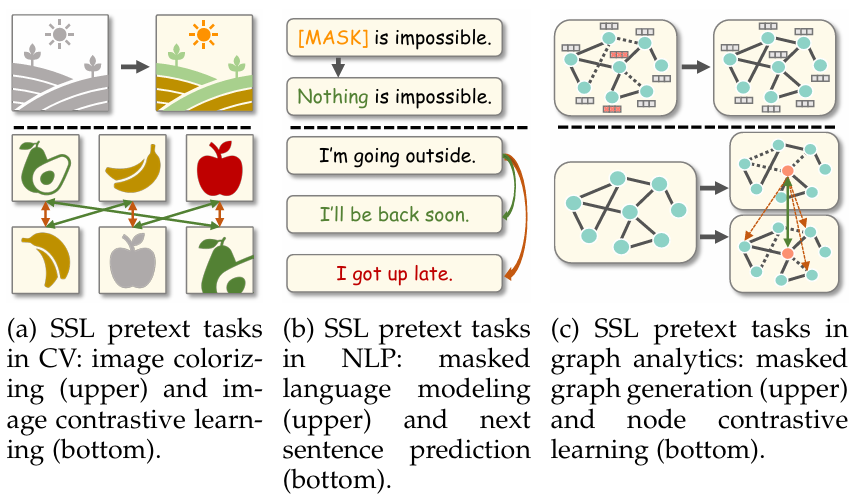
3.5.2 代表性算法与模型架构
-
在综述性文献中 (如 Graph Self‑Supervised Learning: A Survey),研究者将图 SSL 方法划分为 generation-based, auxiliary property–based, contrast-based, hybrid 等类别。 arXiv+1
-
基于对比 / contrast 的方法。例如 Graph Contrastive Learning (GCL)——将对比学习 (contrastive) 的思想引入图数据,通过对图 (graph) 或子图 (subgraph) 做数据增强 (augmentation) (如节点/边扰动、子图抽样、属性掩码 / 隐藏等),将不同增强版本作为正样本 (positive),其他图 (或子图) 作为负样本 (negative),然后用对比损失 (contrastive loss) 来训练 GNN,以便学习对图结构 /语义不变 (invariant) 且具区分性的图 /节点表示。针对图对比学习 (graph contrastive learning) 的综述也指出其数据增强策略 (augmentation), 对比模式 (contrastive mode), 优化目标 (contrastive loss) 等是关键要素。 arXiv+1
-
基于生成 /重建 (generative / reconstruction) 的方法,如图掩码 (masked graph modeling)、graph autoencoder / graph masked autoencoder (Graph‑MAE) 等。最近一项工作叫 Graph Contrastive Masked Autoencoder (GCMAE),便融合了 generative paradigm (masked edge/feature reconstruction) 与 contrastive paradigm (graph-level / subgraph-level contrast) —— 两个分支共享 encoder,通过重建图结构 (如 adjacency matrix) + 对比损失 (discrimination loss),兼顾全局结构 (global graph structure) 与局部 /细粒度特征 (local / feature-level) 的学习。这样的混合设计在多任务 (如节点分类、节点聚类、链路预测、图分类) 上表现优异。 arXiv+1
-
其他基于预测 (predictive)、属性 (auxiliary) 的预训练任务 — 如预测节点属性 /类别 (attribute/property prediction)、预测节点间 connectivity / link, 预测子图 motif / subgraph 结构、最大化局部节点表示与全局图表示 (global graph rep) 之间的互信息 (mutual information maximization) 等 — 都被归入广义的 Graph SSL 方法体系。 arXiv+1
这些方法通常以 GNN (如 GraphSAGE, GCN, GAT 等) 作为 backbone,通过消息传递 (message passing) 或注意力机制 (attention) 聚合邻居信息 (neighborhood information),并基于预训练任务 (contrast / reconstruct / predict) 学习节点 / 图 表示 (embeddings)。
3.5.3 实用考量与应用场景
Graph‑based SSL 方法在处理结构化、关系密集 (relational) 或非欧几里得 (non‑Euclidean) 数据 (如社交网络、生物网络、推荐系统、知识图谱、分子图 /化合物图、交通网络、通信网络等) 上具有天然优势。通过预训练 (self-supervised) 的方式,可以减少对大量人工标注 (例如节点类别 / link labels / node attributes) 的依赖,从而降低成本、提高泛化能力,并增强模型对图结构 /关系 /属性变化的鲁棒性 (robustness)。
不过,这种方法也面临挑战:
-
图规模可能非常大 (large-scale graph),训练与推理 (inference) 的计算 /存储成本高;
-
图数据结构复杂、稀疏 /不规则 (sparse / irregular graph),对 GNN 的设计、数据增强 (augmentation) 策略、预训练任务设计都提出较高要求;
-
如何设计合适的图增强 (graph augmentation)、如何平衡对局部结构 vs 全局结构 (local vs global) 的学习、如何避免过平滑 (over-smoothing) 或过拟合 (overfitting),仍是当前研究热点与挑战。
总的来说,Graph-based SSL 是将自监督 / 表示学习扩展到复杂结构化数据 (graphs) 的重要方向,适用于社交网络分析、推荐系统、生物 /化学 (分子图)、知识图谱、交通 /通信网络分析等多个领域。
3.6 小结与各方法对比
| 方法类别 | 优势 | 局限 / 挑战 | 适用场景 |
|---|---|---|---|
| 基于上下文 (Context-based) | 方法直观、任务设计简单;适用多模态 (文本/图像/音频/时间序列);易于实现 & 扩展 | 对重建 / 重构 /预测目标依赖较大;可能学习到过于局部 /低语义 /冗余特征 | 文本 (mask language)、图像 patch reconstruction / inpainting、语音/时间序列掩码预测等 |
| 生成式 (Generative) | 能学习数据分布 (data distribution);latent 空间结构化、便于生成 / 插值 / 编辑;适合生成 /合成任务 | 生成质量 /稳定性 /多样性问题;训练开销大;评价困难;所学表示对下游任务未必最优 | 图像 / 视频 / 音频 / 文本 /多模态生成/编辑 / 数据增强 |
| 对比 (Contrastive) / 非对比 | 表征判别性强、对增强 (augmentation) 不敏感,迁移能力好;无监督预训练 + 下游 fine‑tune 效果显著 | 需要大量 negative samples /大 batch / memory bank / queue;训练资源 & 工程复杂;对模式 collapse /不稳定性敏感 | 图像 /视觉分类、检测、分割;特征提取 /迁移学习;资源允许的大规模训练环境 |
| 基于聚类 (Clustering) | 可生成伪标签 (pseudo-label);擅长捕捉数据的 global / class-level 结构;对资源要求相对温和 (特别是 online clustering 方法) | 聚类质量受初始化 /簇数敏感;伪标签可能有噪声;聚类 + 训练开销大;类别结构假设不总成立 | 半监督分类 /聚类 /检索 / 特征学习 / 资源受限环境 |
| 图 (Graph-based) | 能处理结构化 /关系型 /非欧几里得数据;适合复杂图 / 网络数据;可捕捉结构 + 属性 + 全局 /局部信息 | 图规模 /稀疏性 /不规则性带来训练 /存储 /计算挑战;图增强 /预训练任务设计复杂;过平滑 / 泛化问题 | 社交网络、生物 /化学网络 (分子)、知识图谱、推荐系统、交通 /通信网络等 |
4 自监督学习的预训练与统一表征
4.1 预训练范式的演进
自监督学习 (Self‑Supervised Learning, SSL) 与“预训练 (Pre‑training) + 微调 (Fine‑tuning)”范式 (pre‑training & fine‑tuning) 的结合,是近年来深度学习模型训练流程的重要变革。该范式使模型能够在大规模、无标签 (unlabeled) 数据上通过自监督任务进行训练,学习通用、可迁移 (transferable) 的特征表示 (representation),再将这些表示通过微调 (fine‑tune) 应用于特定下游任务 (downstream tasks),从而大幅减少对标注数据 (labeled data) 的依赖,同时提升模型泛化能力与迁移性能。
回顾发展历程,这一范式经历了若干关键阶段:
-
早期词嵌入 (word embedding) 与语言模型:虽然传统词嵌入 (如 Word2Vec, GloVe) 本身不是自监督学习,但它们为后来的语言模型 (language model) 与上下文预测 (context prediction) 提供了思想基础。随着模型与计算能力提高,以自监督为基础的大规模语言预训练模型成为可能。
-
基于 Transformer 的语言预训练模型:以 BERT、GPT 系列为代表,通过 Masked Language Modeling (MLM)、自回归语言建模 (autoregressive LM) 等任务,在海量无标签文本上预训练,获得语义丰富、上下文敏感 (contextualized) 的语言表示。此时预训练‑微调范式在自然语言处理 (NLP) 取得巨大成功。
-
视觉 (CV) 领域加入预训练范式:在图像 /视频 /多媒体领域,把自监督 SSL 与预训练‑微调范式结合。研究者利用对比学习 (contrastive learning)、掩码图像建模 (masked image modeling)、自编码器 (autoencoder) 等 SSL 方法,在大规模图像 /视觉数据集上进行预训练,再将获得的视觉特征迁移到图像分类、目标检测、语义分割等下游任务。
-
多模态 / 跨模态预训练的兴起:随着计算力和数据量的提升,以及对通用人工智能 (General AI) 的追求,研究者开始尝试把预训练范式扩展到多模态 (multimodal) 数据 —— 即同时处理文本、图像、音频、视频、结构化数据等,并学习统一、共享 (shared) 的多模态表征 (representation)。
最近的一些研究进一步推动了这一路线的发展。例如,发表于 2025 年的论文 Scaling Language-Free Visual Representation Learning 就探索了“纯视觉自监督 (visual SSL)”在大规模、多数据 /大模型容量 (scale) 下是否能达到或接近跨模态 (language-image) 预训练 (如 CLIP) 的效果。该研究表明,在相同数据与训练条件下,纯视觉 SSL 随着模型与数据规模扩大,其性能并未饱和 (not saturated),并在视觉问答 (VQA) 与经典视觉基准任务上达到了 CLIP 水平。 arXiv
这说明,预训练范式并不局限于某个模态 (如文本或图像),其核心价值在于:利用海量未标注数据 + 合理的自监督任务 + 可扩展模型 /训练机制,获得高质量、通用且可迁移的表示 (representations),从而为不同任务 / 模态 /应用奠定统一基础。
因此,预训练 + 微调范式的发展,使自监督学习从概念与小规模实验,逐步迈入多领域、可应用、工业级 (production‑level) 的主流技术路线。
4.2 统一表征 (Unified Representation) 的提出与意义
随着自监督学习在单模态 (unimodal) 场景 (文本 / 图像 /音频 /视频 /图 /序列) 上取得诸多成功,研究界与工业界越来越关注一个更具挑战性且前瞻性的问题:能否学习一种统一 (unified)、通用 (universal)、跨模态 (cross-modal) 的表征 (representation)?也就是说,是否存在一种表示空间 (latent / embedding space),它可以同时容纳多种模态数据 —— 如文本 (text)、图像 (image)、音频 (audio)、视频 (video)、结构化 /图 (graph) 等 — 并且能够支持多模态任务 (multimodal tasks)、跨模态检索 /生成 /理解 /推理,以及跨任务 (multi-task) 的迁移。
这种“统一表征 (unified representation)” 的提出与追求,具有重要意义:
-
反映现实世界信息的多模态性:现实世界的数据与信息往往是多模态的。例如,一篇新闻可能包含文字+图片+视频+ metadata;一个产品可能有图像、文字描述、用户评论、属性标签等。一个仅能处理单一模态的模型,难以应对真实世界复杂、多模态的信息分布。统一表征能够使模型更贴近现实世界,具备多模态理解、融合与推理能力。
-
提升通用性与迁移能力:如果不同模态的数据能够被映射到同一个表征空间 (shared embedding space),那么模型在某种模态 / 任务上学到的知识可以更容易迁移 (transfer) 到其他模态 /任务。这为构建“大一统 (foundation)” / “通用 (generalist)” 模型打下基础。
-
简化模型设计与部署:统一表征减少了为每个模态 / 任务设计专门模型的需求。研究者与工程师可以基于一个通用 backbone + 统一表示 + 下游适配 (fine‑tune / prompt) 的方式,快速构建多模态、多任务系统。
-
推动多模态生成、检索、推理与交互:统一表征为跨模态生成 (text-to-image, image-to-text, audio-visual synthesis)、跨模态检索 (图文检索、视频-字幕检索等)、多模态推理 (视觉问答 / 视频理解 / 多模态对话) 等任务提供基础,有助于构建更通用、更智能、更接近人类认知的系统。
因此,统一表征 (Unified Representation) 不仅是技术演进的自然产物,也是迈向通用人工智能 (AGI)/通用多模态模型 (multimodal foundation models) 的关键一步。
4.3 从预训练到统一表征的技术路径
要实现统一表征 (multimodal / cross-modal / universal representation),目前文献和实践主要探索了以下几条技术路径 (或组合路径)。
路径一:跨模态对比 (Cross‑Modal Contrastive) / 对齐 (Alignment)
这一路径将对比学习的思想扩展到多模态 (multimodal) 数据:将不同模态 (如图像与文本) 的对应 (paired) 数据作为正样本 (positive pair),不同模态但不对应的数据作为负样本 (negative),然后通过对比 (contrastive) loss,把正样本对的表示拉近 (embed close),把负样本对表示拉远 (embed far) — 从而将各模态映射 (embedding) 到同一个共享语义空间 (shared semantic space / shared embedding space)。
典型代表包括 CLIP (Contrastive Language‑Image Pre‑training) —— 该模型使用大规模 (image, text) 对,在图像编码器与文本编码器上分别编码图像 / 文本,然后通过对比学习,将它们映射到统一 embedding 空间。CLIP 的成功展示了跨模态对比学习 (cross-modal contrastive learning) 在实现统一表征方面的巨大潜力。 维基百科+1
更近于 2025 年的研究,Multi-modal contrastive learning adapts to intrinsic dimensions of shared latent variables 探讨了跨模态对比学习 (multimodal contrastive learning) 所学表示的理论性质。该研究认为,通过合适的温度 (temperature) 优化 (temperature optimisation),跨模态对比学习不仅最大化模态之间 (modalities) 的互信息 (mutual information),还能够适应数据的“内在维度 (intrinsic dimension)” —— 也就是说,所得表示空间 (representation vector) 的维度可以低于人为设定 (user-specified) 的表示维度,同时仍保留丰富、信息量高且有用的语义结构。 arXiv 这一发现为跨模态统一表征的可行性提供了理论支撑,也为未来设计更高效、低维、通用的多模态表示 (multimodal embeddings) 提供方向。
此外,为了解决跨模态对齐中数据噪声 (noise)、多对多 (many-to-many) 对应 (correspondences) 等问题,有研究提出对比 + 自蒸馏 / 软对齐 (soft‑alignment) 的训练机制,例如 Robust Cross-Modal Representation Learning with Progressive Self-Distillation。该方法在 web‑harvested 的图像-文本 (image-caption) 数据集中,使用 progressive self-distillation + soft alignment target,改进了传统对比学习 (如 CLIP) 的鲁棒性 / 训练效率 /噪声容忍性。实验证明,该方法在零样本分类 (zero-shot classification)、线性探测器 (linear-probe transfer)、图文检索 (image-text retrieval) 等任务上均优于 CLIP,且对自然分布 (distribution shift) 的泛化能力更强。 arXiv
因此,跨模态对比 / 对齐 (contrastive / alignment) 方法,是当前实现统一表征最主要、最有效、最广泛使用的技术路径之一。
路径二:统一 / 模态-无关 (Modality‑Agnostic) 模型 + 多模态预训练 (Multimodal Pre-training)
另一种路径是设计统一 (unified) 或模态‑无关 (modality‑agnostic) 的模型 / 架构,使不同模态数据在输入阶段即可被统一编码 /标记 (tokenize / encode),然后在统一 backbone (如 Transformer) 上进行训练,从而从根本上实现多模态融合与通用表示学习。
近年来,这种思路在多个研究与系统中得到了探索。以最近综述 /实践为例:
-
多模态基础 /通用模型 (generalist / foundation models):一些综述指出,从专用 (task‑specific) 模型 → 预训练模型 → 多模态基础模型 (multimodal foundation model) 的过渡,代表了建模范式的演化。具体来说,一些模型使用统一的输入处理 (tokenization / encoding) 模块,将图像 /视频 /文本 /音频等转为共享 token / embedding,然后再用统一的 Transformer 框架处理 — 从而支持多任务、多模态、多下游任务。 优快云 博客+1
-
最近在视觉 /多模态领域提出了多种统一 /通用框架,例如将视觉模型 + 语言模型 + 任务适配 (prompt / instruction) 结合起来,形成能够同时支持分类 /生成 /检索 /多模态推理等任务的一体化系统 (generalist system)。这些框架通常包含模态专用编码器 (modality-specific encoders)、统一 backbone /融合模块 (fusion modules)、以及任务适配层 (task adapters / prompt modules) 等结构。 优快云 博客+1
-
最新研究强调可扩展性 (scalability)、任务与模态无关性 (modality-agnosticism) 以及高效训练 /推理机制。通过合理设计 tokenization、编码和融合机制,可以将不同模态的数据映射到统一 latent 空间。然后通过多模态预训练 + 下游适配 (fine-tune / prompt) 实现跨任务 /跨模态迁移。这种方式减少了任务冗余与模型碎片化 (fragmentation),有助于构建通用、多功能、多模态的大模型 (foundation models / generalist models)。
因此,“统一 / 模态‑无关 + 多模态预训练 (multimodal pre‑training)” 是通向统一表征 / 通用模型 (generalist foundation model) 的关键技术路径,是未来研究与工业应用的重要趋势。
4.4 统一表征的挑战与未来方向
尽管跨模态对比 + 统一模型架构的研究取得显著进展,但实现真正通用、鲁棒、公平、可扩展的统一表征 (unified representation) 仍面临诸多挑战。以下是主要难点与未来可能的发展方向。
| 挑战 / 问题 | 说明 /影响 |
|---|---|
| 模态间差异大 (heterogeneity across modalities) | 不同模态 (text, image, audio, video, graph 等) 在结构 (结构化 vs 非结构化)、尺度 (token 序列 vs 像素 /帧 /图 / waveforms)、统计分布 (distribution)、语义 /信息内容 (semantic vs signal) 等方面差异极大。这导致统一 tokenization / encoding + shared backbone 的设计困难。 |
| 数据集构建与数据质量 | 构建大规模、多模态、多任务的数据集 (image-text, video-text, audio-text, multimodal triples) 成本高昂。网络抓取的数据 (如 web image-caption pairs) 往往 noisy、偏向 (bias)、不平衡 (uneven distribution),这会影响对齐/对比学习效果,以及后一代模型的公平性 (fairness) 与泛化能力 (generalization / robustness)。 |
| 训练与计算资源成本 | 多模态 + 大模型 (foundation model) 的预训练需要巨量计算资源 (GPU/TPU,存储,带宽),训练与推理成本高。对于很多研究机构 / 企业 /开发者来说,资源限制是现实瓶颈。 |
| 负迁移 (Negative Transfer) 与任务干扰 (Task Interference) | 不同任务 /模态 /下游任务之间可能冲突 (conflict) — 在统一模型中,一种任务 /模态的优化可能损害另一种任务 /模态 /下游任务的表现 (catastrophic interference / negative transfer)。如何设计多任务 / 多模态训练机制,避免冲突、保持平衡,是一个重要挑战 (如任务调度、权重平衡、适配器设计、prompt / instruction 机制等)。 |
| 表征可解释性 (Interpretability) 与公平性 (Fairness) /鲁棒性 (Robustness) | 统一模型 /通用表示往往更为复杂 (深层、跨模态、巨量数据训练)。其 learned representation 的可解释性较差 — 对偏见 (bias)、噪声 (noise)、对抗攻击 (adversarial attack) 的敏感性 /脆弱性可能更高。在高风险领域 (医疗、金融、司法等),这对落地应用构成重大阻碍。 |
| 评估 /标准化困难 (Evaluation & Benchmarking) | 多模态 / 多任务 /多应用场景下,很难设计统一 /公平 /全面的评估标准 (benchmarks / metrics) 。不同模态 + 任务的差异性使得统一比较难度极大。 |
基于上述挑战,未来研究 /发展可能围绕以下方向:
-
高效 / 轻量 /节能的多模态模型 /训练机制 — 包括模型压缩 (compression)、知识蒸馏 (distillation)、低秩更新 (low‑rank adaptation) 等技术,以降低计算 /能源消耗,使普通机构 /研究者 /设备也能参与多模态 /统一表征研究;
-
更智能 / 自动 /理论驱动的预训练任务设计 (pretext task design) — 尝试自动化或半自动化生成适合多模态 / 多任务 /多领域的预训练任务 (task generation),减少对人工经验 /启发式 (heuristic) 的依赖;
-
改进数据质量 / 数据构建与治理 (data curation & governance) — 建立更标准、更高质量、更公平 /多样 (diverse) 的多模态数据集,同时注意隐私 (privacy)、偏见 (bias)、伦理 (ethics) / 合规 (compliance);
-
模块化 / 可适配 /可解释 (modular & interpretable) 架构设计 — 通过适配器 (adapter)、专家 (expert) 模块 (Mixture‑of‑Experts, MoE)、任务 /模态条件化 (conditional / prompt-based) 等机制,使统一模型在不同任务 / 模态 /计算资源下更灵活、更高效、更安全 / 可控;
-
统一 /标准化评估 (benchmarking) 与公平 /鲁棒性研究 (fairness, robustness, bias, adversarial) — 建立适合多模态 / 多任务 / 多下游场景的评估基准 (benchmarks),同时深入研究表示 /模型对数据偏见、分布偏移 (distribution shift)、对抗性攻击 (adversarial attacks)、隐私泄漏 (privacy leakage) 等问题。
-
持续 /在线 /终身学习 (continual / lifelong learning) 与 联邦 /分布式 /隐私保护学习 (federated / private learning)** — 使统一表征模型能够在不断变化 /增长 /分布式 /隐私敏感的数据环境中更新与适应,而不会遗忘 /崩溃。
总的来看,统一表征 (unified representation) 虽然面临诸多挑战,但其潜力巨大。随着计算资源、算法、数据处理、模型设计的不断进步,它极有可能成为未来 AI /机器学习 /多模态智能系统的主流范式。
5. 自监督学习的应用与性能分析
5.1 计算机视觉领域的应用
在计算机视觉领域,自监督学习几乎已经成为表征学习和预训练的“默认选项”。以ImageNet为代表的大规模数据集上,早期工作已经证明,通过自监督预训练得到的视觉 backbone,在多种下游任务(图像分类、目标检测、语义分割、实例分割、检索等)上,可以达到甚至逼近完全监督预训练的水平。更重要的是,在标注极其稀缺的低资源场景、自定义行业数据集以及跨域迁移场景中,自监督预训练往往展现出明显优于纯监督训练的优势。arXiv+1
在图像分类任务上,以SimCLR、MoCo v2、BYOL、SwAV、MAE、BEiT / BEiT v2 等为代表的方法,已经系统地展示了自监督表征的可迁移性。SimCLR 通过极简而强大的对比学习框架,在ResNet-50骨干上实现了76.5%的ImageNet Top-1线性评估精度,这一数值已经与标准监督训练的ResNet-50相当,表明自监督学习可以在无标签条件下学到与监督学习同等质量的特征。arXiv+2Proceedings of Machine Learning Research+2 MoCo v2 通过动量队列和改进的数据增强策略,在800轮预训练后达到约71.1%的Top-1精度,一方面显著超越早期的无监督基线,另一方面证明了在中等批大小条件下也可以有效训练大规模对比学习模型。arXiv+1 BYOL 则在不显式使用负样本的情况下,仅依赖在线网络与目标网络之间的一致性约束,就在ResNet-50上获得74.3%的Top-1精度,说明“无负样本”范式在实践中同样可行。 SwAV 将在线聚类与对比学习相结合,通过多裁剪策略(multi-crop)进一步提升性能,在ResNet-50上可达到约75.3%的Top-1精度。
在Transformer 视觉模型方面,掩码自编码器(MAE)和BEiT / BEiT v2 通过“遮掩-重建”范式实现了对图像结构的高效建模。MAE 在ViT-B/16骨干上通过高比例掩码的像素重建任务,在ImageNet线性探测设置下实现了约67.8%的Top-1精度;BEiT v2 进一步结合离散视觉token和改进的预训练目标,在线性探测实验中可达到80%以上的Top-1精度,在同一骨干和训练资源下显著优于早期视觉Transformer自监督方案。 一系列针对轻量级Vision Transformer的研究(例如对小模型在低标注数据下表现的系统分析)也表明,在有限标注和小模型容量条件下,自监督预训练对提升模型泛化能力尤为关键。Proceedings of Machine Learning Research+1
为了更直观地对比不同方法在ImageNet图像分类上的表现,可以参考下面基于原始论文统计的代表性结果(均为ResNet-50骨干的线性评估或标准监督结果)。
表1 代表性自监督学习方法在ImageNet上的Top-1分类性能(ResNet-50)
| 方法 | 预训练任务类型 | 骨干网络 | 预训练数据 | 线性评估 / 监督 Top-1 准确率 (%) |
|---|---|---|---|---|
| Supervised | 监督学习 | ResNet-50 | ImageNet-1K | 76.4–76.5 |
| MoCo v2 | 对比学习 | ResNet-50 | ImageNet-1K | 71.1 |
| SimCLR | 对比学习 | ResNet-50 | ImageNet-1K | 76.5 |
| SwAV | 聚类-对比(多裁剪) | ResNet-50 | ImageNet-1K | 75.3 |
| BYOL | 自蒸馏(非对比) | ResNet-50 | ImageNet-1K | 74.3 |
(数据综合自各方法原始论文与后续复现报告。Arimorcos+4arXiv+4arXiv+4)
在目标检测和语义分割等下游任务中,MoCo 系列以及后续 Fast-MoCo 等工作系统地验证了自监督预训练的迁移优势。MoCo v2 在以ResNet-50为骨干的Faster R-CNN 或Mask R-CNN 检测器中,相比从头监督训练,可以在COCO等数据集上获得约1–2个mAP的提升;而一些增强的对比框架(如Fast-MoCo)在保持甚至减少预训练轮次的前提下,通过更高效的“组合patch对比”机制,在COCO检测与实例分割上进一步刷新性能。arXiv+2欧洲计算机视觉协会+2 这类实验结果的一个重要结论是:即便线性评估Top-1精度与监督模型仍存在差距,自监督表征在复杂下游任务中仍然可以展现出更强的泛化性和鲁棒性。
为了具体说明这一点,可以列举部分公开的检测 / 分割结果(仅展示趋势而非穷尽所有设置)。
表2 自监督预训练对目标检测 / 实例分割性能的影响(部分结果示例)
| 预训练方式 | Backbone | 下游任务与框架 | 数据集 | mAP (box / mask) 大致水平 |
|---|---|---|---|---|
| 监督 ImageNet | R-50-FPN | Faster/Mask R-CNN | COCO | 38–39 / 34–35 |
| MoCo v2 SSL | R-50-FPN | Faster/Mask R-CNN | COCO | 较监督+≈1–2 mAP |
| Fast-MoCo SSL | R-50-FPN | Faster/Mask R-CNN、DETR 等 | COCO | 在更少预训练轮次下达到或略超MoCo v2 |
(具体数值见MoCo v2与Fast-MoCo等论文中COCO检测与实例分割的对比表格。arXiv+2欧洲计算机视觉协会+2)
多模态视觉任务中,自监督学习也展现出强大的能力。CLIP 通过大规模图文对比预训练,在无需额外微调的情况下,就能在ImageNet等多种分类基准上实现强大的零样本分类性能,在许多数据集上超越传统监督模型。ResearchGate+1 大量后续工作基于CLIP进行视觉提示学习(prompting)、线性探测和少样本微调,使得预训练视觉编码器可以快速适配图像检索、开集识别、视频理解等复杂任务。更近的研究则表明,纯视觉自监督预训练在足够大的数据和模型规模下,在许多视觉任务上可以逼近甚至达到CLIP 等跨模态模型的表现,说明单模态视觉SSL本身仍有巨大的挖掘空间。alphaXiv+1
总体而言,计算机视觉领域的证据已经相当充分:在标准大规模数据集上,自监督预训练可以在分类、检测、分割等多种任务上与监督预训练“平起平坐”;在低标注、小样本、跨域迁移以及多模态场景中,自监督学习甚至往往成为性能和泛化性最优的选择。
5.2 自然语言处理领域的应用
在自然语言处理(NLP)领域,自监督学习更是彻底改变了模型训练范式。以BERT、GPT 系列为代表的预训练语言模型,已经成为几乎所有NLP任务的“基础设施”。BERT 通过掩码语言模型(MLM)和下一句预测(NSP)任务,在海量未标注语料上学习到深层双向上下文表征,在GLUE、SQuAD等标准基准上,显著超越了此前基于静态词向量(如Word2Vec、GloVe)的各类模型。Nature+1 后续的RoBERTa、ALBERT、ELECTRA、DeBERTa等模型在预训练目标、架构和训练策略上做了多种改进,通过更长训练、更大batch、更大语料、更稳定的收敛策略等手段进一步提升了性能。arXiv+1
另一方面,自回归语言模型(GPT 系列)采用“根据前文预测下一个token”的预训练目标,在完全无监督 / 自监督的设定下,通过规模化(数百亿或千亿参数级别)展现出惊人的生成与推理能力。GPT-3 在几乎所有主流NLP基准上,通过零样本 / 少样本提示(in-context learning)就能取得接近甚至超越有监督微调模型的表现,改变了人们对“训练一次,多次使用”的理解,也从根本上推动了大模型技术的发展。Nature+1 最近的研究表明,在指令微调(instruction tuning)、人类偏好对齐(RLHF)和多模态扩展的基础上,大型语言模型已经能够一体化地处理对话、翻译、抽取、推理、代码生成等多种任务,而其底层仍然是自监督预训练表征的延伸。ScienceDirect+1
从任务覆盖度来看,自监督预训练语言模型在文本分类、情感分析、命名实体识别、语义角色标注、机器翻译、信息抽取、问答系统、阅读理解、自然语言推理、文本摘要、对话系统等几乎所有NLP下游任务上均取得过SOTA或接近SOTA的结果。系统性的综述工作指出,在资源丰富的高资源语言上,自监督预训练已经成为性能最优且工程成本可控的主流方案;在低资源语言和跨语言迁移场景中,通过多语预训练模型(如mBERT、XLM-R)结合继续预训练(domain / language adaptation)与少量标注微调,则可以在极低标注成本下获得高质量模型。arXiv+1
更值得关注的是,自监督学习在NLP中的作用已经从“表征提供者”延伸到“世界知识载体”和“推理能力涌现”的层面。随着模型参数规模与训练数据规模的持续扩大,各类研究工作观察到大模型在数学推理、符号推理、多步逻辑推理、多任务组合等方面出现明显的“涌现现象”,而这些能力并非来自显式的监督或手工规则,而是自监督预训练在大规模多样语料上长期累积的结果。ScienceDirect+1 因此,从某种意义上说,现代NLP系统本质上已经是建立在自监督学习基础上的“通用文本世界模型”。
5.3 其他领域的应用
除了CV和NLP,自监督学习在语音、推荐系统、医疗与生物信息学等领域同样展现出快速扩张的趋势。
在语音与音频领域,典型代表是Facebook AI提出的 wav2vec 2.0。该方法首先在大量未标注语音上通过对比式自监督目标进行预训练,然后在极少量标注数据上进行微调,就能在LibriSpeech等语音识别基准上取得极高精度。原始论文报告:在仅使用10分钟标注数据的极低资源设定下,wav2vec 2.0 LARGE模型在LibriSpeech test-clean/test-other上的字错误率(WER)可达到约4.8%/8.2%,而传统的离散BERT基线在相同设定下的WER约为16.3%/25.2,误差大幅降低。NeurIPS 论文集+2NeurIPS 论文集+2 当标注数据增至1小时、10小时、100小时甚至全部960小时时,wav2vec 2.0预训练带来的收益依然显著,在全监督设定下,其WER可达到1.8%/3.3,优于多种半监督和自训练方法。NeurIPS 论文集
表3 wav2vec 2.0 在LibriSpeech低资源设置下的WER对比(节选自原始论文)
| 模型 | 未标注数据 | 标注数据量 | LM 类型 | test-clean WER (%) | test-other WER (%) |
|---|---|---|---|---|---|
| Discrete BERT 基线 | LS-960 | 10 分钟 | 4-gram | 16.3 | 25.2 |
| wav2vec 2.0 BASE | LS-960 | 10 分钟 | Transf. | 6.9 | 12.9 |
| wav2vec 2.0 LARGE | LV-60k | 10 分钟 | Transf. | 4.8 | 8.2 |
(数据来源于 wav2vec 2.0 原文表1,略去dev集结果。NeurIPS 论文集+1)
这一系列结果非常清晰地展示了自监督预训练对于“极低标注语音识别”的关键作用,也启发了后续大量基于SSL的声学模型与语音表示(例如 HuBERT、data2vec等)。随着研究的推进,自监督语音表征不仅在ASR,还在说话人识别、情感识别、语音检索、多模态语音-文本模型等场景中得到广泛应用。arXiv+1
在推荐系统领域,自监督学习被视为解决“数据稀疏、冷启动、交互噪声”等根本难题的重要方向。Yu 等在2022年的综述系统提出了“Self-supervised Recommendation (SSR)”的概念,并根据预训练目标和结构设计,将现有方法划分为对比式、生成式、预测式和混合式四大类,展示了自监督信号如何通过图对比、序列预测、多视角一致性等机制缓解交互稀疏和标签噪声问题。arXiv+1 随后,Ren 等在2024年的综合性综述中进一步梳理了自监督推荐在协同过滤、序列推荐、知识图谱推荐、多模态推荐等子方向的最新进展,指出对比学习和图结构自监督是当前提升推荐性能的主流途径之一。arXiv+2ACM Digital Library+2 相关实证研究表明,在多个公开基准上,自监督推荐模型相对于传统协同过滤或图神经推荐模型,常常可以取得显著的AUC、NDCG等指标提升,尤其是在交互稀疏或新用户比例较高的情形下。自监督推荐学习+1
在医疗影像与生物信息学领域,自监督学习的价值更加明显。最新的系统综述显示,在X光、CT、MRI、眼底照片、病理切片等多种模态的医疗影像任务中,利用自监督预训练的模型,在病灶检测、分割、分级等任务上,经常可以在标注大幅减少(甚至仅使用极少量标注)的情况下,达到或接近完全监督模型的性能。arXiv+5Nature+5PubMed+5 有工作对几十篇SSL-医疗影像论文进行定量汇总,发现当标注量减少到10%甚至1%时,自监督预训练加微调的方案往往可以保持90%以上的全监督性能,而从头监督训练则出现明显性能崩溃。这些结果使得自监督学习在高标注成本、高隐私敏感度的医疗场景中具有天然优势。Nature+2ScienceDirect+2
除此之外,自监督学习还在蛋白质结构建模(如通过大规模无标注氨基酸序列预训练蛋白语言模型)、基因组序列分析、分子图性质预测、遥感影像理解、交通流量预测、工业传感器异常检测等诸多领域中被成功应用。近年来的一些跨领域综述指出,只要存在丰富但未标注的数据且任务对表示质量敏感,自监督学习就几乎总能带来显著收益。arXiv
5.4 性能分析与综合比较
从上述不同领域的案例可以看出,自监督学习在性能和实用性上都取得了令人信服的成果。下面从三个维度对其性能特征进行综合分析。
首先,从“与监督学习的距离”来看,在标准大规模数据集(如ImageNet、LibriSpeech、GLUE等)上,自监督表征在充分预训练和适当微调的前提下,通常可以达到与监督预训练相当甚至略优的表现。例如,SimCLR 在ResNet-50上实现了与监督训练几乎相同的ImageNet Top-1精度;BYOL、SwAV等方法在稍低或接近的精度水平之上,还展现了更好的迁移性能;wav2vec 2.0 在大量无标签语音预训练后,只需极少量标注就能在WER上显著超越传统监督或半监督方法。NeurIPS 论文集+3arXiv+3arXiv+3 多篇综合性综述也指出,在视觉和语音领域,自监督预训练在“高资源设定 + 下游全监督微调”下已基本不再是性能短板,而是在“低标注 / 迁移 / 多模态”等更具挑战性的设定中成为主角。arXiv+2ScienceDirect+2
其次,从“数据与标注效率”角度,自监督学习的优势更加明显。在语音识别任务中,wav2vec 2.0 等方法在仅有10分钟或1小时标注数据的极端设定下即可获得可商用的识别性能;在图像领域,少量标注样本配合强大的SSL预训练backbone 已能够实现媲美传统大规模有标注训练的性能;在推荐系统、医疗影像等高成本场景中,自监督学习更是成为缓解数据稀疏和冷启动的核心技术路径。arXiv+4NeurIPS 论文集+4Nature+4 这意味着,当数据获取相对容易而标注昂贵或受限时,自监督学习几乎是唯一可规模化扩展的解决方案。
最后,从“跨任务与跨模态的泛化能力”视角看,自监督表征天然具有更强的迁移潜力。对比学习和掩码建模等预训练目标往往不针对某个特定下游任务,而是聚焦于捕获数据中更普遍、更稳定的语义与结构规律,因此在迁移到与预训练任务分布偏离较大的下游任务时,仍能够保持较好的表现。这一点在多模态任务中尤为重要:CLIP、ALIGN 等跨模态自监督模型在图文检索、零样本分类、跨模态理解等多种任务之间可以“一模多用”;自监督预训练的语音与视觉编码器也可以自然融入多模态Transformer或对比框架中,成为统一表征的一部分。ScienceDirect+3ResearchGate+3PubMed+3
综合这些证据,可以认为:自监督学习不仅在经典基准上缩小了与监督学习的性能差距,甚至在数据效率、迁移能力、多模态扩展等维度上展现了显著优势。这也为下一章讨论“统一表征”和未来发展趋势提供了坚实的现实基础。
6. 自监督学习的未来发展趋势与开放性问题
6.1 未来发展趋势
从近期大量综述性工作以及2023–2025年的前沿研究来看,自监督学习的未来发展大致呈现出几个相互交织的方向:多模态融合与统一表征、规模化与高效化的平衡、持续学习与在线自监督、隐私友好型自监督,以及与强化学习 / 生成模型的深度融合。ResearchGate+4arXiv+4ScienceDirect+4
首先,多模态融合及统一表征将继续成为研究热点。CLIP、ALIGN、Florence 等模型已经证明,通过跨模态对比或联合建模,可以在统一的语义空间中同时表示图像、文本,甚至视频等多种模态,为零样本识别、跨模态检索、视觉问答、多模态对话等任务提供通用基础。ResearchGate+1 最近的理论工作进一步表明,多模态对比学习在适当的温度调节和损失设计下,可以自适应地捕获跨模态共享潜变量的“内在维度”,从而在不显著增加表示维度的前提下保留高信息量。PubMed+1 这些结果说明,从信息论和几何结构上看,跨模态自监督学习具有天然的统一表征潜力。随着大型多模态语音-视觉-语言模型的快速发展(如同时处理文本、图像、语音、视频的“通用多模态大模型”),自监督预训练预计将继续作为其核心训练范式。PubMed+2alphaXiv+2
其次,规模化与高效化的平衡问题会从工程挑战上升为研究范式问题。现有许多成功的自监督模型(无论是视觉还是语言)在训练阶段往往依赖巨量计算资源和长时间训练,例如几百到上千轮的对比预训练、数十万步甚至百万步的Transformer预训练等。Nature+4arXiv+4欧洲计算机视觉协会+4 最近的一些工作尝试通过更高效的预训练目标、更轻量的架构和更智能的样本选择策略,实现在更少计算预算条件下逼近“全量大模型”的效果。例如,Fast-MoCo 通过在两视图之上构造组合patch对,使得100轮预训练即可达到接近MoCo v3 800轮的ImageNet线性评估精度,极大降低了研究者进入这一领域的门槛。arXiv+1 在语言和多模态领域,诸如参数高效微调(PEFT)、适配器(Adapter)、前缀 /提示调优(Prefix/Prompt Tuning)等技术也正在与自监督预训练结合,用更小的增量参数完成下游迁移与任务个性化配置。ScienceDirect+1 可以预见,未来一段时间内,“高效自监督学习”将成为并行于“大模型自监督”的重要研究方向。
第三,持续学习与终身学习能力将借助自监督学习得到进一步强化。当前的自监督预训练大多仍采用“离线批量训练”的范式,即一次性在大规模静态数据集上完成预训练,然后固定参数。对于真实世界持续变化的数据流,这样的方式显然不够理想。越来越多的工作开始探索在流式数据或在线环境中,通过自监督目标持续更新模型表征,同时避免灾难性遗忘。例如,在推荐系统中,基于图的自监督方法通过在线构造对比样本和局部子图,可以在新交互不断到来的情况下,持续优化用户与物品表征;在语音和医疗场景中,研究者也在尝试利用逐日、逐机构新增的未标注数据,构建联邦式或增量式自监督学习管线。ResearchGate+3arXiv+3arXiv+3 从长远来看,能够在不间断数据流中持续进行自监督表征更新的模型,将更接近人类“终身学习”的能力。
第四,隐私友好型和分布式自监督学习将成为在真实应用中落地的重要方向。医疗、金融、物联网等场景中,数据往往分布在多个机构、设备或边缘节点,集中式收集既不现实也存在隐私风险。联邦学习与自监督学习的结合,为“数据不出域但特征共享”提供了新的技术可能。未来的研究有望在联邦自监督学习框架下,通过本地自监督预训练 + 全局参数聚合的方式,在严格的隐私约束下仍然获得高质量统一表征。ResearchGate+5Nature+5PubMed+5
最后,自监督学习与强化学习、生成模型之间的深度融合将催生出更强大的智能体。自监督学习可以被视为学习“世界模型”或“环境表征”的手段,而强化学习则关注如何利用这些表征制定决策策略。已有研究开始将对比式自监督目标引入到RL智能体的状态表征学习中,以提高探索效率和样本利用率;在多模态大模型与机器人领域,也有工作尝试通过语言指令 + 自监督感知 + 强化学习控制的闭环结构,构建具备“看-想-做”能力的复杂系统。PubMed+1 同时,自监督学习与扩散模型、生成对抗网络等生成模型的结合,也将继续推动内容生成、数据增强和世界建模的边界。
6.2 开放性问题与挑战
尽管自监督学习已经在多个领域取得了令人瞩目的成果,但现有文献普遍认为,其发展仍面临一系列尚未充分解决的开放问题。从最新的综述和前沿论文归纳来看,这些问题大致可以从计算资源与能耗、预训练任务设计与理论、模型可解释性与公平性、负迁移风险、数据质量与隐私等几个方面进行讨论。ResearchGate+5arXiv+5ScienceDirect+5
首先,计算资源与能源消耗问题愈发突出。无论是视觉还是语言乃至多模态的大规模自监督模型,其训练往往需要数百到上千张GPU / TPU、持续几周甚至更长的训练时间。这不仅带来极高的经济成本,也引发了关于AI能耗与碳足迹的可持续性讨论。Nature+3ScienceDirect+3arXiv+3 虽然近年来出现了诸如Fast-MoCo、参数高效微调等降低训练成本的尝试,但在如何系统性地权衡“模型规模-数据规模-计算预算-性能”之间的关系、如何设计真正高效且可扩展的自监督算法方面,仍缺乏成熟的理论与实践框架。
其次,预训练任务设计与评估仍然带有很强的“经验主义”色彩。当前许多成功的自监督预训练任务——例如BERT的MLM、SimCLR 的对比学习、MAE 的高比例掩码重建等——大多是通过大量实验探索与手工调参逐步形成的,而非自上而下的理论推导结果。ResearchGate+4arXiv+4ar5iv+4 如何从信息论、统计学习或因果建模的角度,系统地理解“什么样的预训练任务更有利于下游任务”,以及如何在没有下游标签的情况下自动评估与选择预训练目标,是当前的重要研究前沿。部分理论工作尝试从互信息、对齐-均匀性、内在维度等视角进行解释,但距离形成可直接指导实践的原则仍有不小差距。PubMed+2OpenReview+2
第三,模型的可解释性、公平性与鲁棒性问题在自监督学习时代并未消失,甚至在某些场景下被进一步放大。由于自监督模型通常在规模巨大、任务复杂、数据来源多样且未经过滤的语料上训练,其内部表征的含义更难以解释,决策路径也更难追踪。ResearchGate+5Nature+5PubMed+5 同时,这些模型极有可能吸收并放大训练数据中存在的偏见与噪声,在医疗、司法、金融等高风险领域造成潜在危害。如何在自监督学习管线中引入偏见检测与校正机制、如何通过因果推断和可解释建模提高模型透明度、如何增强模型对对抗攻击和分布偏移的鲁棒性,都是目前亟待深入探索的重要方向。
第四,负迁移(Negative Transfer)和跨任务干扰问题在统一表征和多任务训练场景下尤为突出。当预训练任务与下游任务的目标存在显著差异,或者多个下游任务在共享表征空间中竞争资源时,预训练知识可能不仅无益,反而会对某些任务表现产生不利影响。arXiv+1 在大规模多模态、多任务自监督框架中,一个模态或任务的优化过程甚至可能“压制”另一模态/任务的需求,导致性能不均衡或灾难性干扰。如何通过任务加权、模块化设计、可学习路由、条件解耦、任务特定适配器等机制,实现多任务、多模态之间的协同而非竞争,是构建真正通用统一表征系统的关键问题。arXiv+2PubMed+2
最后,数据质量与隐私保护仍然是自监督学习不可回避的基础性问题。自监督范式虽然摆脱了对人工标签的依赖,但对大规模原始数据的需求更甚,从而更容易遭遇版权、合规、隐私与伦理方面的挑战。医疗与金融等领域的数据尤其敏感,稍有不慎就可能触碰法律红线。ResearchGate+5Nature+5PubMed+5 因此,如何在数据采集、预处理、训练和部署的各个环节中引入隐私保护机制(如差分隐私、联邦学习、安全多方计算等),如何在保证模型性能的同时充分尊重用户隐私和数据主权,将成为自监督学习在真实世界大规模落地时必须优先解决的问题。
综合来看,自监督学习既已经成为现代AI系统的基石,又仍处在快速演进与理论积淀的阶段。未来的研究需要在保持性能优势的同时,更加重视效率、理论可解释性、公平与鲁棒性以及合规与伦理等问题。可以预期,随着多模态统一表征、联邦自监督、因果自监督、可解释自监督等方向的不断推进,自监督学习将在向通用人工智能(AGI)演进的道路上扮演愈发核心的角色。
7. 结论
自监督学习作为机器学习领域一颗冉冉升起的新星,正深刻地改变着我们构建和训练AI模型的方式。它通过巧妙地利用数据自身的内在结构作为监督信号,成功地打破了传统监督学习对昂贵人工标注的依赖,为深度学习的发展开辟了新的道路。从BERT在NLP领域的革命性突破,到SimCLR、MoCo在CV领域的巨大成功,再到如今向统一表征、多模态融合方向的演进,自监督学习已经证明了其强大的学习能力和广阔的应用前景。
本文系统地回顾了自监督学习的发展历程,详细阐述了其主要技术方法与模型架构,并探讨了其在各个领域的应用与性能表现。我们看到,无论是基于上下文的预测、生成式的重建,还是对比式的判别,这些方法都从不同角度挖掘了数据中蕴含的丰富信息,学习到了通用、鲁棒的特征表示。预训练-微调范式的确立,使得这些强大的预训练模型能够轻松地适配到各种下游任务,极大地提升了模型的性能和开发效率。
然而,自监督学习的发展仍面临诸多挑战,如计算效率、理论指导、模型可解释性、数据偏见等。未来的研究需要在提升模型性能的同时,更加注重其效率、公平性和可靠性。随着技术的不断进步,我们有理由相信,自监督学习将在构建更强大、更通用、更智能的人工智能系统的道路上扮演越来越重要的角色,最终引领我们走向真正的通用人工智能(AGI)。
部分参考文献
-
Gui, J., Chen, T., Zhang, J., Cao, Q., Sun, Z., Luo, H., & Tao, D. (2023). A Survey on Self‑Supervised Learning: Algorithms, Applications, and Future Trends. arXiv preprint arXiv:2301.05712. arXiv+1
-
Uelwer, T., et al. (2023). A Survey on Self-Supervised Representation Learning. arXiv preprint arXiv:2308.11455. arXiv+1
-
Zhang, C., Zhang, C., Song, J., Yi, J. S. K., & Kweon, I. S. (2022). A Survey on Masked Autoencoder for Visual Self‑supervised Learning. IJCAI 2023 Survey Track. arXiv+1
-
Khan, A., et al. (2024). A Survey of the Self Supervised Learning Mechanisms for Vision Transformers. arXiv preprint arXiv:2408.17059. arXiv+1
-
Ozbulak, U., Lee, H. J., Boga, B., Anzaku, E. T., Park, H., Van Messem, A., De Neve, W., & Vankerschaver, J. (2023). Know Your Self-supervised Learning: A Survey on Image-based Generative and Discriminative Training. arXiv preprint arXiv:2305.13689. arXiv
-
Baevski, A., Zhou, H., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. NeurIPS 2020. arXiv+1
-
Hou, Zhenyu; Liu, Xiao; Cen, Yukuo; Dong, Yuxiao; Yang, Hongxia; Wang, Chunjie; Tang, Jie. (2022). GraphMAE: Self-Supervised Masked Graph Autoencoders. arXiv preprint arXiv:2205.10803. arXiv
-
Zong, Y., Mac Aodha, O., & Hospedales, T. (2023). Self‑Supervised Multimodal Learning: A Survey. arXiv preprint arXiv:2304.01008. arXiv
-
Ramesh, S., et al. (2023). Dissecting self‑supervised learning methods for surgical computer vision. Computers in Biology and Medicine. ScienceDirect
-
Huang, S. C., et al. (2023). Self-supervised learning for medical image classification. NPJ Digital Medicine. Nature+1


















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











